

Benchmarking DeepSeek R1 70B on Ollama: Which GPU Hosting is the Best Choice?
As large language models (LLMs) continue to evolve, DeepSeek R1 70B has emerged as a powerful option. However, running such a massive model requires high-performance GPUs. In this benchmark, we test DeepSeek R1 70B on four different servers using Ollama, comparing inference speed, GPU utilization (GPU UTL), and evaluation rate (Eval Rate in tokens/s) to determine the best server for running LLMs efficiently.
Key Factors in Choosing a GPU Server for DeepSeek-R1:70B
- Tokens/s – How fast can the server process DeepSeek-R1:32B reasoning tasks?
- GPU Utilization – Efficient use of GPU resources impacts stability and throughput.
- Cost vs. Performance – The balance between speed and affordability is key.
- Suitability for Different Users – Some servers are better for research, while others suit commercial applications.
Testing Environment & Benchmark Result
| GPU Server | Nvidia H100 | Quadro RTX A6000 | Nvidia A40 | Nvidia A100 * 2 |
|---|---|---|---|---|
| GPU Configs | Nvidia H100 Compute Capability: 9.0 Microarchitecture: Hopper CUDA Cores: 14,592 Tensor Cores: 456 Memory: 80GB HBM2e FP32: 183 TFLOPS Price: $2079.00/month Order Now > | Nvidia Quadro RTX A6000 Compute Capability: 8.6 Microarchitecture: Ampere CUDA Cores: 10,752 Tensor Cores: 336 Memory: 48GB GDDR6 FP32: 38.71 TFLOPS Price: $549.00/month Order Now > | Nvidia A40 Compute Capability: 8.6 Microarchitecture: Ampere CUDA Cores: 10,752 Tensor Cores: 336 Memory: 48GB GDDR6 FP32: 37.48 TFLOPS Price: $549.00/month Order Now > | Nvidia A100 * 2 Compute Capability: 8.0 Microarchitecture: Ampere CUDA Cores: 6912 Tensor Cores: 432 Memory: 40GB HBM2 * 2 FP3: 19.5 TFLOPS Price: $1139.00/month Order Now > |
| Models | deepseek-r1:70b, 43GB, Q4 | deepseek-r1:70b, 43GB, Q4 | deepseek-r1:70b, 43GB, Q4 | deepseek-r1:70b, 43GB, Q4 |
| Downloading Speed(MB/s) | 113 | 113 | 113 | 113 |
| CPU Rate | 4% | 3% | 2% | 3% |
| RAM Rate | 4% | 4% | 3% | 4% |
| GPU UTL | 92% | 96% | 94% | 44%,44% |
| Eval Rate(tokens/s) | 24.94 | 13.65 | 12.10 | 19.34 |

Best GPU Recommendation for DeepSeek-R1:70B
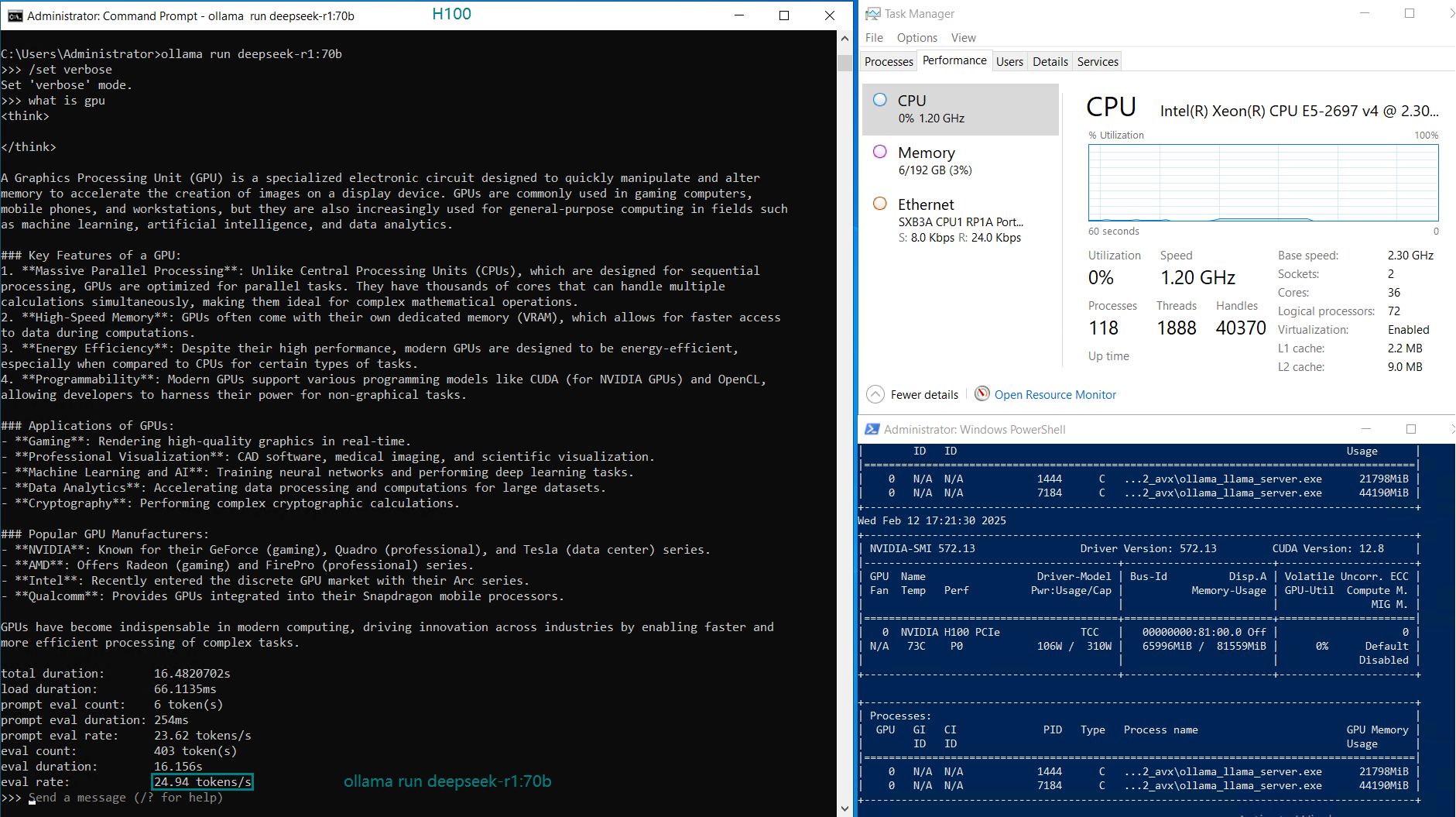
1️⃣. H100 Server: Best Performance, Highest Cost
- Eval Rate 24.94 tokens/s, the highest among all servers.
- GPU UTL: 92%, meaning it fully utilizes its compute power.
- Price: $2079/month, significantly higher than alternatives.
- Ideal for enterprises seeking maximum inference speed.
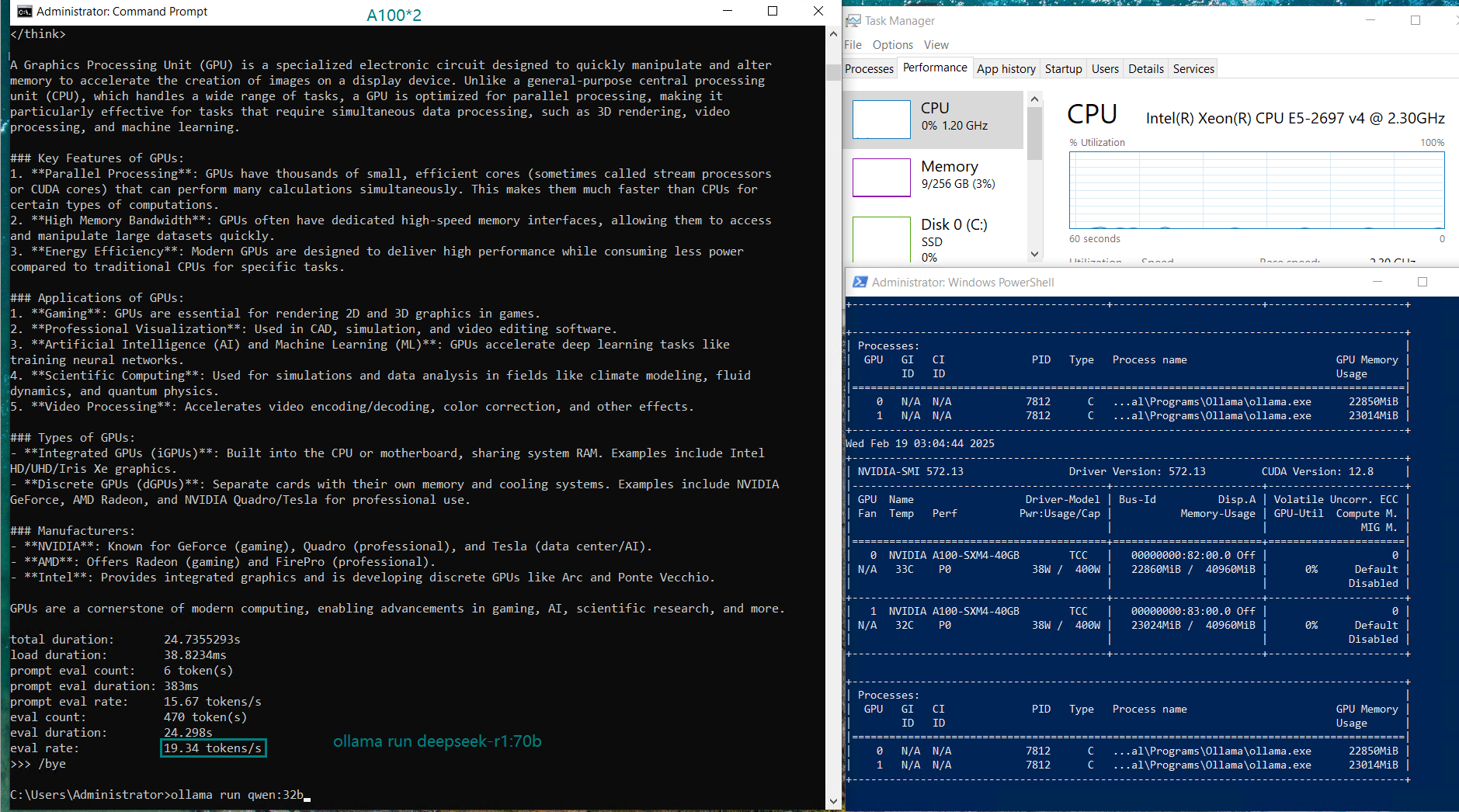
2️⃣. Dual A100 Server: Best Price-to-Performance Ratio
- Eval Rate 19.34 tokens/s, second only to the H100 server.
- GPU UTL: 44%+44%, showing efficient load balancing between two A100s.
- Price: $1139/month, making it a cost-effective alternative.
- Great choice for mid-sized companies needing high performance at a lower cost than H100.
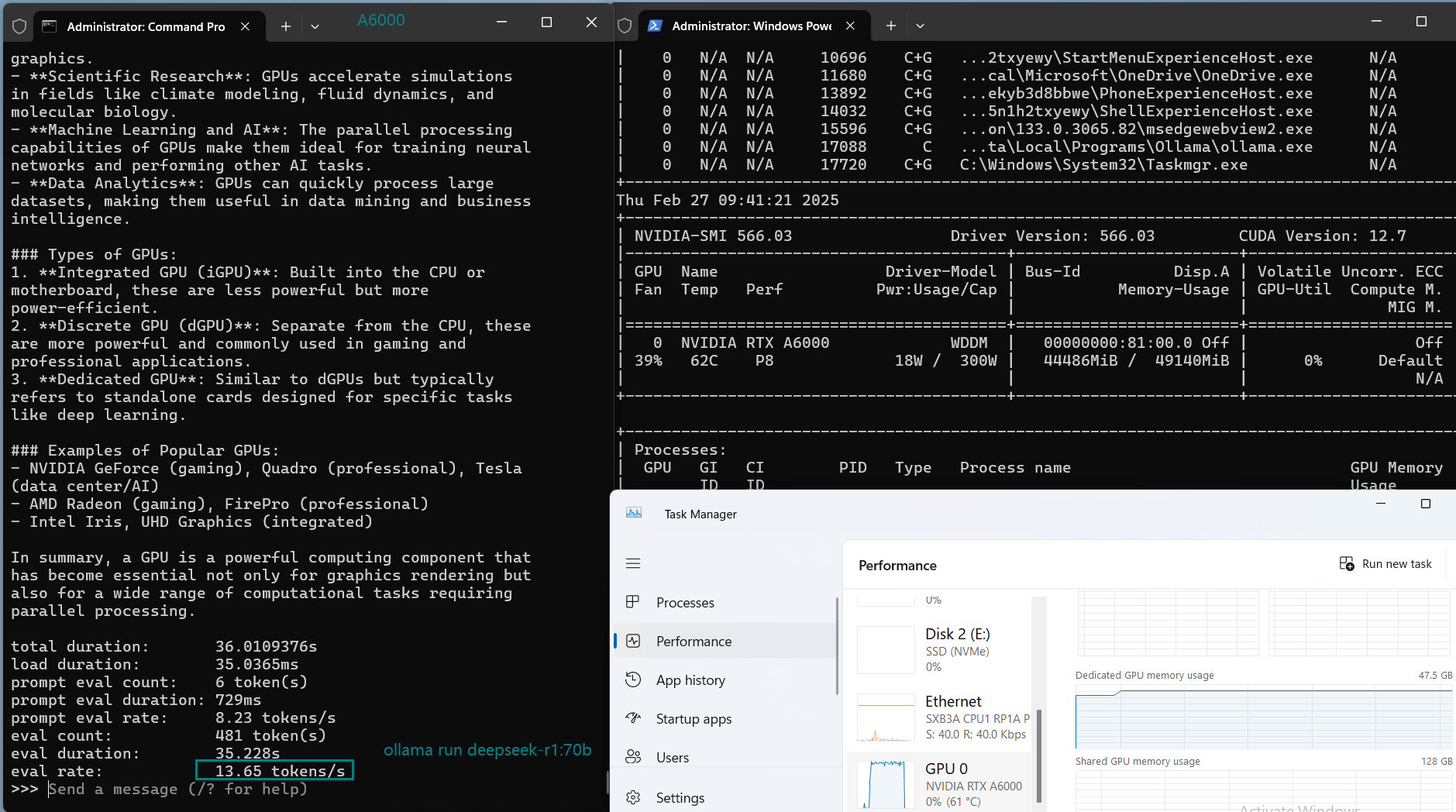
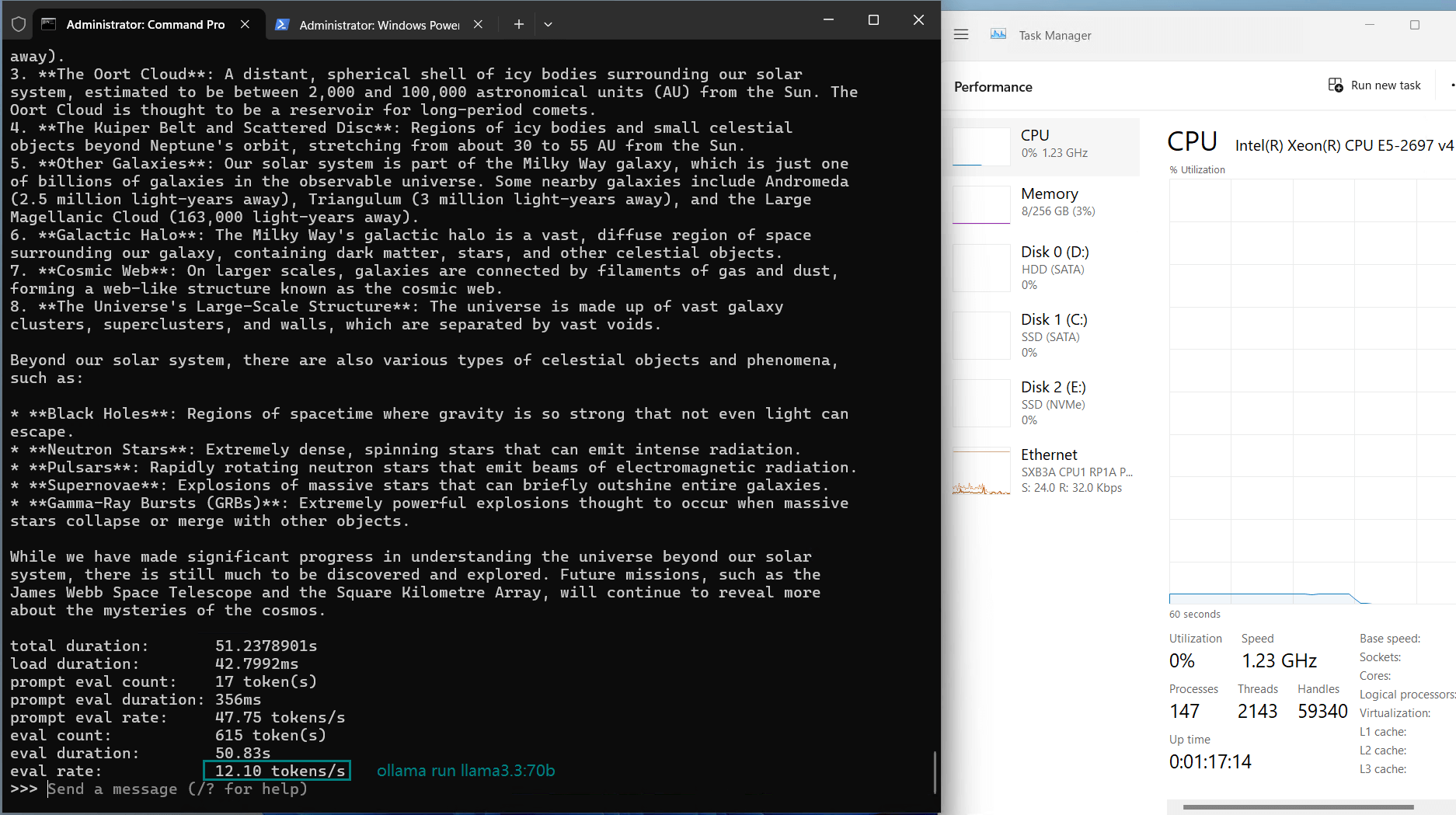
3️⃣. A6000 & A40 Servers: Cheaper but Slower
- Eval Rate: 13.65 tokens/s (A6000), 12.10 tokens/s (A40).
- Price: $549/month, only 1/4 the cost of H100.
- GPU UTL: 94%-96%, meaning they are nearly maxed out.
- Best for lightweight inference workloads or budget-conscious users.
Which Server is the Best?
- If you want the fastest inference speed regardless of cost, the H100 server is the best choice.
- If you need a balance between cost and performance, the Dual A100 server is the most cost-effective option.
- If you are on a tight budget and can tolerate slower speeds, A6000 or A40 servers provide a more affordable alternative.
📢 Rent the Best GPU Server for DeepSeek-R1:70B
Enterprise GPU Dedicated Server - H100
- 256GB RAM
- GPU: Nvidia H100
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Hopper
- CUDA Cores: 14,592
- Tensor Cores: 456
- GPU Memory: 80GB HBM2e
- FP32 Performance: 183TFLOPS
Enterprise GPU Dedicated Server - RTX A6000
- 256GB RAM
- GPU: Nvidia Quadro RTX A6000
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 10,752
- Tensor Cores: 336
- GPU Memory: 48GB GDDR6
- FP32 Performance: 38.71 TFLOPS
Enterprise GPU Dedicated Server - A40
- 256GB RAM
- GPU: Nvidia A40
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 10,752
- Tensor Cores: 336
- GPU Memory: 48GB GDDR6
- FP32 Performance: 37.48 TFLOPS
🎯 Final Verdict: Choose Based on Your Needs
For DeepSeek R1 70B inference on Ollama, the Nvidia H100 server delivers the highest speed, but the Dual A100 server provides a better balance of performance and affordability. If you’re running mission-critical applications, H100 is the way to go; if you need a cost-effective solution for LLM inference, Dual A100 is a great choice.
DeepSeek R1 70B benchmark, Ollama GPU inference, best GPU for DeepSeek 70B, Nvidia H100 vs A100 for AI, LLM inference comparison, A100 vs H100 for DeepSeek, RTX A6000 vs A40 AI performance, best cloud GPU for LLMs, DeepSeek R1 70B on Ollama, cost-effective GPU hosting for AI, GPU Hosting