
























Dual A100 vLLM Benchmark: Best-In-Class Inference for 14B–32B Hugging Face LLMs
Large Language Models (LLMs) continue to grow in scale and capability, but serving them efficiently—especially in production environments—demands the right infrastructure. In this benchmark, we explore the inference performance of dual NVIDIA A100 40GB GPUs (total 80GB) using vLLM across popular Hugging Face models like Gemma 3-27B, Qwen 32B, LLaMA 3-8B, and DeepSeek 14B–32B.
With tensor-parallel-size set to 2 and NVLink enabled, this setup represents the gold standard for high-throughput, low-latency inference of large 14B–32B models.
Test Overview
1. A Single A100 40GB GPU Details(with NVLink):
- GPU: Nvidia A100
- Microarchitecture: Ampere
- Compute capability: 8.0
- CUDA Cores: 6912
- Tensor Cores: 432
- Memory: 40GB HBM2
- FP32 performance: 19.5 TFLOPS
2. Test Project Code Source:
- We used this git project to build the environment(https://github.com/vllm-project/vllm)
3. The Following Models from Hugging Face were Tested:
- google/gemma-3-12b-it
- google/gemma-3-27b-it
- meta-llama/Llama-3.1-8B-Instruct
- deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
- deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
- Qwen/QwQ-32B
4. The Test Parameters are Preset as Follows:
- Input length: 100 tokens
- Output length: 600 tokens
- --tensor-parallel-size 2
- --max-model-len 4096
5. We conducted two rounds of 2*A100 vLLM tests under different concurrent request loads:
- Scenario 1: 50 concurrent requests
- Scenario 2: 100 concurrent requests
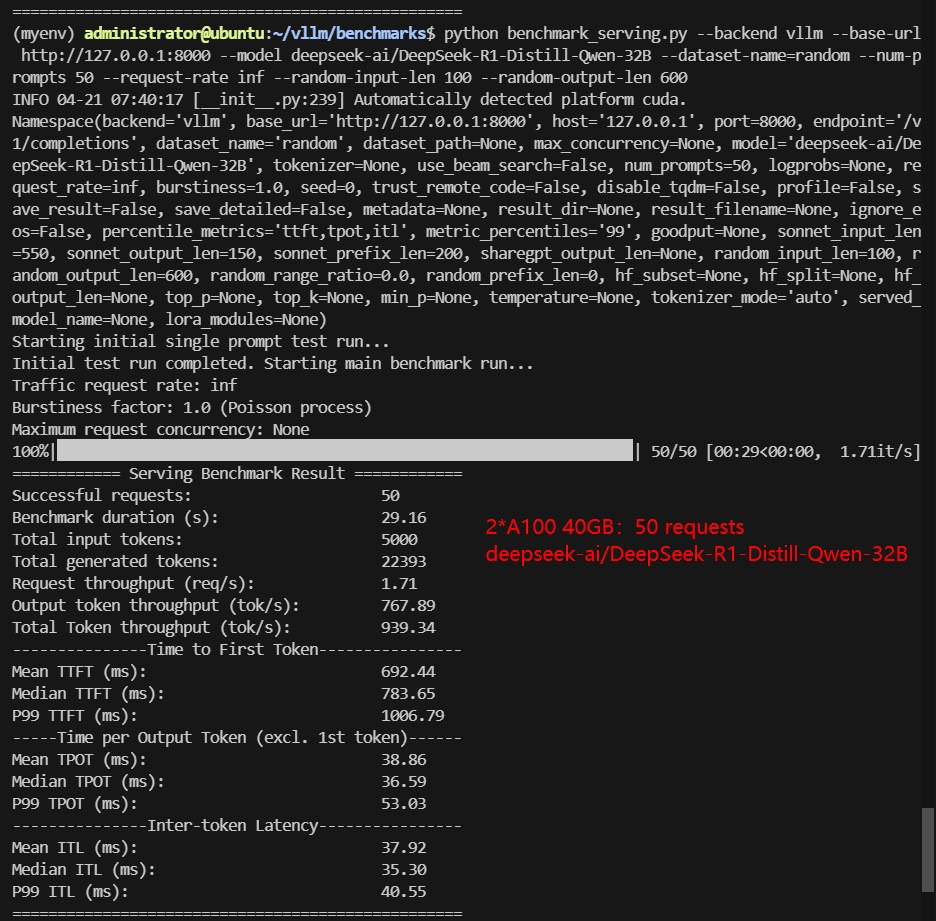
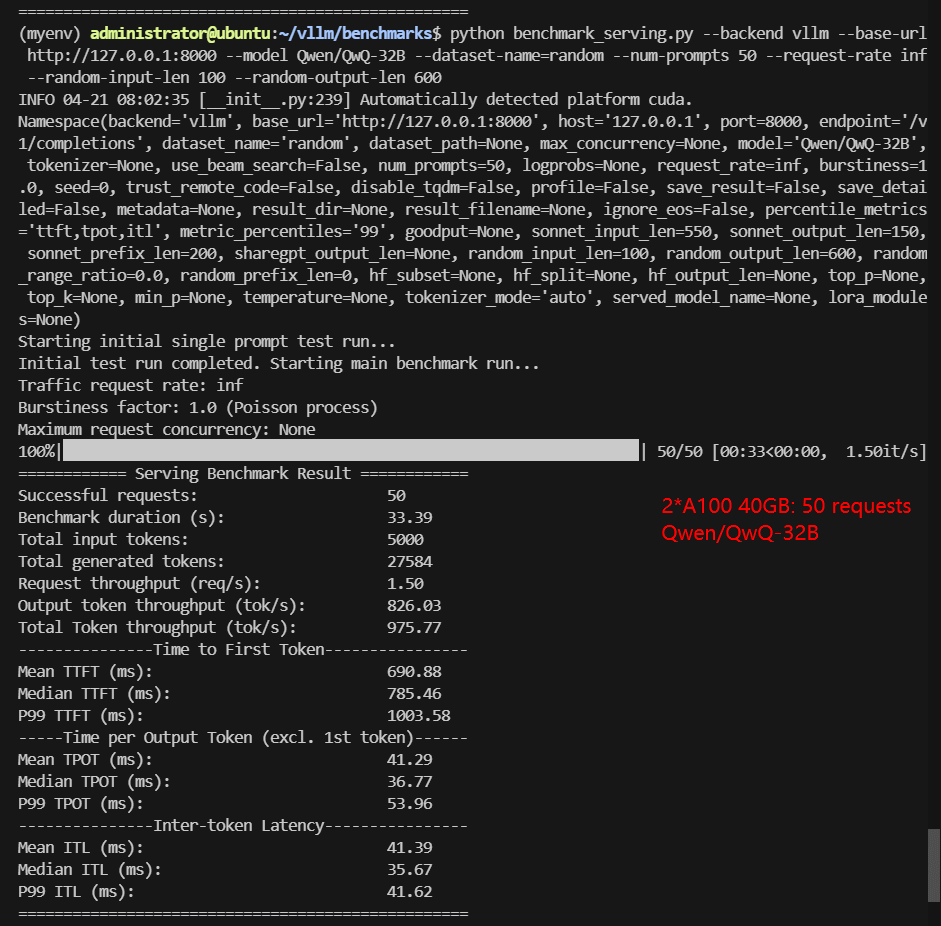
2*A100 Benchmark for Scenario 1: 50 Concurrent Requests
| Models | google/gemma-3-12b-it | google/gemma-3-27b-it | meta-llama/Llama-3.1-8B-Instruct | deepseek-ai/DeepSeek-R1-Distill-Qwen-14B | deepseek-ai/DeepSeek-R1-Distill-Qwen-32B | Qwen/QwQ-32B |
|---|---|---|---|---|---|---|
| Quantization | 16 | 16 | 16 | 16 | 16 | 16 |
| Size(GB) | 23 | 51 | 15 | 28 | 62 | 62 |
| Backend/Platform | vLLM | vLLM | vLLM | vLLM | vLLM | vLLM |
| Request Numbers | 50 | 50 | 50 | 50 | 50 | 50 |
| Benchmark Duration(s) | 12.97 | 22.77 | 7.28 | 11.60 | 29.16 | 33.39 |
| Total Input Tokens | 5000 | 5000 | 5000 | 5000 | 5000 | 5000 |
| Total Generated Tokens | 27004 | 23052 | 22103 | 17528 | 22393 | 27584 |
| Request (req/s) | 3.86 | 2.20 | 6.87 | 4.31 | 1.71 | 1.50 |
| Input (tokens/s) | 385.61 | 219.59 | 687.19 | 430.91 | 171.45 | 149.74 |
| Output (tokens/s) | 2082.65 | 1012.40 | 3037.77 | 1510.59 | 767.89 | 826.03 |
| Total Throughput (tokens/s) | 2468.26 | 1231.99 | 3724.96 | 1941.50 | 939.34 | 975.77 |
| Median TTFT (ms) | 128.42 | 710.96 | 206.38 | 386.49 | 783.65 | 785.46 |
| P99 TTFT (ms) | 154.23 | 888.83 | 307.44 | 524.14 | 1006.79 | 1003.58 |
| Median TPOT (ms) | 21.37 | 34.97 | 11.70 | 18.70 | 36.59 | 36.77 |
| P99 TPOT (ms) | 22.48 | 215.47 | 15.78 | 29.99 | 53.03 | 53.96 |
| Median Eval Rate (tokens/s) | 46.79 | 28.60 | 85.47 | 53.48 | 27.33 | 27.20 |
| P99 Eval Rate (tokens/s) | 44.48 | 4.64 | 63.37 | 33.34 | 36.59 | 18.53 |
✅ Key Takeaways:
- 8B models (Llama-3) dominate in speed (~3.7K tokens/s). Gemma-3-12B performs well (~2.4K tokens/s, low TTFT). 32B models (DeepSeek, Qwen) are usable but slower (~1K tokens/s).
- Even at 50 concurrent requests, models up to 32B run smoothly without hitting performance ceilings.
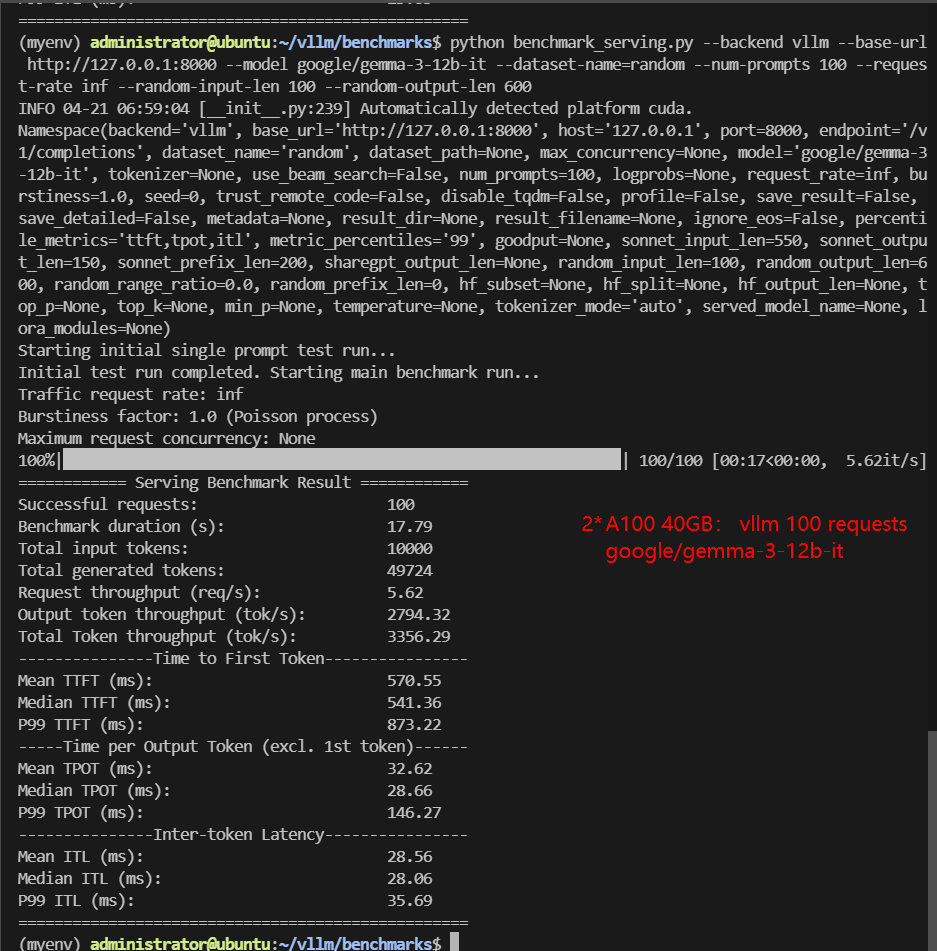
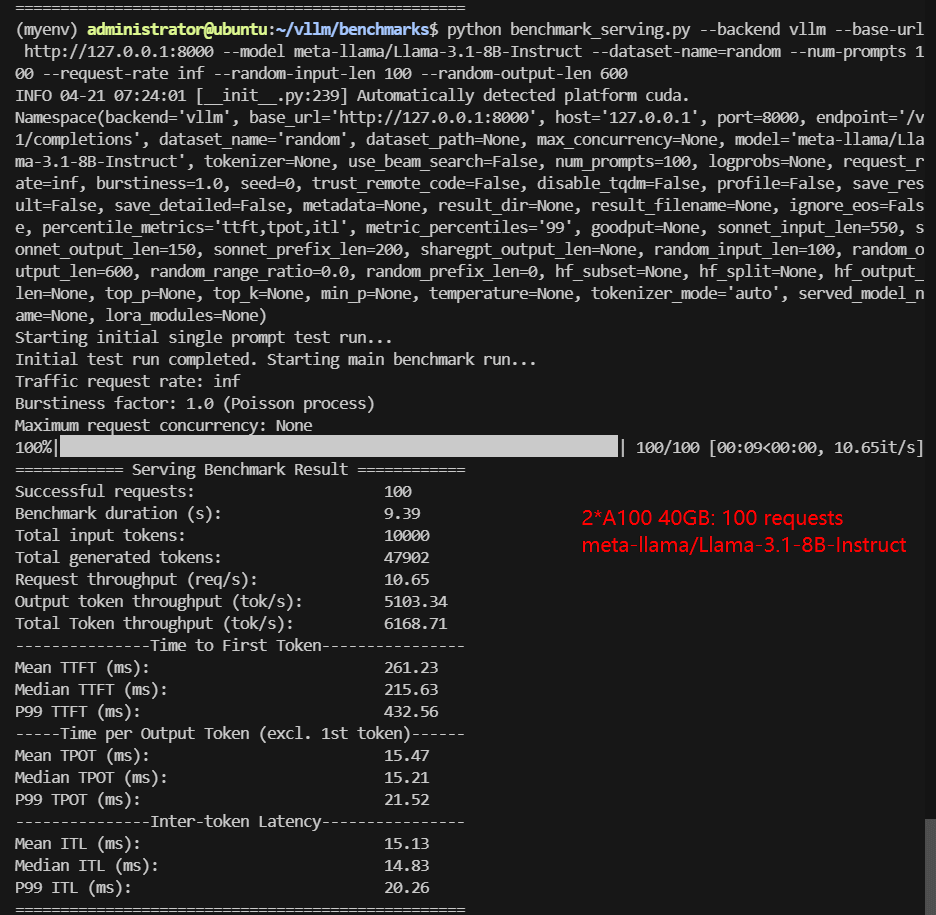
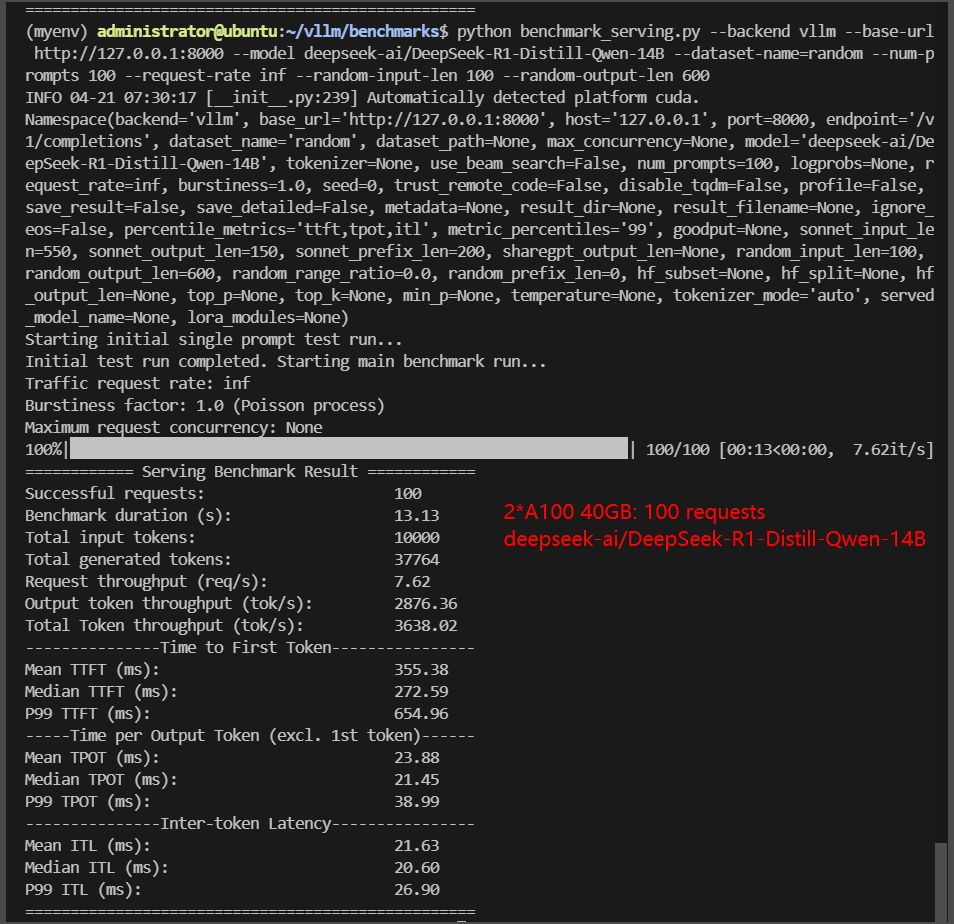
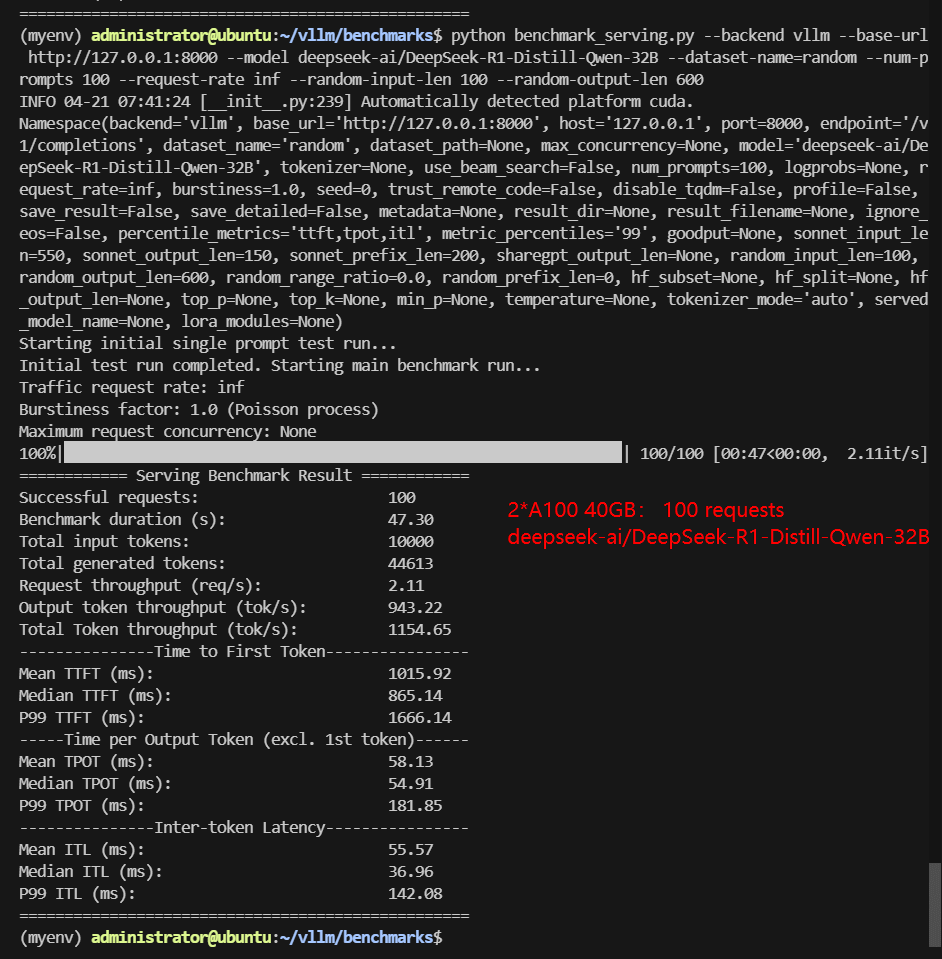
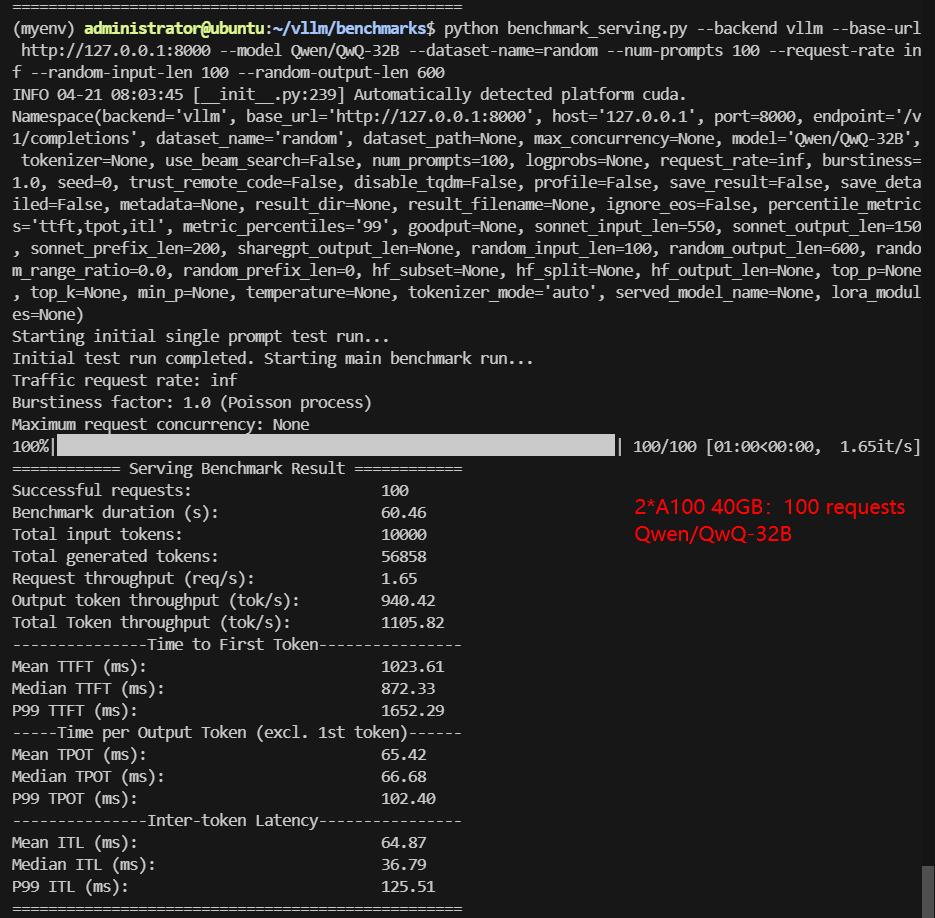
2*A100 Benchmark for Scenario 2: 100 Concurrent Requests
| Models | google/gemma-3-12b-it | google/gemma-3-27b-it | meta-llama/Llama-3.1-8B-Instruct | deepseek-ai/DeepSeek-R1-Distill-Qwen-14B | deepseek-ai/DeepSeek-R1-Distill-Qwen-32B | Qwen/QwQ-32B |
|---|---|---|---|---|---|---|
| Quantization | 16 | 16 | 16 | 16 | 16 | 16 |
| Size(GB) | 23 | 51 | 15 | 28 | 62 | 62 |
| Backend/Platform | vLLM | vLLM | vLLM | vLLM | vLLM | vLLM |
| Request Numbers | 100 | 100 | 100 | 100 | 100 | 100 |
| Benchmark Duration(s) | 17.79 | 41.23 | 9.39 | 13.13 | 47.30 | 60.46 |
| Total Input Tokens | 10000 | 10000 | 10000 | 10000 | 10000 | 10000 |
| Total Generated Tokens | 49724 | 45682 | 47902 | 37764 | 44613 | 56858 |
| Request (req/s) | 5.62 | 2.43 | 10.65 | 7.62 | 2.11 | 1.65 |
| Input (tokens/s) | 561.97 | 242.55 | 1065.37 | 761.66 | 211.43 | 165.4 |
| Output (tokens/s) | 2794.32 | 1108.03 | 5103.34 | 2876.36 | 943.22 | 940.42 |
| Total Throughput (tokens/s) | 3356.29 | 1350.58 | 6168.71 | 3638.02 | 1154.65 | 1105.82 |
| Median TTFT (ms) | 541.36 | 651.69 | 215.63 | 272.59 | 865.14 | 872.33 |
| P99 TTFT (ms) | 873.22 | 1274.52 | 432.56 | 654.96 | 1666.14 | 1652.29 |
| Median TPOT (ms) | 28.66 | 49.01 | 15.21 | 21.45 | 54.91 | 66.68 |
| P99 TPOT (ms) | 146.27 | 325.90 | 21.52 | 38.99 | 181.85 | 102.40 |
| Median Eval Rate (tokens/s) | 34.89 | 20.40 | 65.75 | 46.62 | 18.21 | 14.99 |
| P99 Eval Rate (tokens/s) | 6.84 | 3.07 | 46.47 | 25.65 | 5.50 | 9.77 |
✅ Key Takeaways:
- Throughput scales almost linearly (Llama-3 8b hits 6K tokens/s). 14B-32B models remain stable—no latency spikes at 100 reqs.
- Gemma-3-12B runs smoothly (3.3K tokens/s), proving multi-GPU efficiency.
- Even at 100 requests, throughput continues to increase and latency remains low, confirming no bottleneck—this system can likely handle 200+ concurrent inferences.
Why Dual A100 40GB Is the Best Fit for 14B–32B Models
✅ Perfect Match for Multi-modal Giants
✅ NVLink & Tensor Parallelism Matter
Operational Tips & Cautions
⚠️ -max-model-len 4096 or 8192
⚠️ GPU Temperatures
Get Started with 2*A100 GPU Server Hosting
Interested in optimizing your LLM deployment? Check out GPU server rental services or explore alternative GPUs for high-end AI inference.
Enterprise GPU Dedicated Server - A100
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia A100
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 40GB HBM2
- FP32 Performance: 19.5 TFLOPS
- Good alternativeto A800, H100, H800, L40. Support FP64 precision computation, large-scale inference/AI training/ML.etc
Multi-GPU Dedicated Server - 2xA100
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 1Gbps
- OS: Windows / Linux
- GPU: Nvidia A100
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 40GB HBM2
- FP32 Performance: 19.5 TFLOPS
- Free NVLink Included
- A Powerful Dual-GPU Solution for Demanding AI Workloads, Large-Scale Inference, ML Training.etc. A cost-effective alternative to A100 80GB and H100, delivering exceptional performance at a competitive price.
Enterprise GPU Dedicated Server - A100(80GB)
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia A100
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 80GB HBM2e
- FP32 Performance: 19.5 TFLOPS
Enterprise GPU Dedicated Server - H100
- 256GB RAM
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- GPU: Nvidia H100
- Microarchitecture: Hopper
- CUDA Cores: 14,592
- Tensor Cores: 456
- GPU Memory: 80GB HBM2e
- FP32 Performance: 183TFLOPS
Conclusion: Dual A100 (Total 80GB) Is the Production-Ready Workhorse for 14B–32B LLMs
Dual A100 40GB GPUs (with NVLink) are an excellent choice for 14B-32B models, including Gemma-3-27B, achieving 3K-6K tokens/s at 100+ requests.
- For startups & researchers: Cost-effective alternative to H100.
- For enterprises: Stable for 200-300 concurrent users (no bottleneck detected).
- Always use --tensor-parallel-size 2 for maximum throughput!
Attachment: Video Recording of 2*A100 vLLM Benchmark
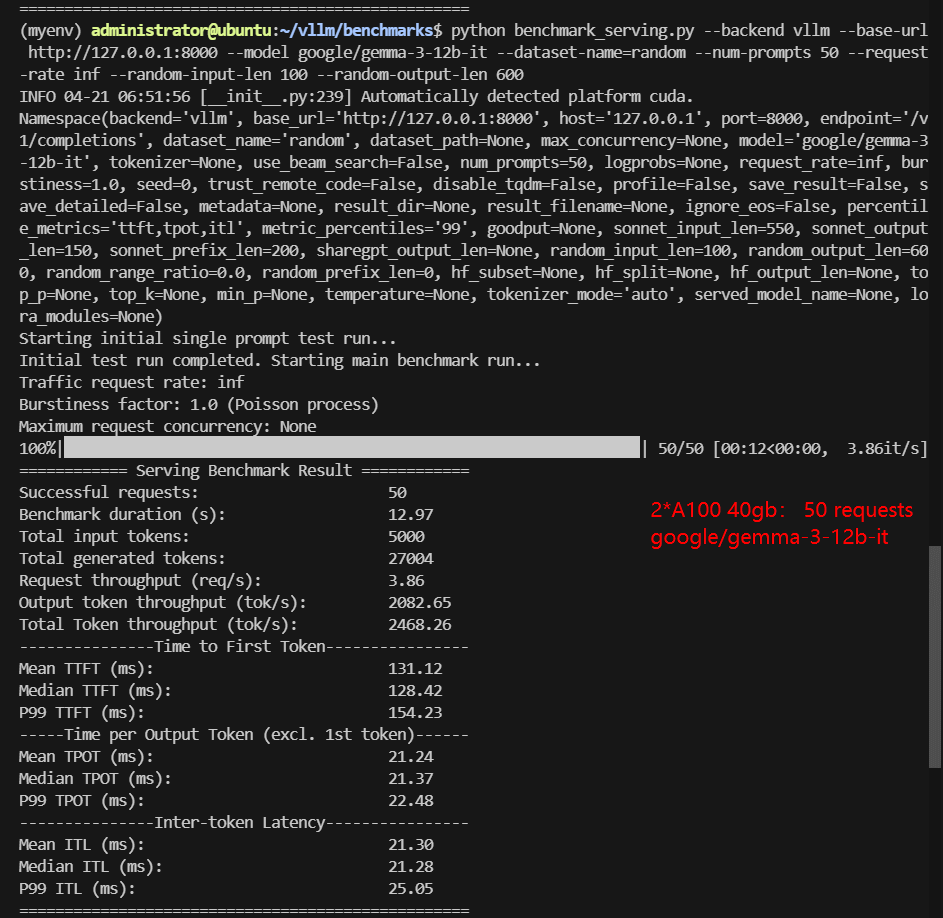
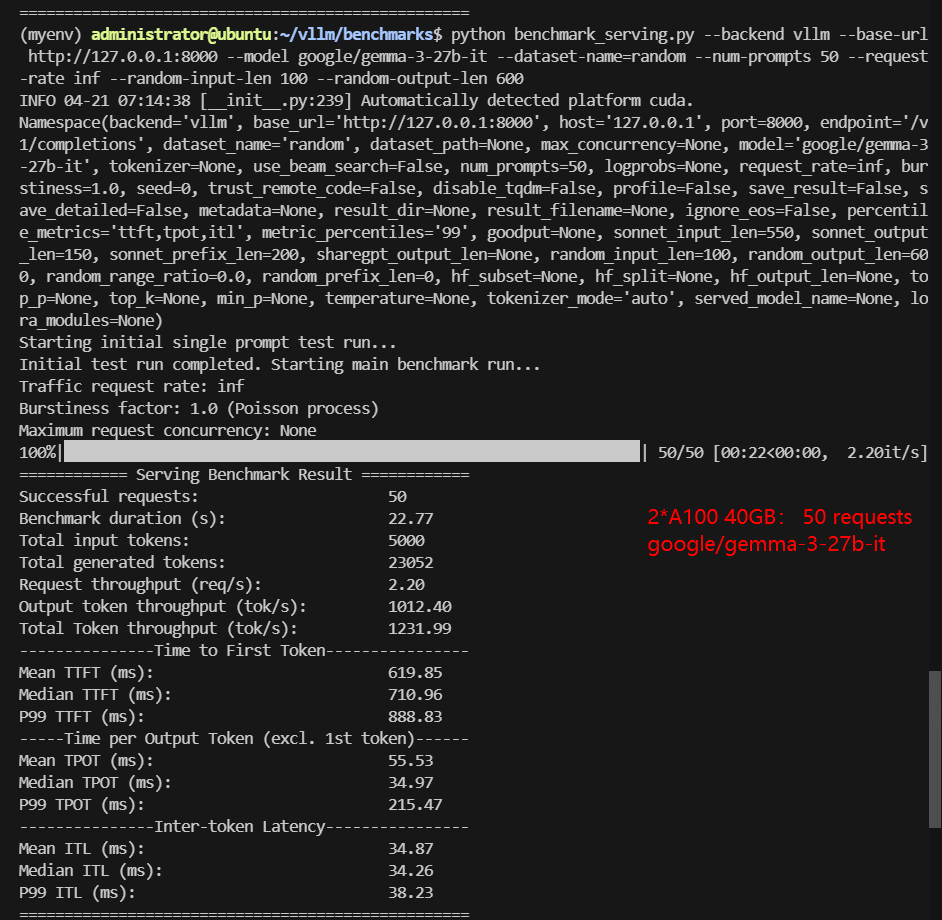
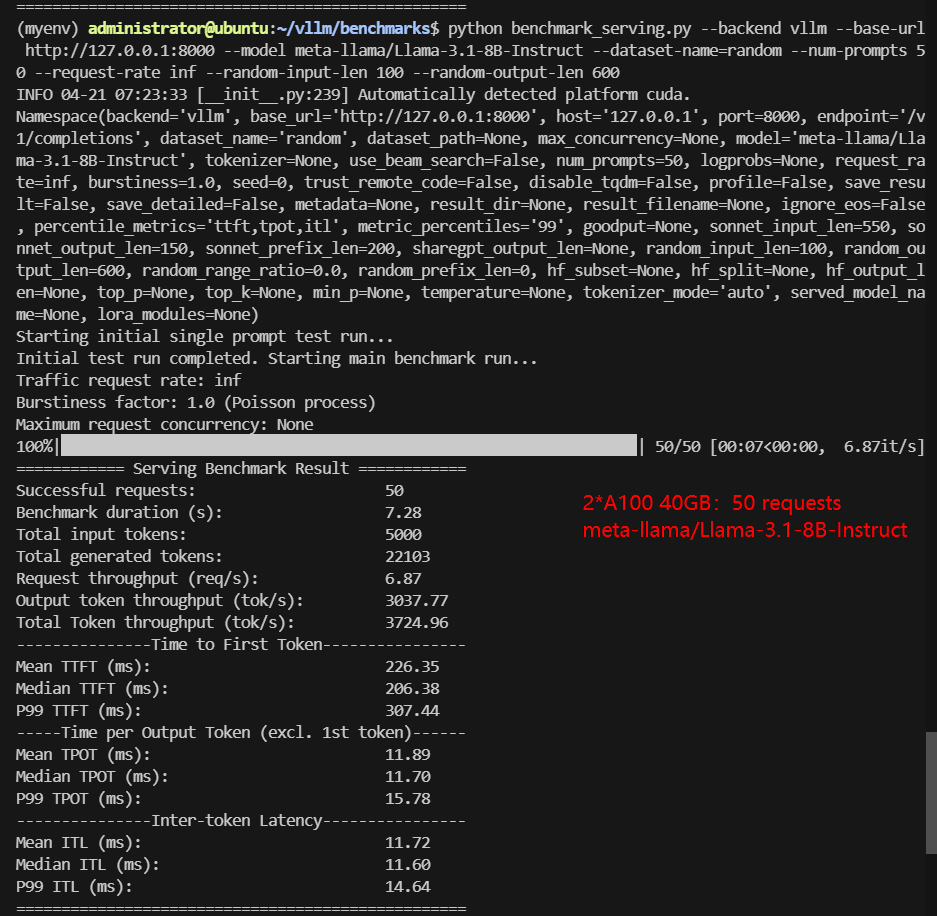
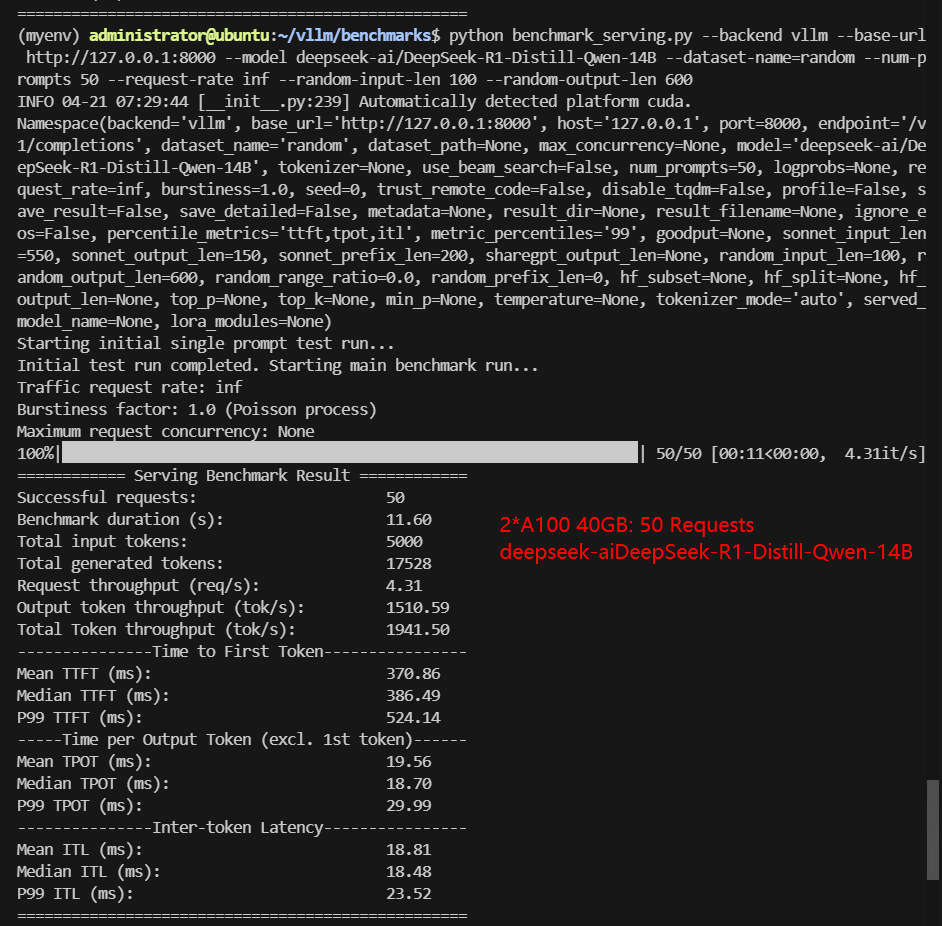

Data Item Explanation in the Table:
- Quantization: The number of quantization bits. This test uses 16 bits, a full-blooded model.
- Size(GB): Model size in GB.
- Backend: The inference backend used. In this test, vLLM is used.
- Successful Requests: The number of requests processed.
- Benchmark duration(s): The total time to complete all requests.
- Total input tokens: The total number of input tokens across all requests.
- Total generated tokens: The total number of output tokens generated across all requests.
- Request (req/s): The number of requests processed per second.
- Input (tokens/s): The number of input tokens processed per second.
- Output (tokens/s): The number of output tokens generated per second.
- Total Throughput (tokens/s): The total number of tokens processed per second (input + output).
- Median TTFT(ms): The time from when the request is made to when the first token is received, in milliseconds. A lower TTFT means that the user is able to get a response faster.
- P99 TTFT (ms): The 99th percentile Time to First Token, representing the worst-case latency for 99% of requests—lower is better to ensure consistent performance.
- Median TPOT(ms): The time required to generate each output token, in milliseconds. A lower TPOT indicates that the system is able to generate a complete response faster.
- P99 TPOT (ms): The 99th percentile Time Per Output Token, showing the worst-case delay in token generation—lower is better to minimize response variability.
- Median Eval Rate(tokens/s): The number of tokens evaluated per second per user. A high evaluation rate indicates that the system is able to serve each user efficiently.
- P99 Eval Rate(tokens/s): The number of tokens evaluated per second by the 99th percentile user represents the worst user experience.
Dual A100 vLLM Benchmark, 2x A100 40GB LLM Hosting, Hugging Face 32B Inference, Multi-GPU vLLM Benchmark, tensor-parallel-size 2 benchmark,VInfer gemma-3 on A100, Qwen 32B GPU requirements, A100 vs H100 for LLMs, Best GPU for 32B LLM inference, Hosting 14B–32B LLMs on vLLM