
Video: Pro5000 vLLM Benchmark with Hugging Face LLMs

NVIDIA RTX Pro 5000 Blackwell vLLM Inference Benchmark Report
In this benchmark, we evaluate the NVIDIA RTX Pro 5000 Blackwell Server GPU as an inference platform using vLLM, a high-performance LLM serving engine designed for efficient memory management and high request parallelism. By testing a diverse set of open-source models under identical conditions, this report aims to provide a practical view of how RTX Pro 5000 performs in real-world inference scenarios, rather than isolated peak benchmarks.
The results focus on key serving metrics such as token throughput, request rate, and latency distribution, helping infrastructure teams and AI practitioners better understand where RTX Pro 5000 fits in modern LLM deployment strategies.
Test Overview
Hardware and Software Stack
- GPU: Nvidia RTX Pro 5000 Blackwell Server Edition
- Inference Engine: vLLM
- Backend: CUDA + vLLM Continuous Batching
- Parallelism: --tensor-parallel-size = 1, Single-GPU inference, no model sharding
Pro 5000 GPU Details
- GPU: Nvidia RTX Pro 5000 Blackwell Server Edition
- Microarchitecture: Blackwell
- Compute capability: 12
- CUDA Cores: 14,080
- Tensor Cores: 440
- GPU Memory: 48GB GDDR7
- FP32 Performance: 66.94 TFLOPS
Benchmark Tool
Benchmark tests were executed using the official vLLM repository:
git clone https://github.com/vllm-project/vllm.gitThe benchmark_serving.py script was used for all measurements.
Unified Benchmark Parameters
All models were tested with the same inference load configuration to ensure fair comparison:
--max-model-len 4096
--tensor-parallel-size 1
--num-prompts 50
--request-rate inf
--random-input-len 100
--random-output-len 600This configuration simulates a realistic API / chat inference workload with moderate concurrency and long-form outputs.
Models Tested
The benchmark includes a mix of mainstream open-source models and quantized variants deployed from Hugging Face:
- meta-llama/Llama-3.1-8B (FP16)
- Qwen/Qwen3-8B (FP16)
- google/gemma-3-12b-it (FP16)
- openai/gpt-oss-20b (INT4 quantized)
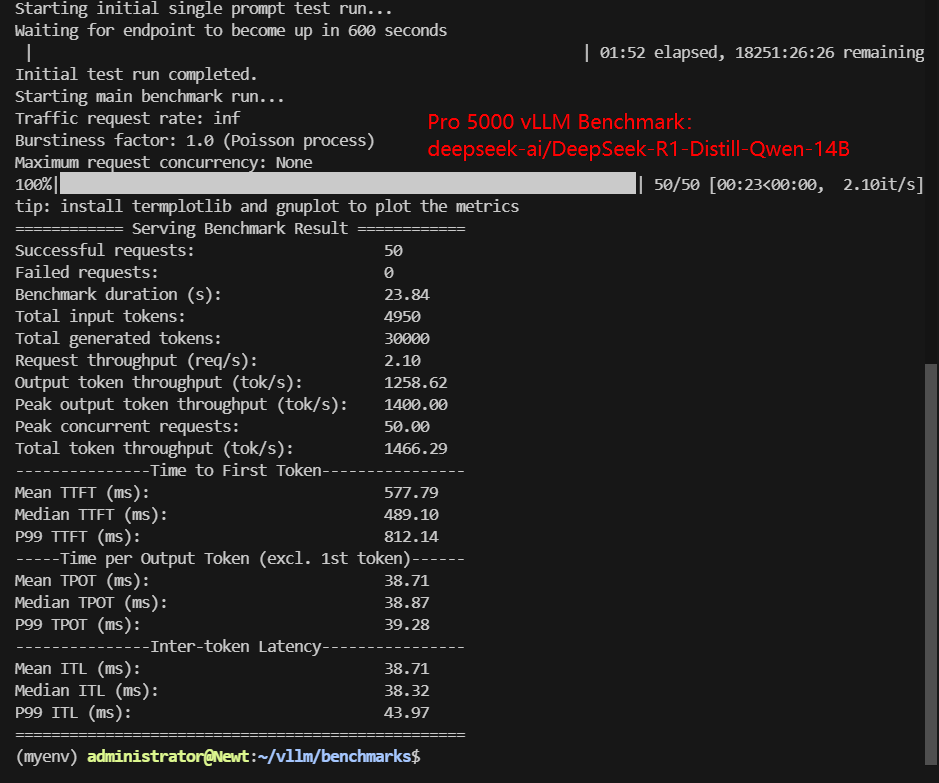
- deepseek-ai/DeepSeek-R1-Distill-Qwen-14B (FP16)
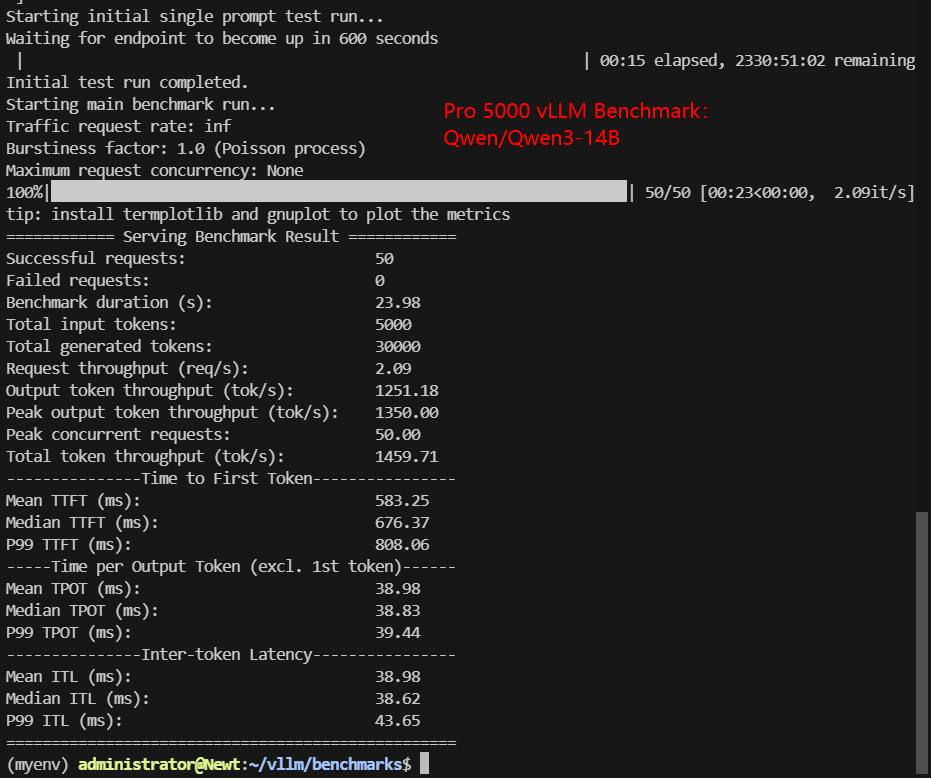
- Qwen/Qwen3-14B (FP16)
All models were served using vLLM with identical runtime parameters to ensure comparability.
Key Performance Results: Pro5000 vLLM Benchmark
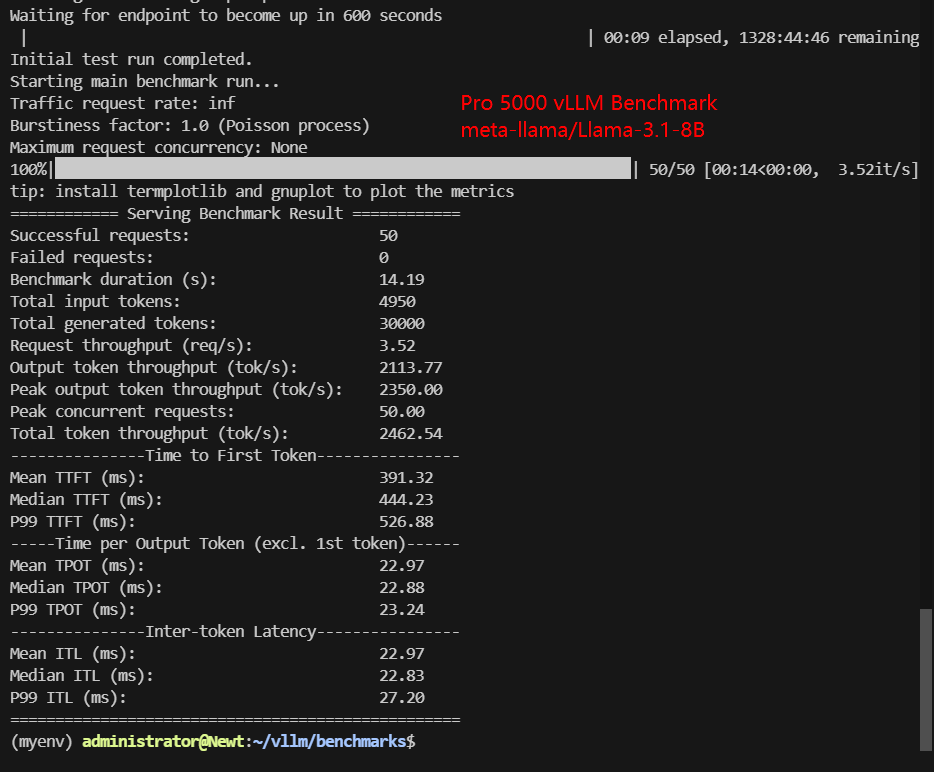
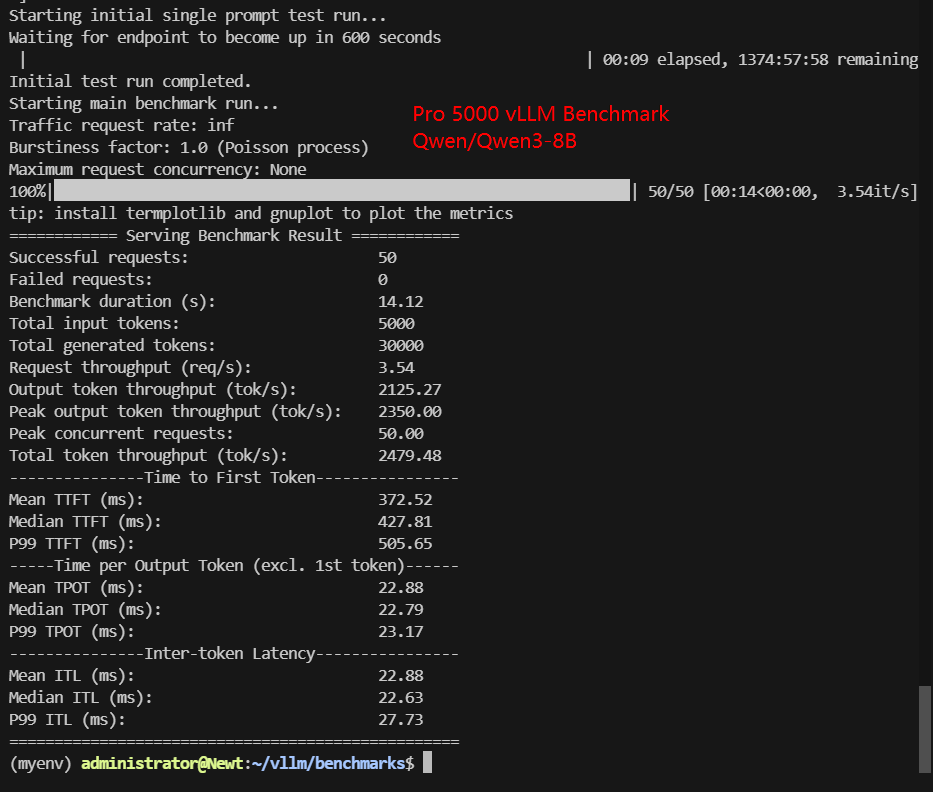
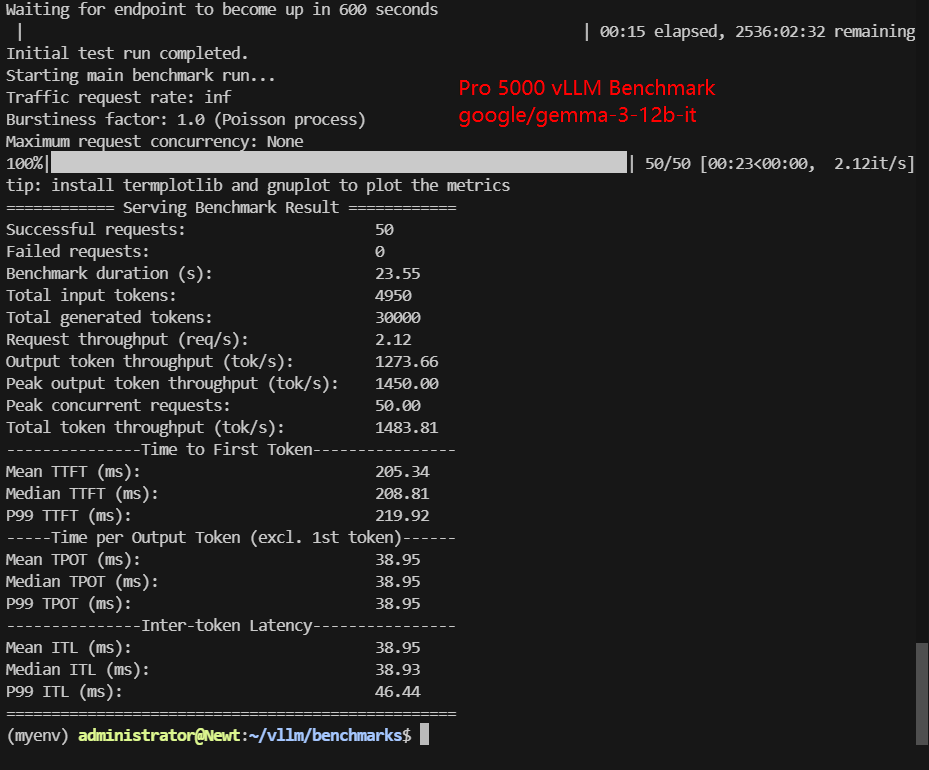
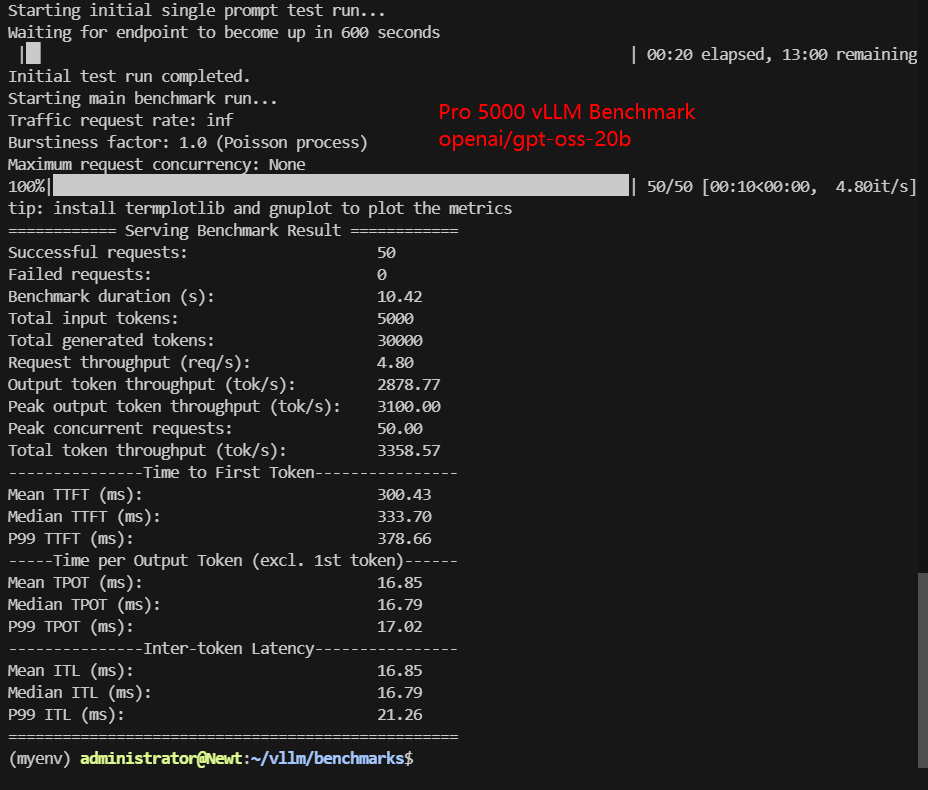
| Models | Llama-3.1-8B | Qwen3-8B | gemma-3-12b-it | gpt-oss-20b | DeepSeek-R1-Distill-Qwen-14B | Qwen3-14B |
|---|---|---|---|---|---|---|
| Quantization | 16 | 16 | 16 | 4 | 16 | 16 |
| Size(GB) | 15GB | 15GB | 23GB | 13GB | 28GB | 28GB |
| Backend/Platform | vLLM | vLLM | vLLM | vLLM | vLLM | vLLM |
| Request Numbers | 50 | 50 | 50 | 50 | 50 | 50 |
| Benchmark Duration(s) | 14.19 | 14.12 | 23.55 | 10.42 | 23.84 | 23.98 |
| Total input tokens | 5000 | 5000 | 5000 | 5000 | 4950 | 4950 |
| Total Generated Tokens | 30000 | 30000 | 30000 | 30000 | 30000 | 30000 |
| Request (req/s) | 3.52 | 3.54 | 2.12 | 4.80 | 2.10 | 2.09 |
| Input (tokens/s) | 348.77 | 354.21 | 210.15 | 479.8 | 207.67 | 208.53 |
| Output (tokens/s) | 2113.77 | 2125.27 | 1273.66 | 2878.77 | 1258.62 | 1251.18 |
| Total Throughput (tokens/s) | 2462.54 | 2479.48 | 1483.81 | 3358.57 | 1466.29 | 1459.71 |
| Median TTFT(ms) | 444.23 | 427.81 | 208.81 | 333.70 | 489.10 | 676.37 |
| P99 TTFT (ms) | 526.88 | 505.65 | 219.92 | 378.66 | 812.14 | 808.06 |
| Median TPOT(ms) | 22.88 | 22.79 | 38.95 | 16.79 | 38.87 | 38.83 |
| P99 TPOT(ms) | 23.24 | 23.17 | 38.95 | 17.02 | 39.28 | 39.44 |
| Median ITL (ms) | 22.83 | 22.63 | 38.93 | 16.79 | 38.32 | 38.62 |
| P99 ITL (ms) | 27.20 | 27.73 | 46.44 | 21.26 | 43.97 | 43.65 |
Throughput Performance Analysis
Overall Token Throughput
The RTX Pro 5000 Blackwell demonstrates strong inference throughput across small and mid-sized models.
- 8B-class FP16 models (LLaMA 3.1 8B, Qwen3 8B) consistently deliver ~2,460–2,480 tokens/s, indicating that the GPU is well-matched for high-QPS, low-latency serving in this parameter range.
- Gemma 3 12B shows a reduced throughput of ~1,484 tokens/s, reflecting the higher compute and memory demands of instruction-tuned 12B models.
- GPT-OSS 20B (INT4) achieves the highest total throughput at ~3,359 tokens/s, outperforming all FP16 models despite its larger parameter count.
- 14B FP16 models (DeepSeek R1 Distill, Qwen3 14B) stabilize around ~1,460 tokens/s, forming a clear performance tier below 8B models but above larger unquantized architectures.
Key Observation:
Quantization has a larger impact on throughput than raw parameter count. The INT4 GPT-OSS 20B model benefits significantly from reduced memory bandwidth and compute requirements.
Request-Level Performance
Requests per Second (req/s)
- GPT-OSS 20B (INT4): 4.80 req/s
- 8B FP16 models: ~3.5 req/s
- 12B–14B FP16 models: ~2.1 req/s
This pattern confirms that serving capacity on RTX Pro 5000 is primarily constrained by model precision and effective memory footprint, rather than nominal model size alone.
Latency Characteristics
Time to First Token (TTFT)
- Lowest TTFT: Gemma 3 12B (~209 ms median)
- 8B models: ~430–445 ms median
- GPT-OSS 20B (INT4): ~334 ms median
- 14B FP16 models: 490–676 ms median, with higher P99 values
While Gemma shows excellent TTFT, its overall throughput is lower, highlighting a trade-off between fast prompt processing and sustained token generation.
Token Generation Latency (TPOT / ITL)
- GPT-OSS 20B (INT4) achieves ~16.8 ms median TPOT, the best result in the test.
- 8B FP16 models remain efficient at ~22–23 ms.
- 12B–14B FP16 models average ~39 ms, nearly doubling per-token latency.
This confirms that Blackwell’s architecture paired with quantization is highly effective for steady-state generation workloads.
Stability and Tail Latency
P99 latency metrics remain stable across all models, with no extreme spikes observed. Even under infinite request rate pressure, the RTX Pro 5000 maintains predictable tail behavior, which is critical for production inference APIs and multi-tenant serving environments.
Key Findings
RTX Pro 5000 Blackwell is highly optimized for vLLM inference, especially for 8B–14B class models.
- INT4 quantization delivers outsized gains, enabling a 20B model to outperform smaller FP16 models in both throughput and latency.
- 8B FP16 models represent the best balance between quality, speed, and resource utilization for general-purpose deployment.
- 14B FP16 models are viable but latency-sensitive, making them better suited for lower-QPS or batch-oriented workloads.
vLLM’s scheduling and memory management effectively utilize Blackwell’s compute capabilities under sustained load.
Conclusion
The NVIDIA RTX Pro 5000 Blackwell Server GPU proves to be a strong inference platform for modern LLM workloads when paired with vLLM. It excels in scenarios requiring consistent throughput, controlled latency, and flexible model support.
For production inference:
- Choose 8B FP16 models for balanced performance.
- Use INT4 quantized models to maximize throughput and cost efficiency.
- Deploy 14B FP16 models selectively where model quality outweighs latency considerations.
Overall, RTX Pro 5000 positions itself as a capable and efficient GPU for small to mid-scale LLM inference, particularly in single-GPU vLLM deployments.
Attachment: Video Recording of Pro5000 vLLM Benchmark
Screenshot: Pro5000 vLLM Benchmark Results
Data Item Explanation in the Table
- Quantization: Indicates the numerical precision used for model weights, affecting memory usage and inference speed.
- Size (GB): Represents the approximate model memory footprint under the specified quantization, not necessarily peak GPU VRAM usage.
- Backend / Platform: Specifies the inference engine and runtime environment used for the benchmark.
- Tensor Parallel Size: Shows how many GPUs are used to run the model, with 1 meaning single-GPU inference.
- Max Model Length: Defines the maximum supported token length for input and output combined.
- Request Numbers: Indicates the total number of inference requests issued during the benchmark.
- Benchmark Duration (s): Measures the total time required to complete all benchmark requests.
- Total Input Tokens: The sum of all prompt tokens processed across requests.
- Total Generated Tokens: The total number of output tokens generated during the benchmark.
- Requests (req/s): Represents how many inference requests the system can handle per second.
- Input Throughput (tokens/s): Measures the rate at which input tokens are processed.
- Output Throughput (tokens/s): Measures the rate at which output tokens are generated.
- Total Throughput (tokens/s): Combines input and output token throughput to reflect overall inference efficiency.
- Median TTFT (ms): The median time from request submission to the first generated token.
- P99 TTFT (ms): The 99th-percentile time to first token, reflecting worst-case initial latency.
- Median TPOT (ms): The median time required to generate each output token after the first token.
- P99 TPOT (ms): The 99th-percentile per-token generation latency under load.
- Median ITL (ms): The median delay between consecutive output tokens during streaming generation.
- P99 ITL (ms): The 99th-percentile inter-token delay, indicating tail latency during output streaming.
Keywords:
Pro 5000 Blackwell,Pro5000 vLLM benchmark, vLLM inference performance, LLM inference GPU benchmark, Blackwell GPU inference, Pro 5000, vLLM throughput latency, LLM serving benchmark, Hugging Face vLLM test
Outline