

CPU vs GPU vs TPU: Key Differences, Use Cases, and Performance Explained
The rapid growth of artificial intelligence, data analytics, and cloud computing has created a demand for increasingly powerful computing hardware. While traditional CPUs (Central Processing Units) remain the backbone of general-purpose computing, the rise of GPUs (Graphics Processing Units) and TPUs (Tensor Processing Units) has reshaped how we process data, train AI models, and deploy applications at scale.
Each of these processors has unique strengths: CPUs excel at versatility and complex logic, GPUs are designed for parallel workloads like graphics rendering and AI training, while TPUs focus on accelerating machine learning with specialized tensor operations.
What is a CPU (Central Processing Unit)?
The CPU, often called the “brain” of a computer, is the primary processor responsible for executing instructions and managing general-purpose tasks. It is designed to handle a wide variety of operations, from running operating systems and applications to controlling hardware resources.
Key Characteristics of a CPU
- Few cores, high clock speed – CPUs usually have fewer cores than GPUs, but each core is optimized for powerful single-thread performance.
- Complex instruction sets – Capable of handling diverse and complex tasks, including arithmetic, logic, memory management, and input/output operations.
- Low parallelism, high flexibility – Unlike GPUs or TPUs, CPUs are not built for massive parallel workloads but excel in versatility and general-purpose computing.
Strengths of a CPU
- Handles sequential and logic-heavy tasks efficiently.
- Essential for running the operating system and coordinating hardware.
- Well-suited for small-scale AI inference, business applications, and everyday computing.
Limitations of a CPU
- Not optimized for large-scale parallel processing.
- Slower in workloads like deep learning training compared to GPUs or TPUs.
- Higher cost per unit of compute power for specialized tasks (e.g., AI training).
Use Cases of CPUs
- Running operating systems and everyday software (browsers, office apps).
- Server-side tasks like web hosting, databases, and transactions.
- Orchestration in heterogeneous computing systems (CPU + GPU/TPU collaboration).
What is a GPU (Graphics Processing Unit)?
A GPU, or Graphics Processing Unit, was originally designed to accelerate the rendering of images and graphics for displays. Over time, GPUs have evolved into powerful parallel processors capable of handling large-scale mathematical and scientific computations, especially in artificial intelligence and deep learning.
Key Characteristics of a GPU
- Many cores, high parallelism – A GPU has thousands of smaller, efficient cores optimized for simultaneous tasks, making it ideal for workloads like matrix multiplications.
- High throughput – Specialized for performing the same type of operation across large datasets in parallel.
- SIMD architecture – Uses Single Instruction, Multiple Data processing, which excels at repetitive calculations.
Strengths of a GPU
- AI & Machine Learning – Speeds up training and inference for deep learning models.
- Graphics rendering – Essential for gaming, 3D modeling, and visualization.
- Scientific computing – Accelerates simulations, data analysis, and high-performance computing (HPC).
- Video processing – Efficient for encoding, decoding, and real-time video streaming.
Limitations of a GPU
- Less effective at complex logic and sequential tasks compared to CPUs.
- Higher power consumption for continuous workloads.
- Needs a CPU to coordinate operations (cannot replace a CPU entirely).
Use Cases of GPUs
- Gaming & Graphics – Rendering realistic 3D environments.
- AI & Deep Learning – Training large-scale neural networks like LLMs or image models.
- Data Analytics & Big Data – Processing huge datasets in parallel.
- Video Streaming – Hardware acceleration for encoding/decoding (NVENC, AMF, etc.).
What is a TPU (Tensor Processing Unit)?
A TPU, or Tensor Processing Unit, is a specialized processor developed by Google to accelerate machine learning workloads, especially deep learning models. Unlike CPUs (general-purpose) and GPUs (parallel-purpose), TPUs are application-specific integrated circuits (ASICs) optimized for tensor operations, which are the core of neural network training and inference.
Key Characteristics of a TPU
- Matrix multiply engine – Designed for fast tensor and matrix operations.
- Optimized for AI – Built to handle the workloads of TensorFlow and other machine learning frameworks.
- High energy efficiency – Delivers more performance per watt for AI tasks compared to GPUs.
- Cloud-first design – Widely available through Google Cloud rather than as consumer hardware.
Strengths of a TPU
- AI training & inference at scale – Especially effective for large models like Transformers and LLMs.
- Specialized hardware – Provides lower latency and higher throughput than GPUs for supported workloads.
- Scalability – TPUs are designed to run in pods, enabling massive parallel training.
Limitations of a TPU
- Narrow focus – Less flexible than GPUs; mainly optimized for deep learning rather than general HPC or graphics.
- Limited ecosystem – Mostly tied to Google Cloud, with less availability for on-premises use.
- Software dependency – Performs best with TensorFlow; less mature support for other frameworks like PyTorch (though improving).
Use Cases of TPUs
- Large-scale AI training – Training massive language models (LLMs) and image models.
- AI inference in production – Accelerating real-time predictions in cloud applications.
- Enterprise & research AI – Used by companies and institutions for cutting-edge ML workloads.
Comparison of CPU vs. GPU vs. TPU
The image illustrates how memory design and compute primitives evolve from CPU → GPU → TPU to support increasingly parallel workloads, from general-purpose computation (scalar) to deep learning-specific tensor operations.
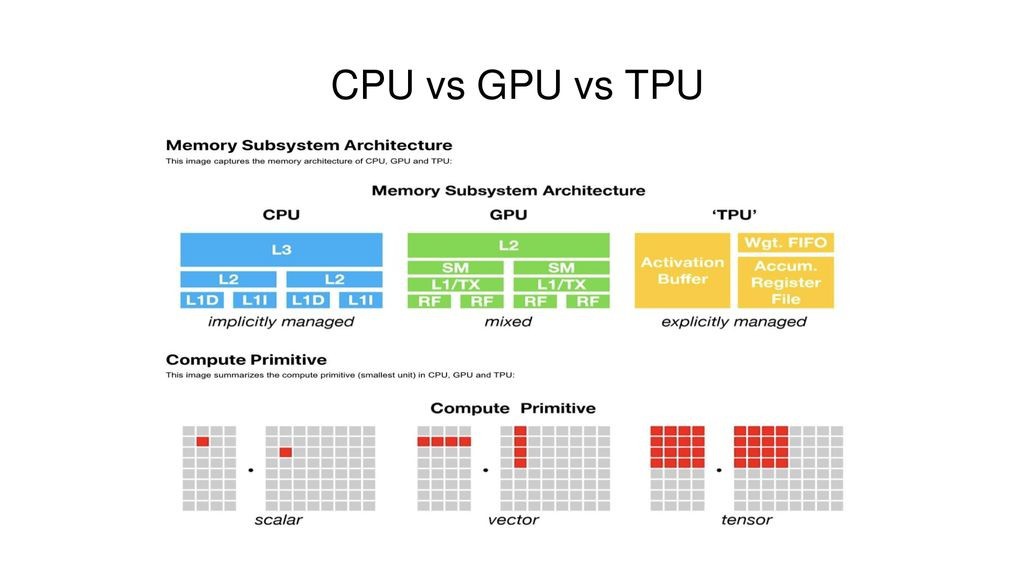
Memory Subsystem Architecture:
- CPU: Features multiple cache levels (L1, L2, L3) that are implicitly managed by the hardware. L1 is split into instruction (L1I) and data (L1D) caches.
- GPU: Uses a mixed memory management system with L1 caches per streaming multiprocessor (SM), shared memory (SM), and register files (RF). L2 cache acts as a higher-level shared cache.
- TPU: Memory is explicitly managed with specialized buffers: Activation Buffer, Weight FIFO, and Accumulator Register File, optimized for matrix/tensor computations.
Compute Primitives:
- CPU: Operates primarily on scalar units, executing one operation at a time.
- GPU: Uses vector units, capable of processing multiple elements simultaneously in a SIMD fashion.
- TPU: Operates on tensor units, processing large blocks of data (matrix/tensor operations) in parallel, ideal for deep learning workloads.
Can Regular Hosting Providers Offer TPU Hosting?
Unlike GPUs, which can be purchased from vendors such as NVIDIA or AMD and installed into dedicated servers, TPUs are proprietary hardware developed and maintained by Google. This means that most traditional hosting providers cannot simply add TPU cards to their infrastructure and offer them as a service.
Currently, TPU hosting is almost exclusively available through Google Cloud, where users can rent TPU v2, v3, v4, or the latest v5p models on demand. For hosting providers, the practical way to include TPU services is by partnering with Google Cloud and reselling or integrating TPU access into their own platforms.
As a result, while GPU hosting is widely offered by many data centers and providers, TPU hosting remains highly specialized and limited to Google’s ecosystem, making it less common in the broader hosting market.
Future Trends
- CPUs: They will continue to serve as the foundation for system control and general logic, but will play a more supporting role in AI training.
- GPUs: They will remain the mainstream AI computing hardware, particularly in Low-Level Machine Learning (LLM) training, inference, rendering, and scientific computing.
- TPUs: They will continue to develop within the Google Cloud ecosystem, while also inspiring innovation in more specialized AI chips (such as NPUs, ASICs, and FPGAs).
Conclusion: CPUs, GPUs, and TPUs
CPUs, GPUs, and TPUs are different types of processors, each optimized for different computing tasks. CPUs are the most versatile, excelling at handling complex logic and multitasking. GPUs excel at massively parallel computing and are commonly used for graphics rendering and AI training. TPUs are optimized for deep learning, offering exceptional efficiency in matrix operations and AI inference. Each has its own focus, and the most appropriate chip is typically chosen based on the task at hand.
CPU vs GPU vs TPU, CPU GPU TPU comparison, CPU GPU TPU performance, CPU GPU TPU use cases, TPU hosting, GPU hosting, AI processors, machine learning hardware, deep learning acceleration, CPU GPU TPU differences