
Video: Offline reasoning of LLMs from Hugging Face using H100 based on vLLM

Nvidia H100 vLLM Benchmark Results: Offline and Online Inference of LLMs on Hugging Face
This article tests the offline and online inference performance of multiple large language models on Hugging Face based on the NVIDIA H100 80GB GPU and vLLM backend. The test covers different combinations of model size, input and output length, and number of requests. The following is a detailed analysis of the test results, which aims to provide valuable reference for users who use H100 servers for large language model inference.
H100 GPU Details
- GPU: NVIDIA H100
- Microarchitecture: Hopper
- Compute capability: 9.0
- CUDA Cores: 14592
- Tensor Cores: 456
- Memory: 80GB HBM2e
- FP32 performance: 183 TFLOPS
1. Test Overview
1. Test Project Code Source:
- We used this git project to build the environment(https://github.com/vllm-project/vllm)。
2. The Following Models from Hugging Face were Tested:
- google/gemma-2-9b-it
- google/gemma-2-27b-it
- deepseek-ai/DeepSeek-R1-Distill-Llama-8B
- deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
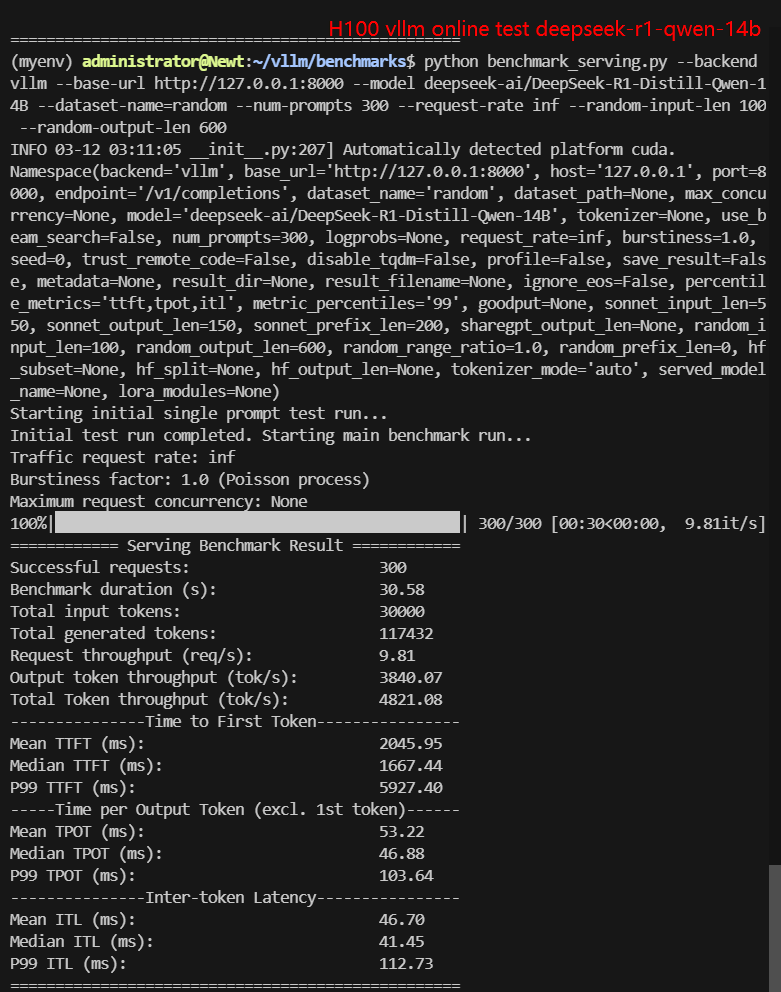
- deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
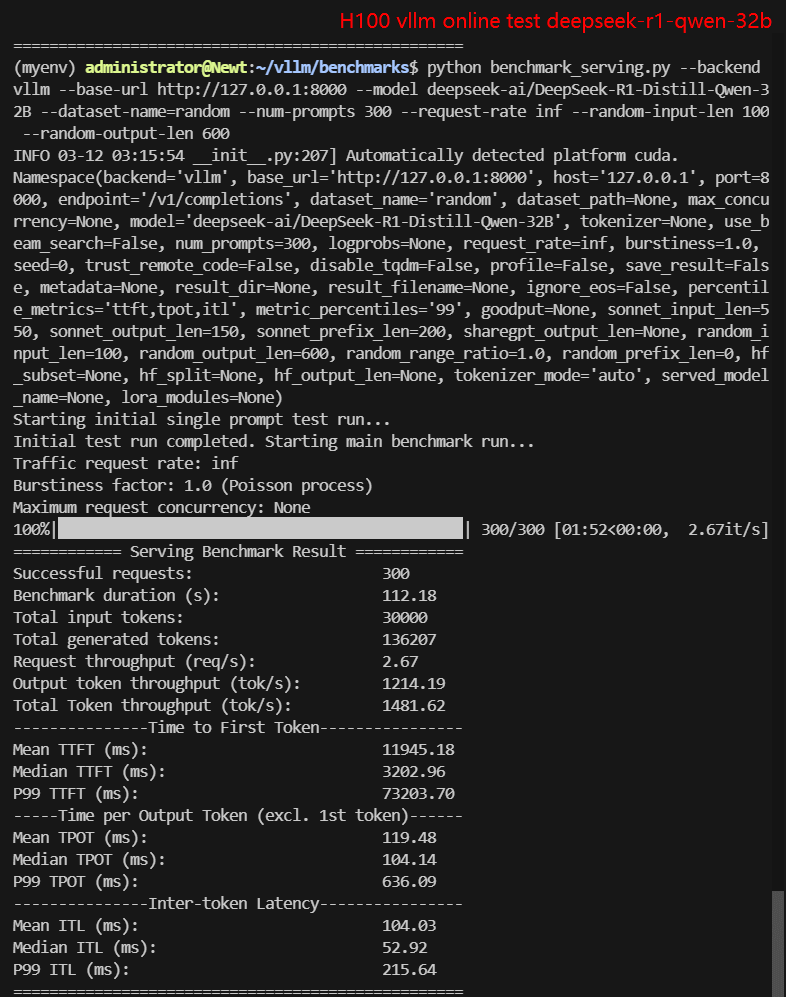
- deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
3. The Test Parameters are Preset as Follows::
- Input length: 100 tokens
- Output length: 600 tokens
- Request Numbers: 300
4. The Test is Divided into Two Modes:
- Offline testing: Use the benchmark_throughput.py script.
- Online testing: Use the benchmark_serving.py script to simulate real client requests.
2、Benchmark Results Data Display
1. Offline Benchmark Results:
| Models | gemma-2-9b-it | gemma-2-27b-it | DeepSeek-R1-Distill-Llama-8B | DeepSeek-R1-Distill-Qwen-7B | DeepSeek-R1-Distill-Qwen-14B | DeepSeek-R1-Distill-Qwen-32B |
|---|---|---|---|---|---|---|
| Quantization | 16 | 16 | 16 | 16 | 16 | 16 |
| Size(GB) | 18.5GB | 54.5GB | 16.1GB | 15.2GB | 29.5GB | 65.5GB |
| Backend/Platform | vLLM | vLLM | vLLM | vLLM | vLLM | vLLM |
| CPU Rate | 1.4% | 1.4% | 1.5% | 1.4% | 1.4% | 1.4% |
| RAM Rate | 5.5% | 5.8% | 4.8% | 5.7% | 5.8% | 4.8% |
| GPU vRAM Rate | 90% | 91.4% | 90.3% | 90.3% | 90.2% | 91.5% |
| GPU UTL | 80-86% | 88-94% | 80-82% | 80% | 72-87% | 91-92% |
| Request (req/s) | 5.99 | 2.62 | 9.27 | 10.45 | 6.15 | 1.99 |
| Total Duration | 49s | 1min54s | 32s | 28s | 48s | 2min30s |
| Input (tokens/s) | 599.06 | 262.45 | 926.91 | 1044.98 | 614.86 | 198.66 |
| Output (tokens/s) | 3594.38 | 1574.67 | 5561.45 | 6269.87 | 3689.21 | 1191.95 |
| Total Throughput (tokens/s) | 4193.44 | 1837.12 | 6488.36 | 7314.85 | 4304.07 | 1390.61 |
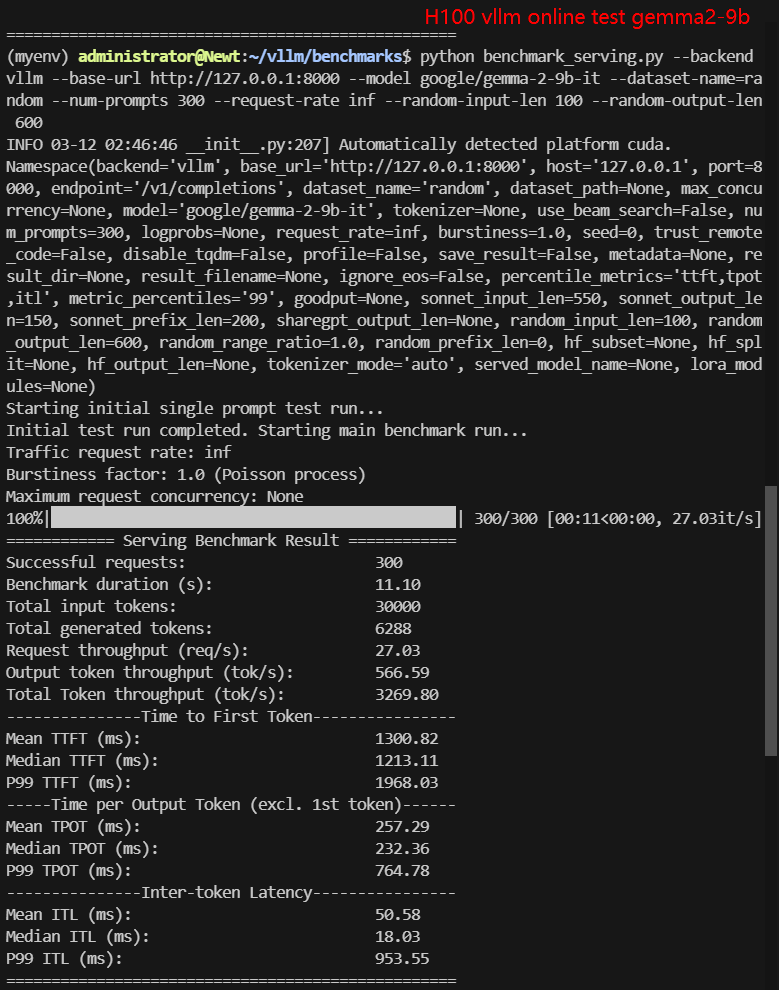
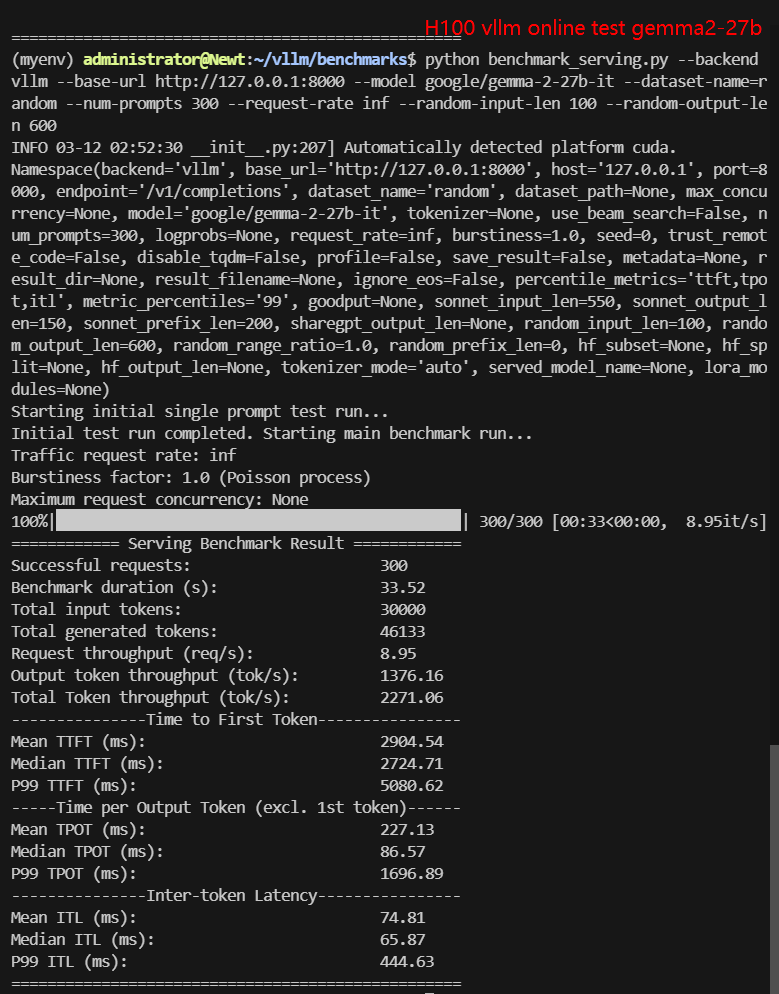
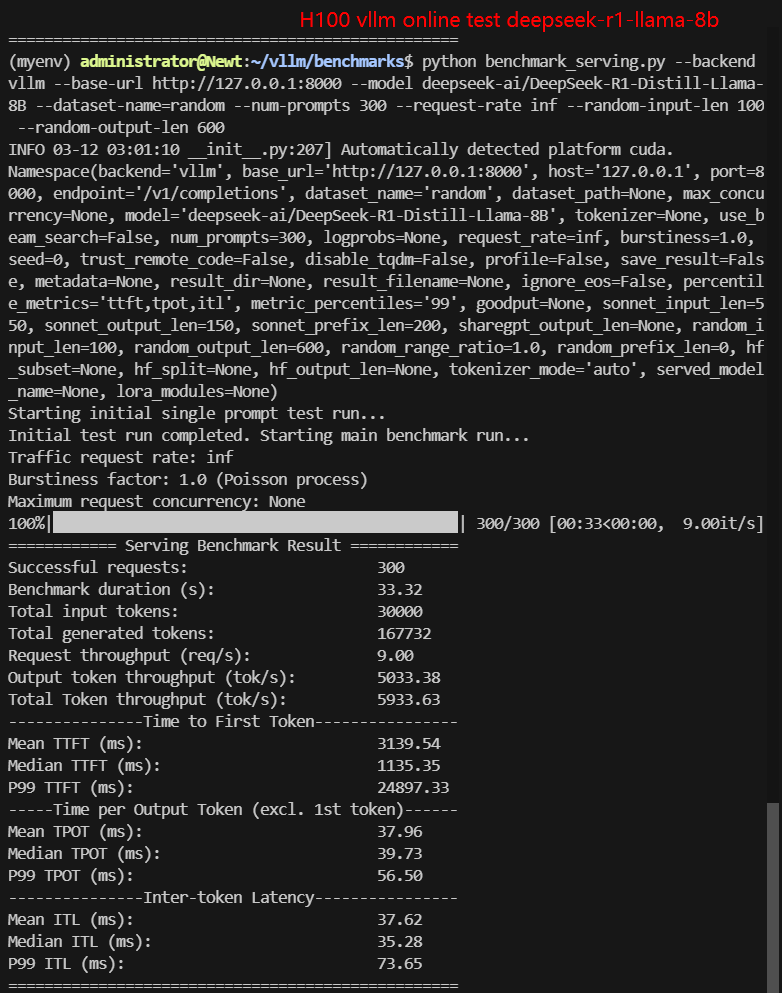
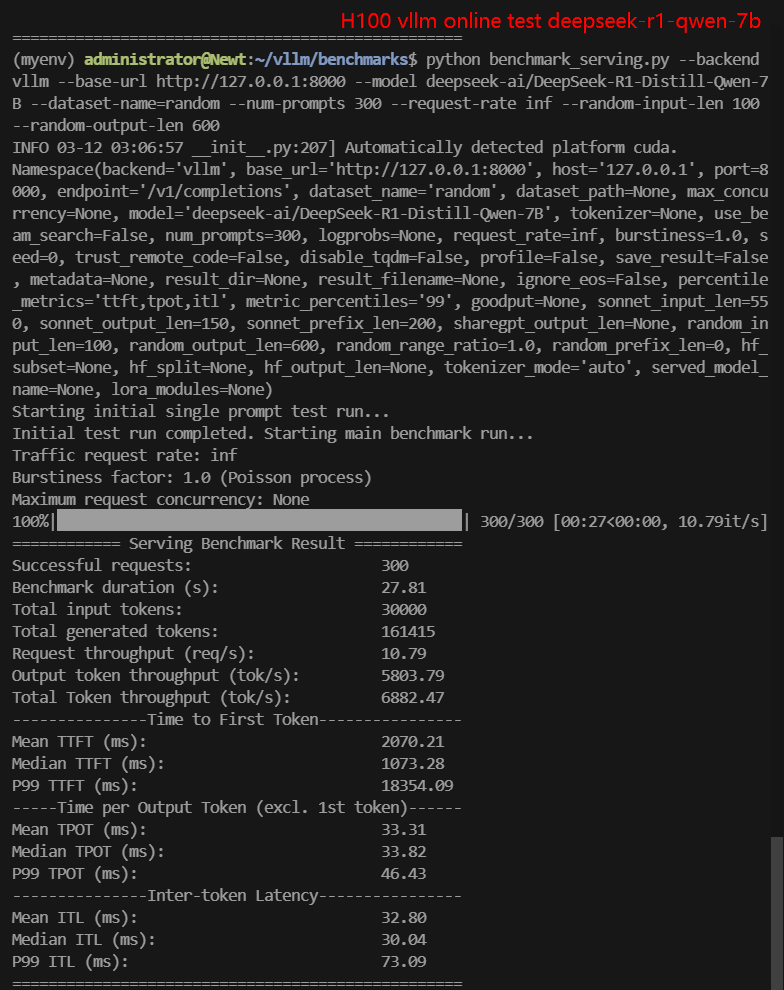
2. Online Benchmark Results:
| Models | gemma-2-9b-it | gemma-2-27b-it | DeepSeek-R1-Distill-Llama-8B | DeepSeek-R1-Distill-Qwen-7B | DeepSeek-R1-Distill-Qwen-14B | DeepSeek-R1-Distill-Qwen-32B |
|---|---|---|---|---|---|---|
| Quantification | 16 | 16 | 16 | 16 | 16 | 16 |
| Size(GB) | 18.5GB | 54.5GB | 16.1GB | 15.2GB | 29.5GB | 65.5GB |
| Backend/Platform | vLLM | vLLM | vLLM | vLLM | vLLM | vLLM |
| CPU Rate | 1.4% | 1.4% | 2.8% | 3% | 2.5% | 2.0% |
| RAM Rate | 13.9% | 15.4% | 11.5% | 18% | 15.9% | 11.8% |
| GPU vRAM Rate | 90.2% | 90.9% | 90.2% | 90.3% | 90% | 90.3% |
| GPU UTL | 93% | 86%-96% | 83%-85% | 50%-91% | 80-90% | 92%-96% |
| Request (req/s) | 27.03 | 8.95 | 8.80 | 10.79 | 9.81 | 2.67 |
| Total Duration | 11s | 33s | 33s | 27s | 30s | 1min52s |
| Input (tokens/s) | 2703.21 | 894.9 | 900.25 | 1078.68 | 981.01 | 267.43 |
| Output (tokens/s) | 566.59 | 1376.16 | 5033.38 | 5803.79 | 3840.07 | 1214.19 |
| Total Throughput (tokens/s) | 3269.80 | 2271.06 | 5933.63 | 6882.47 | 4821.08 | 1481.62 |
3. Data Item Explanation:
The following are the meanings of the data items in the table:
- Quantization: The number of quantization bits. This test uses 16 bits, a full-blooded model.
- Size (GB): Model size in GB.
- Backend: The inference backend used. In this test, vLLM is used.
- CPU Rate: CPU usage rate.
- RAM Rate: Memory usage rate.
- GPU vRAM: GPU memory usage.
- GPU UTL: GPU utilization.
- Request Numbers: The number of requests processed per second.
- Total Duration: The total time to complete all requests.
- Input (tokens/s): The number of input tokens processed per second.
- Output (tokens/s): The number of output tokens generated per second.
- Total Throughput (tokens/s): The total number of tokens processed per second (input + output).
3. H100 Benchmark Results Analysis
1. Offline Testing:
- Impact of model size on performance: The smaller the model size, the higher the request throughput and total throughput. The performance of 7B and 8B models is significantly better than that of 14B and 32B models.
- GPU Utilization (GPU UTL): The larger the model size, the higher the GPU utilization. The GPU utilization of the 32B model is close to full load.
- GPU memory usage (GPU vRAM): In all tests, the GPU video memory usage rate is close to 90%, indicating that the GPU vRAM is close to full load.
2. Online Testing:
- Impact of model size on performance: In online tests, the performance of 7B and 8B models is still significantly better than that of 14B and 32B models.
- GPU Utilization (GPU UTL): In online tests, GPU utilization is generally high, especially for larger models.
- GPU memory usage (GPU vRAM): In all tests, the GPU video memory usage rate is close to 90%, indicating that the GPU vRAM is close to full load.
Conclusion: The larger the model, the higher the GPU requirements. GPU memory is one of the main bottlenecks for performance, especially when processing larger models.
4、Offline Testing vs. Online Testing
From the test results, we can see that when the parameters are set to the same, the request throughput (req/s) and total throughput (tokens/s) of the online test are generally higher than those of the offline test. The following are possible reasons:
1. The difference between offline testing and online testing
Offline testing:
- Use the benchmark_throughput.py script to simulate batch requests.
- Usually all requests are sent at once, and the system needs to process a large number of requests at the same time, which may cause resource competition and video memory pressure.
- More suitable for evaluating the maximum throughput and extreme performance of the system.
Online Test:
- Use the benchmark_serving.py script to simulate client requests.
- Requests are sent gradually, so the system can allocate resources more flexibly and reduce resource contention.
- More suitable for evaluating the performance of the system in an actual production environment.
2. Reasons why online testing is better than offline testing
More efficient resource allocation:
- In online testing, requests are sent gradually, and the system can dynamically allocate resources (such as video memory and computing resources) based on the current load.
- In offline testing, all requests are sent at once, and the system needs to process a large number of requests simultaneously, which may cause resource competition and video memory pressure, thereby reducing performance.
Better memory utilization:
- In online testing, video memory can be allocated more flexibly to each request, reducing video memory fragmentation.
- In offline testing, the video memory may be occupied by a large number of requests at the same time, resulting in insufficient video memory or the need for frequent recalculations (such as PreemptionMode.RECOMPUTE), which degrades performance.
Request processing is smoother:
- In online testing, requests are processed incrementally, and the system can better balance computing and I/O operations.
- In offline testing, a large number of requests arrive at the same time, which may lead to computing and I/O bottlenecks.
Higher GPU utilization:
- In online tests, GPU utilization is generally more stable and the system can better utilize the computing power of the GPU.
- In offline testing, GPU utilization may fluctuate due to resource contention, resulting in performance degradation.
Therefore, online testing is more suitable for evaluating the performance of the system in an actual production environment, while offline testing is more suitable for evaluating the extreme performance of the system.
5. Notes and Insights:
✅ Impact of Test Parameters
- Different input and output lengths have a significant impact on performance. Longer sequences increase video memory usage and computational complexity, which reduces throughput and increases latency. In actual projects, users should adjust the input and output lengths according to task requirements to optimize performance.
- Increasing the number of requests will improve system throughput, but may also lead to insufficient video memory or resource contention. Users should adjust the number of requests based on hardware configuration and task requirements to balance performance and resource usage.
✅ Model Scale Selection
- The larger the model size, the higher the video memory usage and computing requirements. It is recommended that users choose the appropriate model size based on the hardware configuration. For example, the H100 80GB GPU is suitable for running models from 7B to 32B, while models above 40B may require multi-GPU parallelism or hardware support with higher video memory.
- If the model size exceeds the GPU memory capacity (such as 80GB), it will lead to insufficient memory and significantly degraded performance. It is recommended that users avoid using models that exceed the hardware memory capacity in testing and production environments.
✅ Optimization of Hardware Configuration
- GPU vRAM is one of the main performance bottlenecks. Users should monitor video memory usage to avoid performance degradation caused by insufficient video memory. Video memory usage can be optimized by adjusting the --gpu-memory-utilization parameter.
- A higher GPU utilization indicates that hardware resources are fully utilized, but if the utilization is close to 100%, it may cause performance bottlenecks. Users should adjust the model and parameters based on the test results to optimize GPU utilization.
✅ Adjustments in Actual Projects
- Offline testing is suitable for evaluating the extreme performance of the system, while online testing is more suitable for simulating the actual production environment. Users should choose the appropriate test mode according to project requirements.
✅ Test Mode Suitability
- In actual projects, users should adjust test parameters (such as input and output lengths, number of requests, etc.) according to task requirements and hardware configuration to achieve better performance.
- When deploying a model, it is recommended to monitor system resource usage (such as video memory, GPU utilization, etc.) in real time to promptly identify and resolve performance bottlenecks.
6. Attachment: Video Recording of H100 vLLM Benchmark
Screenshot: H100 vLLM benchmark offline results






Screenshot: H100 vLLM benchmark online results
Rent NVIDIA H100 GPU Server Now!
If you need to reason about LLMs under 80GB and apply them in production environments, H100 will meet your needs. Are you ready to develop your AI applications with the power of Nvidia H100 80GB GPU? Explore DatabaseMart's dedicated hosting options now and get the best performance at unbeatable prices.
Enterprise GPU Dedicated Server - H100
$ 2099.00/mo
1mo3mo12mo24mo
Order Now- 256GB RAM
- GPU: Nvidia H100
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Hopper
- CUDA Cores: 14,592
- Tensor Cores: 456
- GPU Memory: 80GB HBM2e
- FP32 Performance: 183TFLOPS
Enterprise GPU Dedicated Server - A100(80GB)
$ 1559.00/mo
1mo3mo12mo24mo
Order Now- 256GB RAM
- GPU: Nvidia A100
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 80GB HBM2e
- FP32 Performance: 19.5 TFLOPS
Hot Sale
Enterprise GPU Dedicated Server - A100
$ 359.55/mo
55% OFF Recurring (Was $799.00)
1mo3mo12mo24mo
Order Now- 256GB RAM
- GPU: Nvidia A100
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 40GB HBM2
- FP32 Performance: 19.5 TFLOPS
Tags:
H100 Server Rental,vllm h100 benchmark, h100 vllm performance testing, vllm online vs offline testing, h100 large language model inference, vllm hugging face models, h100 gpu server rental, vllm performance optimization, h100 deep learning inference
Outline