

H100 vs H200: Which NVIDIA GPU Will Power the Future of AI?
Dive into the ultimate comparison between NVIDIA’s H100 and H200 GPUs. Explore detailed specs, performance benchmarks, and real-world AI applications, from large language model training to high-performance inference workloads. Find out which GPU delivers the best results for cutting-edge AI projects and data center deployments.
H100 vs H200 – Background Comparison
| Model | Brand | Series | Architecture | Release Year | Official Positioning | Current Market Price (Approx.) |
|---|---|---|---|---|---|---|
| NVIDIA H100 | NVIDIA | Data Center / Hopper | Hopper | 2022 | Flagship data center GPU for AI training & inference, HPC workloads | ~$25,000–$40,000 USD |
| NVIDIA H200 | NVIDIA | Data Center / Hopper Enhanced | Hopper (HBM3e) | 2023 | Next-gen data center GPU for generative AI and large model workloads | ~$30,000–$55,000 USD |
Summary Highlights
- H100: Flagship data center GPU, excels in AI training and inference, as well as HPC workloads.
- H200: Next-generation GPU with larger HBM3e memory, optimized for generative AI and large language model workloads, offering higher throughput for massive AI tasks.
- Key Advantage: H200 builds on H100 with increased memory capacity and bandwidth, enabling superior performance for extremely large models and high-concurrency inference.
- Value Insight: While H200 is ideal for cutting-edge AI and generative workloads, H100 remains highly capable and may be more cost-effective for general AI training and HPC scenarios.
H100 vs H200 Specification Comparison
Core Specs: H100 vs H200
| Specification | NVIDIA H100 | NVIDIA H200 | Difference / Advantage |
|---|---|---|---|
| Architecture | Hopper | Enhanced Hopper | H200 is an upgraded Hopper version with improved memory support |
| CUDA Cores | 16,896 | 16,896 | Same CUDA core count |
| Memory Type | HBM3 | HBM3e | H200 uses next-gen HBM3e for higher bandwidth |
| Memory Capacity (vRAM) | 80 GB | 141 GB | H200 has ~ 76% more memory for larger models and datasets |
| Memory Bus | 5120-bit | 6144-bit | Wider memory bus on H200 improves throughput |
| Memory Bandwidth | 3.35 TB/s | 4.8 TB/s | ~ 43% higher bandwidth on H200 benefits memory-heavy AI workloads |
| Core Frequency (Boost) | 1.41 GHz | 1.41 GHz | Same peak clock speed |
| TDP (Power) | 700 W | 700 W | Same power envelope |
| Interface / Bus | NVLink + PCIe Gen5 | NVLink + PCIe Gen5 | Same interconnect and PCIe support |
| FP32 Performance | 67 TFLOPS | 67 TFLOPS | Raw compute performance is similar |
| Ray Tracing / Tensor Cores | Tensor Cores (FP8/FP16/INT8), no dedicated RT cores | Tensor Cores (FP8/FP16/INT8), no dedicated RT cores | Same Tensor Core throughput; advantage comes from larger memory in H200 |
| PCIe Version | PCIe Gen5 | PCIe Gen5 | Same PCIe generation |
Key Highlights:
Memory Capacity:
H200 is equipped with 141 GB HBM3e memory, compared to 80 GB HBM3 on H100, offering approximately 76% more memory capacity, which significantly improves support for large language models and long-context AI workloads.Memory Bandwidth:
With 4.8 TB/s memory bandwidth, H200 delivers about 43% higher bandwidth than H100’s 3.35 TB/s, reducing memory bottlenecks in memory-intensive AI training and inference tasks.Memory Technology:
H200 upgrades from HBM3 to HBM3e, enabling both higher bandwidth and better efficiency, giving H200 a clear advantage in next-generation generative AI workloads.Memory Bus Width:
H200 features a wider memory bus, allowing more data to be transferred per cycle, which directly benefits large-scale AI models that rely heavily on memory throughput.Compute Performance (FP32 & CUDA Cores):
Both H100 and H200 offer the same CUDA core count and FP32 performance, meaning raw compute power remains comparable, and performance gains on H200 mainly come from memory improvements rather than core count.Tensor Core Capabilities:
Both GPUs use the same Hopper-generation Tensor Cores, but H200’s larger and faster memory enables higher real-world AI inference throughput, especially for very large models.Power Efficiency Perspective:
Despite its larger memory and higher bandwidth, H200 maintains a similar TDP to H100, resulting in better performance per watt for memory-bound AI workloads.
Advanced Features
| Parameter | NVIDIA H100 | NVIDIA H200 | Difference / Advantage |
|---|---|---|---|
| Primary Optimization Focus | Balanced AI training & inference | Memory-optimized for large AI models | H200 is better for memory-bound workloads |
| LLM Model Size Support | Large models | Extra-large models | H200 can handle larger models without sharding |
| Inference Throughput (Real-World) | High | Higher | H200 delivers higher inference throughput due to faster memory |
| Context Length Capability | Long context | Longer context | H200 supports longer context windows for LLM inference |
| MIG Memory per Instance | Smaller per slice | Larger per slice | H200 enables larger MIG partitions |
Although NVIDIA H100 and H200 share similar compute architecture, H200 GPU is clearly optimized for large language model inference, offering higher throughput, longer context support, and better multi-tenant efficiency thanks to its larger and faster memory.
NVIDIA H100 vs H200 Benchmark for AI
Both NVIDIA H100 and H200 are designed for large-scale AI workloads, including AI inference and training. While their compute capabilities are similar, differences in memory capacity and bandwidth lead to noticeable performance gaps as model sizes and inference demands increase, especially in memory-intensive AI inference scenarios.
H100 vs H200 for AI Inference
Based on benchmark testing, the NVIDIA H200 significantly outperforms the H100 in large language model (LLM) inference. Thanks to larger memory (141 GB vs 80 GB) and higher HBM3e bandwidth, the H200 achieves significantly higher tokens/sec than the H100. For example, on Llama2‑13B, H200 reaches 11,819 tokens/sec, a ~ 90% increase over H100’s 6,221 tokens/sec; on Llama2‑70B, H200 hits 31,712 tokens/sec, roughly 42% higher than H100’s 22,290 tokens/sec. These results highlight H200’s clear advantage for memory-bound LLM inference, including long-context generation and high-concurrency deployments.
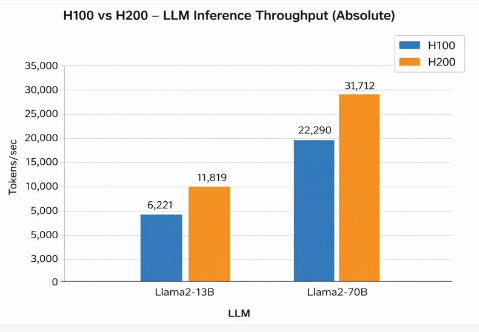
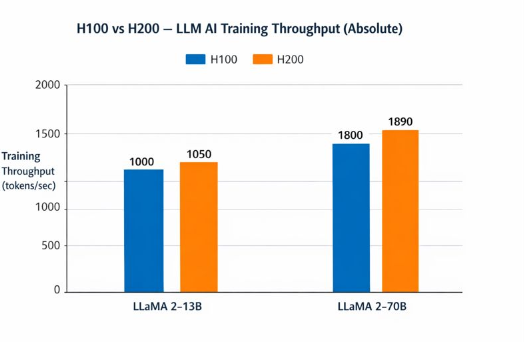
H100 vs H200 for AI Training
H200 provides a modest performance improvement of approximately +5% over H100 in AI training workloads, reflecting slightly higher memory bandwidth and GPU frequency. While H200 excels in memory-bound inference tasks, its training performance remains largely comparable to H100 in compute-bound scenarios.
Price & Value: Nvidia H100 vs H200
| Platform | Nvidia H100 (USD) | Nvidia H200 (USD) | Price Difference (USD) | Price Difference (%) |
|---|---|---|---|---|
| Official MSRP | $29,000 | $31,000 | +$2,000 | +7% |
| Amazon | $28,500 – $30,500 | $30,500 – $33,000 | +$2,000 – $2,500 | +7% – +8% |
| Third-Party Resellers (eBay etc.) | $27,000 – $31,500 | $29,500 – $33,500 | +$2,500 – $3,000 | +8% – +10% |
Value Proposition:
While the Nvidia H200 GPU carries a 7–10% premium over the H100 price, it offers measurable performance improvements in AI training and inference workloads. For users running large-scale models or high-throughput tasks, the slightly higher cost is offset by faster processing, improved efficiency, and better long-term value, making the H200 a compelling upgrade for organizations prioritizing performance per dollar.
H200 vs H100 – Pros & Cons
| GPU | Pros | Cons |
|---|---|---|
| H100 | • Excellent AI training and inference performance • High memory bandwidth (80 GB HBM3) • Strong power efficiency for HPC workloads • Widely available via OEMs and resellers |
• High price point • Slightly lower throughput than H200 in large-scale AI tasks • May require specialized infrastructure |
| H200 | • Improved AI training and inference performance (+5–10% vs H100) • Slightly higher memory bandwidth and efficiency • Better performance per watt • Optimized for large-scale model workloads |
• 7–10% higher price than H100 • May have limited availability initially • Marginal gains may not justify upgrade for small workloads |
H100 Server Hosting
The H100 is one of the most sought-after GPUs for AI training and high-performance computing, commonly offered by cloud hosting providers. To save costs, some providers use shared cloud instances or serverless platforms, but this can limit performance for demanding workloads. For users running real-world AI training, inference, or HPC tasks, a dedicated H100 server is the smarter choice.
Database Mart provides GPU server hosting built with high-quality hardware, ensuring a strong balance of performance and value. With decades of proven reliability, Database Mart has become a trusted provider for enterprises and researchers worldwide seeking enterprise-grade GPU solutions.
Conclusion
The Nvidia H100 and H200 are both top-tier GPUs for AI training and high-performance computing. The H200 delivers slightly higher performance and efficiency, making it ideal for large-scale or high-throughput workloads, while the H100 remains a powerful and cost-effective option for most AI and HPC tasks. Ultimately, the choice depends on your performance requirements, workload scale, and budget, with both GPUs offering excellent value for cutting-edge AI applications.
h100 vs h200, h200 vs h100, nvidia h100 vs h200, nvidia h100, h100 gpu, h100 price,nvidia h200 gpu, h200 gpu, h100 specs, h200 specs, h100 for AI training, h200 for AI inference