

H20 vs H100: AI Inference Performance, Pricing, and Use Case Comparison
H20 vs H100 – Background Comparison
| Brand | Series | Model | Release Year | Official Positioning | Market Price (USD) |
|---|---|---|---|---|---|
| NVIDIA | Data Center | NVIDIA H20 GPU | 2023 | The NVIDIA H20 GPU is a data center accelerator designed for AI workloads in regulated markets. Built on the Hopper architecture, it delivers balanced performance for gpu for ai training, inference, and enterprise AI deployment. In a typical h20 vs h100 comparison, H20 prioritizes accessibility and efficiency over peak compute density. Its practical h20 specs make it suitable for organizations evaluating overall value against h20 price. | Varies (Enterprise Pricing) |
| NVIDIA | Data Center | NVIDIA H100 GPU | 2022 | The NVIDIA H100 GPU is NVIDIA’s flagship accelerator for large-scale data centers and advanced gpu for ai training. Powered by the Hopper architecture, it delivers industry-leading performance for deep learning, large language models, and high-performance computing. In any h20 vs h100 analysis, the H100 stands out with superior compute throughput and memory bandwidth, supported by robust h100 specs that justify its premium h100 price in enterprise environments. | Varies (Enterprise Pricing) |
H20 vs H100– Specifications Comparison
The h20 vs h100 comparison reflects a clear difference in server-grade specifications and performance ceilings rather than a generational architecture change, as both accelerators are built on the same Hopper platform from NVIDIA.
The nvidia h100 gpu is engineered to maximize absolute compute density and memory throughput for large-scale AI workloads. Its significantly higher CUDA core count, substantially greater memory bandwidth, and higher FP32 throughput define its role as a flagship accelerator for bandwidth-intensive and compute-heavy gpu for ai training scenarios. These strengths are clearly visible in the h100 specs, where memory bandwidth and peak performance scale far beyond what most single-node workloads require, justifying the premium h100 price in enterprise and hyperscale deployments.
The nvidia h20 gpu, while based on the same Hopper architecture, adopts a more constrained specification profile. With reduced core count, lower memory bandwidth, and capped compute performance, the H20 prioritizes balanced utilization over peak throughput. From a specifications perspective, the h20 specs emphasize sufficient memory capacity and stable PCIe deployment rather than maximum interconnect and compute density. In direct h20 vs h100 comparisons, these limitations place the H20 behind the H100 in raw performance, but they also translate into lower power envelopes and a more approachable h20 price for regulated or cost-sensitive environments.
In summary, the h20 vs h100 distinction is fundamentally defined by specifications: H100 leads in every performance-critical metric tied to large-scale training, while H20 delivers a trimmed specification set designed to meet real-world deployment constraints. Rather than competing head-to-head, the two GPUs serve different tiers of gpu for ai training, with the H100 targeting maximum scalability and the H20 focusing on practical, compliant server configurations.
Core Specs Comparison between RTX 3080 Ti vs RTX 4070 Super
| Specification | NVIDIA H20 GPU | NVIDIA H100 GPU |
|---|---|---|
| Architecture | Hopper | Hopper |
| CUDA Cores | ~14,000 (restricted configuration) | 16,896 |
| Memory Type | HBM3 | HBM3 / HBM3e |
| Memory Capacity | 96 GB | 80 GB / 94 GB / 144 GB (variant-dependent) |
| Memory Bus | ~5,120-bit | 5,120-bit |
| Memory Bandwidth | ~4.0 TB/s | Up to ~8.0 TB/s |
| Core Frequency (Boost) | ~1.5 GHz | ~1.8 GHz |
| TDP (Power) | ~400 W | 350 W (PCIe) / 700 W (SXM) |
| Interface / Bus | PCIe 5.0 x16 | PCIe 5.0 x16 / SXM5 |
| FP32 Performance | ~44 TFLOPS | ~60 TFLOPS |
| Ray Tracing / Tensor | 4th-gen Tensor Cores | 4th-gen Tensor Cores |
| PCIe Version | PCIe 5.0 | PCIe 5.0 |
Key Differences: H20 vs H100
Compute Density & Core Configuration
From a specifications standpoint, the most significant difference in the h20 vs h100 comparison lies in compute density. The nvidia h100 gpu features a substantially higher CUDA core count and fully enabled Hopper compute blocks, allowing it to deliver much higher FP32 and mixed-precision throughput. These characteristics define the h100 specs as being optimized for large-scale, compute-bound gpu for ai training, where maximum parallelism directly translates into faster model training and better multi-node scaling. By contrast, the nvidia h20 gpu operates with a restricted core configuration, limiting peak compute output and placing an upper bound on raw training throughput, which is a defining trait of the h20 specs.
Memory Bandwidth & Data Throughput
Memory bandwidth represents another major divergence between the two GPUs. The H100 is equipped with a significantly higher-bandwidth HBM memory subsystem, enabling it to sustain data-hungry workloads such as large language model training and high-dimensional tensor operations. This advantage is central to many h20 vs h100 performance discussions, as memory bandwidth often becomes the primary bottleneck in advanced AI workloads. The H20, while offering ample memory capacity, operates with a notably lower bandwidth ceiling, which can constrain performance in bandwidth-intensive training scenarios even when compute resources are available.
Power Envelope & Performance Scaling
Power and performance scaling further separate these two accelerators at the specification level. The H100 is designed to operate at much higher power levels, especially in SXM configurations, allowing it to sustain peak performance under continuous load. This capability aligns with its premium h100 price and hyperscale deployment targets. The H20, with a more constrained power envelope, emphasizes predictable performance and deployment flexibility over absolute throughput. In practical h20 vs h100 evaluations, this results in lower sustained performance but improved suitability for cost- and compliance-sensitive environments, often reflected in a comparatively lower h20 price.
H20 vs H100 AI Training
Estimated Token Throughput on LLaMA 2 70B
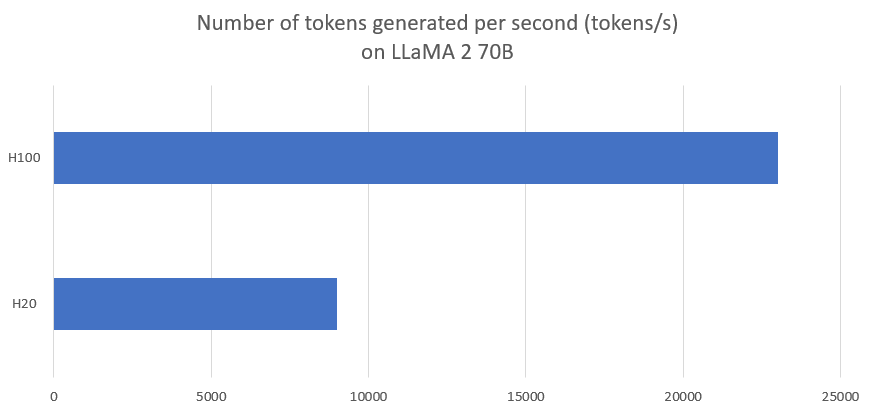
This chart compares the estimated number of tokens generated per second (tokens/s) when running** LLaMA 2 70B** in an AI inference scenario on NVIDIA H100 and NVIDIA H20 GPUs.
The H100 value (~21,500–23,000 tokens/s) is based on public MLPerf Inference benchmarks under optimized server configurations.
The H20 value (~6,000–9,000 tokens/s) is an engineering-level estimate, derived from architectural constraints, memory bandwidth differences, and real-world inference deployment behavior, as NVIDIA has not released official MLPerf inference results for H20.
Training Compute Capability (FP16/BF16)
In training-focused workloads, the gap is significantly larger:
H100 provides several times higher FP16/BF16 tensor throughput than H20, enabling efficient large-scale model training and full-parameter fine-tuning.
H20’s reduced training throughput limits its practicality for large-model pretraining, positioning it primarily for inference or light fine-tuning tasks.
Memory Capacity and Model Fit
H20: 96 GB HBM
H100: 80 GB HBM
The larger memory capacity of H20 allows easier deployment of memory-heavy inference workloads, longer context windows, and additional KV cache per instance. In contrast, H100 relies on higher compute and bandwidth to maximize throughput per deployed model instance.
Practical Deployment Density (Inference)
In real-world inference deployments using mid-sized models (e.g., 32B parameters):
H20 can typically support 1–2 concurrent inference instances per GPU, depending on precision and KV-cache configuration.
H100 generally prioritizes single-instance, high-throughput execution, achieving much higher tokens-per-second per instance but fewer standalone replicas.
Power and Efficiency Considerations
While H100 delivers superior absolute performance, it operates at a higher power envelope. H20 offers a more predictable performance-per-card profile, making it suitable for inference clusters where cost control and memory utilization are key constraints.
Summary of Quantitative Positioning
H100: Maximum AI throughput, strongest training performance, highest tokens-per-second under heavy concurrency.
H20: Lower absolute throughput, larger memory headroom, and more flexible inference-oriented deployment characteristics.
These quantitative differences clarify why H100 is favored for large-scale AI training and high-density inference services, while H20 is commonly selected for cost-efficient, memory-driven inference deployments.
Price & Value: H20 vs H100
Price Comparison
From a pricing perspective, the H20 vs H100 comparison reflects a difference in market positioning, rather than a simple price gap. The NVIDIA H100 does not follow a consumer-style MSRP model; its pricing is largely determined by enterprise contracts, server configurations, and deployment scale. As a result, the H100 price sits firmly in the top tier of the data center market, aligning with its leading compute performance and memory bandwidth.
By contrast, the NVIDIA H20 targets a more cost-controlled deployment segment. While it also lacks a public MSRP, the H20 price is generally lower due to reduced compute throughput and a more constrained performance envelope when evaluated in direct H20 vs H100 workloads. This makes H20 more accessible for organizations with tighter budget or compliance requirements.
In practical terms, the price gap mirrors the performance gap. The H100 commands a significantly higher total cost of ownership, justified by faster AI training, better scaling efficiency, and stronger utilization in large, bandwidth-heavy workloads. The H20, meanwhile, trades peak performance for predictable costs, offering a balanced option for AI deployment without the investment level required by H100-class infrastructure.
Overall, the H20 vs H100 pricing discussion is less about value-for-money and more about deployment intent: H100 is priced for maximum performance and density, while H20 is positioned for controlled investment and broader accessibility.
User Value & Performance Feedback: H20 vs H100
Unlike consumer GPUs, the H20 vs H100 comparison does not appear on public gaming benchmark platforms such as UserBenchmark or Technical.City. Instead, user evaluation of the nvidia h20 gpu and nvidia h100 gpu is primarily based on real-world AI deployment factors, including training throughput, scalability, and total cost of ownership.
Across enterprise and data center use cases, feedback consistently shows that the nvidia h100 gpu delivers outstanding performance in large-scale gpu for ai training, driven by its superior memory bandwidth, higher compute density, and strong multi-GPU scaling capabilities. These strengths make H100 the preferred choice for large language model training and multi-node AI clusters, as reflected in its h100 specs and premium positioning.
In contrast, the nvidia h20 gpu is often viewed as a cost-efficient alternative for organizations that do not require extreme-scale performance. Based on its balanced h20 specs, users report solid results in inference workloads, fine-tuning tasks, and small-to-medium AI training jobs. The more accessible h20 price and lower infrastructure requirements further improve its perceived value in budget-controlled or regionally compliant deployments.
Overall, enterprise feedback indicates that the H20 vs H100 decision is driven less by absolute performance rankings and more by workload scale and investment efficiency. While H100 maximizes performance for demanding AI workloads, H20 provides a practical balance of capability and cost for many real-world server environments.
H20 vs H100 – Pros & Cons
| GPU | Pros | Cons |
|---|---|---|
| NVIDIA H20 | ✅ More accessible deployment cost and a comparatively lower h20 price, making it suitable for budget-controlled AI servers ✅ Optimized for AI inference and small-to-medium training workloads, offering stable performance in real-world deployments ✅ Lower power and infrastructure requirements reduce overall operational complexity ✅ Balanced h20 specs fit well in regulated or region-specific environments |
❌ Significantly lower compute scale and memory bandwidth compared to H100 ❌ Limited multi-GPU scaling capability, not ideal for large distributed training ❌ Longer training time for large models due to constrained throughput ❌ Not designed for maximum-performance AI clusters |
| NVIDIA H100 | ✅ Industry-leading performance for large-scale gpu for ai training, driven by extreme compute density and memory bandwidth ✅ Excellent multi-GPU scalability with NVLink support, ideal for enterprise and hyperscale AI clusters ✅ Strong real-world results in large language model training, reflecting the strength of its h100 specs ✅ Future-proof architecture for demanding AI and HPC workloads |
❌ Very high acquisition cost with a premium h100 price ❌ Higher power consumption and cooling requirements increase infrastructure complexity ❌ Overkill for inference or small-scale training workloads ❌ Best value only realized at scale, not cost-efficient for limited deployments |
Deployment & Operations Perspective: H20 vs H100
From an operations and deployment standpoint, the H20 vs H100 comparison highlights two very different approaches to building and managing AI server infrastructure. The H20 is generally easier to deploy within existing data center environments, requiring less aggressive power, cooling, and rack-level planning. This makes it a practical option for teams seeking faster provisioning cycles, simpler maintenance workflows, and predictable operational costs.
In contrast, deploying H100-based servers often involves purpose-built infrastructure designed to support high-density GPU configurations. Power delivery, thermal management, and interconnect planning become critical factors, especially in multi-GPU and multi-node clusters. While this increases operational complexity, it enables superior scalability and sustained performance for large-scale AI training environments.
From a long-term operations perspective, H20 deployments tend to favor flexibility and cost control, allowing organizations to scale gradually as workloads grow. H100 deployments, on the other hand, are optimized for environments where workloads are already well-defined and continuously demand maximum throughput, justifying the higher infrastructure investment with consistent utilization at scale.
Deployment & Operations Comparison: H20 vs H100
| Operations Aspect | NVIDIA H20 | NVIDIA H100 |
|---|---|---|
| Deployment Difficulty | Low to Medium | High |
| Power Planning | Easier to integrate into existing power budgets | Requires high-capacity power planning |
| Cooling Requirements | Standard data center cooling is usually sufficient | Advanced cooling solutions often required |
| Rack Density | Moderate GPU density per rack | High-density GPU configurations |
| Infrastructure Changes | Minimal or incremental | Often requires purpose-built infrastructure |
| Multi-GPU Complexity | Relatively simple to manage | Complex, especially with large GPU clusters |
| Maintenance Overhead | Lower, easier routine operations | Higher, requires experienced operations teams |
| Provisioning Speed | Faster deployment and scaling | Longer planning and deployment cycles |
| Operational Cost Control | Easier to predict and manage | Higher and more variable operational costs |
| Best-Fit Environment | General data centers, budget-conscious deployments | Enterprise and hyperscale AI clusters |
FAQ: H20 vs H100
Is H100 always better than H20?
No. While H100 delivers significantly higher performance, it is designed for large-scale AI training and high-density deployments. For inference workloads or moderate training tasks, H20 often provides sufficient performance with lower cost and simpler operations.
Which GPU is better for AI inference, H20 or H100?
H20 is typically the more practical choice for AI inference. It offers balanced performance with lower power consumption and infrastructure requirements, whereas H100 may be underutilized in inference-heavy environments.
Can H20 be used for AI training?
Yes. H20 can handle small-to-medium training jobs and fine-tuning tasks. However, it is not optimized for large distributed training or very large models, where H100 clearly excels.
What type of workloads justify choosing H100?
H100 is best suited for large language model training, multi-node AI clusters, and workloads that require maximum throughput, fast convergence, and strong multi-GPU scalability.
Is H100 cost-effective for small teams or startups?
In most cases, no. The higher acquisition cost, power consumption, and operational complexity of H100 make it less cost-effective for small teams unless their workloads consistently demand its full performance.
Which GPU is easier to deploy and maintain?
H20 is generally easier to deploy and maintain. It integrates more smoothly into existing data center environments, while H100 often requires advanced power, cooling, and infrastructure planning.
How should I choose between H20 and H100?
Choose H20 if your priority is cost control, operational simplicity, and inference-focused workloads. Choose H100 if you require maximum training performance, large-scale scalability, and long-term high utilization.
Does choosing H100 reduce training time significantly?
Yes. For large-scale training workloads, H100 can substantially reduce training time. Whether this justifies the higher cost depends on how time-sensitive your projects are.
Is it possible to start with H20 and upgrade later?
Yes. Many organizations begin with H20 for early-stage workloads and transition to higher-performance GPUs like H100 as their models and infrastructure requirements grow.
Conclusion
When viewed from a full-system and decision-making perspective, the H20 vs H100 comparison is ultimately about workload maturity, infrastructure readiness, and return on investment, rather than absolute performance alone. Both GPUs are built for data center environments, but they serve distinctly different stages of AI deployment.
The H20 stands out as a practical and accessible option for organizations running inference-focused workloads, fine-tuning models, or early-stage training tasks. Its balanced performance profile, lower operational complexity, and more manageable deployment requirements make it well suited for teams that value flexibility, predictable costs, and efficient resource utilization. In many real-world scenarios, H20 delivers performance that is “right-sized” for the task, avoiding the risks and overhead of overprovisioning.
The H100, on the other hand, is designed for environments where AI workloads are already operating at scale and performance directly translates into time and business value. Its strengths are fully realized in large language model training, multi-GPU clusters, and high-throughput workflows that demand maximum scalability and sustained compute power. While it requires greater upfront investment and more sophisticated infrastructure planning, H100 enables faster training cycles and long-term performance headroom for advanced AI initiatives.
In summary, choosing between H20 and H100 is less about which GPU is superior, and more about aligning hardware capability with workload demands and operational strategy. H20 offers a cost-efficient, deployment-friendly path for many production AI use cases, while H100 remains the optimal choice for performance-critical, large-scale GPU for AI training environments where scale and speed are decisive factors.
While Database Mart doesn't currently offer H20 GPU servers, it provides a wide range of GPU servers, including the H100 GPU server, covering different performance levels and price points. From low-end to high-end configurations, users can choose the appropriate server for their needs, whether for artificial intelligence, deep learning, rendering, or general GPU workloads. We offer scalable single-GPU or multi-GPU configurations, 99.9% uptime, and 24/7 professional support, allowing you to focus on your project without worrying about hardware management.
h20 vs h100, nvidia h20 gpu, h20, h100, nvidia h100 gpu, h20 specs, h100 specs, h20 price, h100 price, gpu for ai training