
























Benchmarking LLMs on Ollama: Performance of Nvidia RTX 4060 GPU Server
As large language models (LLMs) continue to gain traction, running them efficiently on consumer-grade GPUs has become a hot topic. In this benchmark, we test Ollama on a dedicated Nvidia RTX 4060 server to evaluate its performance in LLM inference. If you're looking for a high-performance yet affordable LLM hosting solution, this RTX 4060 benchmark will help you decide whether it's the right choice for your AI workload.
Test Server Configuration
Server Configuration:
- Price: $149/month
- CPU: Intel Eight-Core E5-2690
- RAM: 64GB
- Storage: 120GB SSD + 960GB SSD
- Network: 100Mbps Unmetered
- OS: Windows 11 Pro
GPU Details:
- GPU: Nvidia GeForce RTX 4060
- Compute Capability: 8.9
- Microarchitecture: Ada Lovelace
- CUDA Cores: 3072
- Tensor Cores: 96
- Memory: 8GB GDDR6
- FP32 Performance: 15.11 TFLOPS
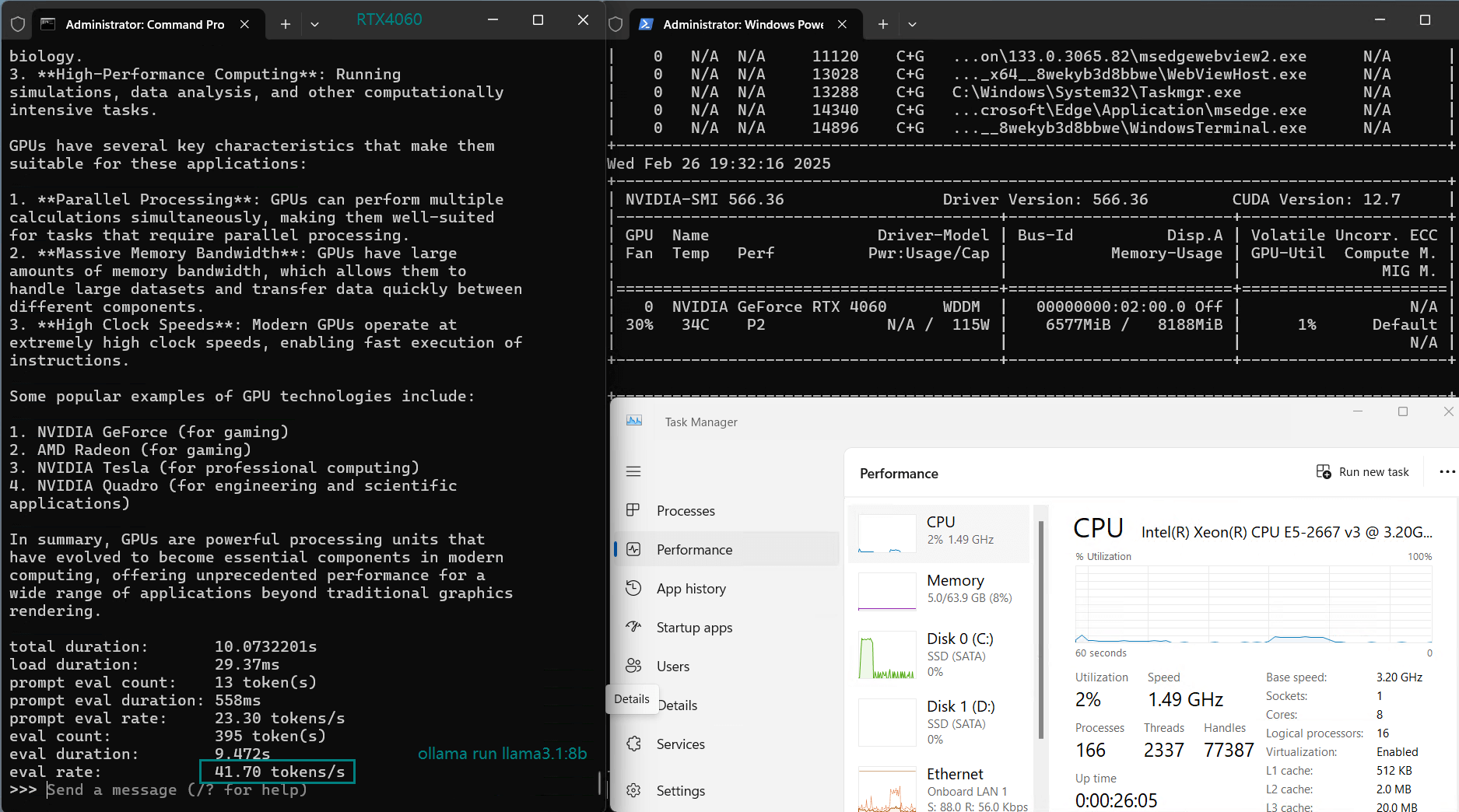
This setup makes it a viable option for Nvidia RTX 4060 hosting to run LLM inference workloads efficiently while keeping costs in check.
Ollama Benchmark: Testing LLMs on NVIDIA RTX4060 Server
| Models | deepseek-r1 | deepseek-r1 | deepseek-coder | llama2 | llama3.1 | codellama | mistral | gemma | gemma2 | codegemma | qwen2.5 | codeqwen |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Parameters | 7b | 8b | 6.7b | 13b | 8b | 7b | 7b | 7b | 9b | 7b | 7b | 7b |
| Size(GB) | 4.7 | 4.9 | 3.8 | 7.4 | 4.9 | 3.8 | 4.1 | 5.0 | 5.4 | 5.0 | 4.7 | 4.2 |
| Quantization | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Running on | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 |
| Downloading Speed(mb/s) | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 |
| CPU Rate | 7% | 7% | 8% | 37% | 8% | 7% | 8% | 32% | 30% | 32% | 7% | 9% |
| RAM Rate | 8% | 8% | 8% | 12% | 8% | 7% | 8% | 9% | 10% | 9% | 8% | 8% |
| GPU UTL | 83% | 81% | 91% | 25-42% | 88% | 92% | 90% | 42% | 44% | 46% | 72% | 93% |
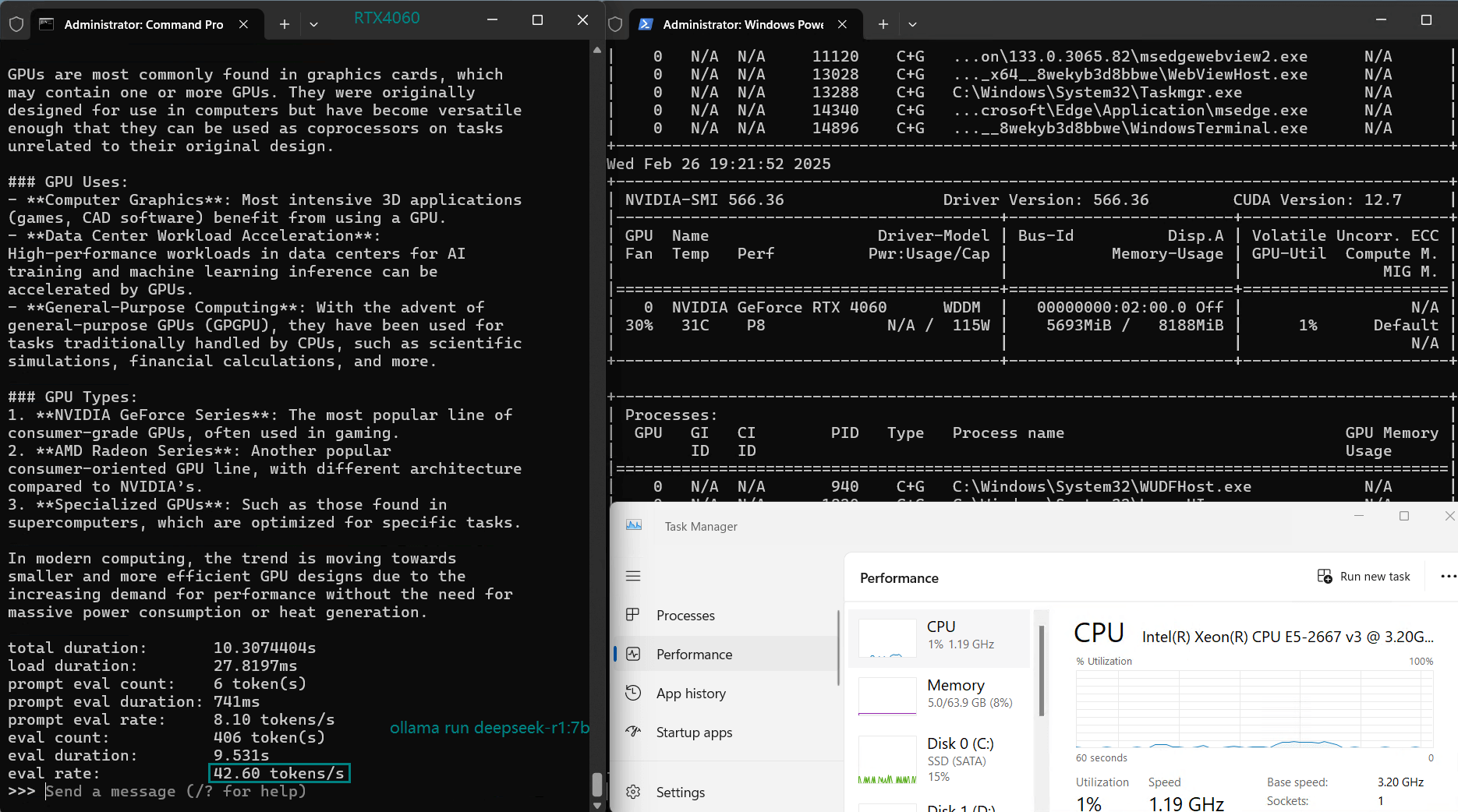
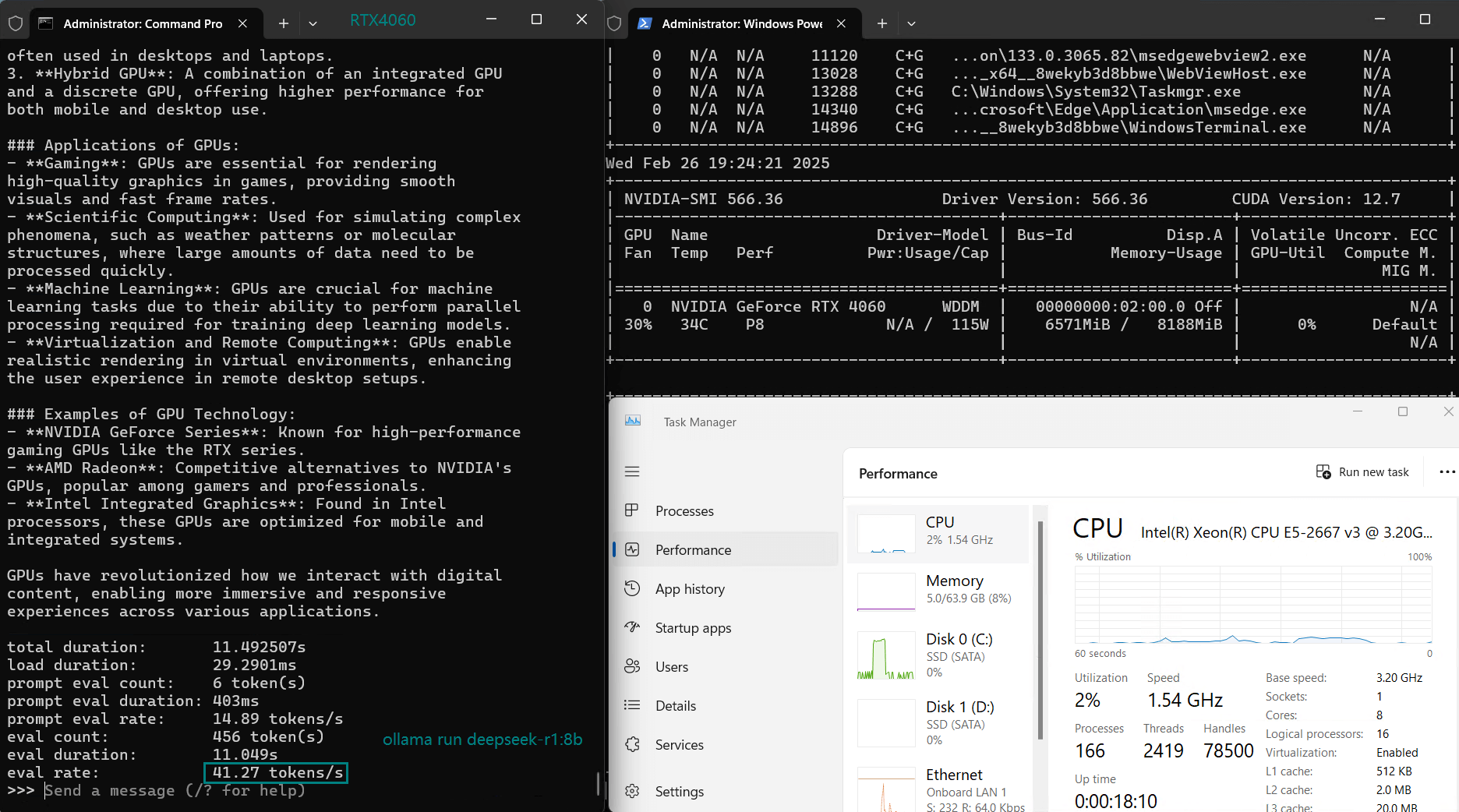
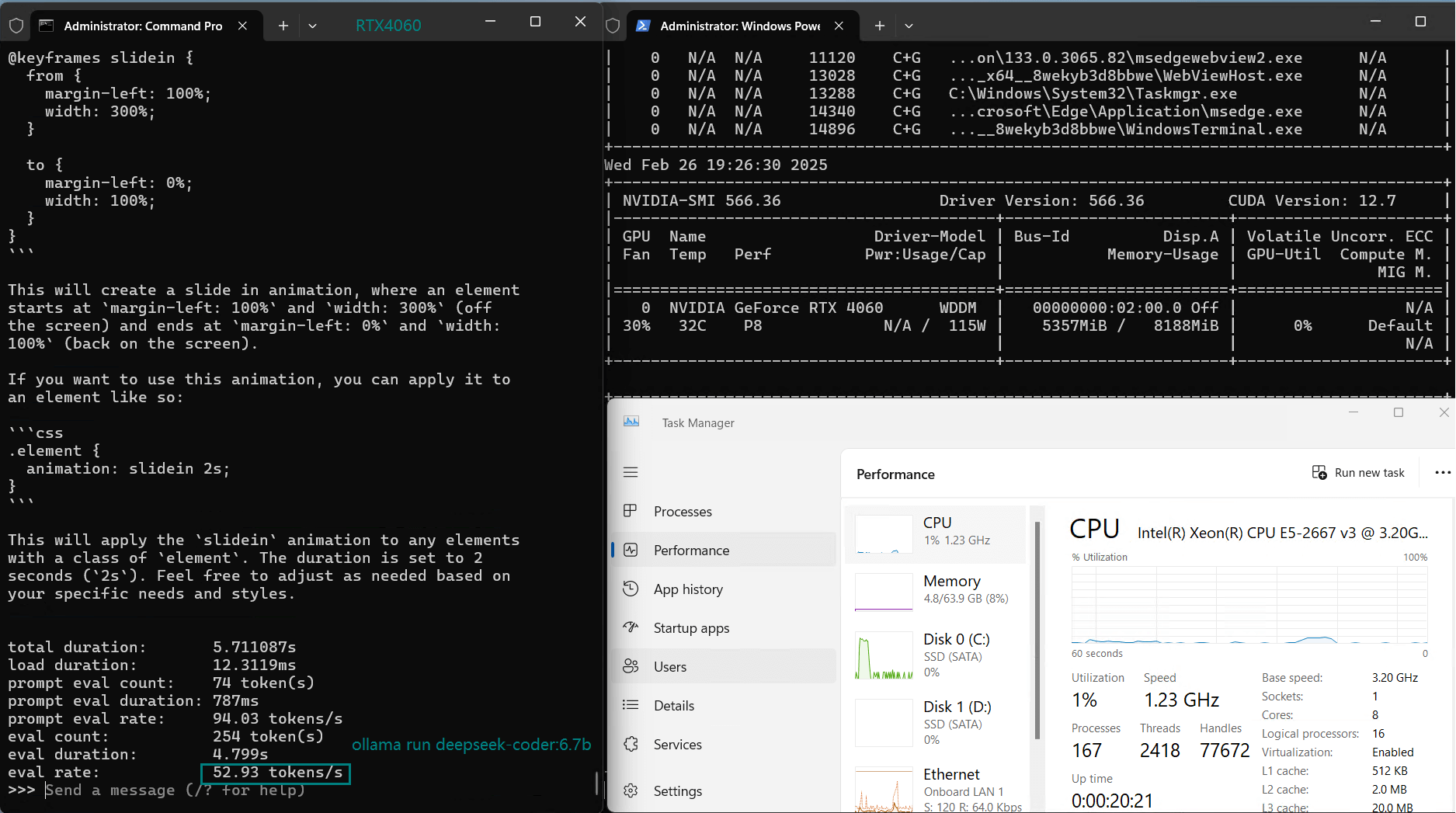
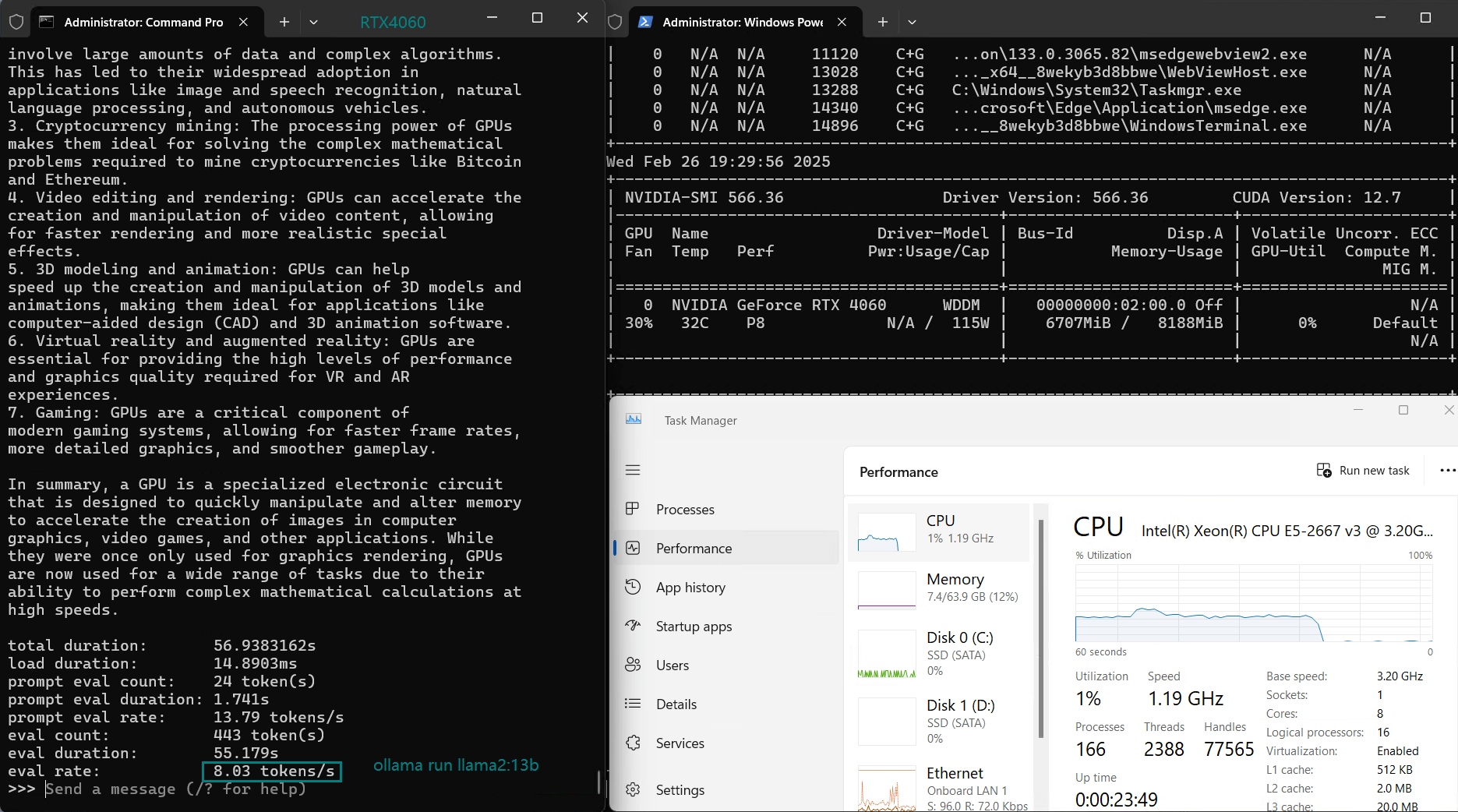
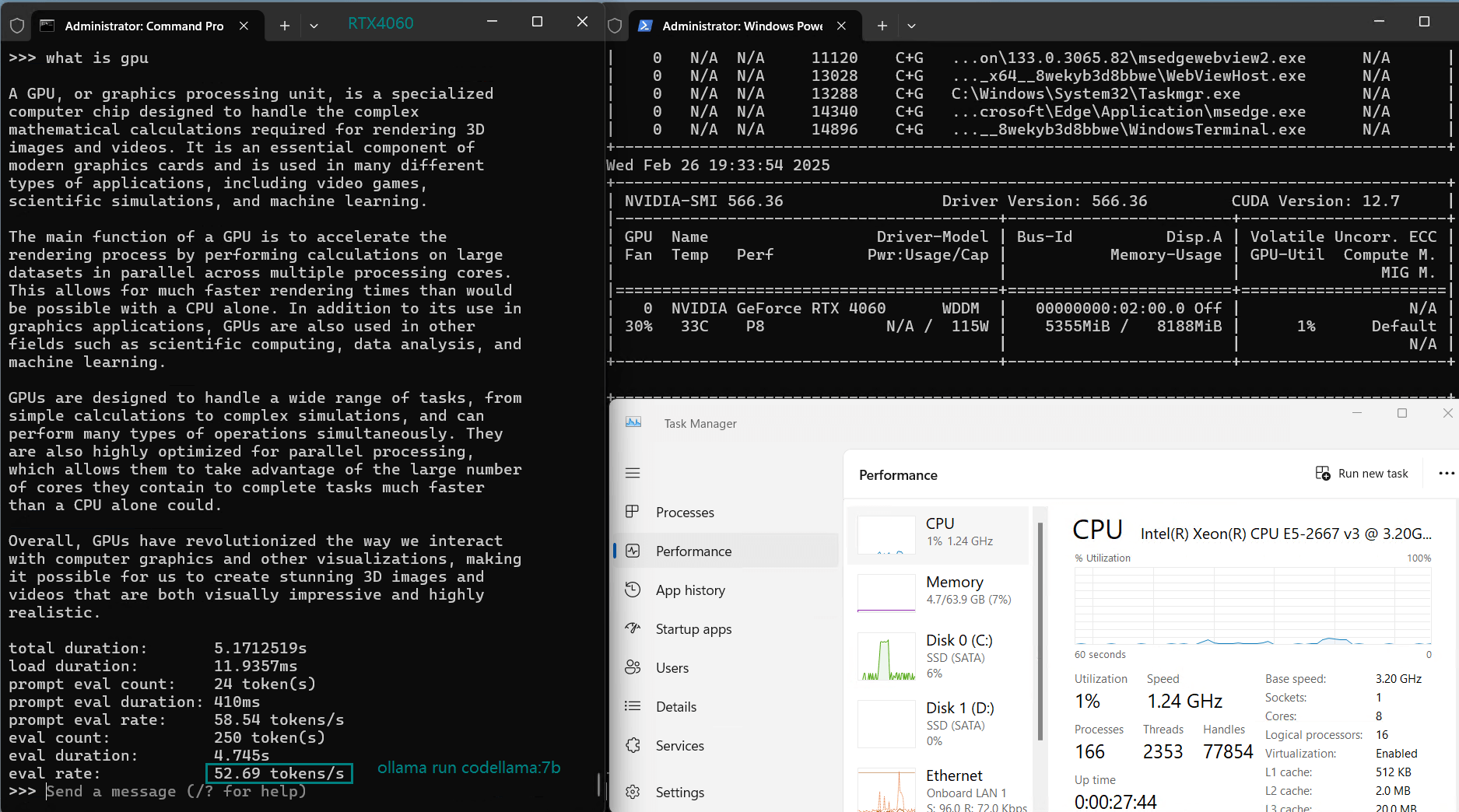
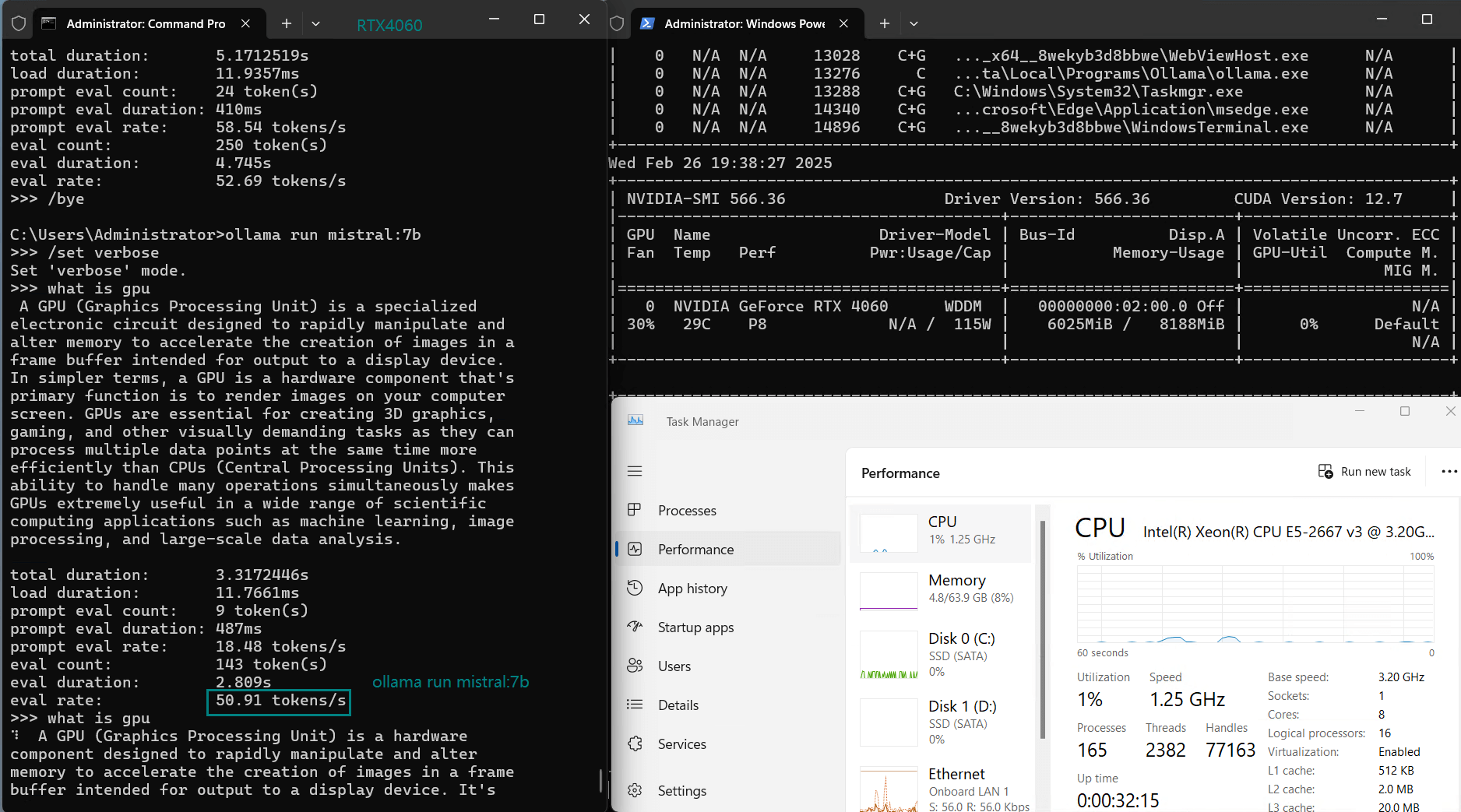
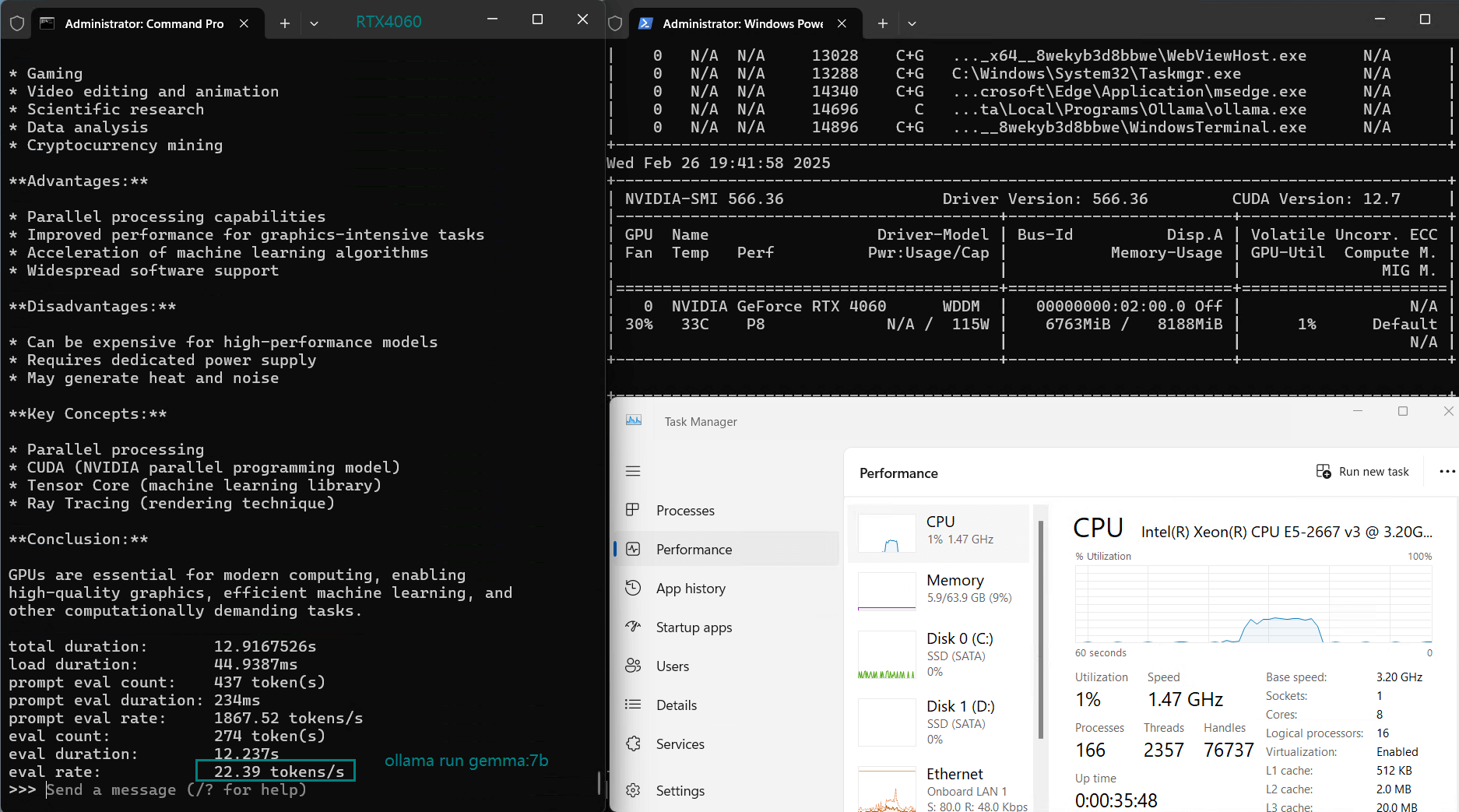
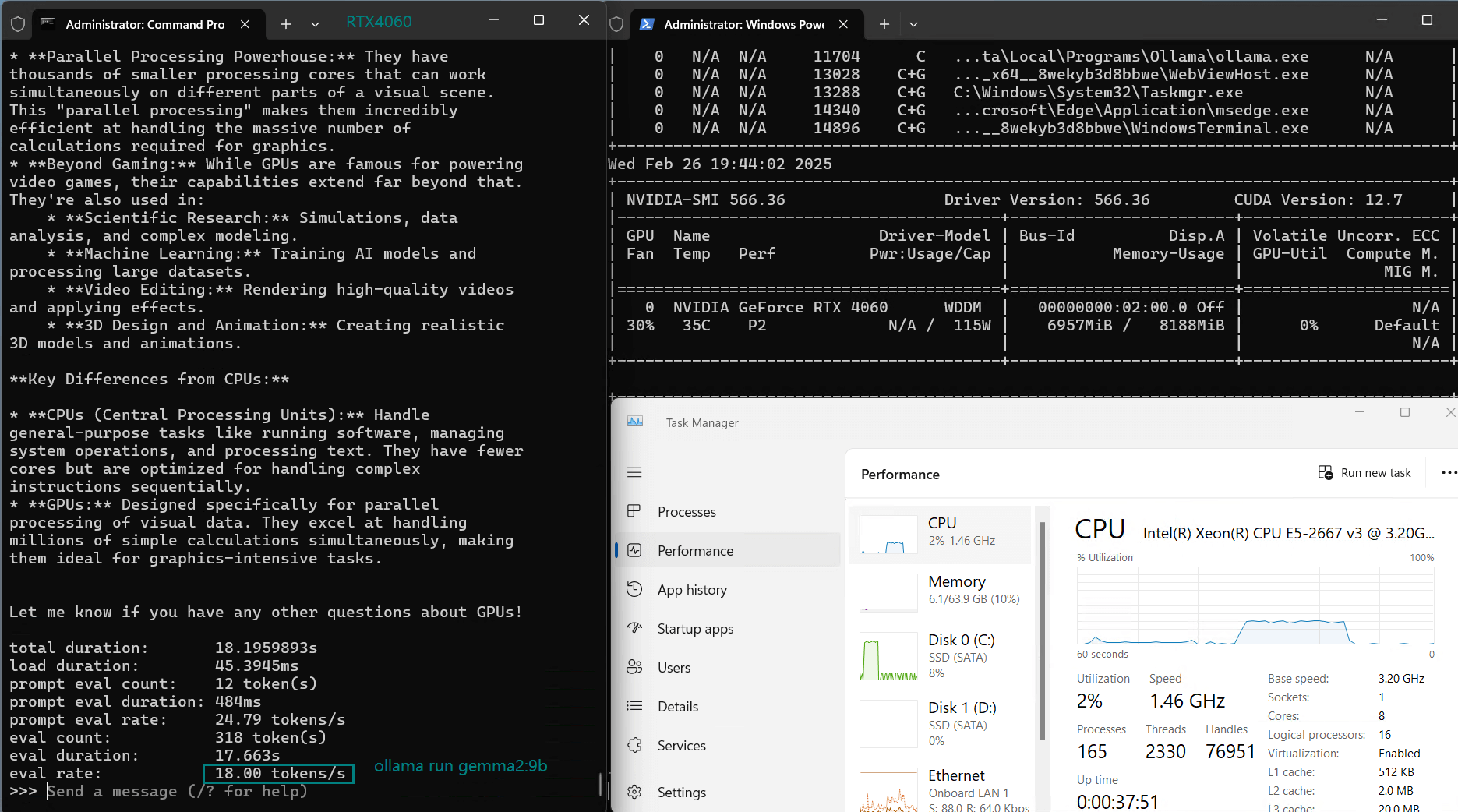
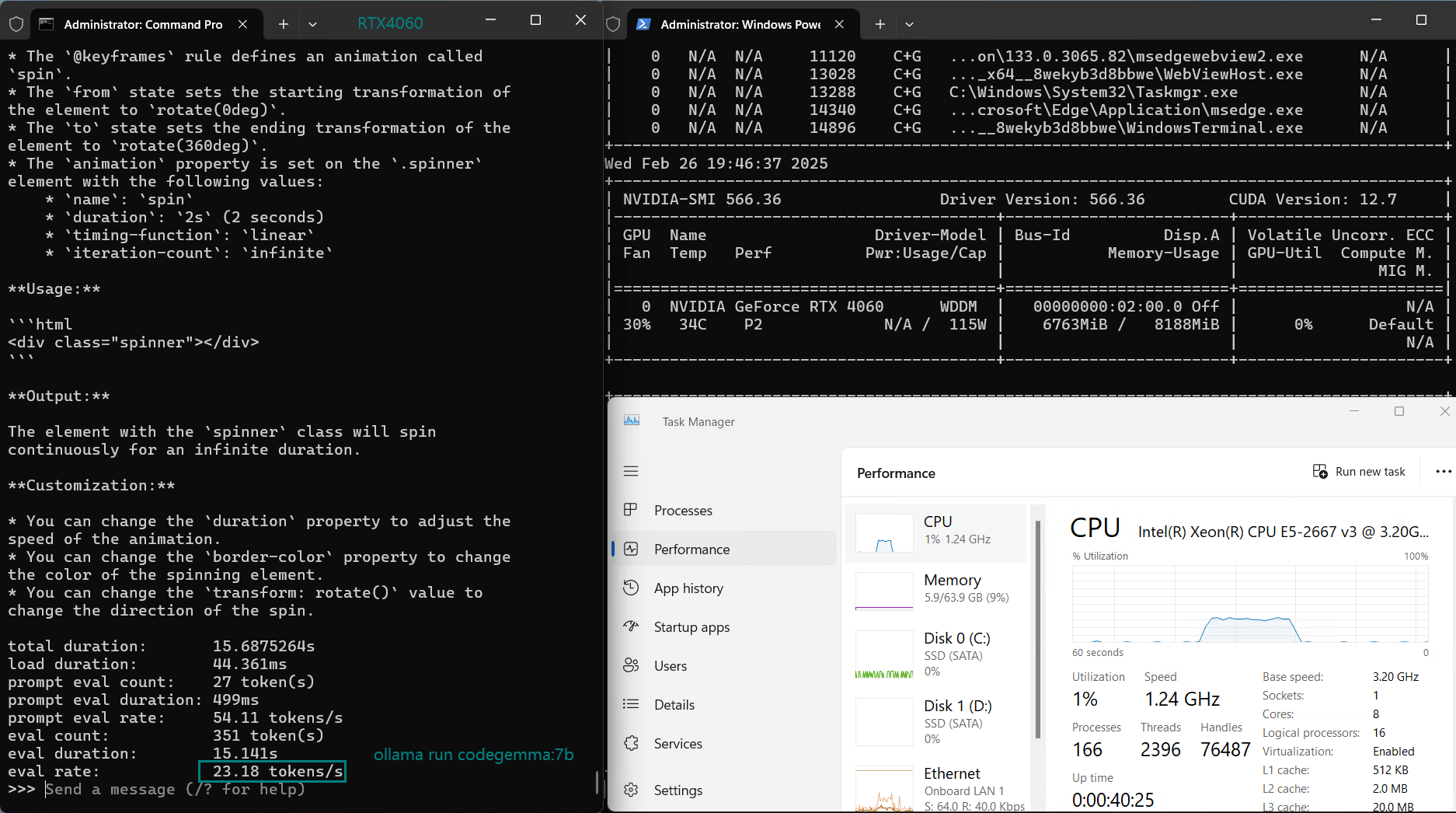
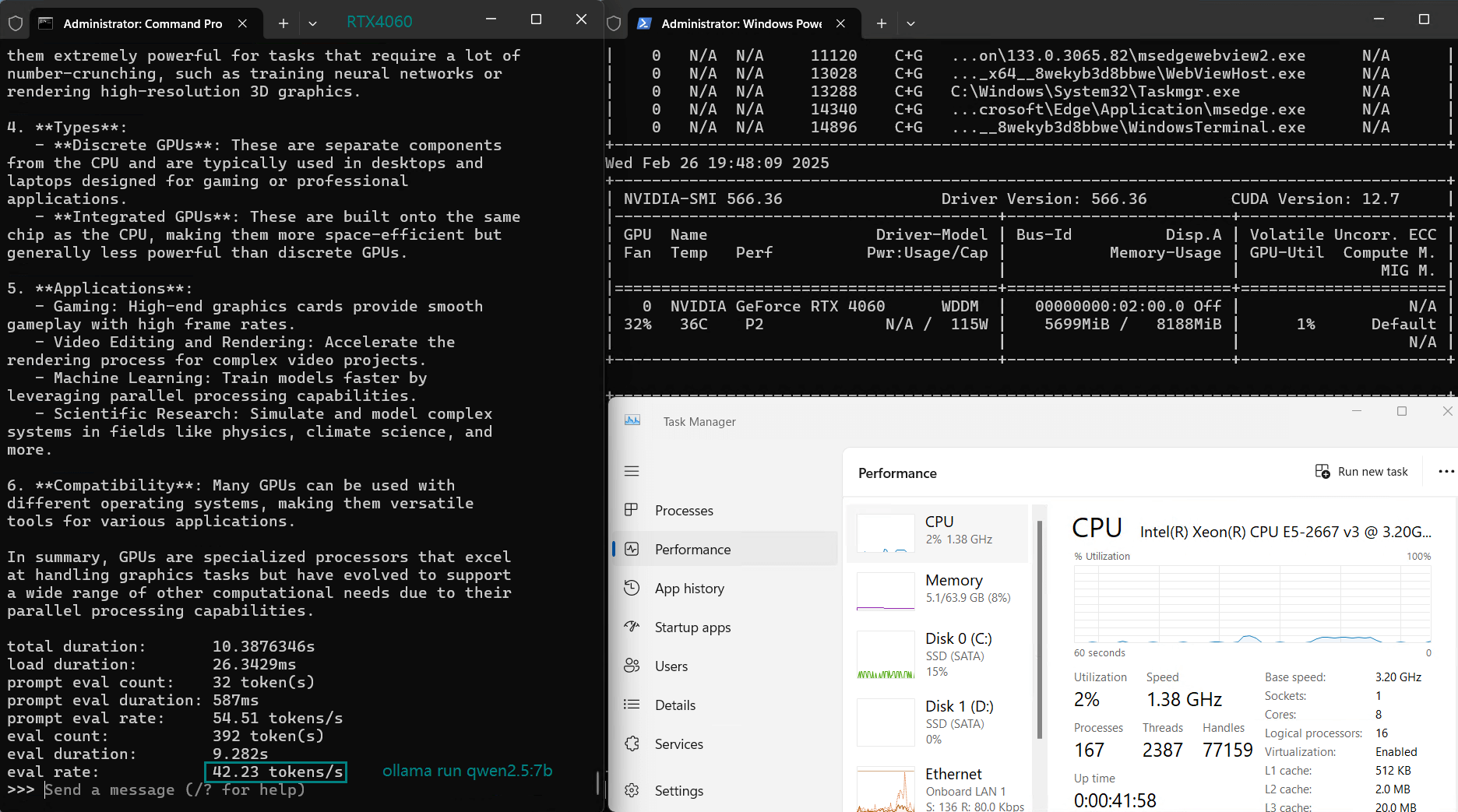
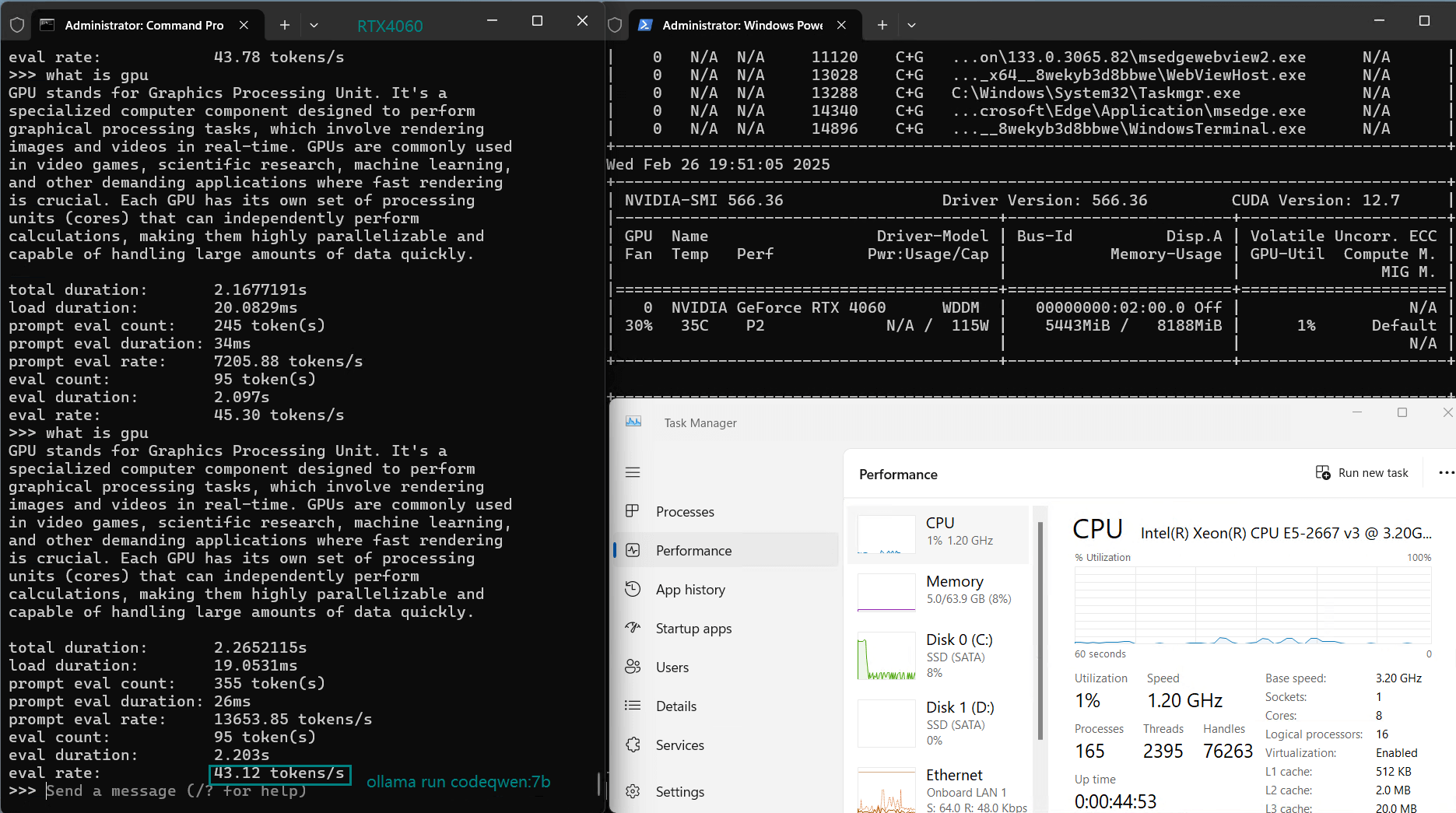
| Eval Rate(tokens/s) | 42.60 | 41.27 | 52.93 | 8.03 | 41.70 | 52.69 | 50.91 | 22.39 | 18.0 | 23.18 | 42.23 | 43.12 |
Performance Analysis from the Benchmark
1️⃣. Best choice for models under 5.0GB
2️⃣. Not suitable for models 13b and above
Due to memory limitations, LLaMA 2 (13B) performs poorly on RTX 4060 Server with low GPU utilization (25-42%), indicating that RTX 4060 cannot be used to infer models 13b and above.
3️⃣. After the model size reaches 5.0GB, the speed drops from 40+ to 20+ tokens/s
4️⃣. Cost-effective choice for models of 8b and below
Is the Nvidia RTX 4060 Server Good for LLM Inference??
✅ Pros of Using NNvidia RTX 4060 or Ollama
- Affordable $149/month RTX 4060 hosting
- Good performance for 7B-8B models
- DeepSeek-Coder & Mistral run efficiently at 50+ tokens/s
❌ Limitations of Nvidia RTX 4060 Server for Ollama
- Limited VRAM (8GB) struggles with 13B models
- LLaMA 2 (13B) underutilizes GPU
Get Started with RTX4060 Hosting for LLMs
Basic GPU Dedicated Server - RTX 4060
- 64GB RAM
- Eight-Core E5-2690
- 120GB SSD + 960GB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia GeForce RTX 4060
- Microarchitecture: Ada Lovelace
- CUDA Cores: 3072
- Tensor Cores: 96
- GPU Memory: 8GB GDDR6
- FP32 Performance: 15.11 TFLOPS
- Ideal for video edting, rendering, android emulators, gaming and light AI tasks.
Professional GPU VPS - A4000
- 32GB RAM
- 24 CPU Cores
- 320GB SSD
- 300Mbps Unmetered Bandwidth
- Once per 2 Weeks Backup
- OS: Linux / Windows 10/ Windows 11
- Dedicated GPU: Quadro RTX A4000
- CUDA Cores: 6,144
- Tensor Cores: 192
- GPU Memory: 16GB GDDR6
- FP32 Performance: 19.2 TFLOPS
- Available for Rendering, AI/Deep Learning, Data Science, CAD/CGI/DCC.
Advanced GPU Dedicated Server - V100
- 128GB RAM
- Dual 12-Core E5-2690v3
- 240GB SSD + 2TB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia V100
- Microarchitecture: Volta
- CUDA Cores: 5,120
- Tensor Cores: 640
- GPU Memory: 16GB HBM2
- FP32 Performance: 14 TFLOPS
- Cost-effective for AI, deep learning, data visualization, HPC, etc
Enterprise GPU Dedicated Server - RTX 4090
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: GeForce RTX 4090
- Microarchitecture: Ada Lovelace
- CUDA Cores: 16,384
- Tensor Cores: 512
- GPU Memory: 24 GB GDDR6X
- FP32 Performance: 82.6 TFLOPS
- Perfect for 3D rendering/modeling , CAD/ professional design, video editing, gaming, HPC, AI/deep learning.
Summary
Nvidia RTX 4060 is a cost-effective choice for models of 9B and below. Most models of 7B-8B and below run smoothly, with GPU utilization of 70%-90%, and inference speed stable at 40+ tokens/s. It is a cost-effective LLM inference solution.
Ollama 4060, Ollama RTX4060, Nvidia RTX4060 hosting, Benchmark RTX4060, Ollama benchmark, RTX4060 for LLMs inference, Nvidia RTX4060 rental