
























Benchmarking LLMs on Ollama with Dual Nvidia A100 GPUs(Total 80GB): Best Choice for 70B~110B Models
When it comes to running Large Language Models (LLMs), having the right server configuration is crucial to balance performance and cost. In this article, we explore the performance of running LLMs on Ollama using dual Nvidia A100 GPUs. Specifically, we will examine the ability of the A100*2 setup to handle models ranging from 70B to 110B parameters, including popular models like DeepSeek-R1, Qwen, and LLaMA.
This setup is priced at $1399/month and offers a solid performance-to-cost ratio for AI projects requiring large-scale computations. Let's dive into the benchmark results to understand how dual A100 GPUs handle these demanding tasks.
Server Configuration: Dual Nvidia A100 GPUs
Server Configuration:
- Price: $1399/month
- CPU: Dual 18-Core E5-2697v4 (36 cores & 72 threads)
- RAM: 256GB RAM
- Storage: 240GB SSD + 2TB NVMe + 8TB SATA
- Network: 1Gbps
- OS: Windows 10 Pro
GPU Details:
- GPU: Dual Nvidia A100
- Microarchitecture: Ampere
- Compute Capability:8.0
- CUDA Cores: 6912 per card
- Tensor Cores: 432
- Memory: 40GB HBM2 per card
- FP32 Performance: 19.5 TFLOPS per card
The dual A100 GPUs provide a combined 80GB of GPU memory, ideal for running large language models efficiently. This configuration allows us to process models with parameter counts as high as 110B with reasonable speed and efficiency.
👉 Benchmarking LLMs with Dual A100 GPUs
| Models | deepseek-r1 | deepseek-r1 | deepseek-r1 | qwen | qwen | qwen | qwen2 | llama3 | llama3.1 | llama3.3 | gemma3 | gemma3 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Parameters | 14b | 32b | 70b | 32b | 72b | 110b | 72b | 70b | 70b | 70b | 12b | 27b |
| Size(GB) | 9 | 20 | 43 | 18 | 41 | 63 | 41 | 40 | 43 | 43 | 8.1 | 17 |
| Quantization | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Running on | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.6.5 | Ollama0.6.5 |
| Downloading Speed(mb/s) | 117 | 117 | 117 | 117 | 117 | 117 | 117 | 117 | 117 | 117 | 117 | 117 |
| CPU Rate | 0% | 2% | 3% | 2% | 1% | 1% | 1% | 2% | 1% | 1% | 1% | 1% |
| RAM Rate | 4% | 4% | 4% | 4% | 4% | 4% | 4% | 3% | 4% | 3% | 4% | 4% |
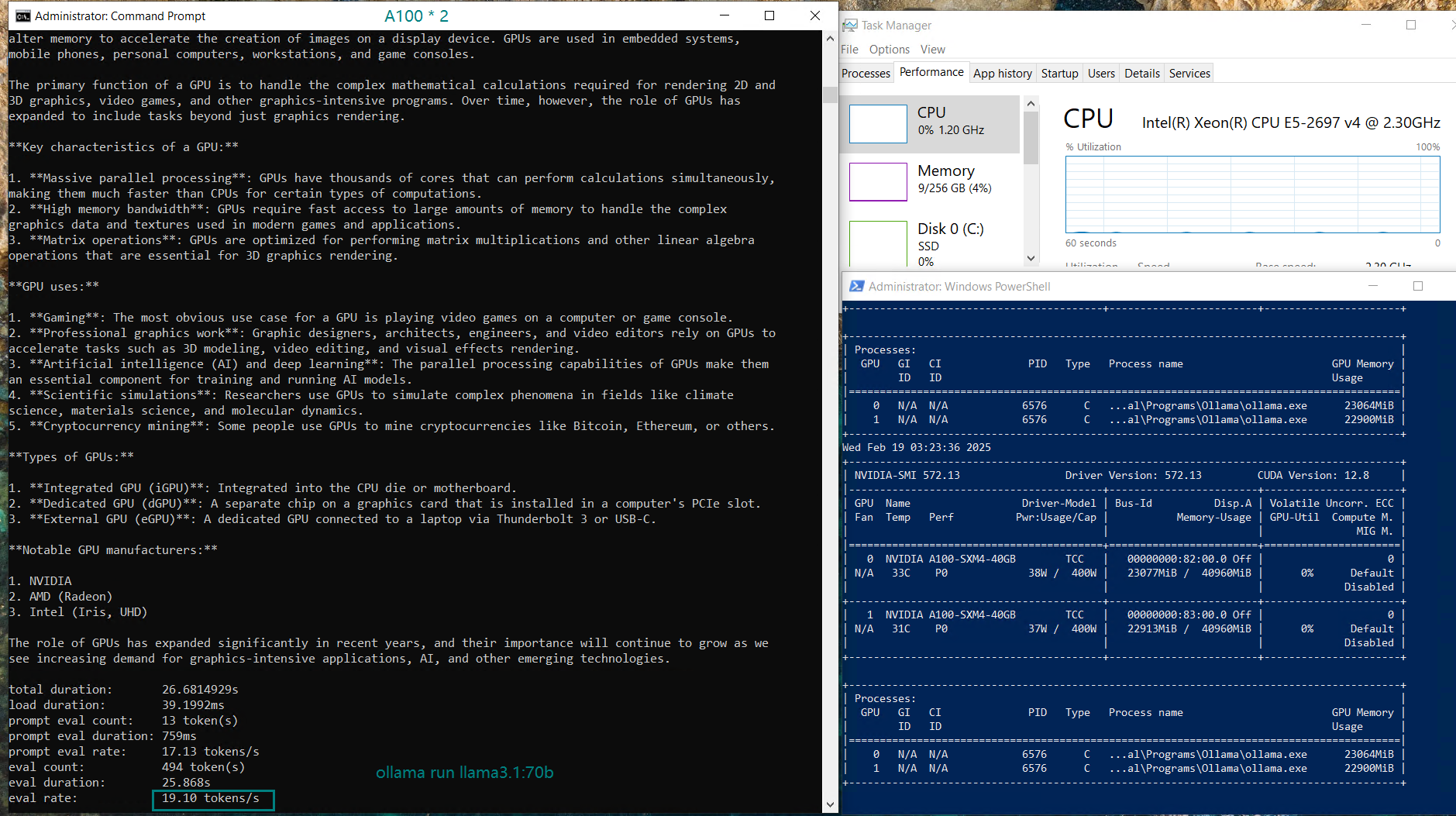
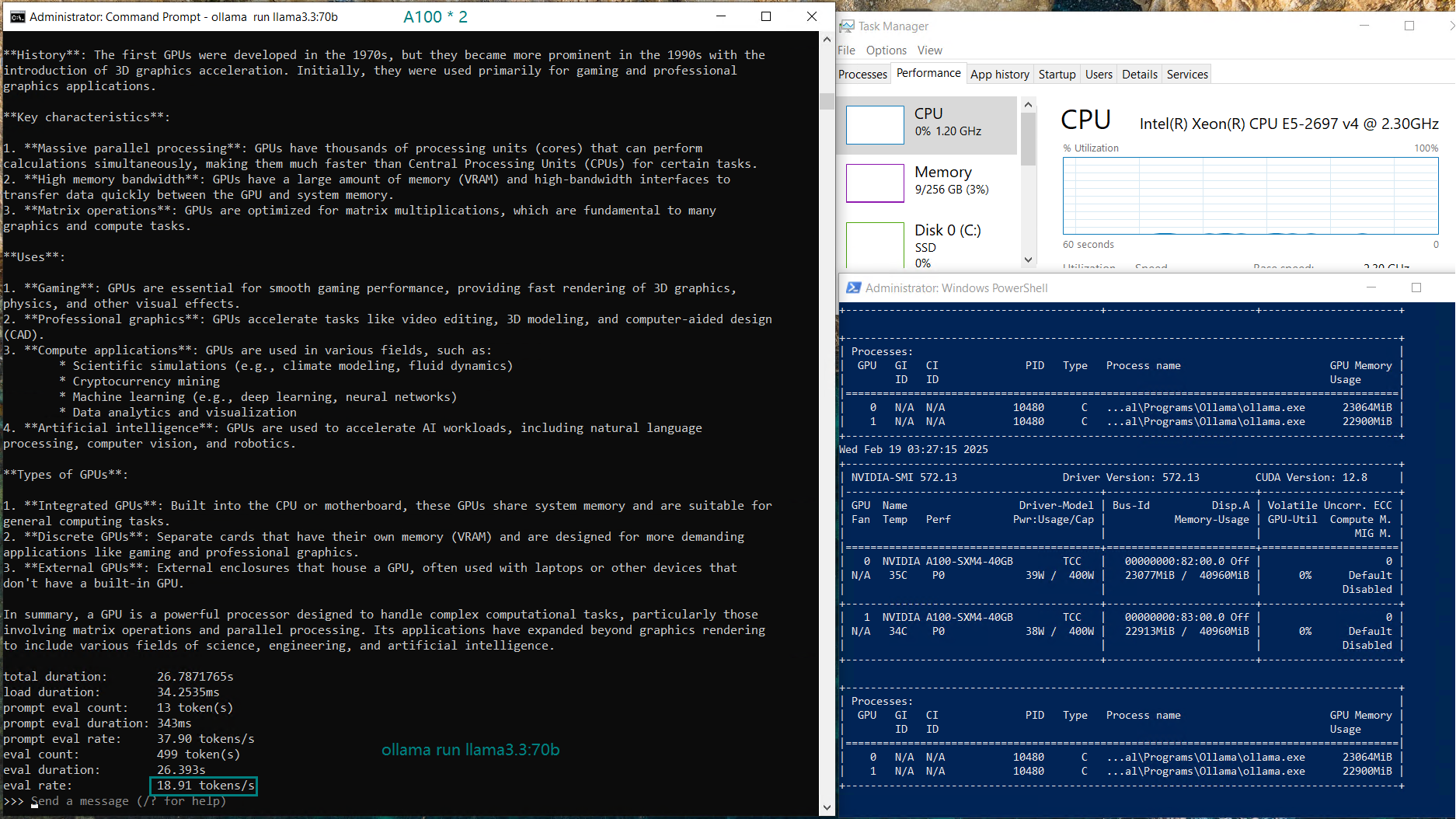
| GPU UTL(2 Cards) | 0%, 80% | 0%, 88% | 44%, 44% | 36%, 39% | 42%, 45% | 50%, 50% | 38%, 37% | 92%, 0% | 44%, 43% | 44%, 43% | 71%, 0% | 87%, 0% |
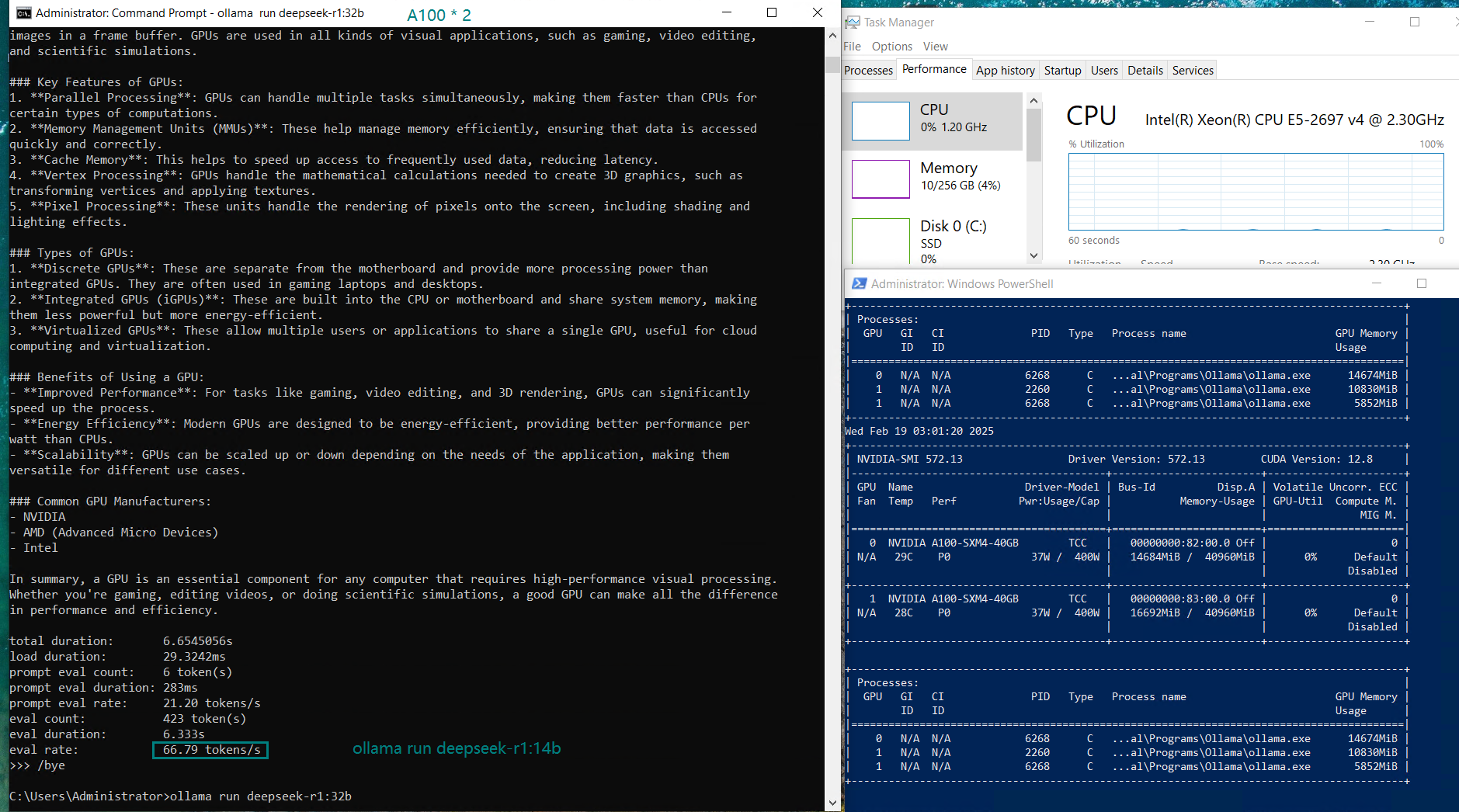
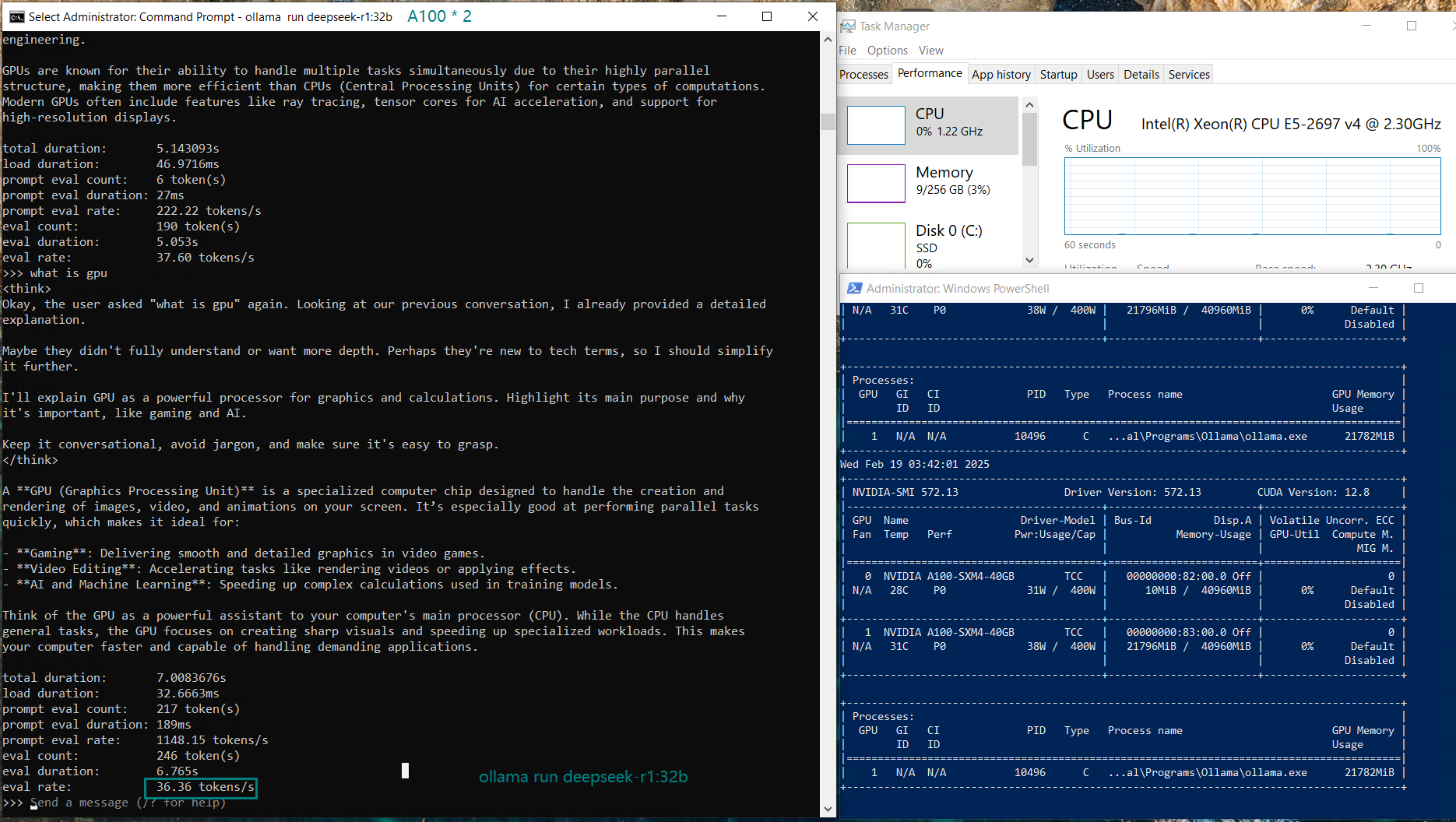
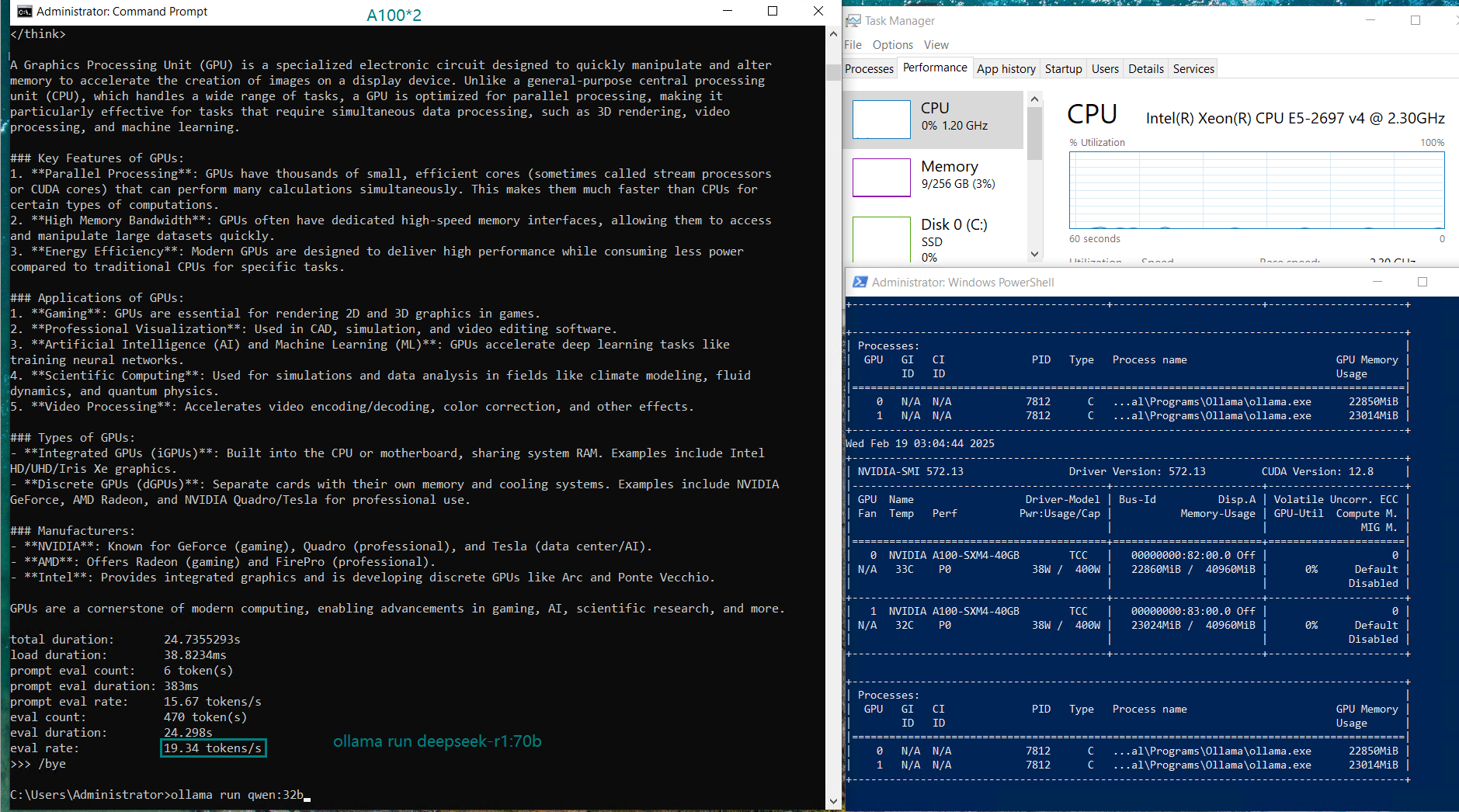
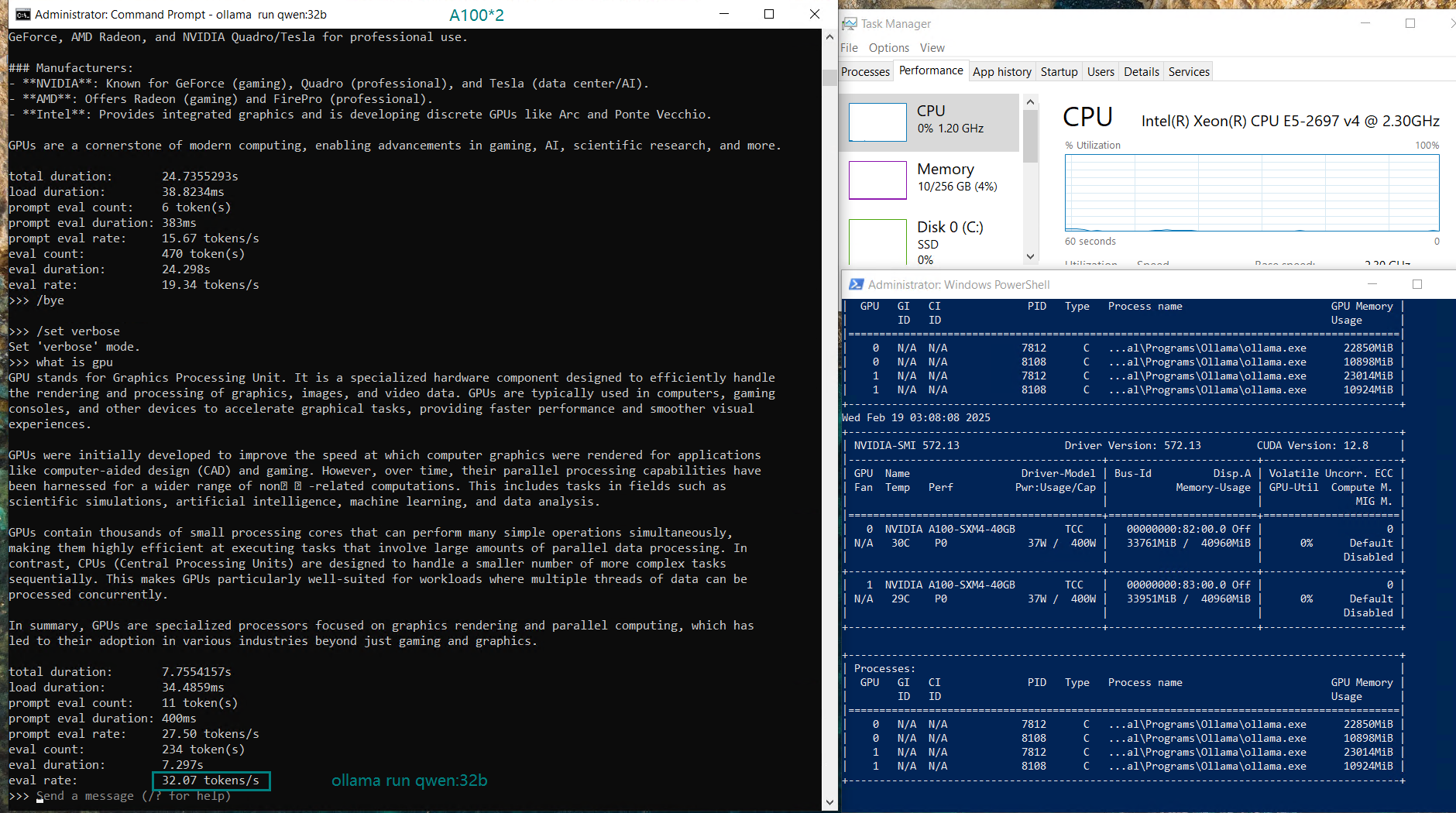
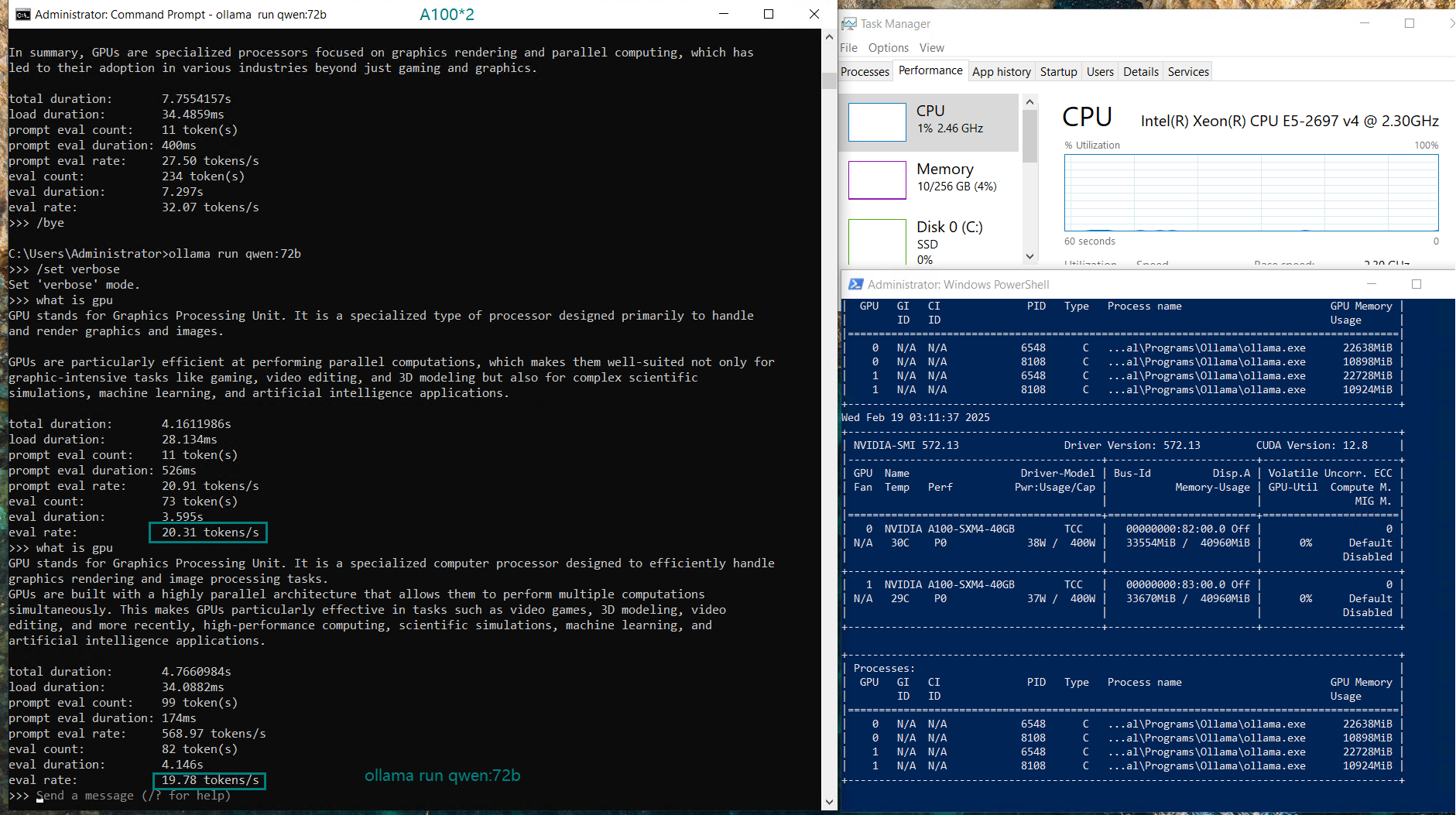
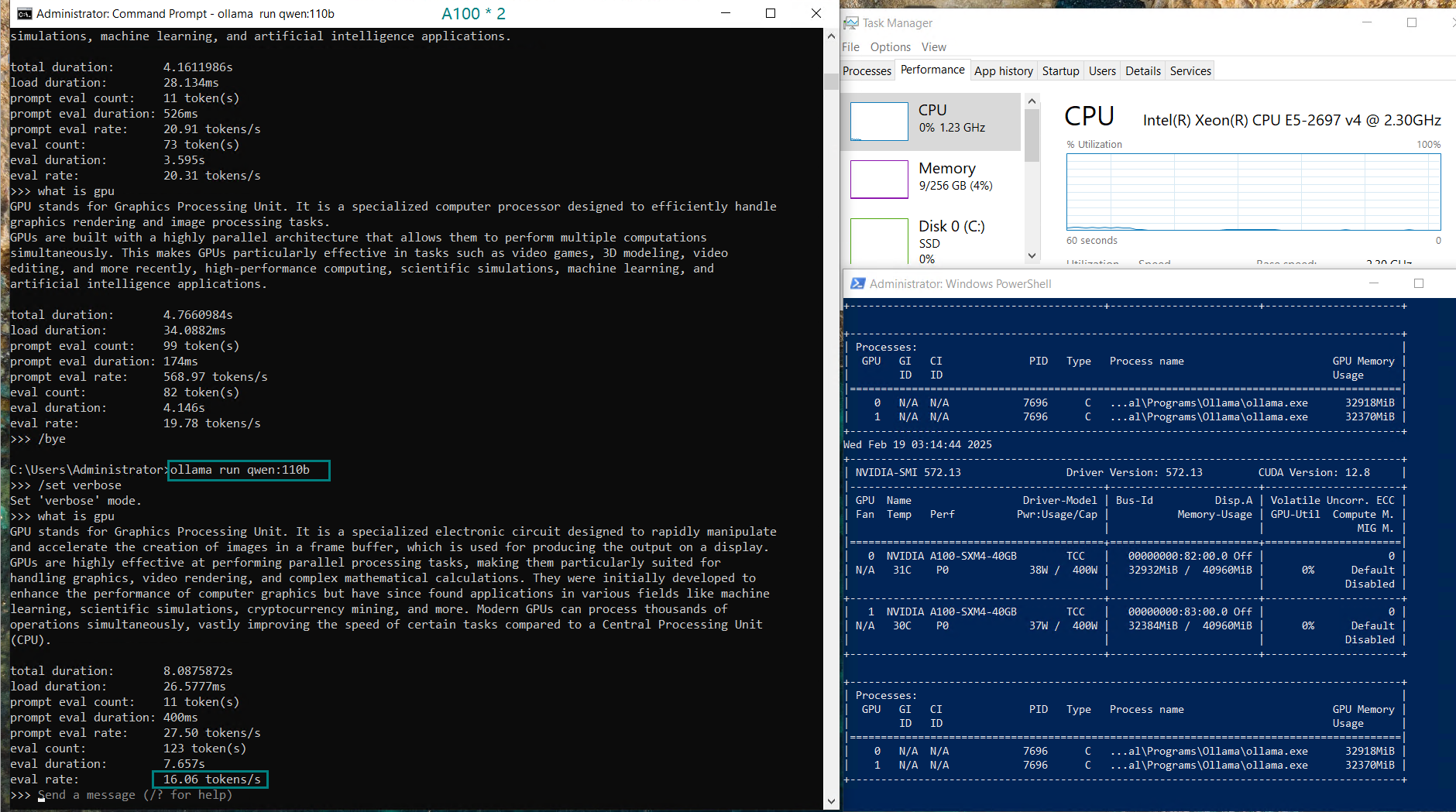
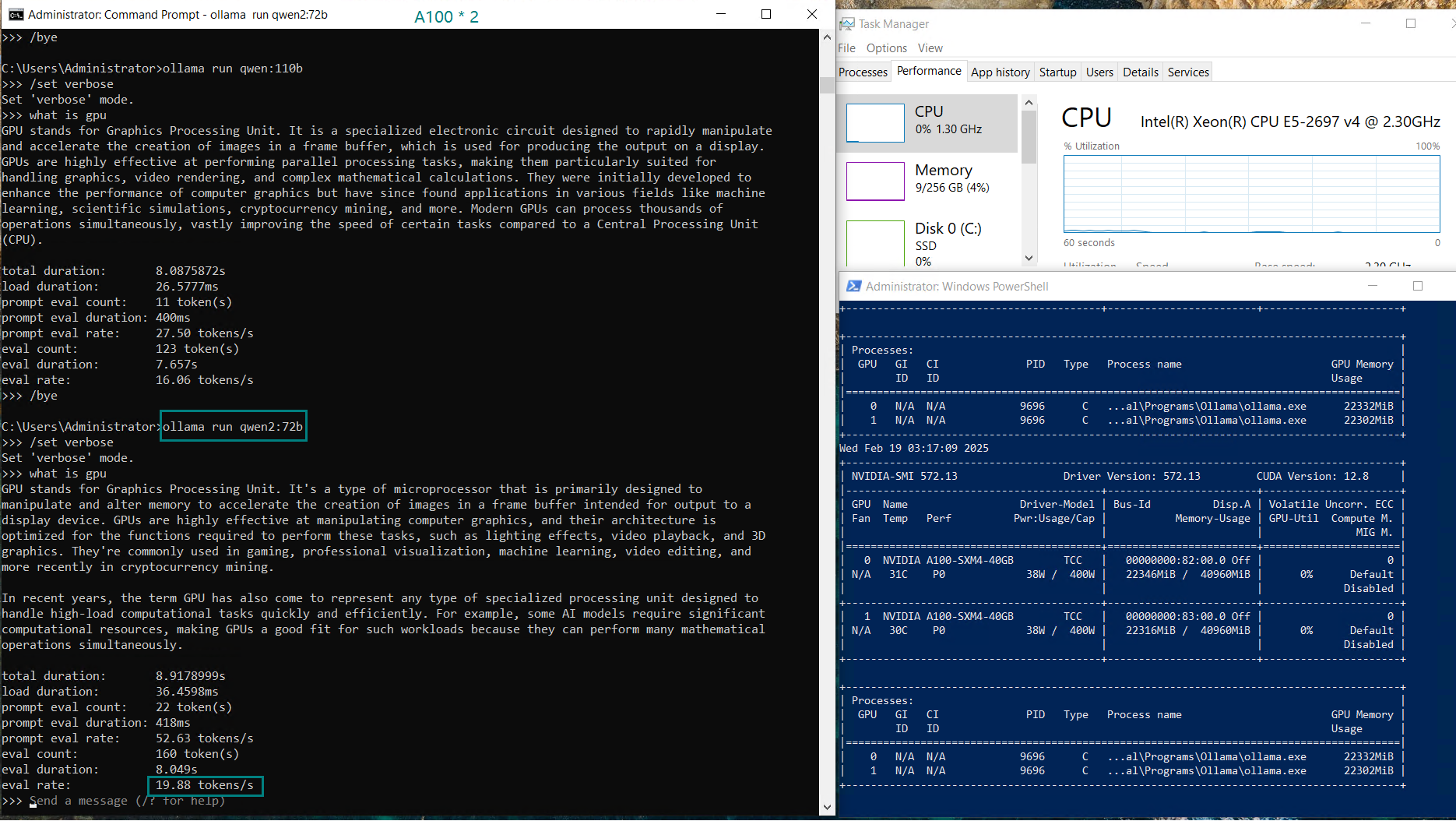
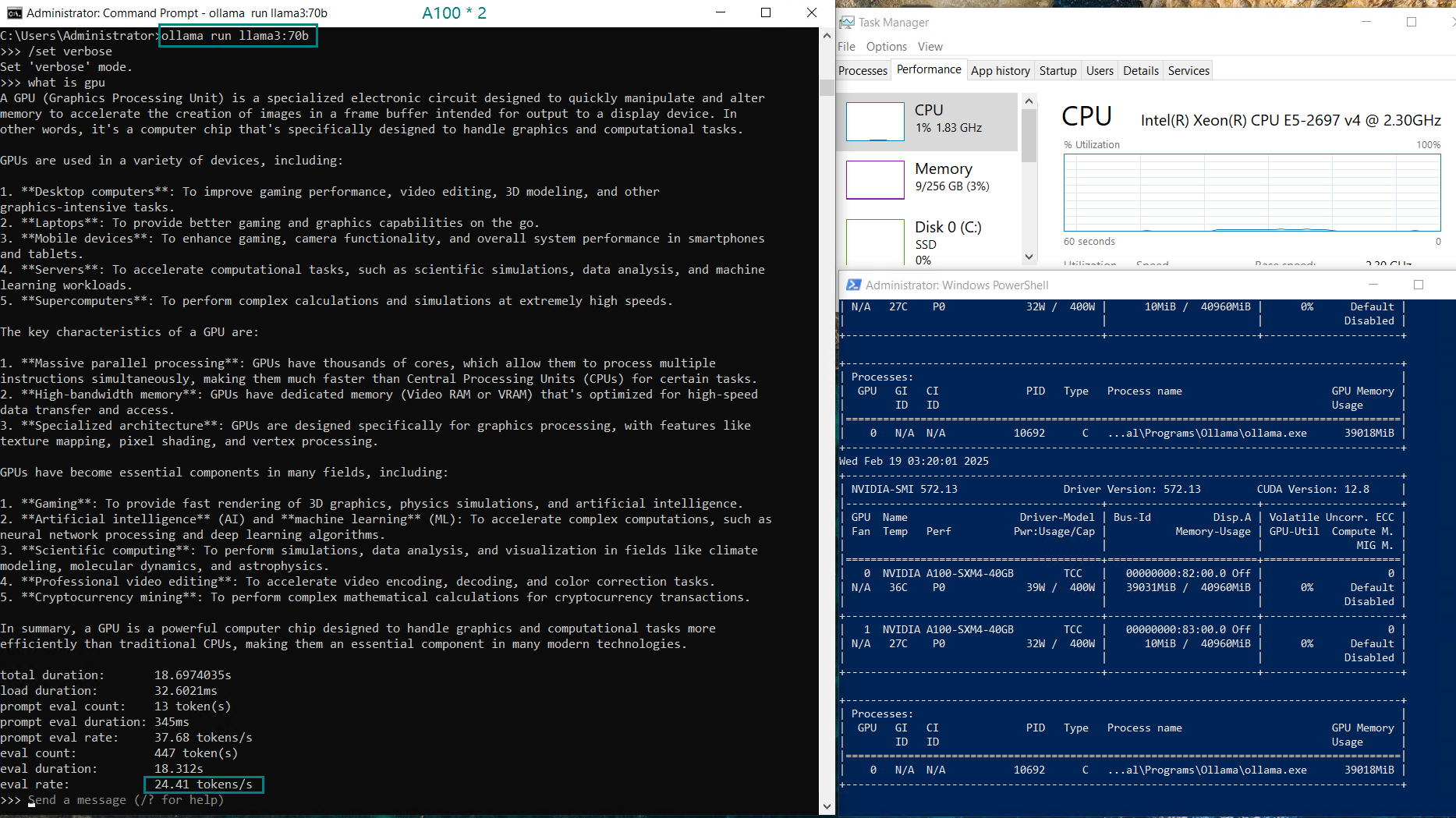
| Eval Rate(tokens/s) | 66.79 | 36.36 | 19.34 | 32.07 | 20.13 | 16.06 | 19.88 | 24.41 | 19.01 | 18.91 | 61.56 | 37.95 |
Analysis & Insights: Dual A100 GPUs Performance
1️⃣. High Performance Choice for 70b-110b
- DeepSeek-R1 runs efficiently with 66.79 tokens/s for 14B parameters and 36.36 tokens/s for 32B parameters.
- Qwen and Llama:72B shows solid performance with ~20 tokens/s.
- When processing the 110B models like Qwen, dual A100 GPUs experience a slight reduction in evaluation speed (16.06 tokens/s). Despite the drop in performance, the dual A100 setup still offers a cost-effective solution compared to the H100, especially for users running AI workloads on a budget.
2️⃣️. GPU Utilization in Dual GPU Setup
In contrast, single GPU configurations (with single A100 GPUs) can provide better utilization and faster inference, as the model is loaded into the entire GPU memory. Splitting the model across two GPUs means higher memory overhead and increased PCI bus traffic, which can introduce some latency.
3️⃣. Memory Distribution in Multi-GPU Configuration
4️⃣. A100 vs. H100
📢 Get Started with Dual A100 GPU Hosting for LLMs
Enterprise GPU Dedicated Server - RTX A6000
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia Quadro RTX A6000
- Microarchitecture: Ampere
- CUDA Cores: 10,752
- Tensor Cores: 336
- GPU Memory: 48GB GDDR6
- FP32 Performance: 38.71 TFLOPS
- Optimally running AI, deep learning, data visualization, HPC, etc.
Multi-GPU Dedicated Server - 2xA100
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 1Gbps
- OS: Windows / Linux
- GPU: Nvidia A100
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 40GB HBM2
- FP32 Performance: 19.5 TFLOPS
- Free NVLink Included
- A Powerful Dual-GPU Solution for Demanding AI Workloads, Large-Scale Inference, ML Training.etc. A cost-effective alternative to A100 80GB and H100, delivering exceptional performance at a competitive price.
Enterprise GPU Dedicated Server - A100(80GB)
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia A100
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 80GB HBM2e
- FP32 Performance: 19.5 TFLOPS
Enterprise GPU Dedicated Server - H100
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia H100
- Microarchitecture: Hopper
- CUDA Cores: 14,592
- Tensor Cores: 456
- GPU Memory: 80GB HBM2e
- FP32 Performance: 183TFLOPS
Conclusion
The Dual Nvidia A100 GPU server is a powerful and cost-effective solution for running LLMs with parameter sizes up to 110B. It offers excellent performance for mid-range to large models like Qwen:32B, DeepSeek-R1:70B, and Qwen:72B, with a significant price advantage over higher-end GPUs like the H100.
For users who need to process large-scale models without the steep costs of more premium GPUs, A100*2 hosting offers a compelling option that balances performance and affordability.
Nvidia A100, LLM hosting, AI server, Ollama, performance analysis, GPU server hosting, DeepSeek-R1, Qwen model, AI performance, A100 server, Nvidia GPUs