
























RTX2060 Ollama Benchmark: Best GPU for 3B LLMs Inference
With the rise of local large language model (LLM) inference, many AI enthusiasts and developers are looking for cost-effective solutions. One such popular choice is running models using Ollama on an Nvidia RTX2060 GPU. In this benchmark, we evaluate the performance of various LLMs on a dedicated RTX2060 server, analyzing their inference speed, GPU utilization, and overall feasibility for small-scale deployment.
This RTX2060 Ollama benchmark aims to answer the question: Can an Nvidia RTX2060 effectively handle LLMs like DeepSeek, Llama 3, Mistral, and Qwen? And if so, which models provide the best trade-off between performance and resource consumption?
Test Server Configuration
Server Configuration:
- Price: $199/month
- CPU: Intel Dual 10-Core E5-2660 v2
- RAM: 128GB
- Storage: 120GB + 960GB SSD
- Network: 100Mbps Unmetered
- OS: Windows 11 Pro
GPU Details:
- GPU: Nvidia GeForce RTX 2060
- Compute Capability: 7.5
- Microarchitecture: Ampere
- CUDA Cores: 1920
- Tensor Cores: 240
- Memory: 6GB GDDR6
- FP32 Performance: 5.0 TFLOPS
This setup allows us to explore RTX2060 for small LLM inference, focusing on models up to 3B parameters due to the 6GB VRAM limitation.
Benchmark Results: Ollama on Nvidia RTX2060
| Models | deepseek-r1 | deepseek-r1 | deepseek-r1 | deepseek-coder | llama3.2 | llama3.1 | codellama | mistral | gemma | codegemma | qwen2.5 | qwen2.5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Parameters | 1.5b | 7b | 8b | 6.7b | 3b | 8b | 7b | 7b | 7b | 7b | 3b | 7b |
| Size(GB) | 1.1 | 4.7 | 4.9 | 3.8 | 2.0 | 4.9 | 3.8 | 4.1 | 5.0 | 5.0 | 1.9 | 4.7 |
| Quantization | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Running on | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 |
| Downloading Speed(mb/s) | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 |
| CPU Rate | 7% | 46% | 46% | 42% | 7% | 51% | 41% | 7% | 51% | 53% | 7% | 45% |
| RAM Rate | 5% | 6% | 6% | 5% | 5% | 6% | 5% | 5% | 7% | 7% | 5% | 6% |
| GPU UTL | 39% | 35% | 32% | 35% | 56% | 31% | 35% | 21% | 12% | 11% | 43% | 36% |
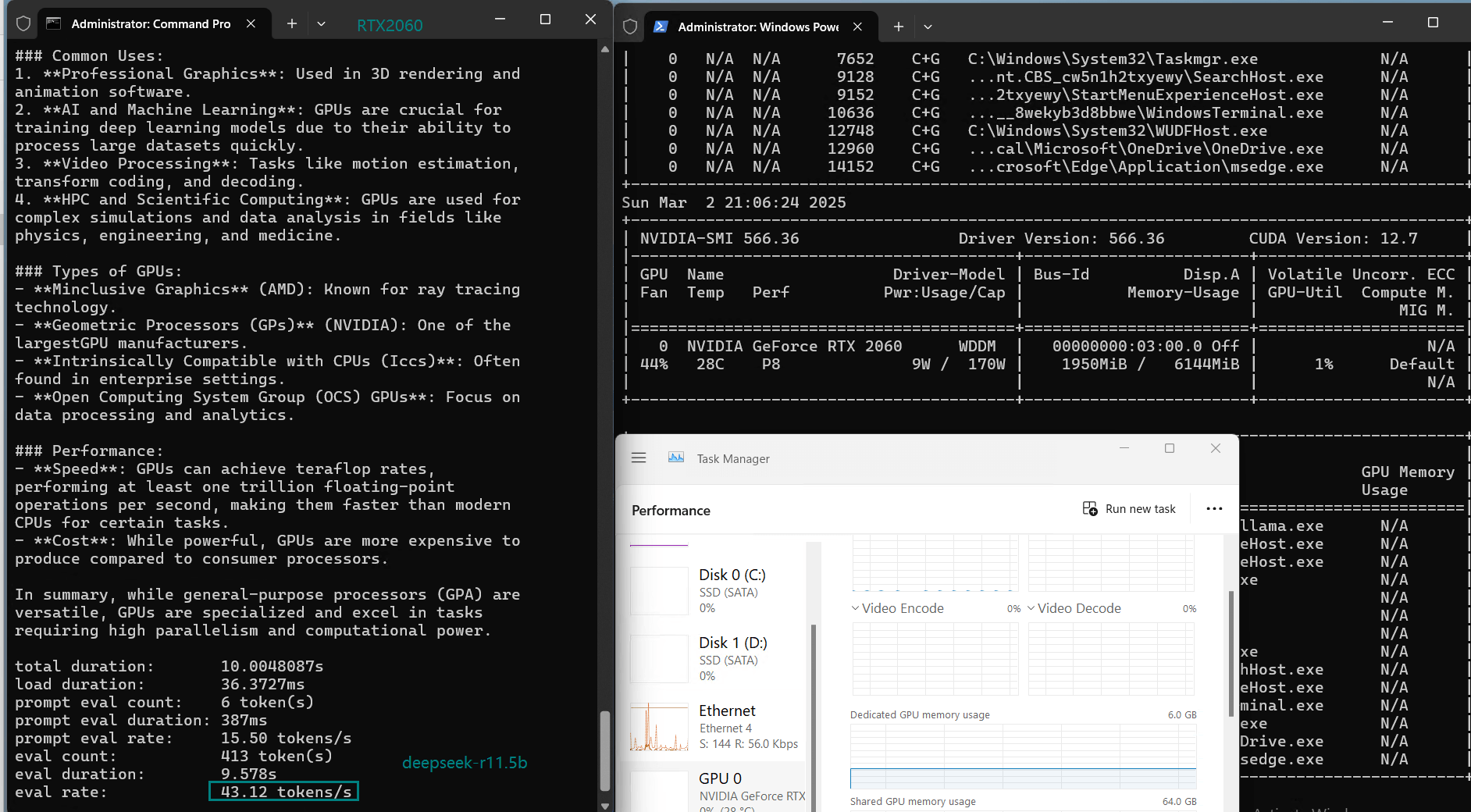
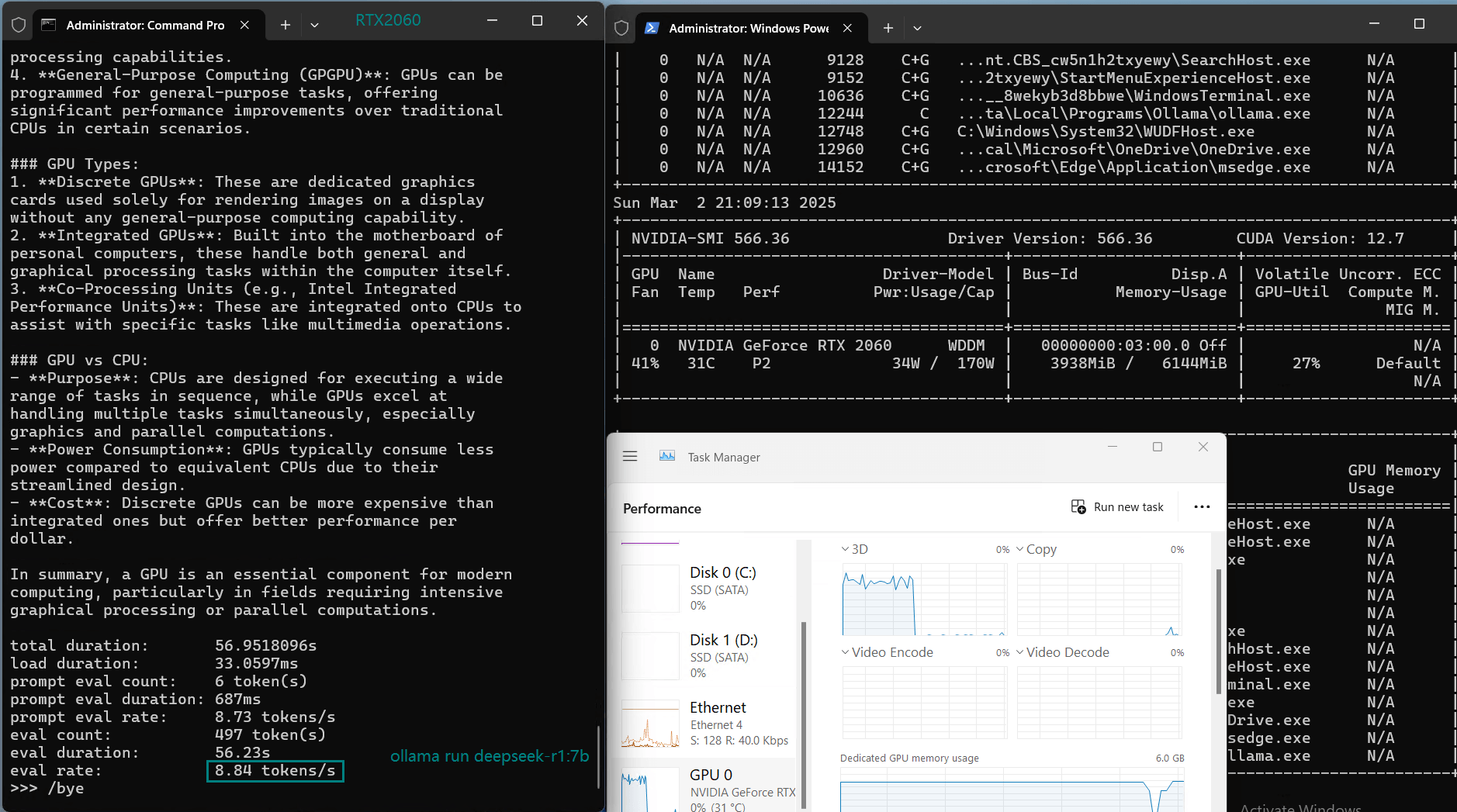
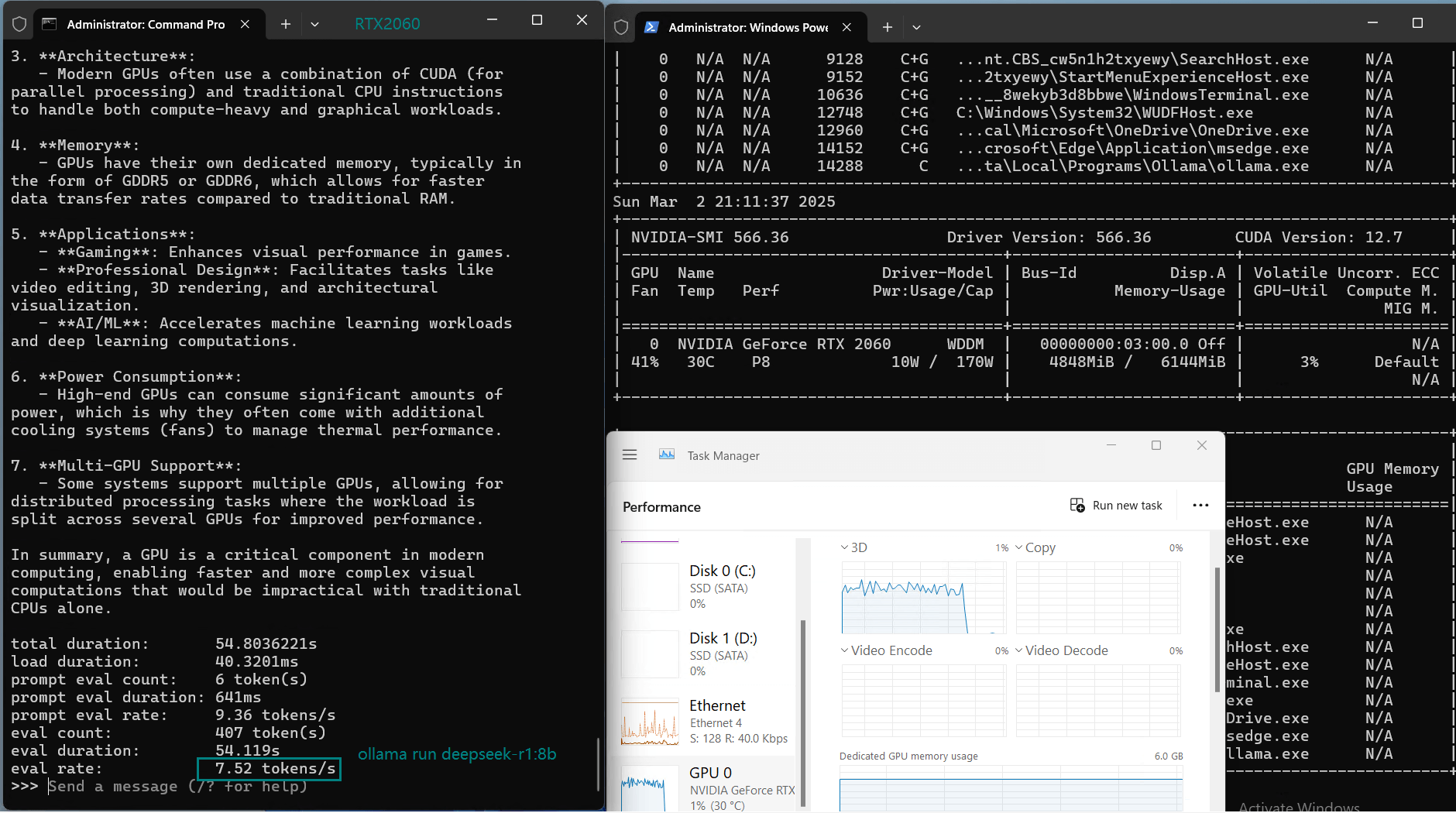
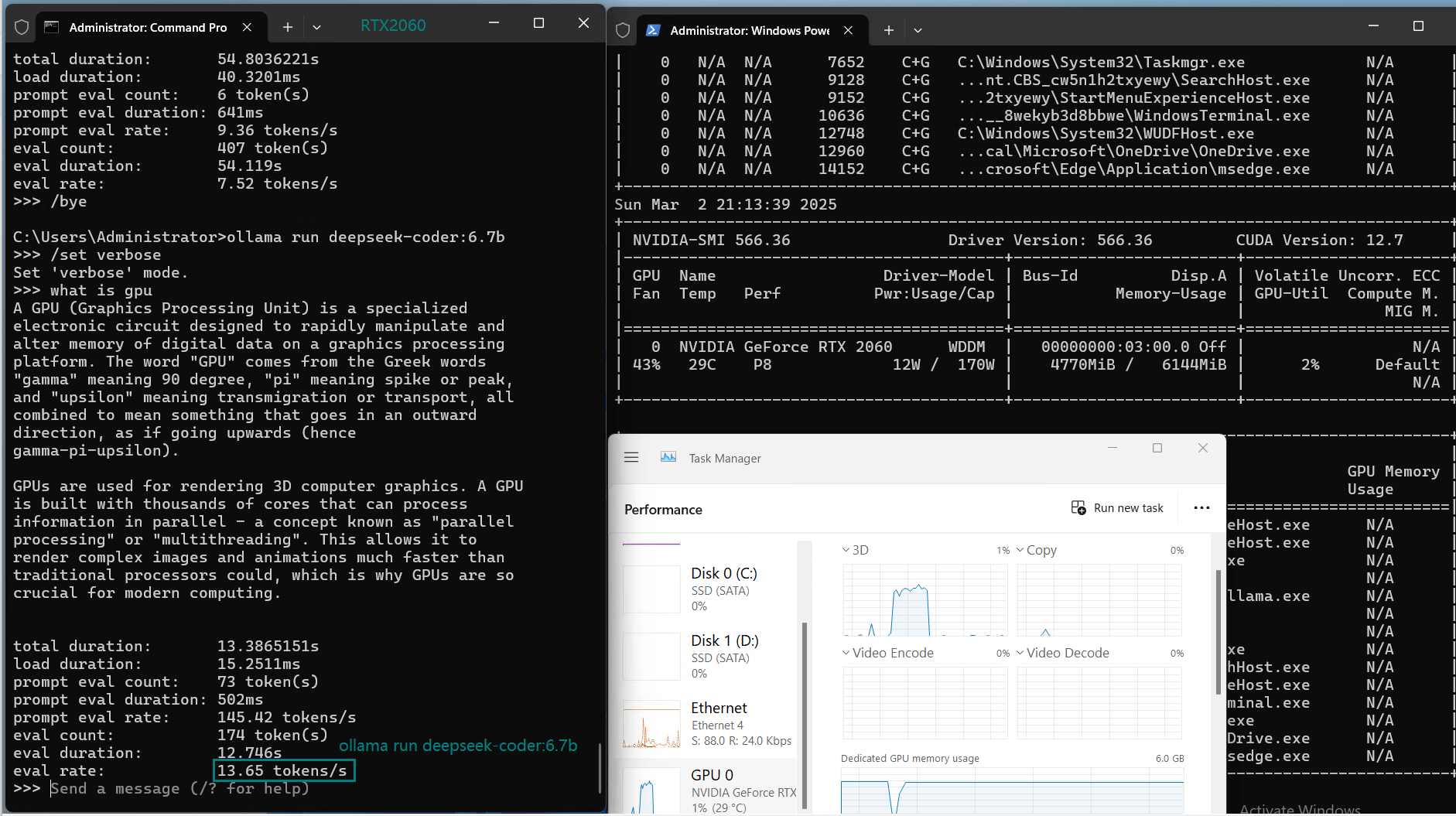
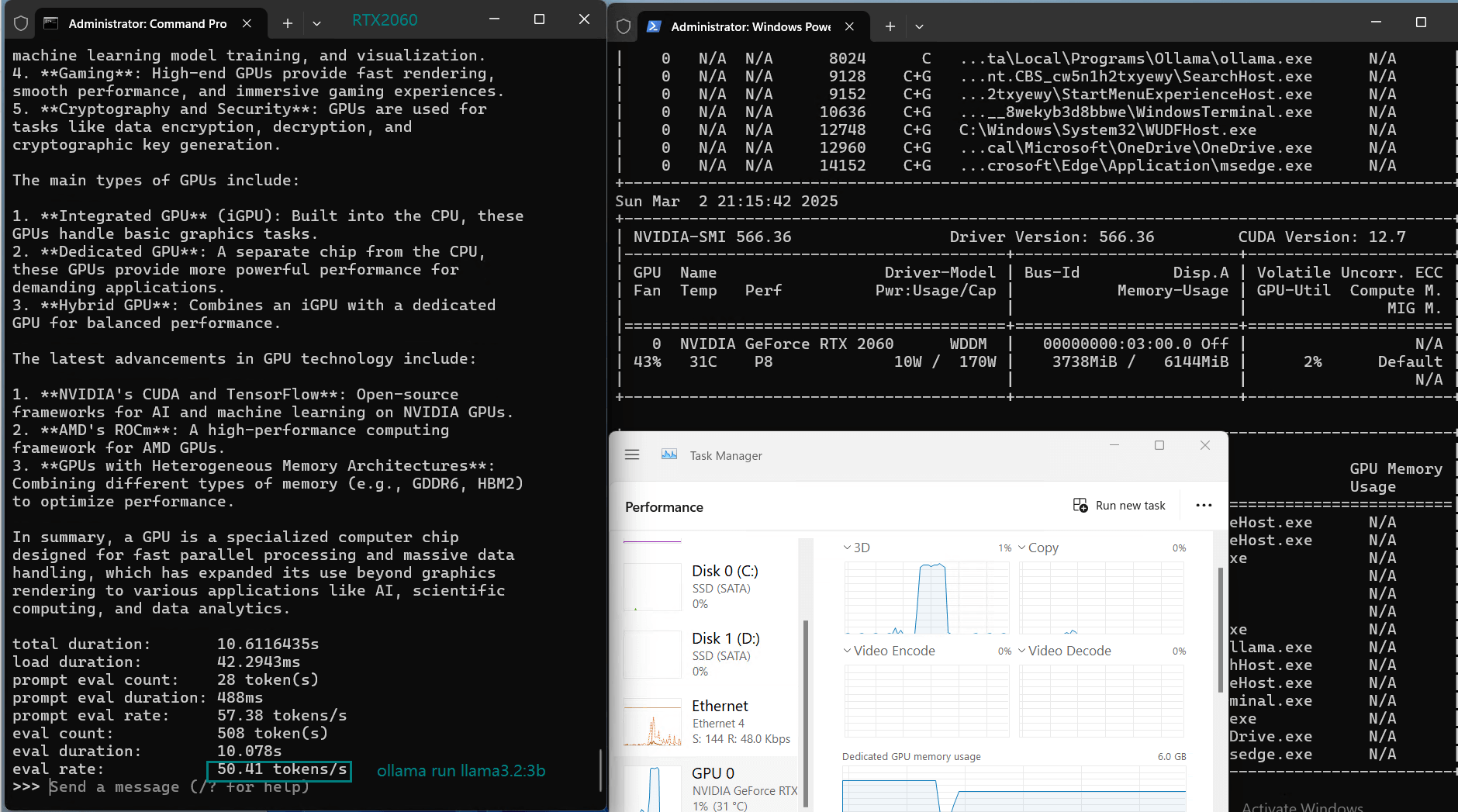
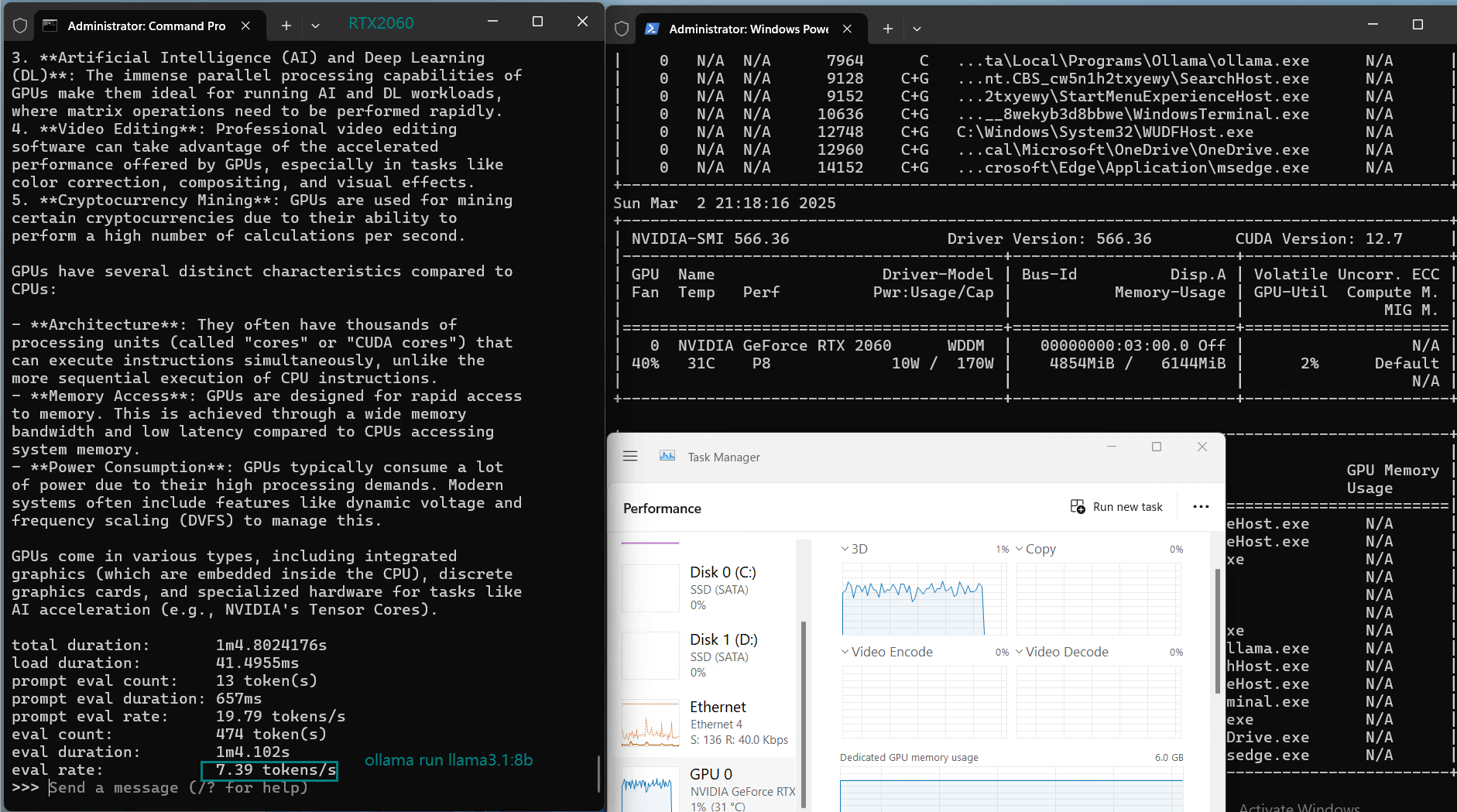
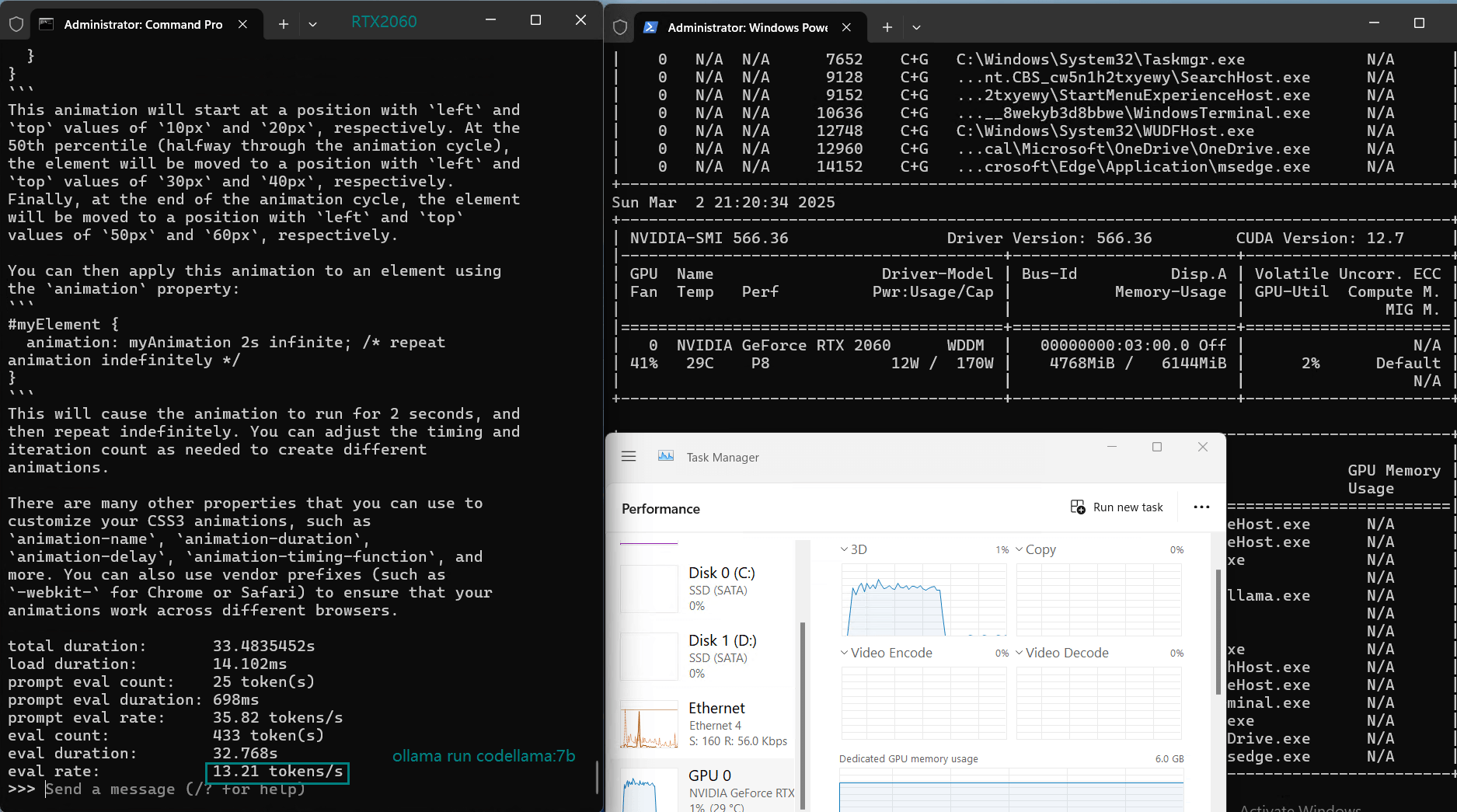
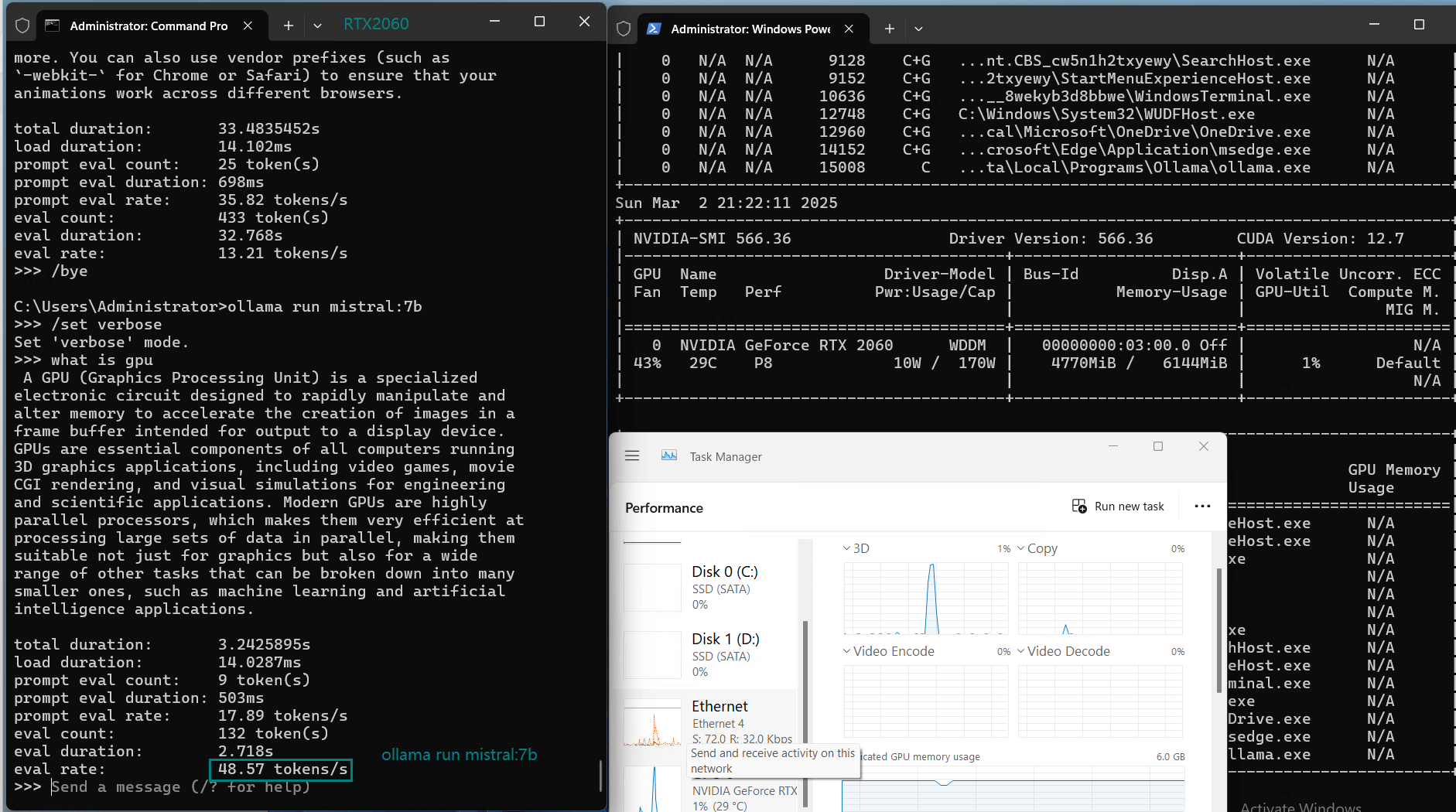
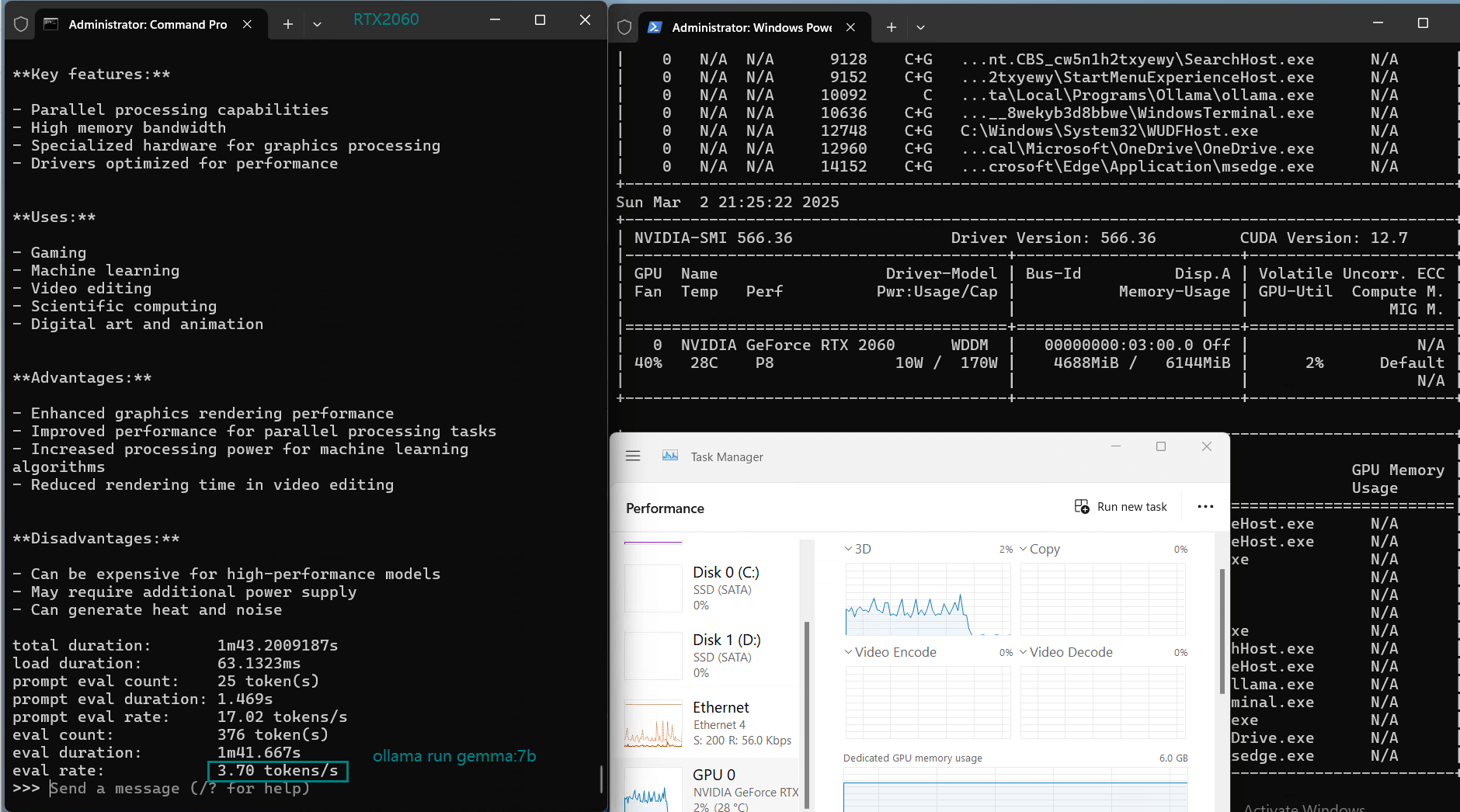
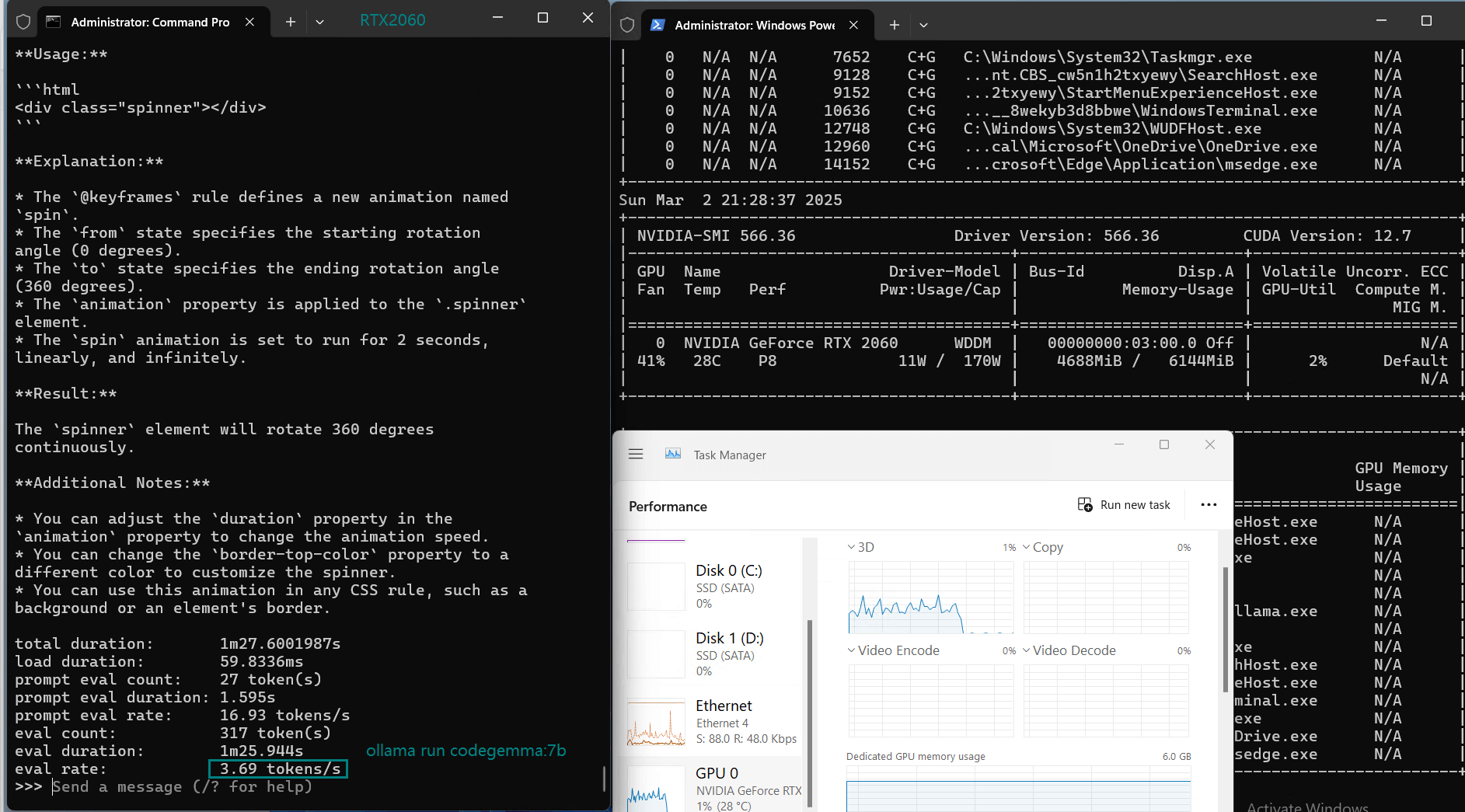
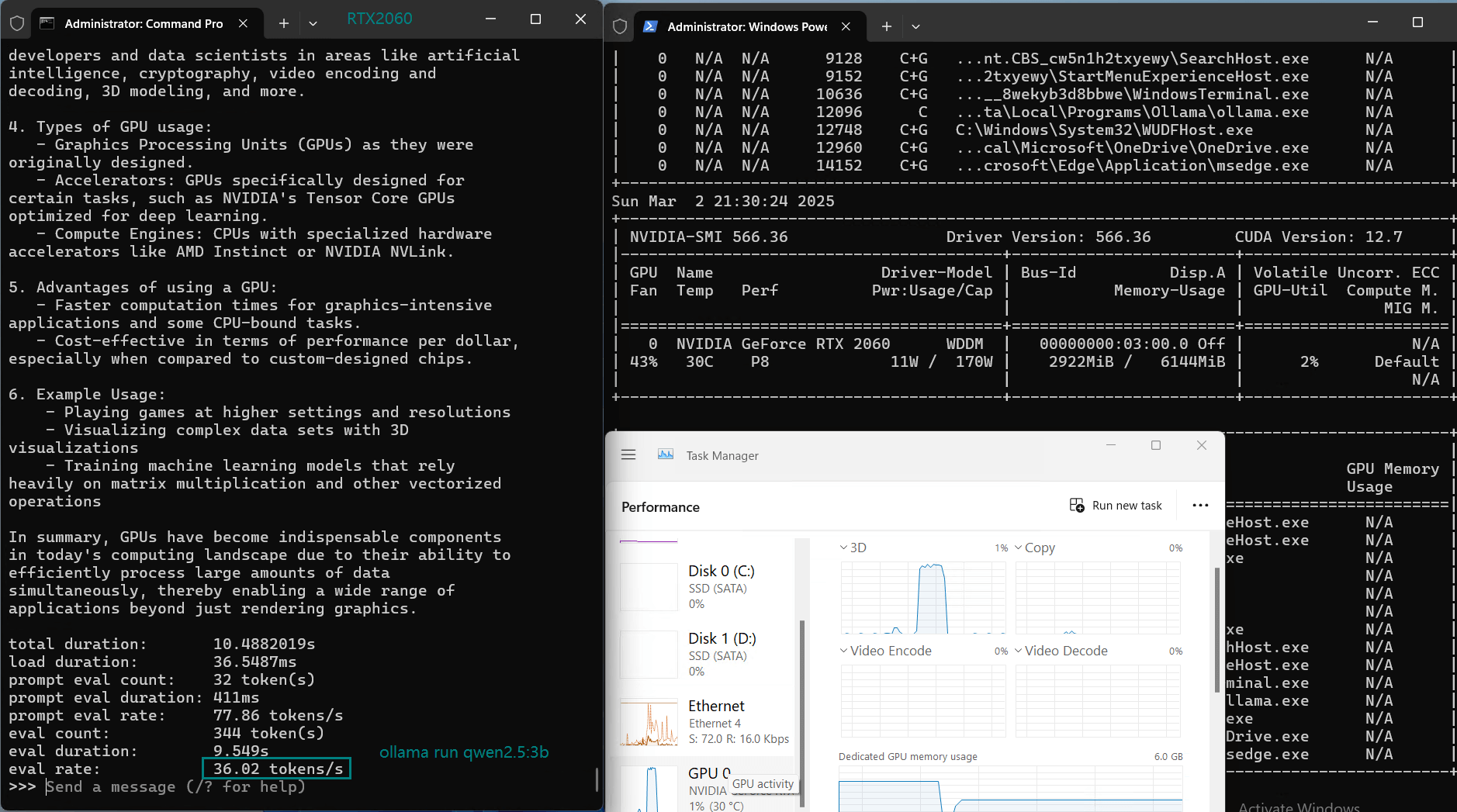
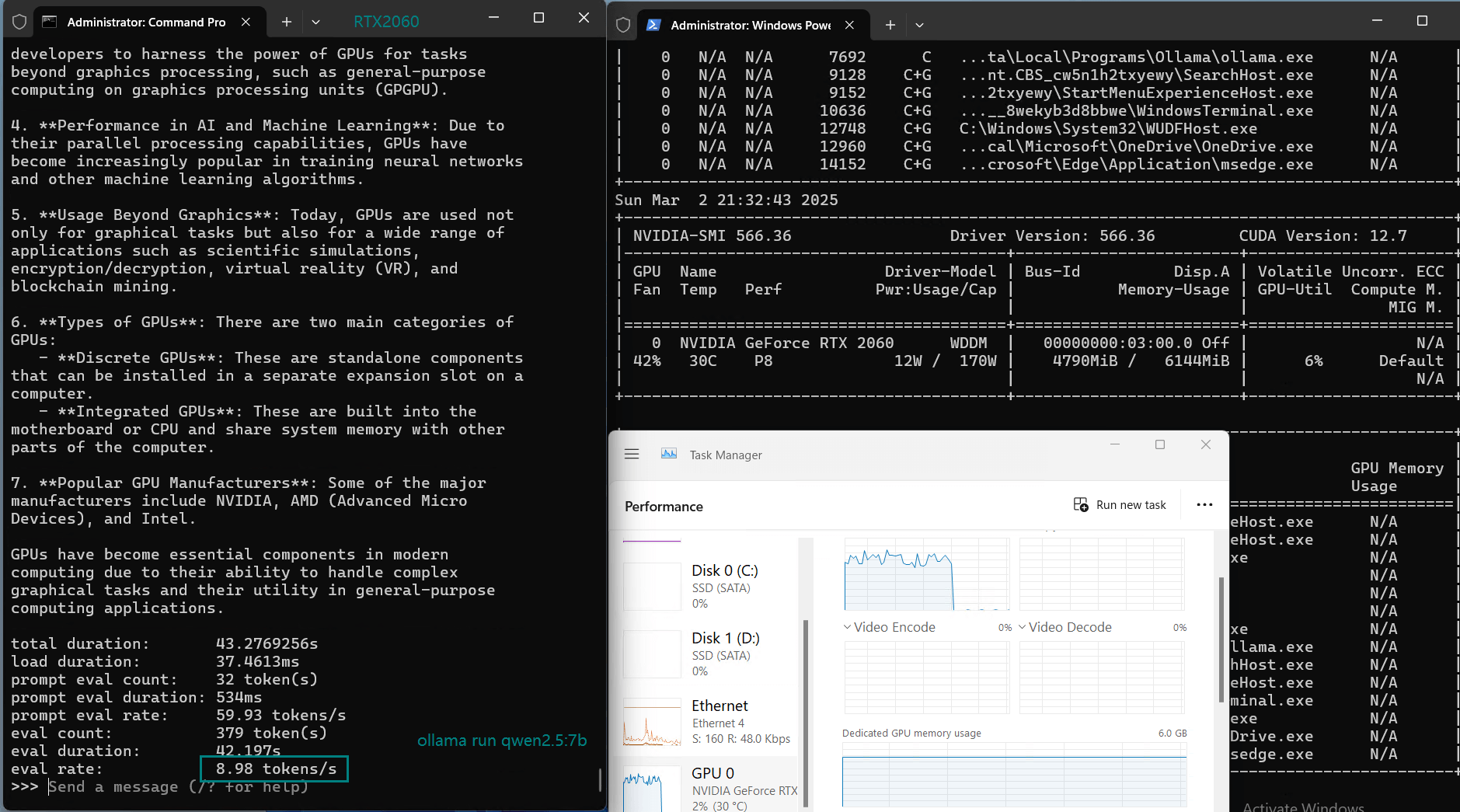
| Eval Rate(tokens/s) | 43.12 | 8.84 | 7.52 | 13.62 | 50.41 | 7.39 | 13.21 | 48.57 | 3.70 | 3.69 | 36.02 | 8.98 |
Key Findings from the Benchmark
1️⃣. RTX2060 performs well with 3B parameter models)
2️⃣. RTX2060 struggles with 7B+ models
Models like Mistral 7B, DeepSeek 7B, and Llama 3.1 (8B) experienced low inference speeds (7-9 tokens/s) and near 80% VRAM usage.While technically runnable, the performance is too slow for real-time applications.
3️⃣. Efficient utilization at 3B models
Get Started with RTX2060 Hosting for Small LLMs
Professional GPU Dedicated Server - RTX 2060
- 128GB RAM
- Dual 10-Core E5-2660v2
- 120GB + 960GB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia GeForce RTX 2060
- Microarchitecture: Ampere
- CUDA Cores: 1920
- Tensor Cores: 240
- GPU Memory: 6GB GDDR6
- FP32 Performance: 6.5 TFLOPS
- Powerful for Gaming, OBS Streaming, Video Editing, Android Emulators, 3D Rendering, etc
Basic GPU Dedicated Server - RTX 4060
- 64GB RAM
- Eight-Core E5-2690
- 120GB SSD + 960GB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia GeForce RTX 4060
- Microarchitecture: Ada Lovelace
- CUDA Cores: 3072
- Tensor Cores: 96
- GPU Memory: 8GB GDDR6
- FP32 Performance: 15.11 TFLOPS
- Ideal for video edting, rendering, android emulators, gaming and light AI tasks.
Advanced GPU Dedicated Server - RTX 3060 Ti
- 128GB RAM
- Dual 12-Core E5-2697v2
- 240GB SSD + 2TB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: GeForce RTX 3060 Ti
- Microarchitecture: Ampere
- CUDA Cores: 4864
- Tensor Cores: 152
- GPU Memory: 8GB GDDR6
- FP32 Performance: 16.2 TFLOPS
Professional GPU VPS - A4000
- 32GB RAM
- 24 CPU Cores
- 320GB SSD
- 300Mbps Unmetered Bandwidth
- Once per 2 Weeks Backup
- OS: Linux / Windows 10/ Windows 11
- Dedicated GPU: Quadro RTX A4000
- CUDA Cores: 6,144
- Tensor Cores: 192
- GPU Memory: 16GB GDDR6
- FP32 Performance: 19.2 TFLOPS
- Available for Rendering, AI/Deep Learning, Data Science, CAD/CGI/DCC.
Conclusion: RTX2060 is Best for 3B Models
If you're looking for a budget-friendly LLM server using Ollama on an RTX2060, your best bet is 3B parameter models like Llama3.2 and Qwen2.5.
Final Recommendations
- For fast inference → Llama3.2 (3B)
- For alternative choices → Qwen2.5 (3B)
- Avoid models over 7B due to low speed and high VRAM use
This RTX2060 Ollama benchmark shows that while Nvidia RTX2060 hosting is viable for small LLM inference, it is not suitable for models larger than 3B parameters. If you require 7B+ model performance, consider a higher-end GPU like RTX 3060/A4000 servers.
RTX2060 Ollama benchmark, RTX2060 AI inference, best LLM for RTX2060, Nvidia RTX2060 hosting, Llama 3 RTX2060, Qwen RTX2060, Mistral AI benchmark, DeepSeek AI, small LLM inference, budget AI GPU