

NVIDIA H100 vs A100: Ultimate High-Performance Computing GPU Comparison
As NVIDIA’s two latest data center GPUs, the A100 and H100 are designed to meet diverse enterprise and industrial demands, especially in AI training, inference, and HPC workloads. But how much does the H100 improve in terms of specifications, availability, and hardware innovations? Is it truly the best price-to-performance option? And what differences emerge in real-world scenarios like AI, large-scale models, and high-concurrency tasks? This article will break it down for you.
A100 vs H100– Background Comparison
| Brand | Series | Model | Release Year | Official Positioning / Description | Market Price (USD) |
|---|---|---|---|---|---|
| NVIDIA | A100 | A100 40GB / 80GB | 2020 | Data center GPU for AI training and HPC workloads | $11,000+ |
| NVIDIA | H100 | H100 80GB / SXM5 | 2022 | Next-generation data center GPU for AI training, HPC, and inference | $25,000+ |
Summary Highlights
- A100: Up to 20× faster than V100, widely used for AI, ML, and HPC workloads.
- H100: Next-gen replacement with 6× faster Transformer training and up to 30× AI Inference performance on the largest models.
- Key Advantage: H100 introduces major architectural upgrades (Hopper), delivering unmatched performance for large AI models and high-concurrency tasks.
- Value Insight: While H100 dominates in cutting-edge workloads, A100 remains a strong, cost-effective choice in many enterprise scenarios.
NVIDIA A100 vs H100 – Specifications Comparison
Core Specs Comparison between A100 and H100
The H100, built on NVIDIA’s Hopper architecture, introduces 4th-generation Tensor Cores, the Transformer Engine, and higher interconnect bandwidth, enabling much faster AI training and inference compared to A100’s Ampere architecture. Its larger GPU memory and significantly higher memory bandwidth allow for bigger models, larger batch sizes, and faster data movement, reducing bottlenecks in HPC simulations and large-scale deep learning workloads. While A100 remains a reliable and cost-efficient option for many production scenarios, H100 provides a substantial performance and capability leap for cutting-edge AI and high-performance computing tasks.
| Parameter | NVIDIA A100 | NVIDIA H100 | Difference / Advantage |
|---|---|---|---|
| Architecture | Ampere | Hopper | H100 is newer generation |
| CUDA Cores | 6,912 | 16,896 | H100 has ~2.4× more cores |
| Memory Type | HBM2 (40G A100), HBM2e (80G A100) | HBM3 | H100 uses faster HBM3 |
| Memory Capacity | 40 GB / 80 GB | 80 GB | H100 standardizes at 80 GB |
| Memory Bandwidth | ~1.6(40G A100), ~2.0 TB/s (80G A100) | ~3.0 TB/s | H100 has higher bandwidth |
| Core Frequency (Base/Boost) | ~1.41 GHz (varies by model) | ~1.8 GHz (varies by model) | H100 generally higher |
| TDP (Total Graphics Power) | 400W (PCIe) / 500W (SXM4) | 350W (PCIe) / 700W (SXM5) | H100 SXM5 supports higher power/performance |
| Interface / Bus | PCIe Gen4, NVLink (SXM4) | PCIe Gen5, NVLink (SXM5, 900 GB/s link) | H100 supports newer PCIe & faster NVLink |
| FP32 Performance | ~19.5 TFLOPS | ~60 TFLOPS | H100 ~3× faster in FP32 |
| Tensor Cores | 3rd-gen Tensor Cores | 4th-gen Tensor Cores + Transformer Engine | H100 stronger AI acceleration |
| PCIe Version | Gen4 | Gen5 | H100 newer PCIe standard |
Advanced Features
| Parameter | NVIDIA A100 | NVIDIA H100 | Difference / Advantage |
|---|---|---|---|
| FP16 / BF16 Performance | ~312 TFLOPS (Tensor Cores) | ~1,000 TFLOPS (Tensor Cores) | H100 ~3× faster in FP16/BF16 |
| INT8 / INT4 Performance | ~624 TOPS (INT8 Tensor Ops) | ~2,000 TOPS (INT8) / ~4,000 TOPS (INT4) | H100 much stronger for inference |
| FP64 Performance | ~9.7 TFLOPS | ~30 TFLOPS | H100 ~3× faster in double precision |
| Number of Transistors | 54.2B | 80B | H100 ~1.5× more, higher density |
| Power Consumption (TDP) | 400–500 W | 700 W | H100 requires more power |
| Interface | PCIe Gen4 / SXM4 | PCIe Gen5 / SXM5 | H100 supports faster PCIe Gen5 |
| NVLink Bandwidth / Version | 600 GB/s (NVLink 3, SXM4) | 900 GB/s (NVLink 4, SXM5) | H100 faster interconnect |
| Nvlink Interconnect | NVLink 3 / SXM4 | NVLink 4 / SXM5 | H100 newer NVLink generation |
| NVIDIA AI Enterprise | Supported | Supported | Same, both certified for enterprise AI stack |
| Multi-Instance GPU (MIG) | Up to 7 GPU instances | Up to 7 GPU instances (improved isolation) | H100 better MIG isolation and efficiency |
| Transformer Engine Support | Not available | Supported (specialized Tensor Cores) | H100 advantage for large language models |
| Form Factor (PCIe / SXM) | PCIe Gen4 / SXM4 (up to 500W) | PCIe Gen5 / SXM5 (up to 700W) | H100 higher power envelope and Gen5 |
| NVSwitch Compatibility | Supported (Ampere NVSwitch) | Supported (Hopper NVSwitch, faster links) | H100 newer NVSwitch generation |
| ECC Memory Support | Yes | Yes | Same (enterprise-grade reliability) |
| Virtualization / vGPU | Supported | Supported | Same, but H100 optimized for new CUDA stack |
Summary & Analysis
The NVIDIA H100 demonstrates a massive leap over the A100 across almost all core performance metrics.
Mixed-precision AI training (FP16/BF16):
H100 delivers ~1,000 TFLOPS vs. A100’s 312 TFLOPS, enabling 3×+ faster deep learning workloads, especially in large-scale model training.Scientific computing (FP32/FP64):
FP32 performance improves from 19.5 TFLOPS (A100) to ~60 TFLOPS (H100), while FP64 doubles from 9.7 TFLOPS to ~30 TFLOPS. This positions H100 as a far stronger GPU for HPC simulations, climate modeling, and physics research.Inference performance (INT8/INT4):
With support for up to ~4,000 TOPS, H100 provides 4–6× higher throughput compared to A100, dramatically boosting AI inference, recommendation systems, and quantized model deployment.Memory bandwidth:
H100' s HBM3 (3 TB/s) nearly doubles A100’ s HBM2e (1.6 TB/s), reducing data bottlenecks and allowing larger batch sizes and faster data movement between GPU cores and memory. This is critical for training foundation models and handling massive datasets.Architectural innovations:
- 4th-gen Tensor Cores with FP8 and BF16 support reduce memory footprint while maintaining accuracy, significantly improving efficiency in massive model training.
- Transformer Engine is specialized for LLMs like GPT, delivering up to 6× faster Transformer training vs. A100.
- DPX acceleration adds unique capabilities for dynamic programming tasks (e.g., DNA/RNA sequencing, optimization problems).
- Enhanced MIG maintains 7-way partitioning but with better isolation and QoS, making H100 more suitable for multi-tenant and cloud-scale deployments. Inference is 1.5–2× faster than A100 in MIG scenarios.
- Blazing interconnects (PCIe Gen5 + NVLink 900 GB/s) support scaling up to exascale GPU clusters with higher efficiency than A100’s Gen4/NVLink 600 GB/s.
Key Takeaway
While the A100 remains a strong and cost-effective option for AI training and HPC workloads, the H100 redefines data center GPU performance. With up to 6× gains in Transformer training, 3× improvements in FP32/FP64, and double the memory bandwidth, H100 is a quantum leap designed for next-generation AI, HPC, and large-scale inference — making it the superior choice for enterprises targeting LLMs, generative AI, and multi-tenant cloud deployments.
H100 vs A100 Benchmark for AI
Both the H100 and A100 are designed for high-computation workloads such as AI, HPC, and advanced interface tasks. As model sizes and data volumes increase, the performance gap between the two GPUs in AI inference becomes more pronounced.
H100 vs A100 for AI Interface
According to NVIDIA’s official data, in specific optimized test scenarios—for example, performing short-question inference on a 530-billion-parameter model using H100’s next-generation high-speed interconnect—H100 can outperform A100 by 16–30× in AI inference throughput.
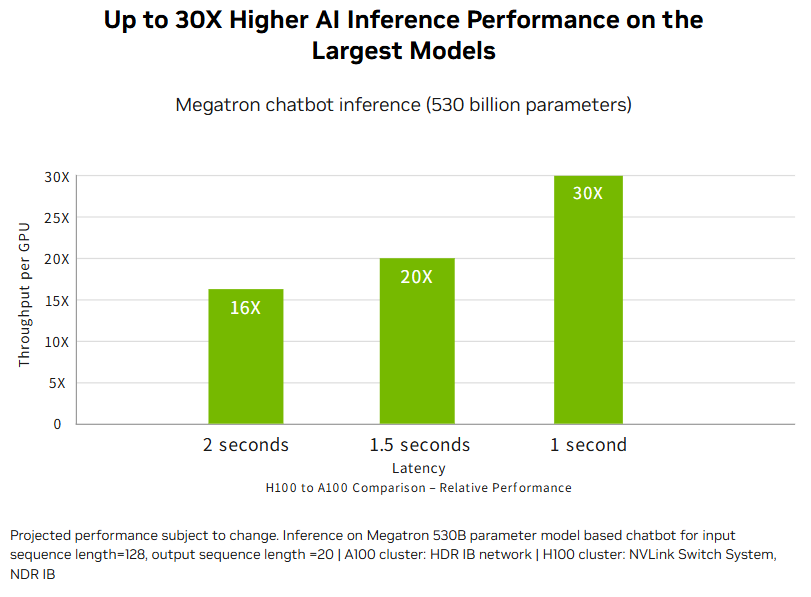
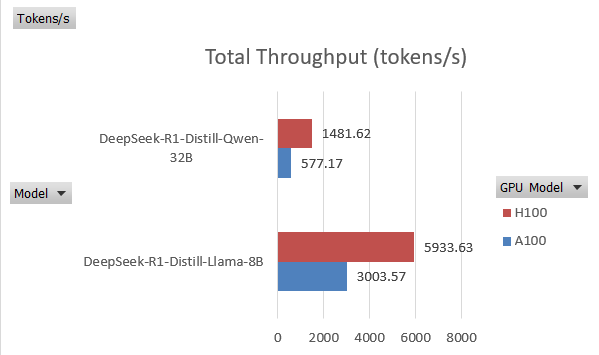
However, in testing DeepSeek-R1-Distill-Qwen-32B, the total throughput is:
- A100: ~577.17 tokens/sec (Check different tests for A100 here)
- H100: ~1,481.62 tokens/sec (Check different tests for H100 here)
This represents less than a 3× improvement. For smaller models, the performance gap narrows even further, showing that the advantage of H100 depends strongly on model size and workload characteristics.
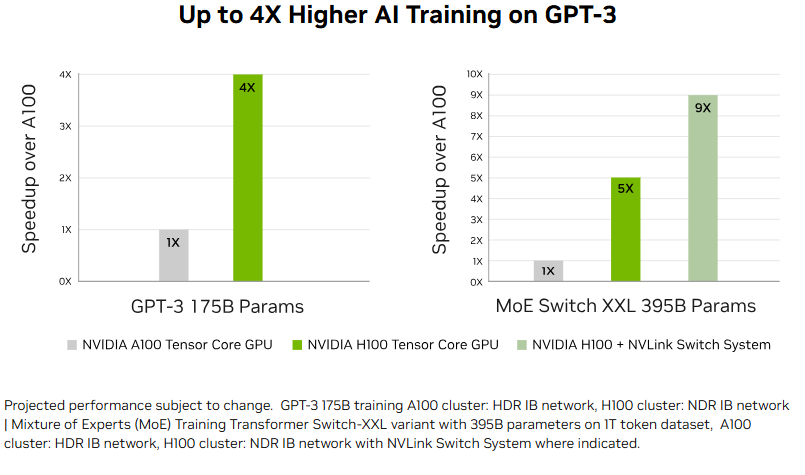
A100 vs H100 AI Training
In certain large-scale AI training tasks, especially when paired with 4th-generation NVLink, the performance gap between the A100 and H100 can reach 4–7×. At data center scale, the H100 GPU clearly outshines the A100, demonstrating its superiority in high-performance, large-model deployments.
H100 vs A100: Price & Value
As enterprise-grade GPUs priced in the tens of thousands of dollars, the A100 and H100 prices show differences across platforms ranging from 2× to 10×, depending on factors such as used vs. new units, memory capacity, and market inventory. Clearly, used A100 cards offer the best value, and for small- to mid-sized models under 70B parameters, the A100 may be the more cost-effective choice.
| Platform | NVIDIA A100 (USD) | NVIDIA H100 (USD) | Price Difference (USD) | Price Difference (%) |
|---|---|---|---|---|
| Official MSRP | $11,000 | $30,000 | +$19,000 | +173% |
| Amazon | $7,500–$14,000 | $25,000–$30,000 | +$17,500–$22,500 | +233–300% |
| Third-Party Resellers(ebay etc) | $2,500–$17,200 | $27,000–$31,000 | +$24,500–$28,500 | +1,000–1,140% |
H100 vs A100 – Pros & Cons
| GPU Model | Pros | Cons |
|---|---|---|
| NVIDIA A100 | - Mature and proven for AI/HPC - Lower cost, especially used - Supports 7-way MIG - Broad software and ecosystem support - Stable driver and library support - Efficient for medium models (<70B) - Lower power consumption vs H100 |
- Slower FP16/BF16 training - Lower FP32/FP64 throughput - HBM2e memory limits bandwidth - Older architecture - Limited future-proofing for LLMs - Lower inference throughput |
| NVIDIA H100 | - Massive FP16/BF16 throughput - High FP32/FP64 performance - HBM3 memory with ~3 TB/s - 4th-gen Tensor Cores, FP8 support - Transformer Engine for LLMs - DPX accelerator for dynamic programming - Enhanced MIG isolation & QoS - PCIe Gen5 + NVLink 900 GB/s - Scales for cloud and multi-GPU clusters |
- Very high price (2–10× A100) - Overkill for small/mid-size models - Higher power consumption - Software optimization may lag initially - Limited availability in some regions |
H100 & A100 Server Hosting
The A100 and H100 are among the most commonly offered GPUs by hosting providers. To cut costs, many providers deliver them through serverless platforms or shared cloud instances, but this often comes at the expense of performance. For clients running real-world inference or AI training workloads, a dedicated A100 or H100 server is the smarter choice.
Database Mart provides A100 and H100 server hosting ranging from single-GPU to multi-GPU configurations. Their servers are built with high-quality hardware, offering a strong balance of performance and value. With over 20 years of proven reliability, Database Mart has become a trusted hosting provider for businesses worldwide seeking enterprise-grade GPU solutions.
Conclusion
The NVIDIA H100 delivers a major leap in AI and HPC, with performance gains of 2–30× over the A100 in large-scale AI training, inference, and cluster deployments. While it costs 2–3× more, the gap is far smaller on mid-sized models, where the A100 remains a highly cost-effective choice—especially with used cards. Ultimately, the best option depends on workload scale and budget, with both GPUs offering strong value for enterprise AI projects.
h100 vs a100, a100 vs h100, nvidia a100 vs h100, nvidia h100 vs a100, H100 for AI, H100 price, H100 specs, A100 price, A100 specs, A100 for AI