
OpenAI GPT-OSS Hosting
Ollama partners with OpenAI to bring its latest open-weight models to Ollama. The 20B and 120B models bring a whole new local AI experience, designed for powerful reasoning, agentic tasks, and versatile developer use cases.
Best GPU Servers for GPT‑OSS 20B
Unlock the power of OpenAI's GPT‑OSS-20B models — fully hosted and managed on enterprise‑grade NVIDIA GPU servers by DatabaseMart.
Professional GPU VPS - RTX A4000
- GPU Model: RTX A4000
- CPU: 24 CPU Cores
- Memory: 28GB RAM
- Disk: 320GB SSD
- Bandwidth: 300Mbps Unmetered
- IP: 1 Dedicated IPv4
- Location: USA
- Backup: Once per 2 Weeks
Professional GPU VPS - RTX Pro 2000
- GPU Model: RTX Pro 2000
- CPU: 16 CPU Cores
- Memory: 28GB RAM
- Disk: 240GB SSD
- Bandwidth: 300Mbps Unmetered
- IP: 1 Dedicated IPv4
- Location: USA
- Backup: Once per 2 Weeks
Advanced GPU VPS - RTX Pro 4000
- GPU Model: RTX Pro 4000
- CPU: 24 CPU Cores
- Memory: 56GB RAM
- Disk: 320GB SSD
- Bandwidth: 500Mbps Unmetered
- IP: 1 Dedicated IPv4
- Location: USA
- Backup: Once per 2 Weeks
Advanced Dedicated GPU Server - RTX A5000
- GPU Model: RTX A5000
- CPU: 24-Core Dual E5-2697v2
- Memory: 128GB RAM
- Disk: 240GB SSD+2TB SSD
- Bandwidth: 100Mbps Unmetered
- IP: 1 Dedicated IPv4
- Location: USA
Advanced Dedicated GPU Server - V100
- GPU Model: V100
- CPU: 24-Core Dual E5-2690v3
- Memory: 128GB RAM
- Disk: 240GB SSD+2TB SSD
- Bandwidth: 100Mbps Unmetered
- IP: 1 Dedicated IPv4
- Location: USA
Advanced GPU VPS - RTX 5090
- GPU Model: RTX 5090
- CPU: 32 CPU Cores
- Memory: 84GB RAM
- Disk: 400GB SSD
- Bandwidth: 500Mbps Unmetered
- IP: 1 Dedicated IPv4
- Location: USA
- Backup: Once per 2 Weeks
Enterprise Dedicated GPU Server - RTX 4090
- GPU Model: RTX 4090
- CPU: 36-Core Dual E5-2697v4
- Memory: 256GB RAM
- Disk: 240GB SSD+2TB NVMe+8TB SATA
- Bandwidth: 100Mbps Unmetered
- IP: 1 Dedicated IPv4
- Location: USA
Enterprise Dedicated GPU Server - A100
- GPU Model: A100
- CPU: 36-Core Dual E5-2697v4
- Memory: 256GB RAM
- Disk: 240GB SSD+2TB NVMe+8TB SATA
- Bandwidth: 100Mbps Unmetered
- IP: 1 Dedicated IPv4
- Location: USA
Best GPU Servers for GPT-OSS 120B
Unlock the power of OpenAI's GPT-OSS-120B models — fully hosted and managed on enterprise-grade NVIDIA GPU servers by DatabaseMart.
Enterprise GPU VPS - RTX Pro 6000
- GPU Model: RTX Pro 6000
- CPU: 32 CPU Cores
- Memory: 84GB RAM
- Disk: 400GB SSD
- Bandwidth: 1000Mbps Unmetered
- IP: 1 Dedicated IPv4
- Location: USA
- Backup: Once per 2 Weeks
Enterprise Multi-GPU Dedicated Server - 3xRTX A6000
- GPU Model: 3 x RTX A6000
- CPU: 36-Core Dual E5-2697v4
- Memory: 256GB RAM
- Disk: 240GB SSD+2TB NVMe+8TB SATA
- Bandwidth: 1000Mbps Unmetered
- IP: 1 Dedicated IPv4
- Location: USA
Enterprise Dedicated GPU Server - A100(80GB)
- GPU Model: A100(80GB)
- CPU: 36-Core Dual E5-2697v4
- Memory: 256GB RAM
- Disk: 240GB SSD+2TB NVMe+8TB SATA
- Bandwidth: 100Mbps Unmetered
- IP: 1 Dedicated IPv4
- Location: USA
Enterprise Dedicated GPU Server - H100
- GPU Model: H100
- CPU: 36-Core Dual E5-2697v4
- Memory: 256GB RAM
- Disk: 240GB SSD+2TB NVMe+8TB SATA
- Bandwidth: 100Mbps Unmetered
- IP: 1 Dedicated IPv4
- Location: USA
Features of Our GPT-OSS LLM Hosting
Pre-installed with Open WebUI and Ollama, ready to use out of the box. Pairing Open WebUI with Ollama is widely regarded as a solid and practical solution for self-hosting LLMs.
Key features of Open WebUI:
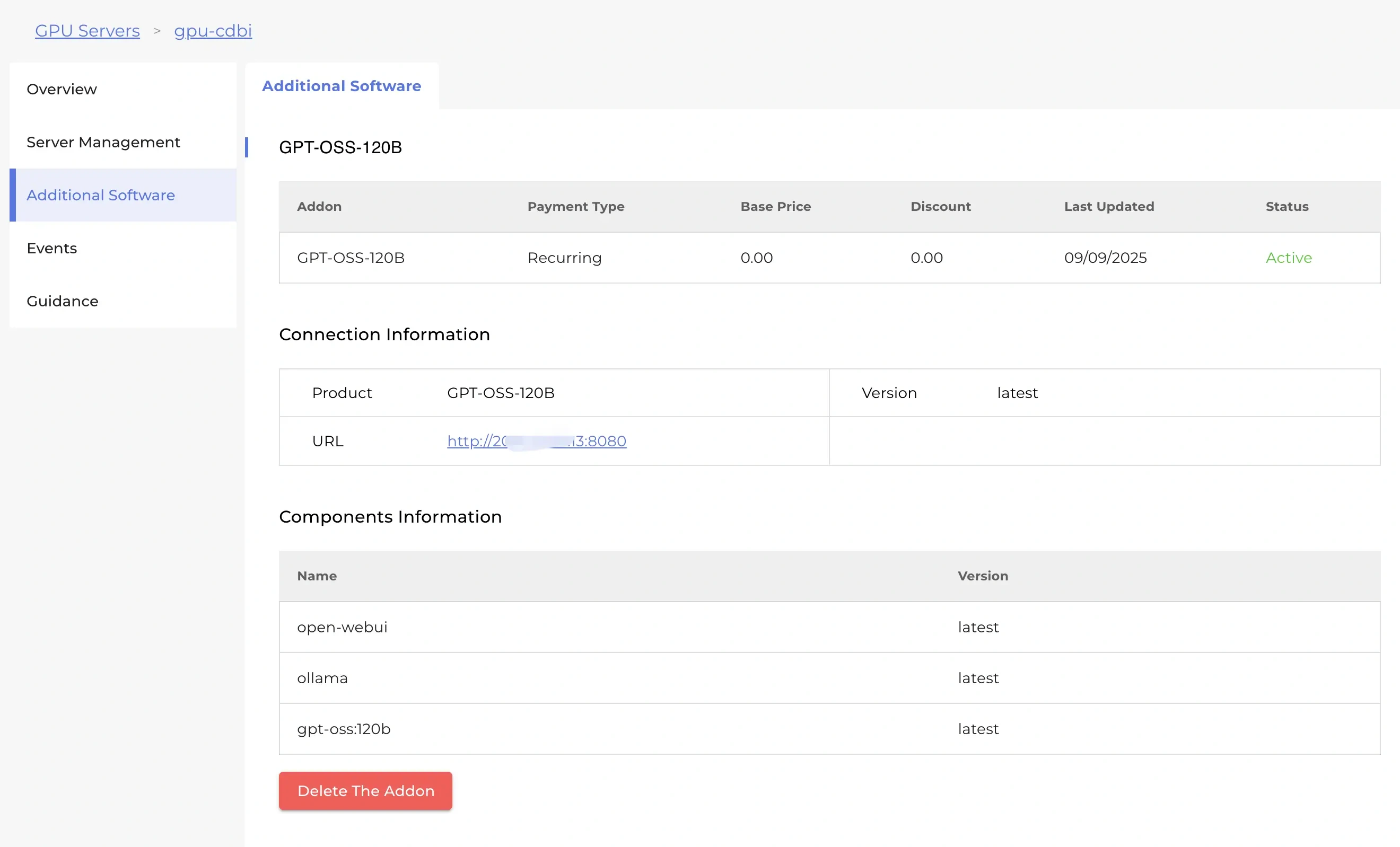
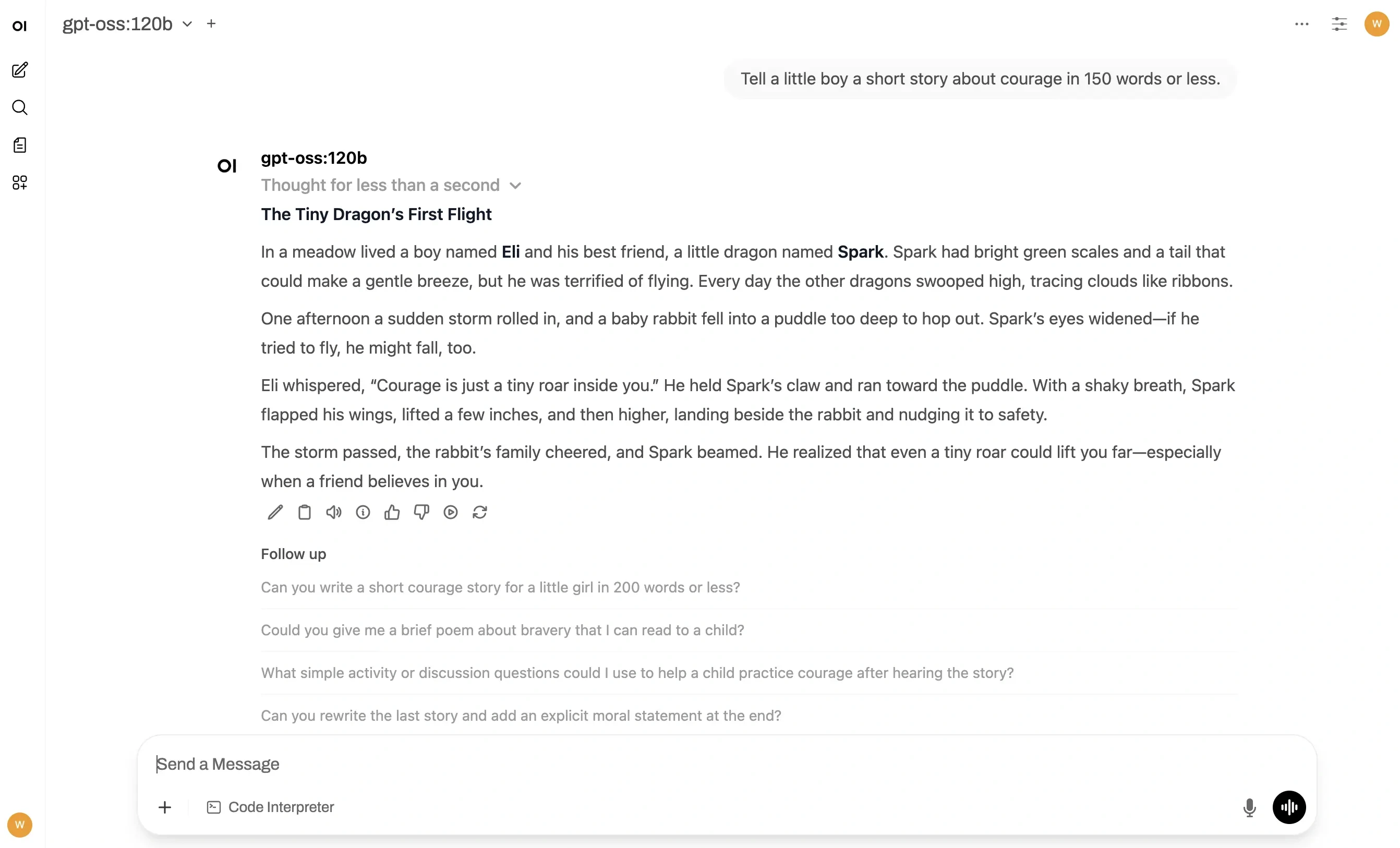
Open WebUI is designed to easily connect with Ollama. It detects Ollama automatically once both are running, and you can manage and chat with your models through a polished web interface.
Open WebUI offers a user-friendly, extensible interface running completely offline. Supports Ollama, OpenAI-compatible APIs, and advanced features like RAG and tool pipelines.
Ollama enables strictly local model execution. Your data stays on your machine, enhancing privacy and giving you full control over the environment.
We provide 24/7 customer support. Simply reach out through a ticket or live chat, and our support team responds promptly to ensure your concerns are addressed quickly.
Each Dedicated GPU server comes with a dedicated GPU, CPU, and a dedicated U.S. IP address. This isolation ensures your data and privacy are securely maintained.
As your business grows, you can easily adjust resource allocations, upgrading or downgrading your plan to ensure optimal server performance aligned with your requirements.
Our data centers in the U.S. are monitored 24/7 by a professional team and equipped with camera surveillance to ensure top-notch security.
Full access empowers you to configure your server and allocate resources freely. Install and download any software without restrictions.
What is GPT OSS
GPT-OSS is the open-source model family from OpenAI — a hugely anticipated open-weights release designed for powerful reasoning, agentic tasks, and versatile developer use cases.
OpenAI GPT-OSS is an open-weight large language model (LLM) series released by OpenAI on August 6, 2025. Designed for local deployment, transparency, and commercial use, GPT-OSS offers powerful AI capabilities while addressing privacy, cost, and customization challenges associated with closed API models.
Overview of Capabilities
Feature highlights
Use the models’ native capabilities for function calling, web browsing (Ollama is providing a built-in web search that can be optionally enabled to augment the model with the latest information), python tool calls, and structured outputs.
Gain complete access to the model’s reasoning process, facilitating easier debugging and increased trust in outputs.
Easily adjust the reasoning effort (low, medium, high) based on your specific use case and latency needs.
Fully customize models to your specific use case through parameter fine-tuning.
Build freely without copyleft restrictions or patent risk—ideal for experimentation, customization, and commercial deployment.
gpt‑oss‑120b vs gpt‑oss‑20b
Choose the right model for your workload — from edge deployment to enterprise-grade reasoning.
gpt-oss-120b
A 117-billion parameter mixture-of-experts model (~5.1B active parameters per token). Designed for high reasoning and general-purpose use, offering performance comparable to OpenAI's proprietary o4-mini model. Architecturally, it has 36 layers, each with 128 experts, of which 4 are active per token.
gpt-oss-20b
A smaller 21-billion parameter model, with ~3.6B active parameters per token. Optimized for local or edge deployment — runs well on devices with ≈16 GB GPU memory. Designed for latency-sensitive agentic workflows, tool use, and rapid prototyping with lower compute overhead.
Benchmark Results
| gpt-oss-120b | gpt-oss-20b | OpenAI o3 | OpenAI o4-mini | |
|---|---|---|---|---|
| Reasoning knowledge | ||||
| MMLU | 90 | 85.3 | 93.4 | 93 |
| GPQA Diamond | 80.1 | 71.5 | 83.3 | 81.4 |
| Humanity's Last Exam | 19 | 17.3 | 24.9 | 17.7 |
| Competition math | ||||
| AIME 2024 | 96.6 | 96 | 95.2 | 98.7 |
| AIME 2025 | 97.9 | 98.7 | 98.4 | 99.5 |
Why Choose Database Mart for GPT-OSS?
Tailored infrastructure for deploying open-weight LLMs with full privacy, dedicated hardware, and around-the-clock support.
Tailored servers for deploying gpt‑oss‑20B, gpt‑oss‑120B, and more via Ollama, vLLM, LLaMA, and Mistral frameworks.
Access to high‑VRAM cards — RTX 4090 (24GB), RTX A6000 (48GB), A100 (40/80GB) — ideal for gpt‑oss deployment at scale.
Eliminate hypervisor overhead and ensure maximum GPU performance for inference workloads with dedicated hardware.
High uptime guarantee with U.S.-based data centers and enterprise-grade infrastructure backing your deployments.
Free help available via live chat, ticket, or email — free for VPS and professional for dedicated GPU servers.
Choose from standalone GPU machines or custom multi-GPU configurations — just tell us your deployment needs.
FAQs of GPT-OSS Hosting
The most commonly asked questions about GPT-OSS hosting.
- gpt-oss-20b: A 20-billion-parameter model suitable for powerful inference on a single high-end GPU or multi-GPU system.
- gpt-oss-120b: A 120-billion-parameter model requiring high memory bandwidth and typically multiple GPUs for optimal performance.
- For 20B: 1× A4000 16GB, or 1× RTX 4090 24GB
- For 120B: 1× A100 80GB, or 2× A100 40GB with NVLink or high-speed interconnect
- Ollama, vLLM, or Open WebUI as the inference server
- Python ≥ 3.10
- CUDA drivers for GPU acceleration
- Model weights from Hugging Face or other open repositories
- Choose a compatible GPU server on DatabaseMart.com
- Request GPT-OSS environment setup
- Access your server via SSH or web interface
- Start generating with full control and privacy
Deploy GPT-OSS on Your Own GPU Server
Pre-installed with Ollama and Open WebUI. Dedicated NVIDIA GPUs. Full root access. Privacy-first infrastructure — your data stays on your machine.