
























Evaluation: Performance of Running LLMs with Ollama on Nvidia A40 GPU Server
As large language models (LLMs) continue to advance, researchers and enterprises increasingly seek high-performance hardware for hosting and running these models. This report evaluates the performance of Nvidia A40 GPUs when running LLMs with the Ollama platform, offering detailed analysis and insights from practical data.
Test Environment and Configuration
Server Configuration:
- CPU: Dual 18-Core E5-2697v4 (36 cores, 72 threads)
- RAM: 256GB
- Storage: 240GB SSD + 2TB NVMe + 8TB SATA
- Network: 100Mbps-1Gbps connection
- OS: Windows 11 Pro
GPU Details:
- GPU: Nvidia A40
- Compute Capability: 8.6
- Microarchitecture: Ampere
- CUDA Cores: 10,752
- Tensor Cores: 336
- GPU Memory: 48GB GDDR6
- FP32 Performance: 37.48 TFLOPS
With ultra-high vRAM(48GB) ensures that the A40 Server can run 70b models.
LLMs Reasoning Tested on Ollama with A40
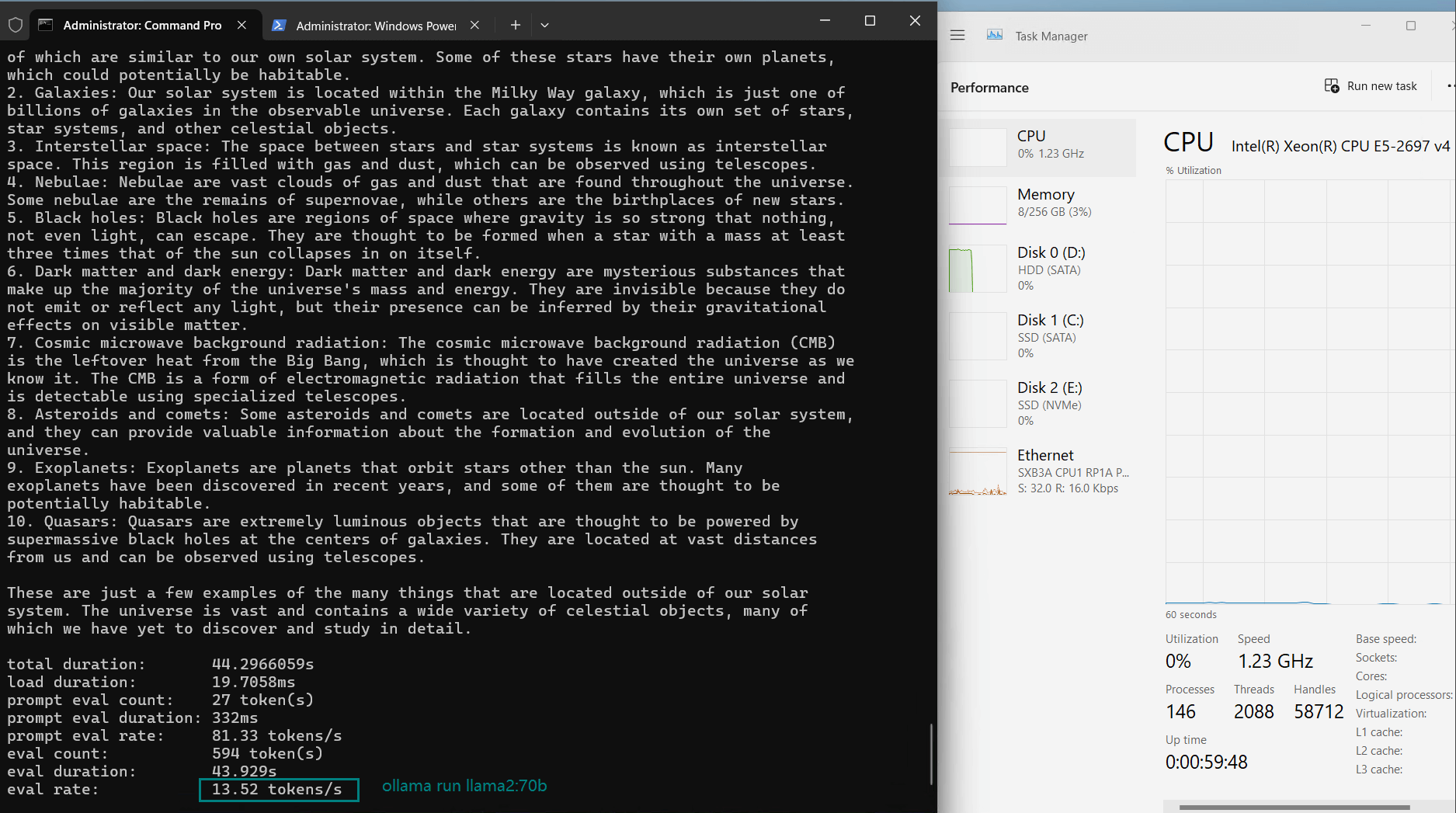
- Llama2 (70B)
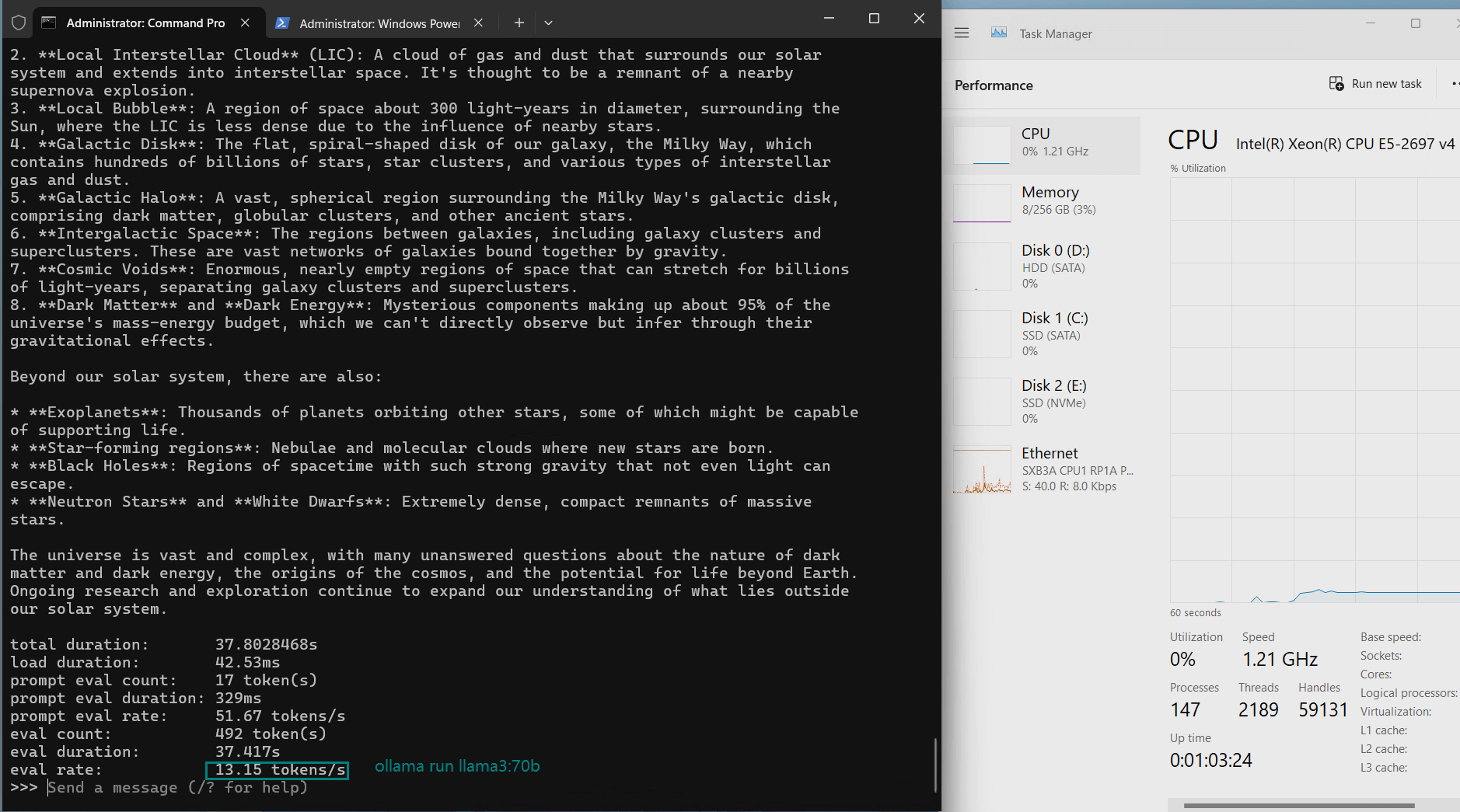
- Llama3 (70B)
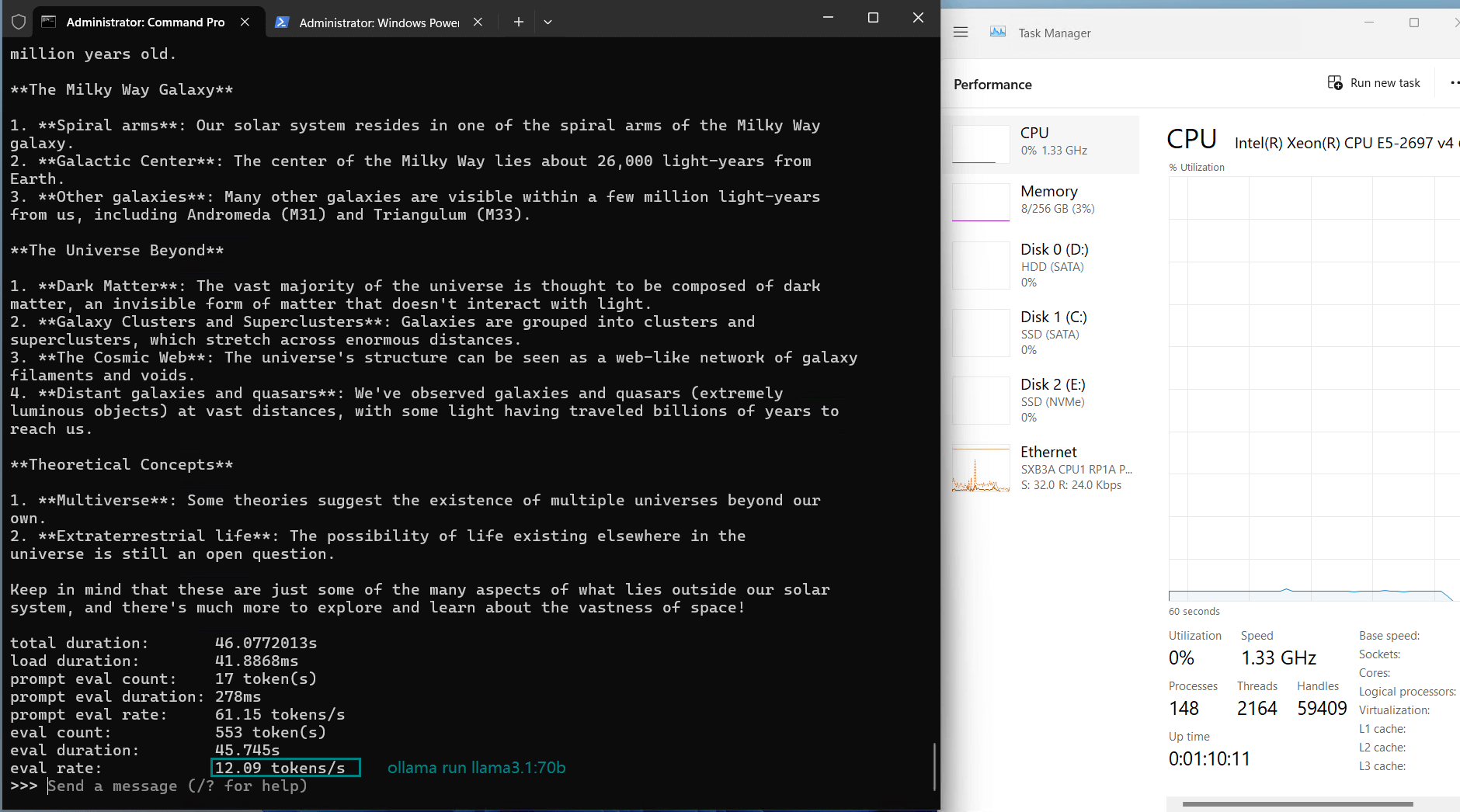
- Llama3.1 (70B)
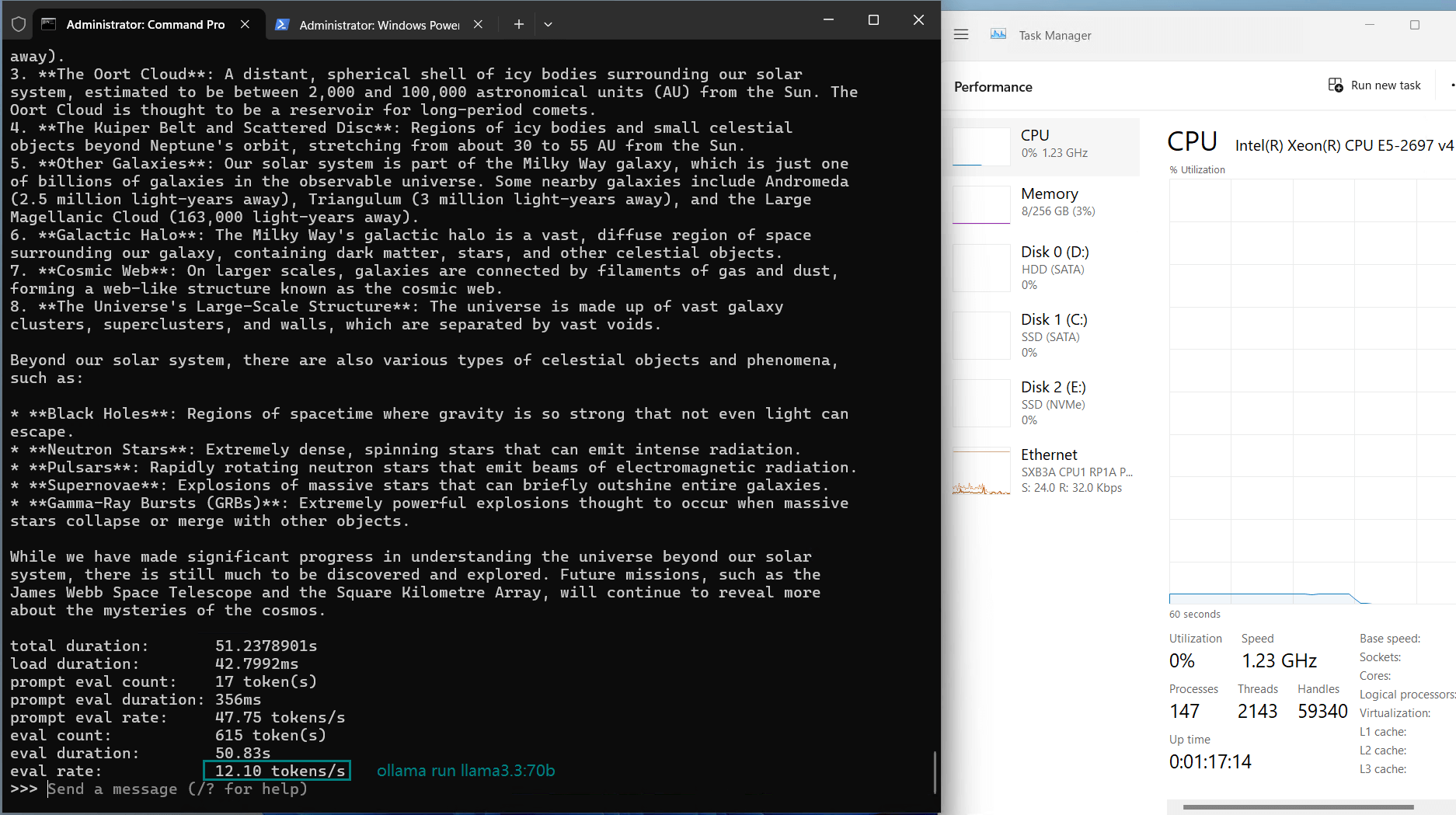
- Llama3.3 (70B)
- Qwen (32B, 72B)
- Qwen2.5 (14B, 32B, 72B)
- Gemma2 (27B)
- Llava (34B)
- QWQ (32B)
Benchmark Results: Ollama GPU A40 Performance Metrics
| Models | llama2 | llama3 | llama3.1 | llama3.3 | qwen | qwen | qwen2.5 | qwen2.5 | qwen2.5 | gemma2 | llava | qwq |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Parameters | 70b | 70b | 70b | 70b | 32b | 72b | 14b | 32b | 72b | 27b | 34b | 32b |
| Size | 39GB | 40GB | 43GB | 43GB | 18GB | 41GB | 9GB | 20GB | 47GB | 16GB | 19GB | 20GB |
| Quantization | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Running on | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 |
| Downloading Speed(mb/s) | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| CPU Rate | 2% | 2% | 3% | 2% | 3% | 17-22% | 2% | 2% | 30-40% | 3% | 3% | 2% |
| RAM Rate | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 4% |
| GPU UTL | 98% | 94% | 94% | 94% | 90% | 66% | 83% | 92% | 42-50% | 89% | 94% | 90% |
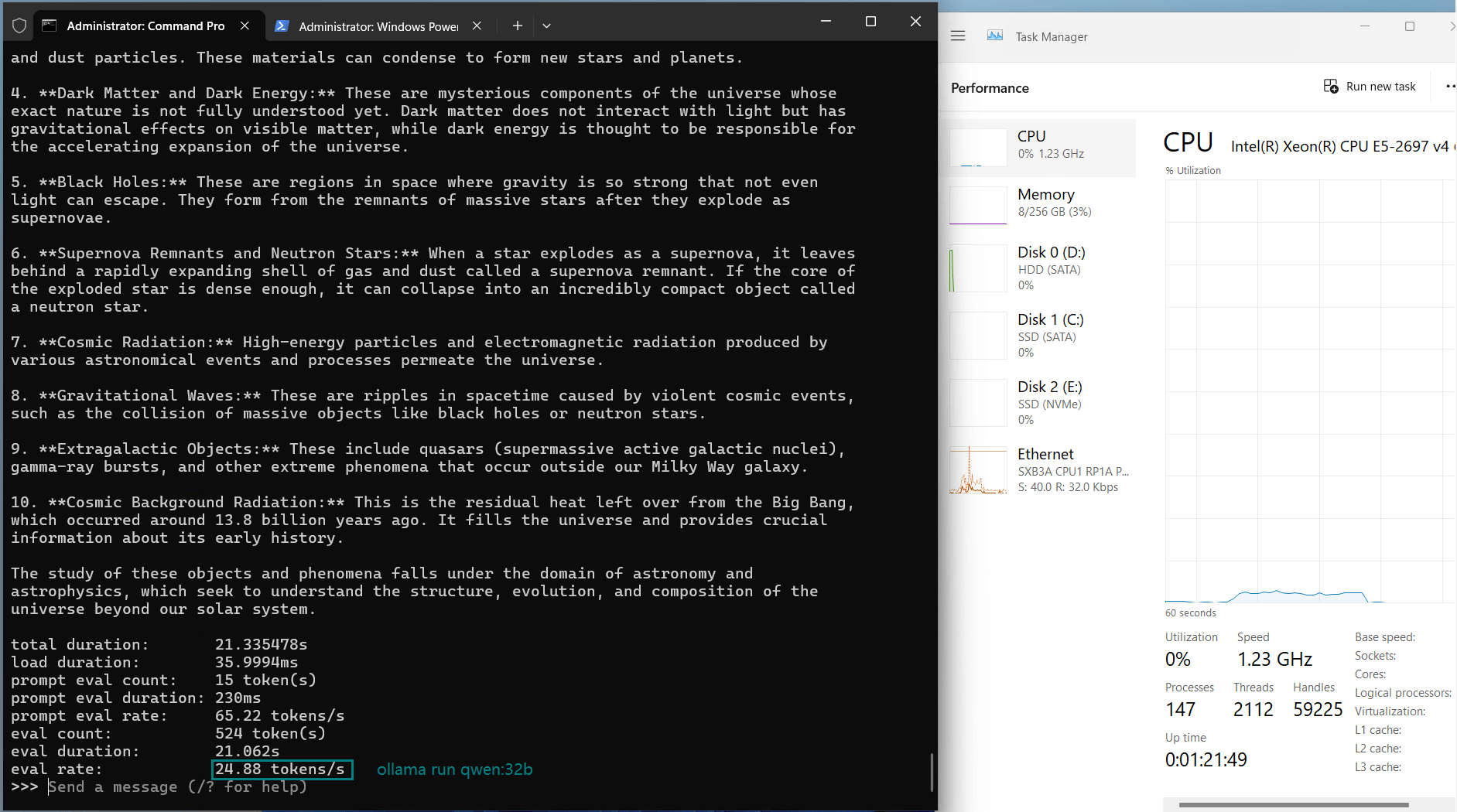
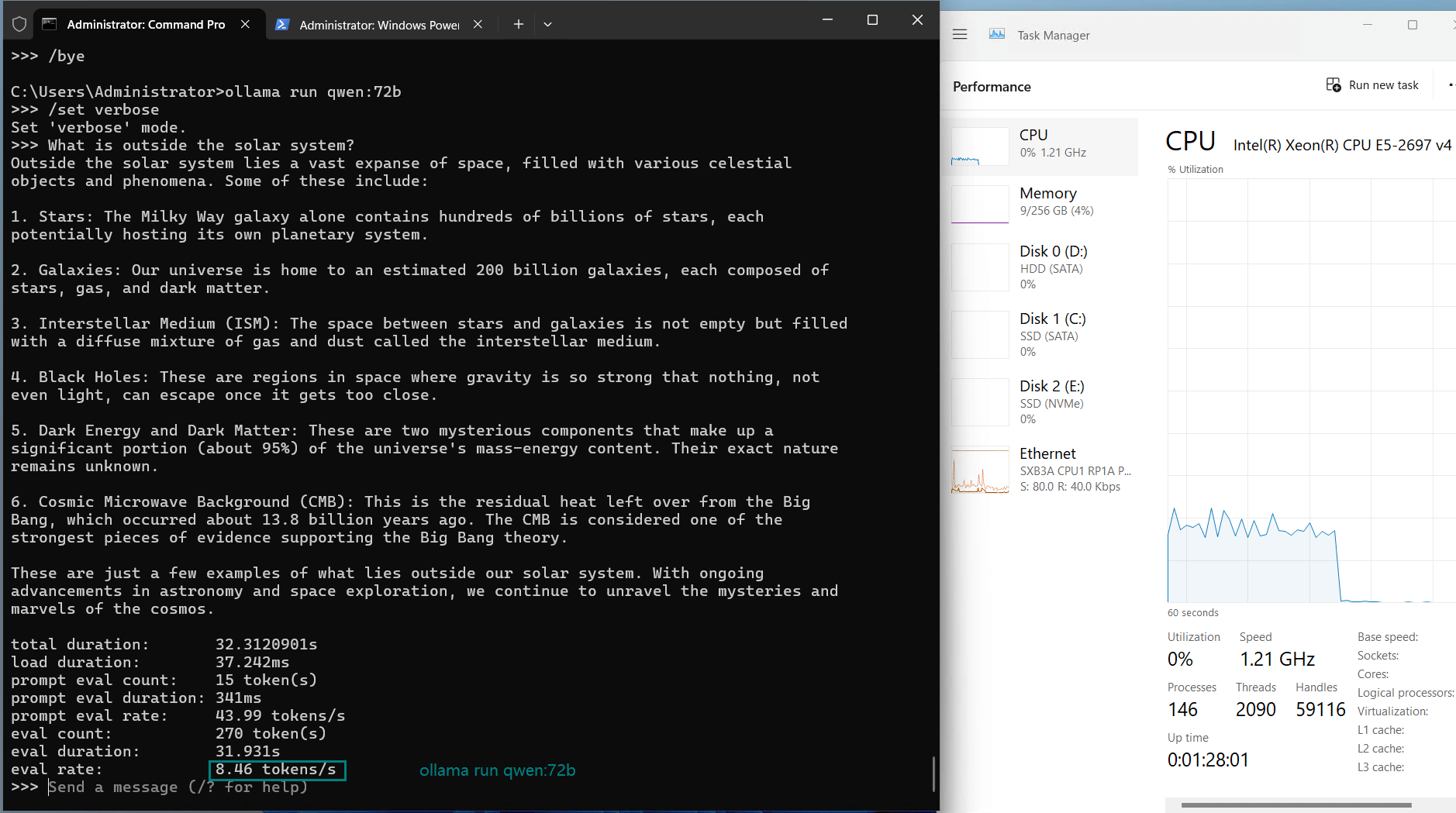
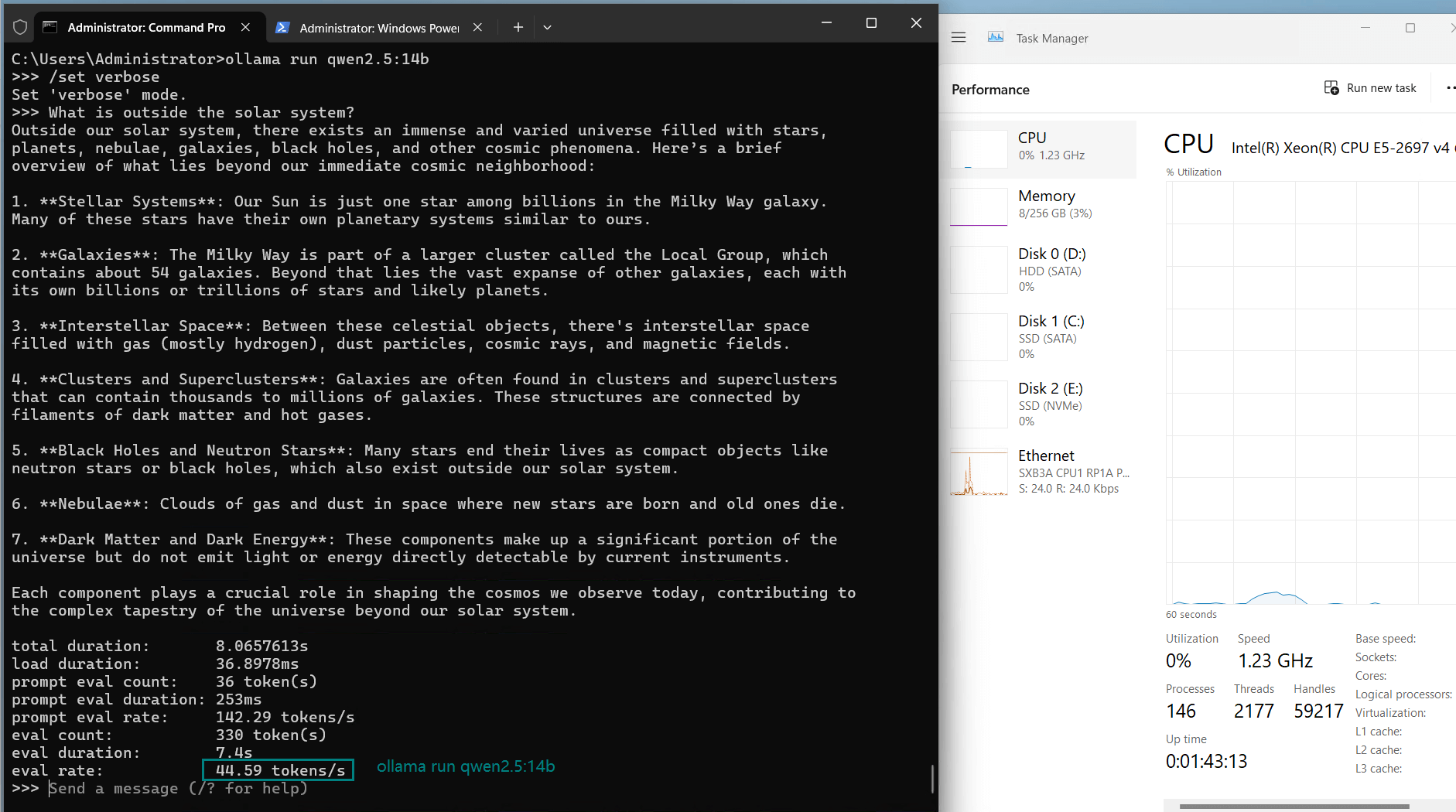
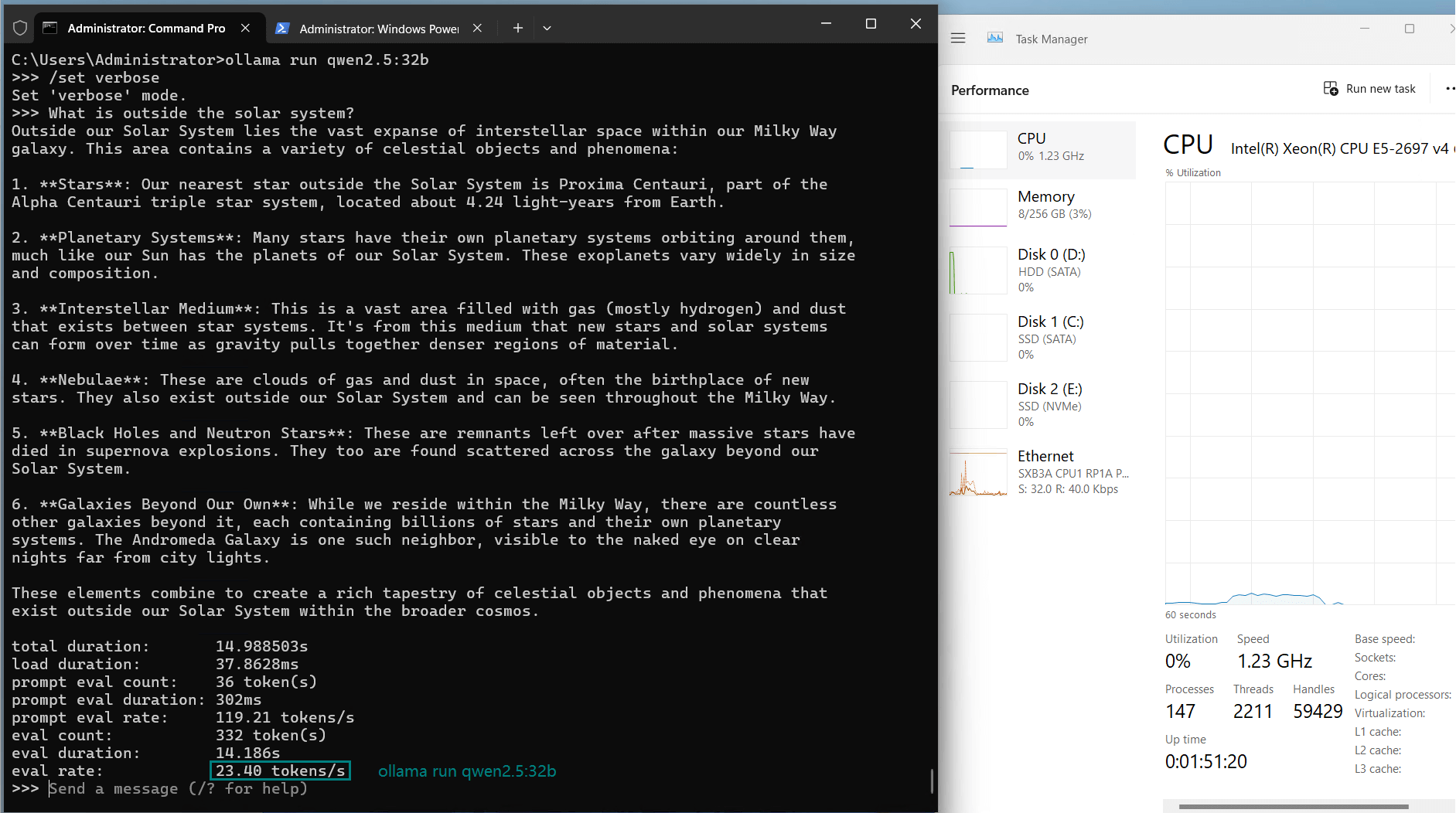
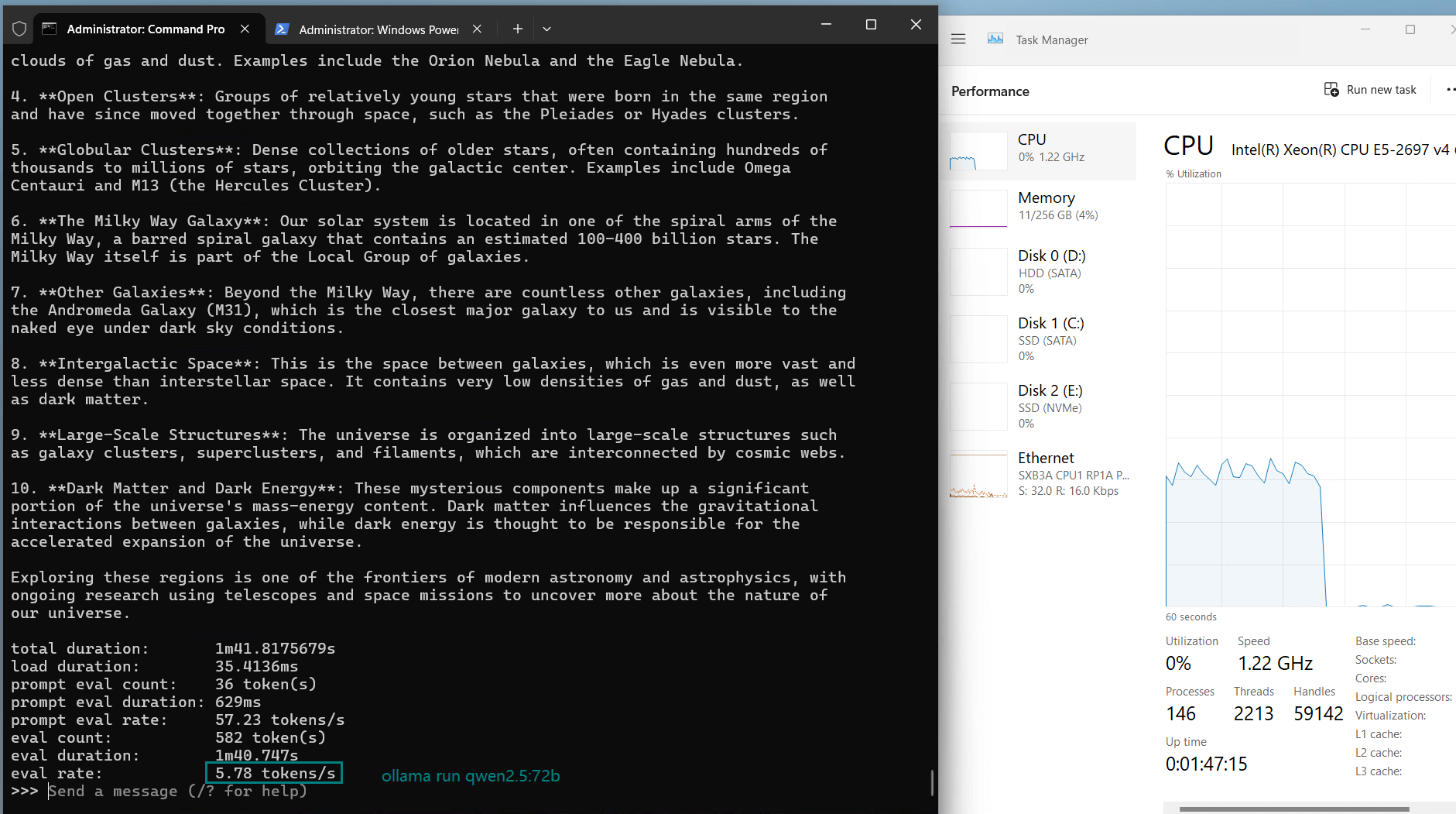
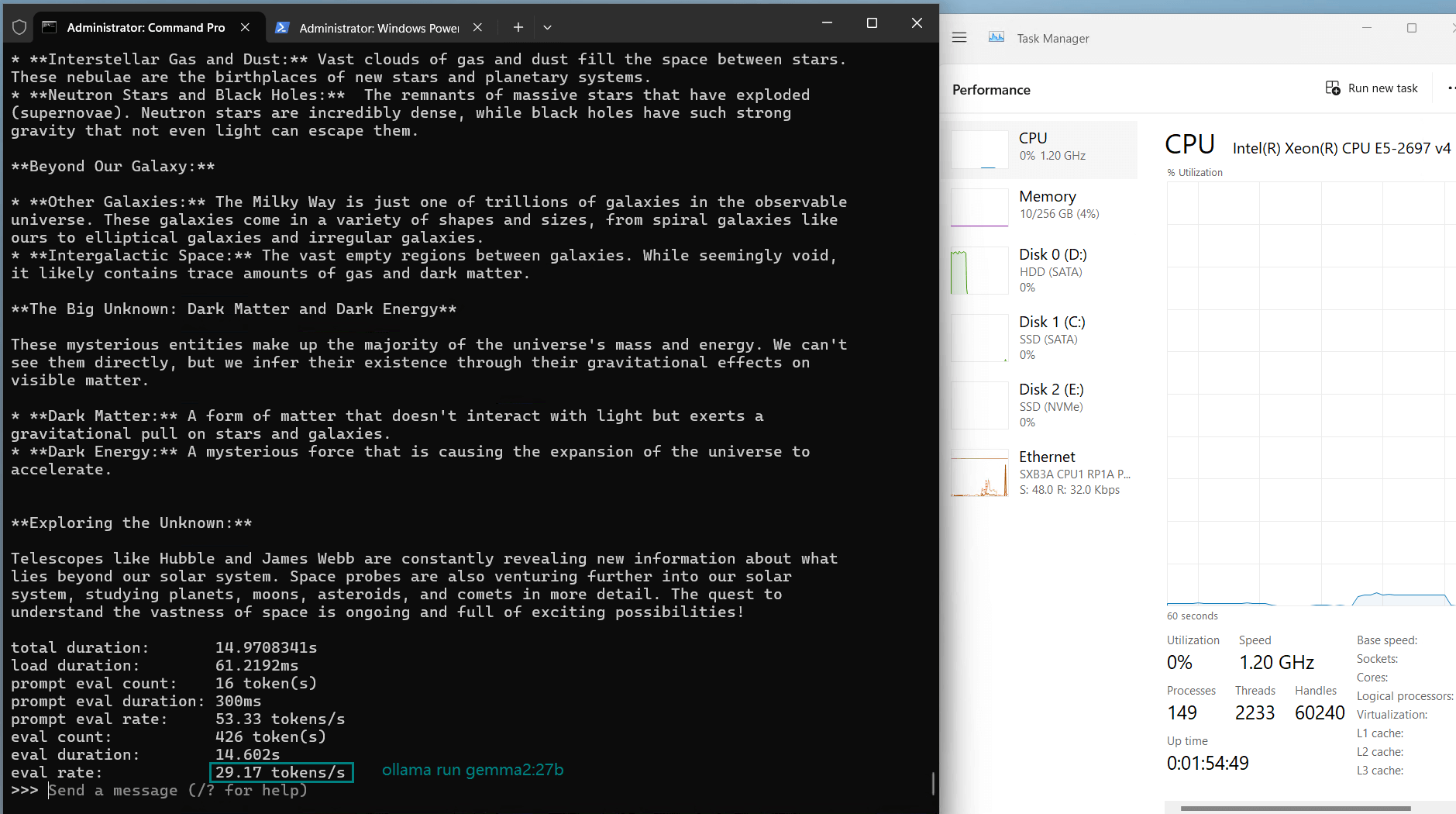
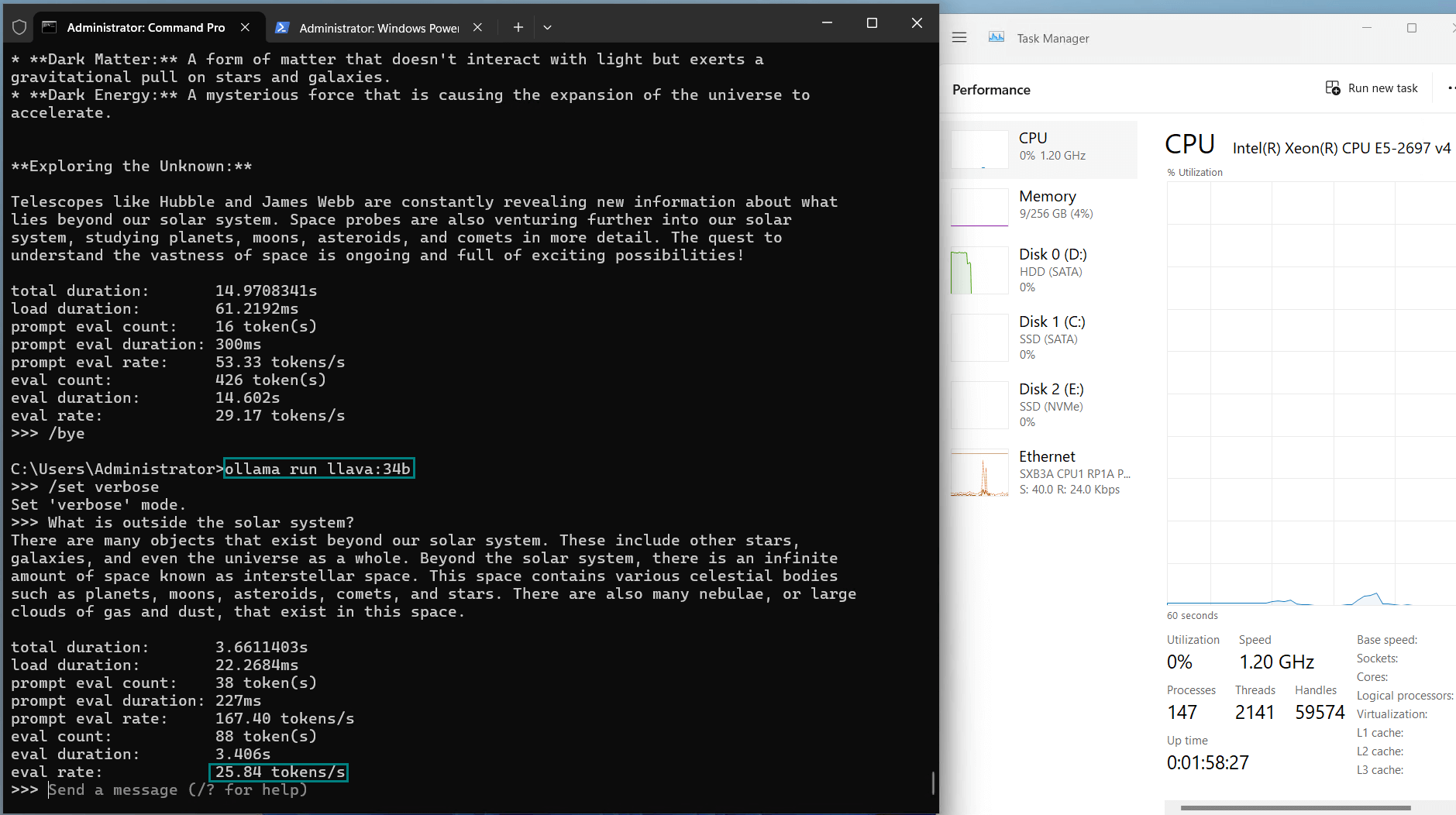
| Eval Rate(tokens/s) | 13.52 | 13.15 | 12.09 | 12.10 | 24.88 | 8.46 | 44.59 | 23.04 | 5.78 | 29.17 | 25.84 | 23.11 |
Key Insights
1. Upper Limits of A40's Processing Capability
However, for models like Qwen:72b, despite sufficient memory, the evaluation rate dropped significantly to 8.46 tokens/s, indicating the GPU's performance ceiling. This suggests that the A40 is not ideal for sustained operations of ultra-large models (72b or higher).
2. Performance on Medium-Scale Models: 32b-34b
- GPU utilization: Stable at 90%-94%
- Evaluation rate: 23-26 tokens/s
3. High Efficiency for Small Models
- GPU utilization: 42%-83%
- Evaluation rate: 44.59 tokens/s
Advantages of Nvidia A40
1. Efficient Memory Management
2. High Inference Performance
3. Versatile Adaptability
Limitations and Recommendations
1. Limited Support for Ultra-Large Models
2. Network Bottleneck
Comparison: Nvidia A40 vs A6000
Both the Nvidia A40 and Nvidia A6000 come equipped with 48GB of VRAM, making them capable of running models up to 70 billion parameters with similar performance. In practical scenarios, these GPUs are nearly interchangeable for tasks involving models like LLaMA2:70b, with evaluation rates and GPU utilization showing minimal differences.
However, when it comes to models exceeding 72 billion parameters, neither the A40 nor the A6000 can maintain sufficient evaluation speed or stability. For such ultra-large models, GPUs with higher memory capacities, such as the A100 80GB or the H100, are highly recommended. These GPUs offer significantly better memory bandwidth and compute capabilities, ensuring smooth performance for next-generation LLMs.
The A100 80GB is a particularly cost-effective choice for hosting multiple large models simultaneously, while the H100 represents the pinnacle of performance for AI workloads, ideal for cutting-edge research and production.
Enterprise GPU Dedicated Server - A40
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia A40
- Microarchitecture: Ampere
- CUDA Cores: 10,752
- Tensor Cores: 336
- GPU Memory: 48GB GDDR6
- FP32 Performance: 37.48 TFLOPS
- Ideal for hosting AI image generator, deep learning, HPC, 3D Rendering, VR/AR etc.
Enterprise GPU Dedicated Server - RTX 4090
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: GeForce RTX 4090
- Microarchitecture: Ada Lovelace
- CUDA Cores: 16,384
- Tensor Cores: 512
- GPU Memory: 24 GB GDDR6X
- FP32 Performance: 82.6 TFLOPS
- Perfect for 3D rendering/modeling , CAD/ professional design, video editing, gaming, HPC, AI/deep learning.
Enterprise GPU Dedicated Server - RTX A6000
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia Quadro RTX A6000
- Microarchitecture: Ampere
- CUDA Cores: 10,752
- Tensor Cores: 336
- GPU Memory: 48GB GDDR6
- FP32 Performance: 38.71 TFLOPS
- Optimally running AI, deep learning, data visualization, HPC, etc.
Multi-GPU Dedicated Server- 2xRTX 4090
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 1Gbps
- OS: Windows / Linux
- GPU: 2 x GeForce RTX 4090
- Microarchitecture: Ada Lovelace
- CUDA Cores: 16,384
- Tensor Cores: 512
- GPU Memory: 24 GB GDDR6X
- FP32 Performance: 82.6 TFLOPS
Conclusion: How Well Does Nvidia A40 Perform for LLMs?
Overall, the Nvidia A40 is a highly cost-effective GPU, especially for medium-sized and small LLM inference tasks. Its 48GB VRAM enables stable support for models up to 70b parameters, with evaluation rates reaching 13 tokens/s, while achieving even better results with 32b-34b models.
If you're looking for a GPU server to host LLMs, the Nvidia A40 is a strong candidate. It delivers excellent performance at a reasonable cost, making it suitable for both model development and production deployment.
A40 benchmark, Nvidia A40, Ollama benchmark, LLM A40, A40 test, A40 GPU, Nvidia A40 GPU, A40 hosting, A40 vs A6000, LLM hosting, Nvidia A40 server, A100 vs A40, H100 vs A40, Ollama A40