Android EmulatorRunning multiple simulators simultaneously
Android EmulatorRunning multiple simulators simultaneously Rendering ServerGPU for HD image rendering
Rendering ServerGPU for HD image rendering Streaming ServerOBS Live Streaming, Recording
Streaming ServerOBS Live Streaming, Recording Web HostingStore and maintain files. Put website online
Web HostingStore and maintain files. Put website online Forex VPSRun multiple trading terminals and platforms
Forex VPSRun multiple trading terminals and platforms RDP ServerRemote Desktop Connection on Windows
RDP ServerRemote Desktop Connection on Windows VPN ServerSecure connection, protect your network traffic
VPN ServerSecure connection, protect your network traffic Database HostingSQL, NoSQL, and NewSQL database server hosting
Database HostingSQL, NoSQL, and NewSQL database server hosting Kubernetes HostingFully Managed Kubernetes Clusters
Kubernetes HostingFully Managed Kubernetes Clusters Colocation HostingRent Dedicated Half or Full Rack of Space
Colocation HostingRent Dedicated Half or Full Rack of Space









Which GPU is the Cheapest for Qwen3-32B Inference with vLLM?
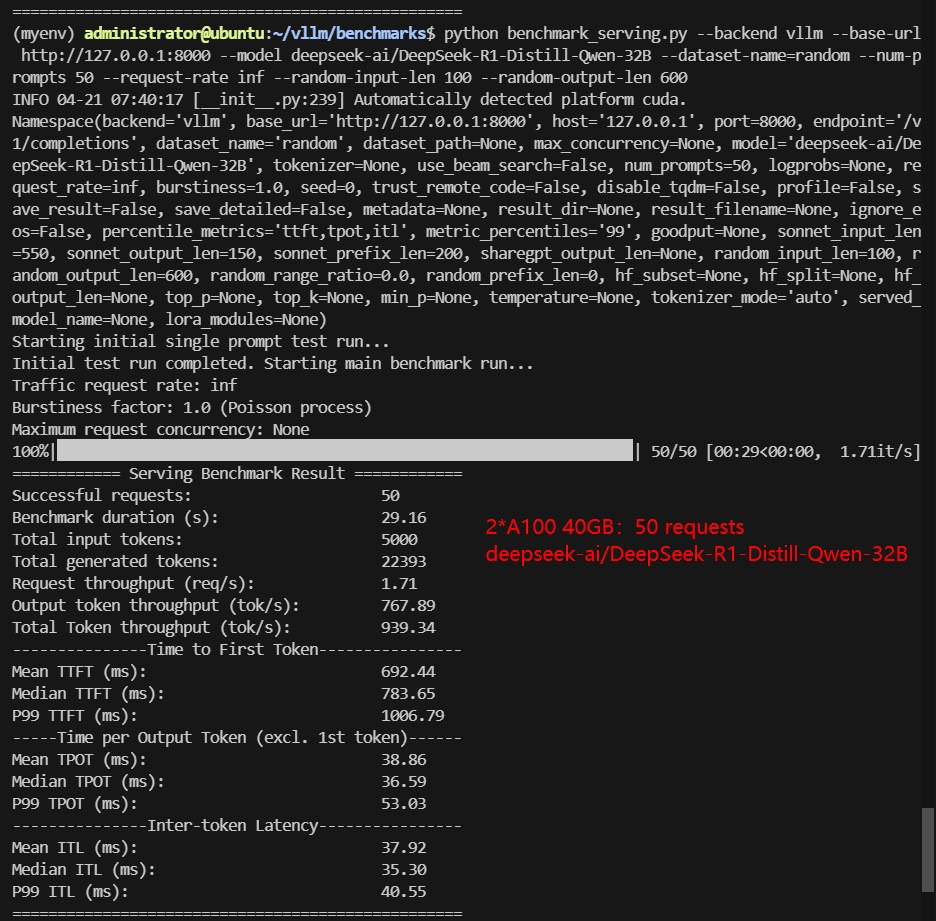
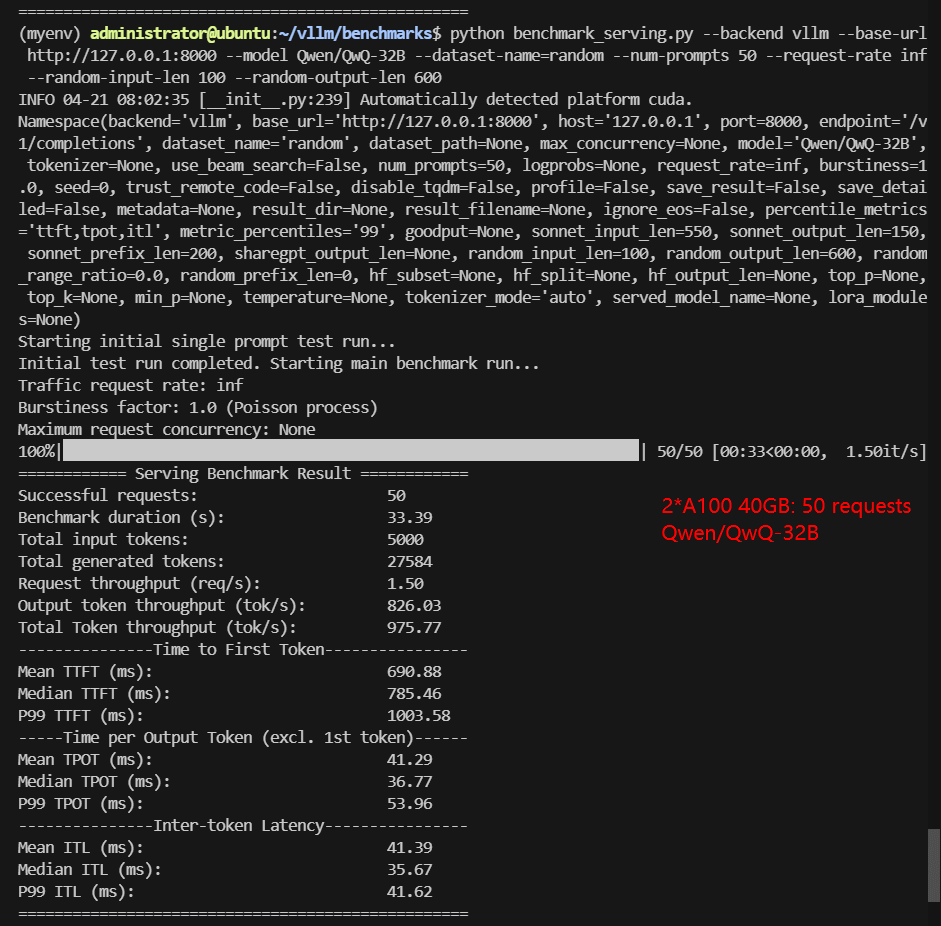
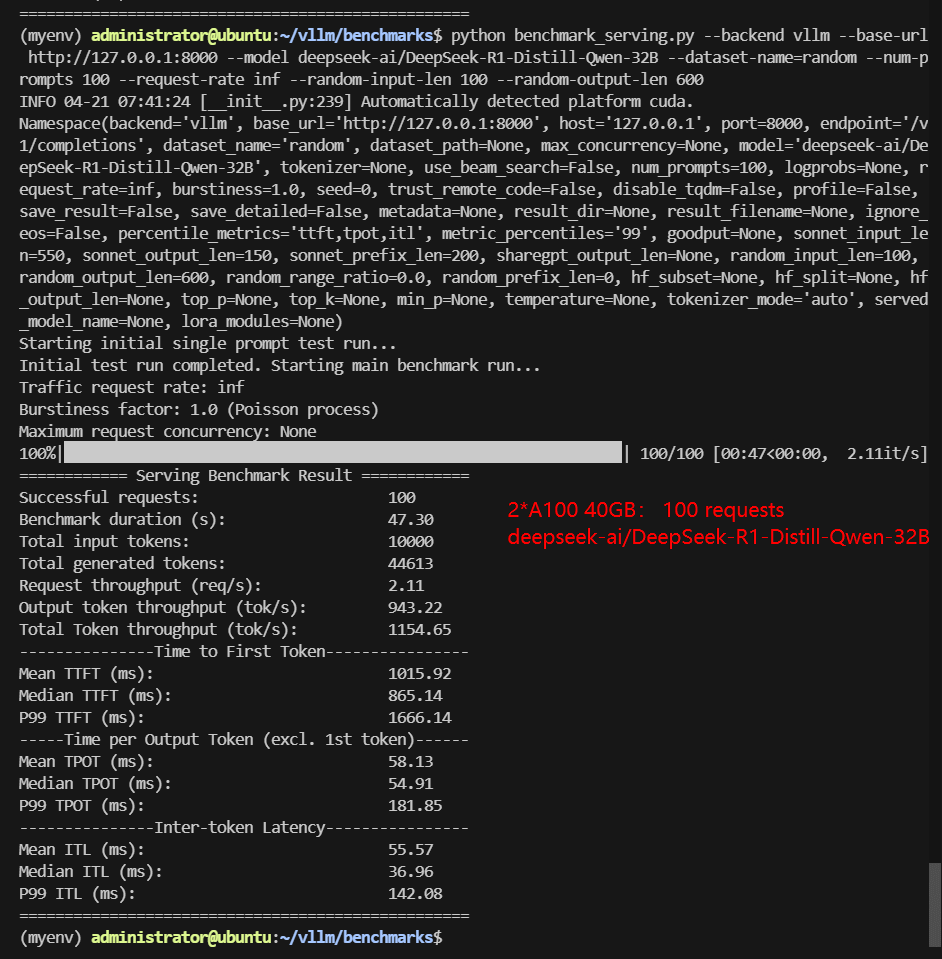
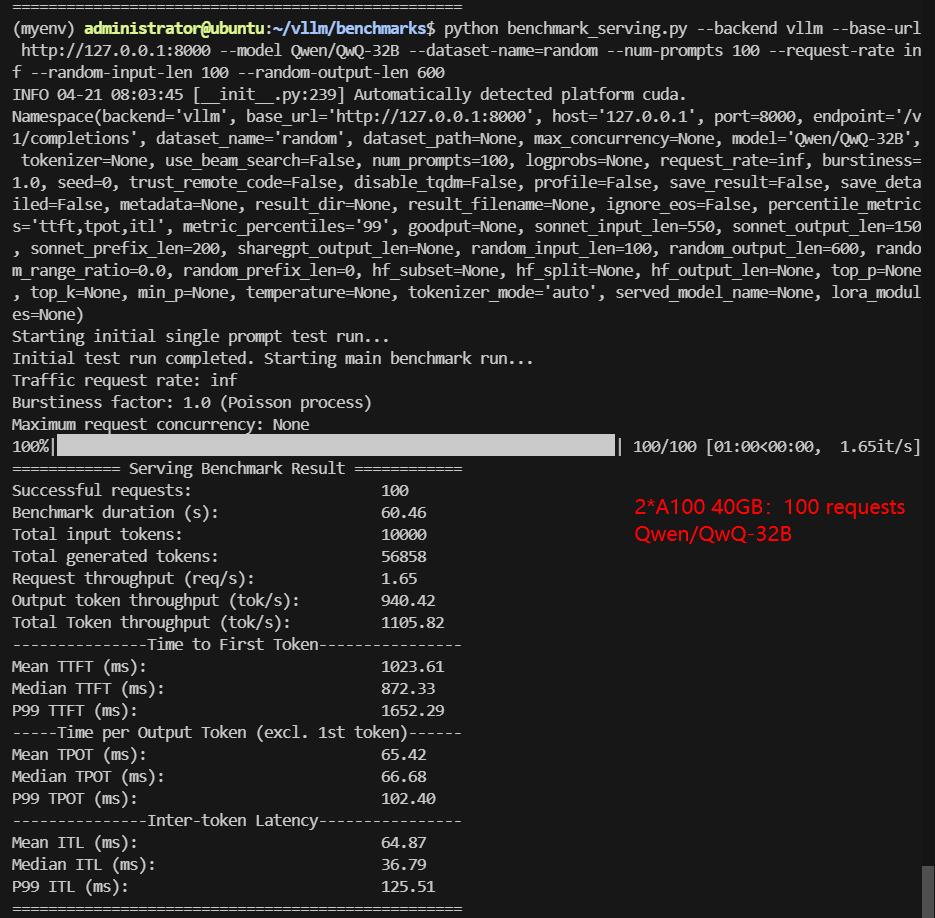
If you're looking to run inference on massive 32B models like Qwen-32B or Qwen3-32B from Hugging Face, the most cost-effective GPU setup for Qwen3-32B inference is 2×NVIDIA A100 40GB using vLLM with tensor-parallel-size=2.
- Performance: In benchmark tests, this dual-GPU setup achieved ~976 tokens/s throughput and median TTFT under 800ms—comparable to a single NVIDIA H100.
- Cost: 2×A100 costs roughly 50% less than one H100, making it the best price-to-performance solution for 32B LLMs like Qwen3-32B.
- Compatibility: Fully supports large-scale models like Qwen/Qwen3-32B using vLLM with tensor parallelism.
Screenshot: 2*A100 40GB for Qwen3:32B with vLLM