

Tesla V100 vs RTX 4090: Two GPUs Built for Very Different Worlds
Tesla V100 and RTX 4090 are both powerful NVIDIA GPUs, but they target very different users. In this guide, we break down specs, benchmarks, performance, and pricing to help gamers, creators, developers, and AI professionals understand which GPU actually fits their workloads.
Tesla V100 vs RTX 4090 – Background Comparison
| Brand | Series | Model | Release Year | Official Positioning / Description | Market Price (USD) |
|---|---|---|---|---|---|
| NVIDIA | Tesla | V100 16GB / 32GB | 2017 | Data center GPU designed for AI training, HPC, and scientific computing workloads | $800–$2,000 (used/refurbished) |
| NVIDIA | GeForce RTX | RTX 4090 24GB | 2022 | Flagship consumer GPU for high-end gaming, content creation, and AI compute tasks | $1,600–$2,000 |
Summary Highlights
Tesla V100: Enterprise-grade data center GPU optimized for long-duration AI training, HPC workloads, and stable multi-GPU environments.
RTX 4090: Modern consumer GPU delivering massive raw compute power, widely used for gaming, rendering, and single-node AI training or inference.
Key Difference: V100 focuses on reliability, ECC memory, and data center scalability, while RTX 4090 prioritizes peak performance, newer architecture, and desktop flexibility.
Value Insight: RTX 4090 often offers superior performance-per-dollar for individual users and developers, whereas Tesla V100 remains relevant in legacy data center and enterprise AI setups.
Tesla v100 vs RTX 4090 – Specifications Comparison
Core Specs Comparison
| Specification | NVIDIA Tesla V100 | NVIDIA RTX 4090 | Difference / Advantage |
|---|---|---|---|
| Architecture | Volta | Ada Lovelace | RTX 4090 has newer, more efficient architecture → better for modern workloads; V100 optimized for HPC stability |
| CUDA Cores | 5,120 | 16,384 | RTX 4090 has ~ 220% more CUDA cores → higher parallel throughput |
| Memory Type | HBM2 | GDDR6X | V100’s HBM2 offers higher bandwidth per watt and ECC; 4090’s GDDR6X is cheaper and higher clock |
| Memory Capacity (vRAM) | 16 GB / 32 GB | 24 GB | 4090 has 50% more memory than 16 GB V100, but V100 32 GB variant is higher capacity |
| Memory Bus | 4096‑bit | 384‑bit | V100 has ~ 10.7× wider memory bus → higher raw bandwidth potential; 4090 optimized for consumer workloads |
| Memory Bandwidth | 897 GB/s | 1008 GB/s | RTX 4090 has ~12% higher peak memory bandwidth |
| Core Frequency (Boost) | 1380 MHz | 2520 MHz | RTX 4090 has ~ 83% higher boost clock → stronger single-thread performance |
| TDP (Power) | 250–300 W | 450 W | V100 is more power-efficient; 4090 consumes ~ 50–80% more power for higher peak performance |
| Interface / Bus | PCIe 3.0 x16 (NVLink support) | PCIe 4.0 x16 | RTX 4090 supports newer PCIe → faster host bandwidth; V100 supports NVLink for multi-GPU setups |
| FP32 Performance | 14–15.7 TFLOPS | 82.6 TFLOPS | RTX 4090 ~5× higher FP32 performance |
| Ray Tracing / Tensor Cores | 640 Tensor, no RT cores | 512 Tensor, 128 RT cores | RTX 4090 wins for ray tracing & modern AI; V100 has more Tensor cores but lacks RT units |
| PCIe Version | Gen3 | Gen4 | RTX 4090 supports Gen4 → higher bandwidth to CPU/host |
The RTX 4090 clearly outperforms the Tesla V100 in CUDA cores (+220%), FP32 performance (~5× higher), boost clock (+83%), and memory bandwidth (+12%), making it ideal for gaming, creative work, and AI inference.
In contrast, the Tesla V100 excels in power efficiency, ECC memory support, and multi-GPU scaling via NVLink, making it the preferred choice for HPC, scientific computing, and large-scale AI training.
Overall, the 4090 is optimized for modern consumer and AI workloads, while the V100 remains strong for data-center and professional HPC tasks.
Advanced Features
| Specification | NVIDIA Tesla V100 | NVIDIA RTX 4090 | Difference / Advantage |
|---|---|---|---|
| FP64 Performance | ~7.8 TFLOPS | ~2.6 TFLOPS | V100 far superior for double-precision scientific/HPC workloads |
| L2 Cache | 6 MB | 96 MB | RTX 4090 has 16× larger L2 cache → better throughput for gaming/AI inference |
| VR / Display Outputs | None | 1× HDMI 2.1 + 3× DP 1.4a | RTX 4090 supports displays and VR; V100 is compute-only |
| Multi-GPU Support | NVLink (up to 8 GPUs) | Not supported | V100 can scale in HPC clusters; 4090 designed for single-GPU use |
| CUDA Compute Capability | 7.0 | 8.9 | RTX 4090 supports newer CUDA features → better compatibility with modern AI frameworks |
| AI / Advanced Features | Tensor cores only, optimized for FP16/FP32 | Tensor cores + RT cores + DLSS/AI acceleration | RTX 4090 supports modern AI inference, ray tracing, and DLSS; V100 optimized for HPC training |
| Thermal / Cooling | Passive / server blade | Active blower / desktop | V100 requires server cooling; 4090 suitable for high-end desktop/workstation |
Key Takeaway
The Tesla V100 stands out for double-precision performance (FP64) and multi-GPU scalability via NVLink, making it ideal for HPC, scientific computing, and large-scale AI training.
The RTX 4090, on the other hand, excels in L2 cache size, modern AI features (RT cores, DLSS), display/VR support, and newer CUDA capabilities, making it perfect for gaming, creative workloads, AI inference, and desktop workstations.
In short, V100 is optimized for data-center and professional computing, while 4090 is tailored for consumer/prosumer and modern AI workloads.
Tesla v100 vs RTX 4090 benchmarks Across Different Scenarios
V100 vs 4090 for AI Training / HPC Performance
In AI training and HPC workloads, the RTX 4090 delivers a significant performance advantage in mainstream deep learning precision. Under single-GPU theoretical benchmarks, the RTX 4090 provides ~ 5.9× higher FP32 throughput and ~ 2.9× higher FP16 throughput compared to the Tesla V100. However, the Tesla V100 maintains a clear edge in scientific computing, offering ~ 5.5× higher FP64 performance, which remains critical for traditional HPC and precision-sensitive simulations. This highlights a fundamental trade-off between raw AI training speed and double-precision compute capability.
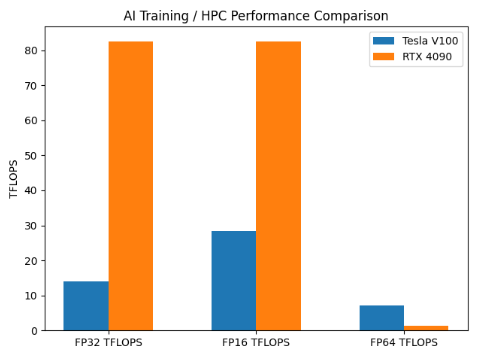
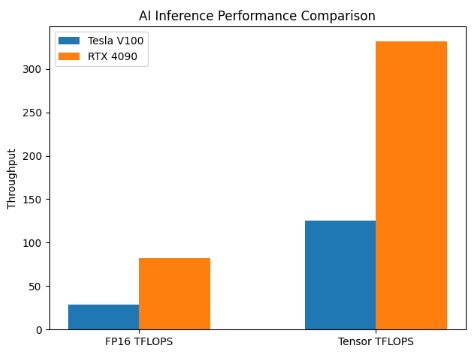
V100 vs 4090 AI Inference
For AI inference workloads, the RTX 4090 shows a decisive advantage in throughput-oriented metrics. Based on FP16 and Tensor Core performance, the RTX 4090 delivers approximately 2.7–3× higher inference potential than the Tesla V100. In real-world deployment scenarios such as large language model inference, this typically translates into 2–3× higher tokens-per-second, making the RTX 4090 better suited for real-time AI services, chatbots, and latency-sensitive inference pipelines.
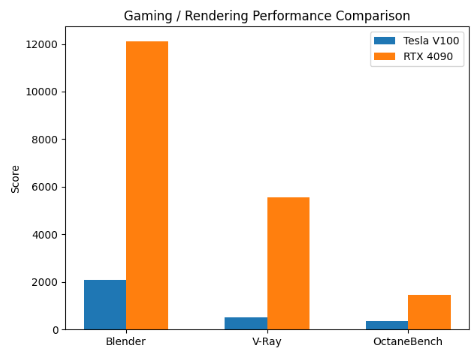
Gaming / Creative / Rendering Performance
In graphics and creative workloads, the RTX 4090 outperforms the Tesla V100 by a wide margin. In Blender Cycles, it achieves ~ 480% higher performance, while in V-Ray it delivers over 1,000% higher performance. OctaneBench results show a ~ 300% performance lead for the RTX 4090. These figures demonstrate that the RTX 4090 is optimized for modern rendering, content creation, and gaming, whereas the Tesla V100 is not designed for graphics-centric tasks.
Tesla V100 vs RTX 4090: Price & Value
| Platform | Tesla V100 (USD) | RTX 4090 (USD) | Price Difference (USD) | Price Difference (%) |
|---|---|---|---|---|
| Official MSRP | ~$10,600 – $11,500 | $1,599 | +$9,000 – $9,900 | +560% – 620% |
| Amazon | $2,500 – $4,500 | $1,700 – $2,200 | +$800 – $2,800 | +36% – 165% |
| Third-Party Resellers (eBay etc.) | $1,800 – $3,500 | $1,500 – $2,100 | +$300 – $2,000 | +15% – 130% |
As GPUs built for different markets, the Tesla V100 and RTX 4090 differ sharply in price and value. At launch, the Nvidia V100 price is over 6× higher, reflecting its focus on enterprise reliability, FP64 performance, and multi-GPU scalability. The RTX 4090, in contrast, delivers far stronger price-to-performance for modern AI workloads, content creation, and graphics-intensive tasks, making it the better value choice for most users today.
V100 vs 4090 – Pros & Cons
| GPU | Pros | Cons |
|---|---|---|
| Tesla V100 | - Excellent FP64 performance for HPC & scientific computing - Large memory capacity (up to 32 GB HBM2) - ECC memory & NVLink for multi-GPU scalability - Stable & reliable for data-center workloads |
- No display outputs / not suitable for gaming - Older architecture (Volta) → lower FP32/mixed precision performance - Lower single-card FP32 throughput compared to modern consumer GPUs - Higher cost for HPC deployment |
| RTX 4090 | - Extremely high FP32 & mixed-precision performance - Dedicated RT cores & Tensor cores for AI, DLSS, ray tracing - Modern Ada Lovelace architecture → better efficiency - Supports gaming, creative workloads, VR, and desktop AI inference - Lower cost for comparable FP32 AI performance |
- Less suitable for FP64/scientific computing - No NVLink → limited multi-GPU scaling - High power consumption (450 W) - Smaller effective memory for very large datasets compared to V100 32 GB |
Tesla V100 vs RTX 4090 Server Hosting
The Tesla V100 and RTX 4090 are popular choices for server hosting. To save costs, some providers offer them through shared cloud instances, which can reduce performance. For clients running AI training, inference, or HPC workloads, a dedicated V100 or RTX 4090 server is the better option.
Database Mart provides V100 and RTX 4090 server hosting, from single-GPU to multi-GPU configurations. Their servers use high-quality hardware to deliver a strong balance of performance and reliability. With years of proven experience, Database Mart is a trusted provider for businesses seeking enterprise-grade GPU solutions.
Conclusion
The choice between the Tesla V100 and RTX 4090 GPU depends on the workload. The V100 excels in HPC, scientific computing, and large-scale AI training with FP64 performance, ECC memory, and NVLink multi-GPU support, making it ideal for data-center and enterprise environments. The RTX 4090, on the other hand, shines in gaming, creative work, AI inference, and desktop AI training, offering high FP32 and mixed-precision throughput, Tensor and RT cores, and modern architecture for real-time performance. Understanding their strengths ensures you select the GPU best suited to your needs—V100 for precision and scalability, 4090 for speed and versatility.
v100 vs 4090, tesla v100 vs rtx 4090, 4090 gpu, v100 gpu, nvidia v100 price, nvidia rtx4090 price, RTX 4090 benchmarks, 4090 specs, tesla v100, nvidia tesla v100