

Best Server for DeepSeek-R1:32B Reasoning | H100 vs. RTX 4090 vs. A6000
As large language models (LLMs) like DeepSeek-R1:32B become increasingly popular for AI reasoning and inference, choosing the right GPU server is crucial for achieving optimal performance at a reasonable cost. In this article, we compare four powerful GPU dedicated servers—Nvidia H100, RTX 4090, A6000, and A5000—to determine the best option for running DeepSeek-R1:32B on Ollama efficiently.
Key Factors in Choosing a GPU Server for DeepSeek-R1:32B
- Performance – How fast can the server process DeepSeek-R1:32B reasoning tasks?
- GPU Utilization – Efficient use of GPU resources impacts stability and throughput.
- Memory Capacity – Large models like DeepSeek-R1:32B require high VRAM.
- Cost vs. Performance – The balance between speed and affordability is key.
- Suitability for Different Users – Some servers are better for research, while others suit commercial applications.
👉 Performance Comparison: H100 vs. RTX 4090 vs. A6000 vs. A5000
| GPU Servers | GPU Server - H100 | GPU Server - RTX4090 | GPU Server - A6000 | GPU Server - A5000 |
|---|---|---|---|---|
| Server Configs | Price: $2599.00/month GPU: Nvidia H100 Compute Capability: 9.0 Microarchitecture: Hopper CUDA Cores: 14,592 Tensor Cores: 456 GPU Memory: 80GB HBM2e FP32: 183TFLOPS Order Now > | Price: $549.00/month GPU: Nvidia GeForce RTX 4090 Compute Capability: 8.9 Microarchitecture: Ada Lovelace CUDA Cores: 16,384 Tensor Cores: 512 GPU Memory: 24GB GDDR6X FP32: 82.6 TFLOPS Order Now > | Price: $549.00/month GPU: Nvidia Quadro RTX A6000 Compute Capability: 8.6 Microarchitecture: Ampere CUDA Cores: 10,752 Tensor Cores: 336 GPU Memory: 48GB GDDR6 FP32: 38.71 TFLOPS Order Now > | Price: $349.00/month GPU: Nvidia Quadro RTX A5000 Compute Capability: 8.6 Microarchitecture: Ampere CUDA Cores: 8192 Tensor Cores: 256 GPU Memory: 24GB GDDR6 FP32: 27.8 TFLOPS Order Now > |
| Platform | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 |
| Model | deepseek-r1:32b, 20GB, Q4 | deepseek-r1:32b, 20GB, Q4 | deepseek-r1:32b, 20GB, Q4 | deepseek-r1:32b, 20GB, Q4 |
| Downloading Speed(MB/s) | 113 | 113 | 113 | 113 |
| CPU Rate | 4% | 3% | 5% | 3% |
| RAM Rate | 3% | 3% | 4% | 6% |
| GPU vRAM | 20% | 90% | 42% | 90% |
| GPU UTL | 83% | 98% | 89% | 97% |
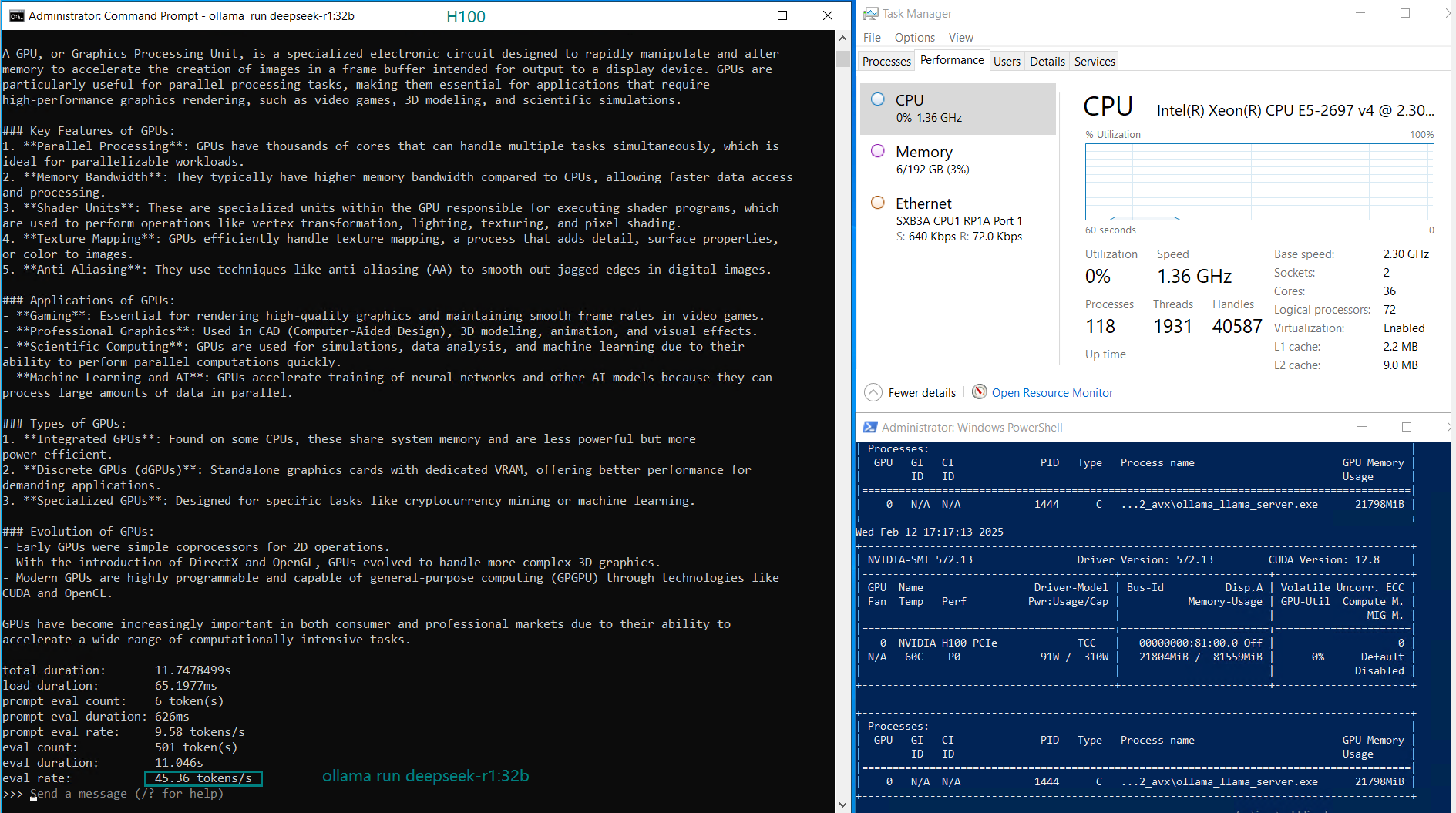
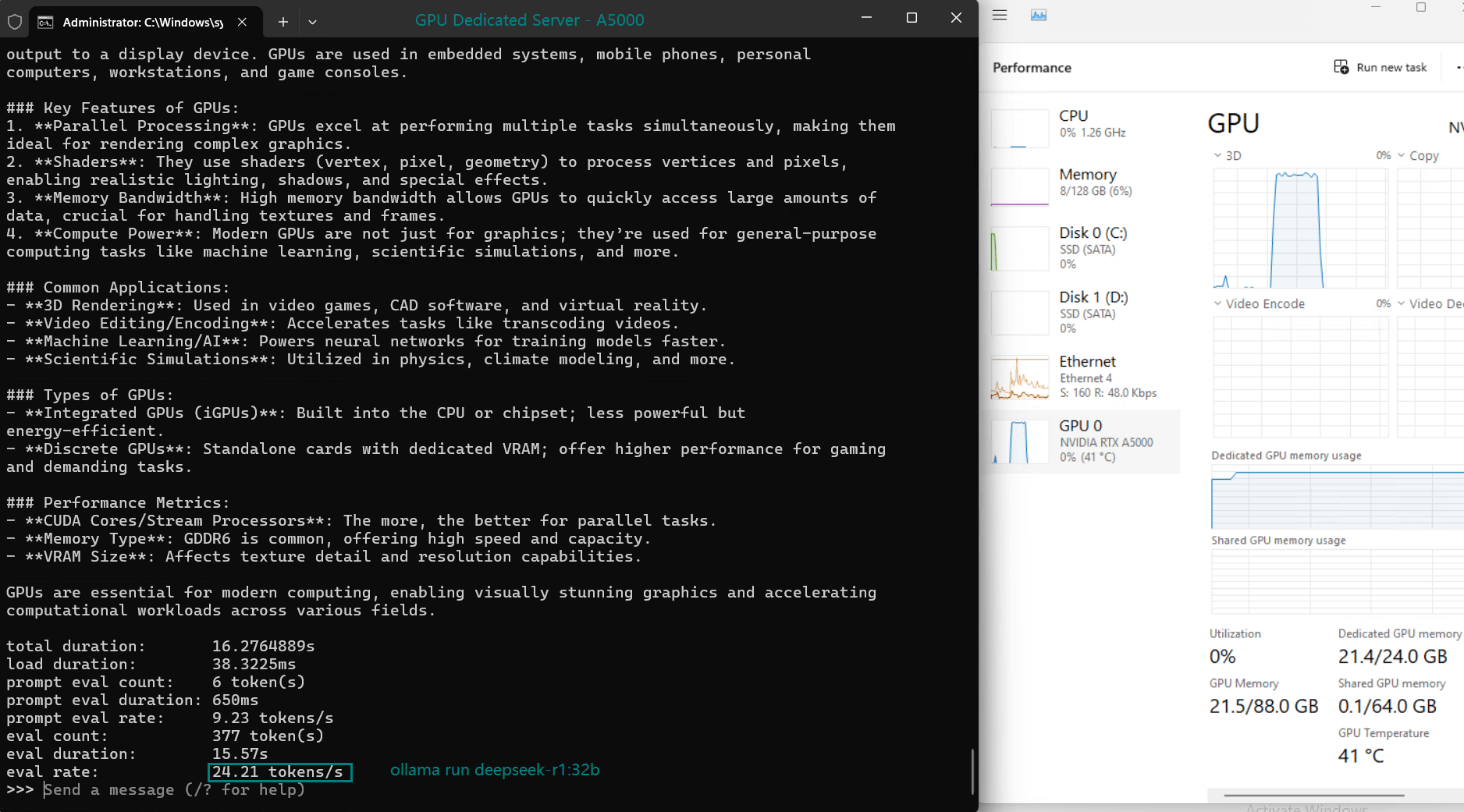
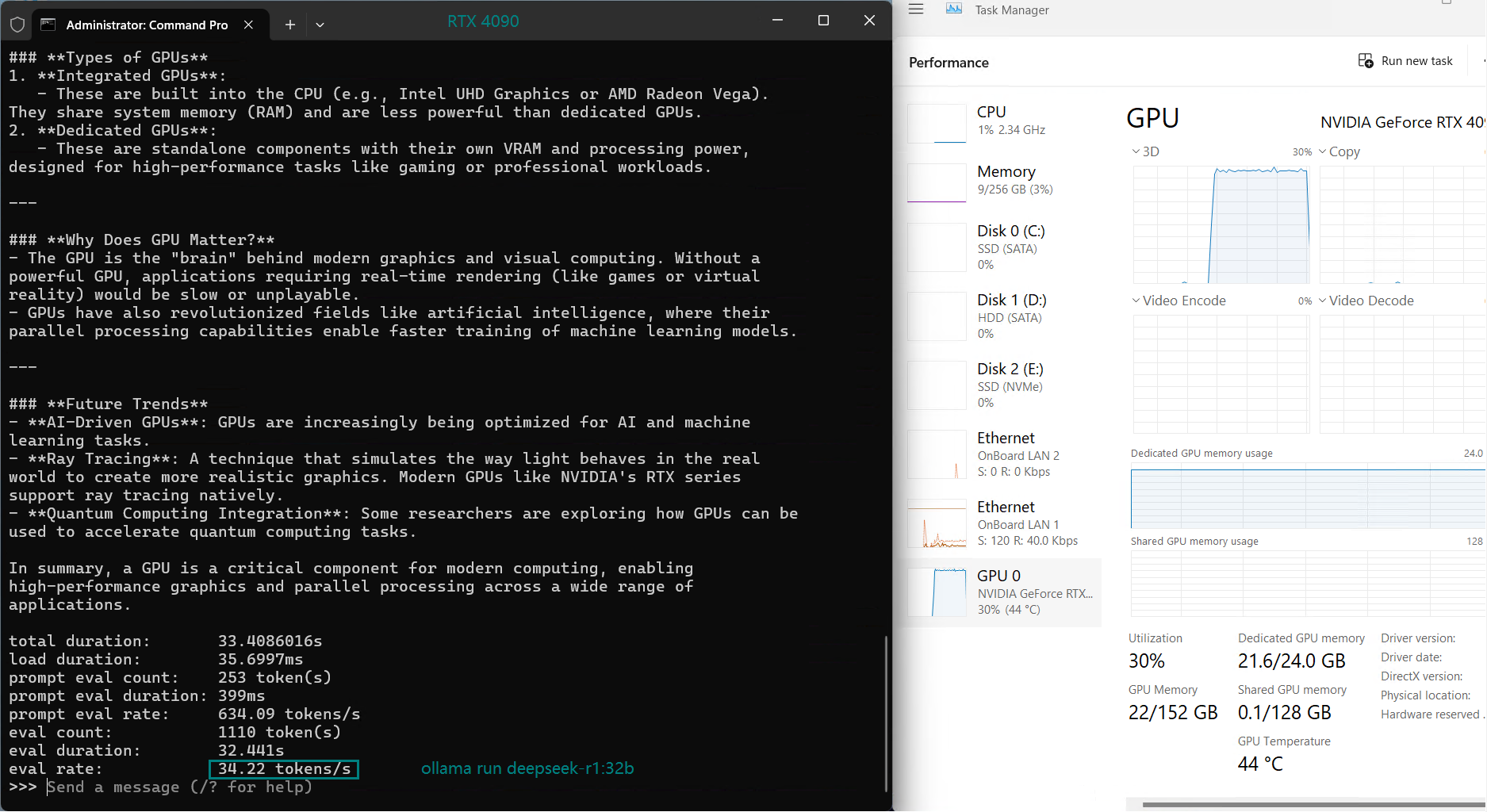
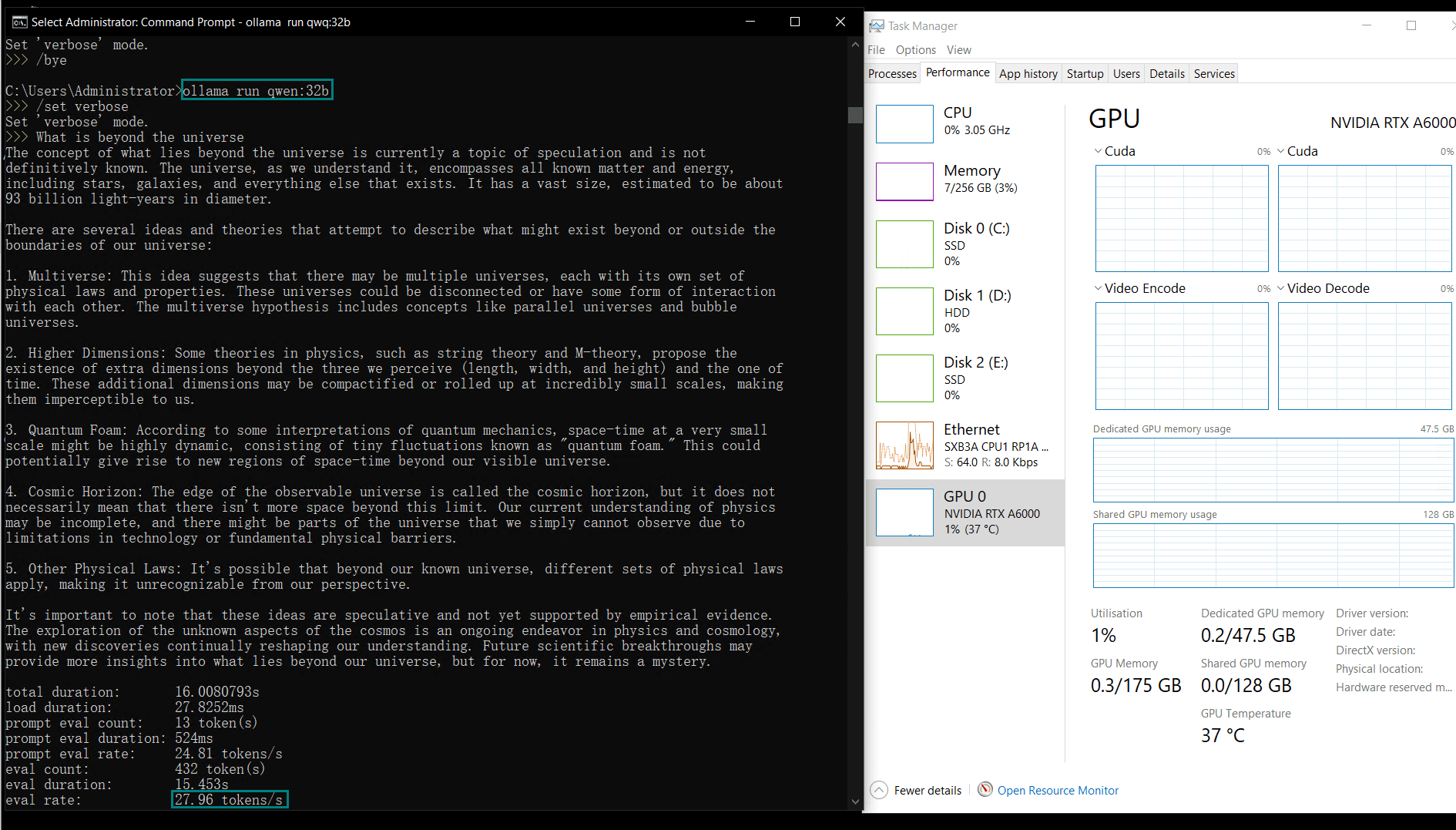
| Eval Rate(tokens/s) | 45.36 | 34.22 | 27.96 | 24.21 |

Best GPU Server for DeepSeek-R1:32B
1️⃣. Best Performance: Nvidia H100
- Fastest eval rate (45.36 tokens/s) – 2x faster than A5000.
- 80GB VRAM – Essential for large LLMs like DeepSeek-R1:32B.
- Enterprise-grade reliability with HBM2e memory.
Downside: Very expensive ($2599/month). Only worth it for high-demand production AI.
2️⃣. Best Value for Money: RTX 4090
- Much cheaper ($549/month) vs. H100 ($2599/month).
- Decent eval rate (34.22 tokens/s) – ~75% of H100 speed at 21% of the cost.
- Best for AI startups, individual researchers, and cost-sensitive projects.
Downside: 24GB VRAM limits extreme-scale LLM tasks.
3️⃣. Best for Researchers: RTX A6000
- 48GB VRAM – More than RTX 4090, allowing better inference stability.
- Lower utilization (89%) means less risk of overheating or throttling.
Downside: Slightly slower (27.96 tokens/s) vs. RTX 4090 (34.22 tokens/s).
4️⃣. Best Budget Option: RTX A5000
- Most affordable ($349/month) – Great for entry-level AI experimentation.
- Still runs DeepSeek-R1:32B decently (24.21 tokens/s).
Downside: Slowest of the four, but acceptable.
Final Recommendation: Which GPU Should You Choose?
- If you have unlimited budget → Choose H100 for top performance.
- If you need a balance of speed & price → Choose RTX 4090.
- If you’re a researcher needing more VRAM → Choose RTX A6000.
- If you want the cheapest option → Choose RTX A5000.
📢 Get Started with the Best GPU Server for DeepSeek-R1:32B
Advanced GPU Dedicated Server - A5000
- 128GB RAM
- GPU: Nvidia Quadro RTX A5000
- Dual 12-Core E5-2697v2
- 240GB SSD + 2TB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 8192
- Tensor Cores: 256
- GPU Memory: 24GB GDDR6
- FP32 Performance: 27.8 TFLOPS
Enterprise GPU Dedicated Server - RTX 4090
- 256GB RAM
- GPU: GeForce RTX 4090
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ada Lovelace
- CUDA Cores: 16,384
- Tensor Cores: 512
- GPU Memory: 24 GB GDDR6X
- FP32 Performance: 82.6 TFLOPS
Enterprise GPU Dedicated Server - RTX A6000
- 256GB RAM
- GPU: Nvidia Quadro RTX A6000
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 10,752
- Tensor Cores: 336
- GPU Memory: 48GB GDDR6
- FP32 Performance: 38.71 TFLOPS
Enterprise GPU Dedicated Server - H100
- 256GB RAM
- GPU: Nvidia H100
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Hopper
- CUDA Cores: 14,592
- Tensor Cores: 456
- GPU Memory: 80GB HBM2e
- FP32 Performance: 183TFLOPS
Final Thoughts
The best GPU server for DeepSeek-R1:32B depends on your needs: H100 for speed, RTX 4090 for affordability, A6000 for research, and A5000 for budget users. Choose wisely based on performance, cost, and intended use case!
What GPU are you using for DeepSeek-R1:32B? Let us know in the comments! 🎯
DeepSeek-R1:32B, AI Reasoning, Nvidia H100, RTX 4090, GPU Server, Large Language Model, AI Deployment, Deep Learning, FP32 Performance, GPU Hosting