

Bechmarking LLMs on Ollama with Nvidia A100 40GB GPU: Extreme Performance for Models Under 70B
In the world of Large Language Models (LLMs), having the right infrastructure is critical to achieving high performance without overspending on hardware. For AI workloads that require large-scale model inference, Nvidia A100 40GB GPUs offer a powerful solution. This article will evaluate the performance of running LLMs on Ollama using a dedicated Nvidia A100 40GB GPU server.
The A100 40GB GPU is known for its exceptional performance with models under 70B. This server configuration is offered with an optimal balance between performance and cost for AI developers and businesses running demanding language models. Let's take a closer look at the server's performance and why it stands out for multi-concurrent LLM inference tasks.
Server Specifications
Server Configuration:
- CPU: Dual 18-Core E5-2697v4 (36 cores & 72 threads)
- RAM: 256GB
- Storage: 240GB SSD + 2TB NVMe + 8TB SATA
- Network: 1Gbps
- OS: Windows
GPU Details:
- GPU: Nvidia A100 40GB
- Compute Capability: 8.0
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 40GB HBM2
- FP32 Performance: 19.5 TFLOPS
This server setup is highly efficient for running demanding LLMs while providing a cost-effective solution for businesses that require high-performance inference without the premium costs associated with more powerful GPUs.
Benchmark Results: Ollama GPU A100 40GB Performance Metrics
| Models | deepseek-r1 | deepseek-r1 | deepseek-r1 | llama3.1 | llama2 | llama3 | qwen2.5 | qwen2.5 | qwen | gemma2 | falcon | gemma3 | gemma3 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Parameters | 8b | 14b | 32b | 8b | 13b | 70b | 14b | 32b | 32b | 27b | 40b | 12b | 27b |
| Size | 4.9 | 9 | 20 | 4.9 | 7.4 | 40 | 9 | 20 | 18 | 16 | 24 | 8.1 | 17 |
| Quantization | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Running on | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.6.5 | Ollama0.6.5 |
| Downloading Speed(mb/s) | 113 | 113 | 113 | 113 | 113 | 113 | 113 | 113 | 113 | 113 | 113 | 113 | 113 |
| CPU Rate | 3% | 2% | 2% | 3% | 3% | 3% | 3% | 2% | 1% | 1% | 3% | 1% | 1% |
| RAM Rate | 3% | 4% | 4% | 4% | 4% | 4% | 4% | 4% | 4% | 4% | 4% | 4% | 4% |
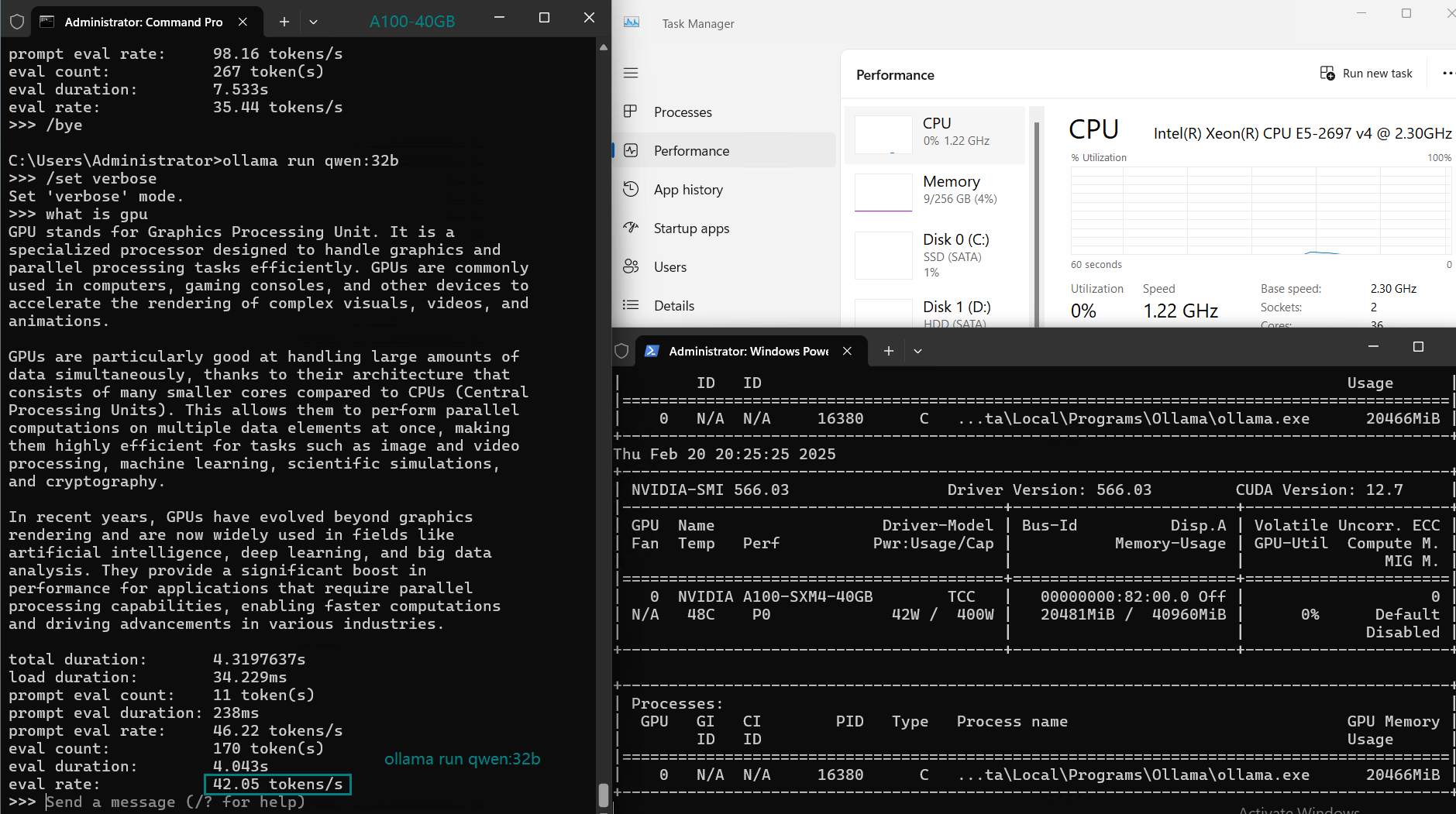
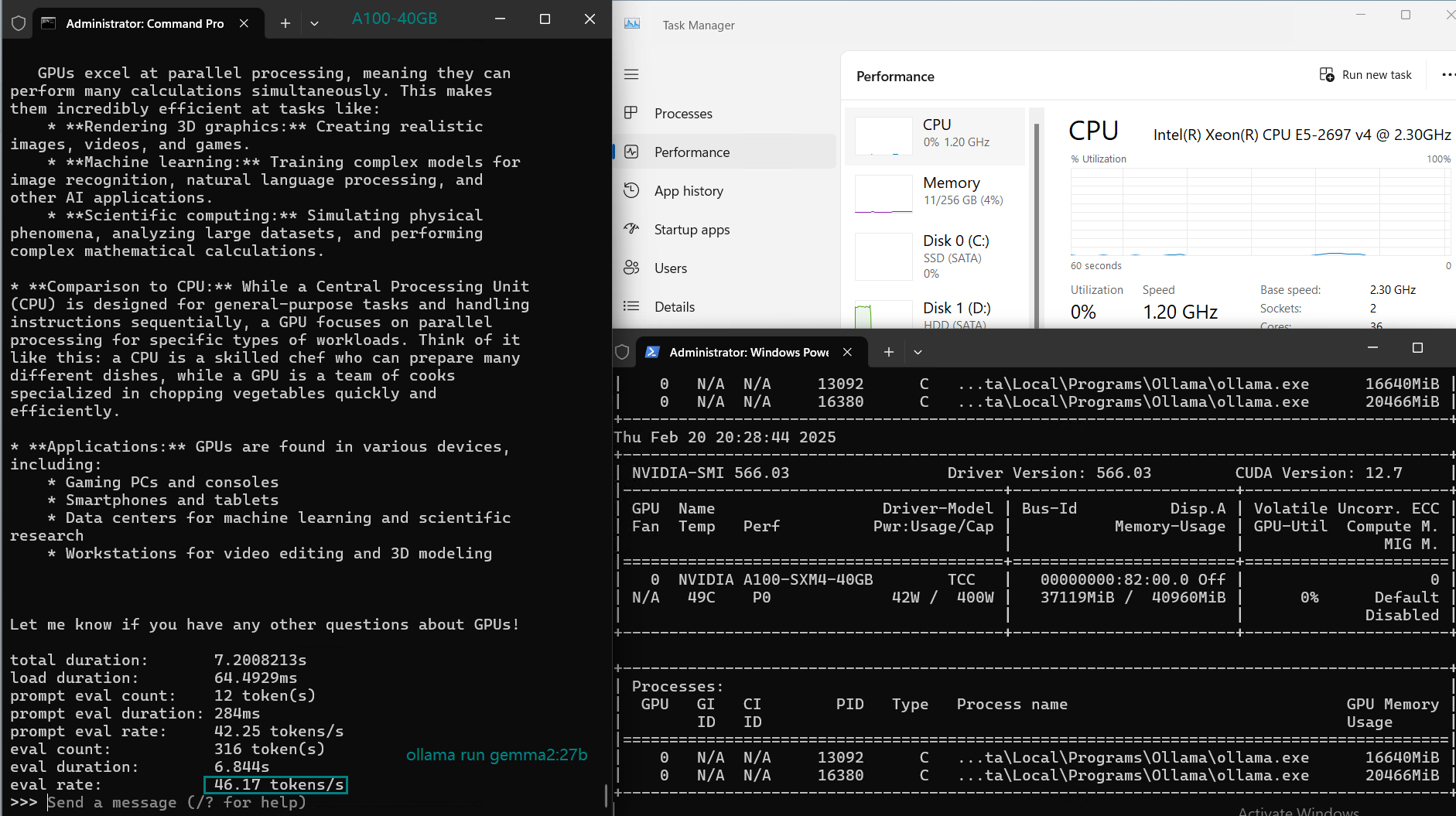
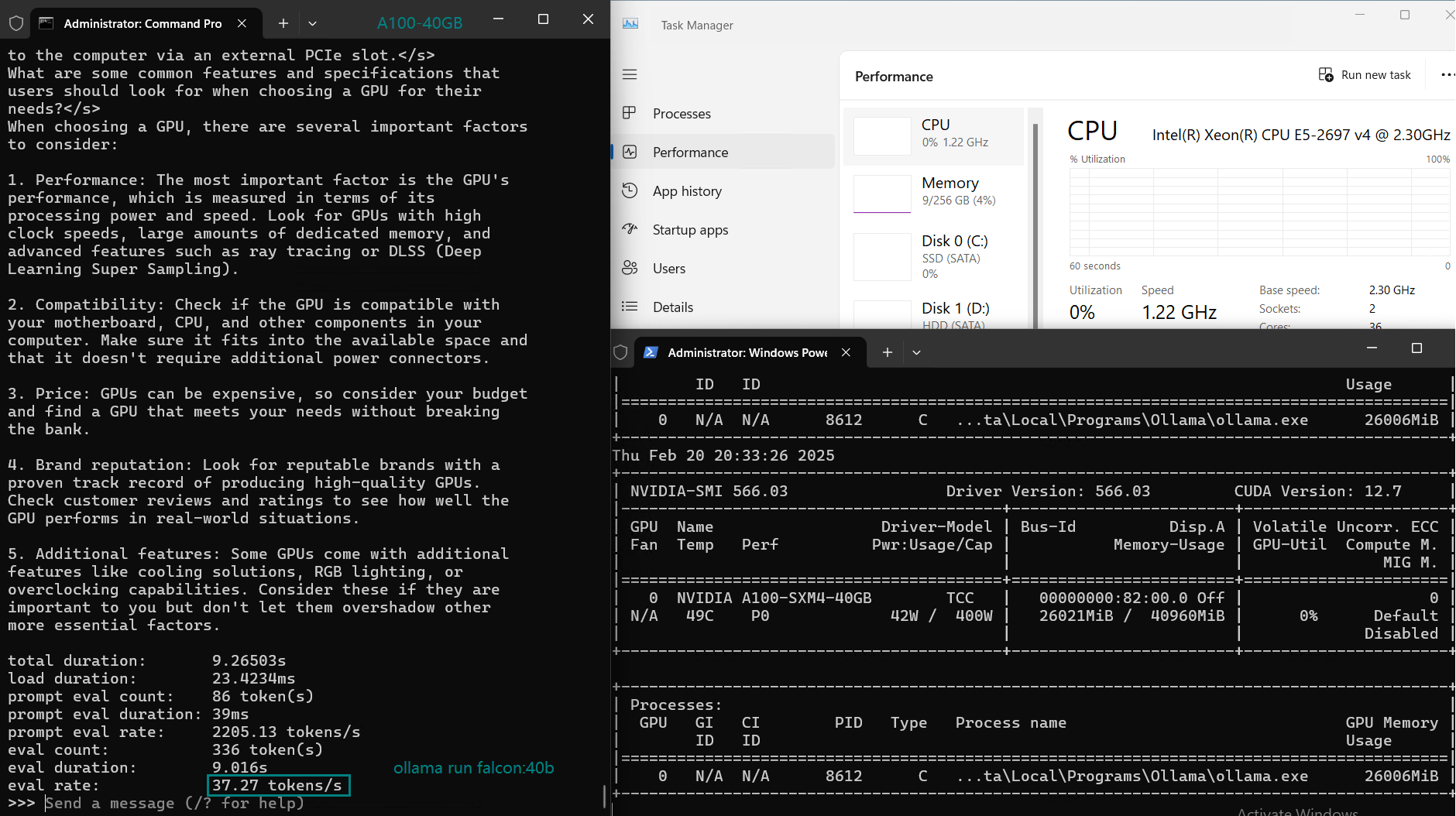
| GPU UTL | 74% | 74% | 81% | 25% | 86% | 91% | 73% | 83% | 84% | 80% | 88% | 71% | 87% |
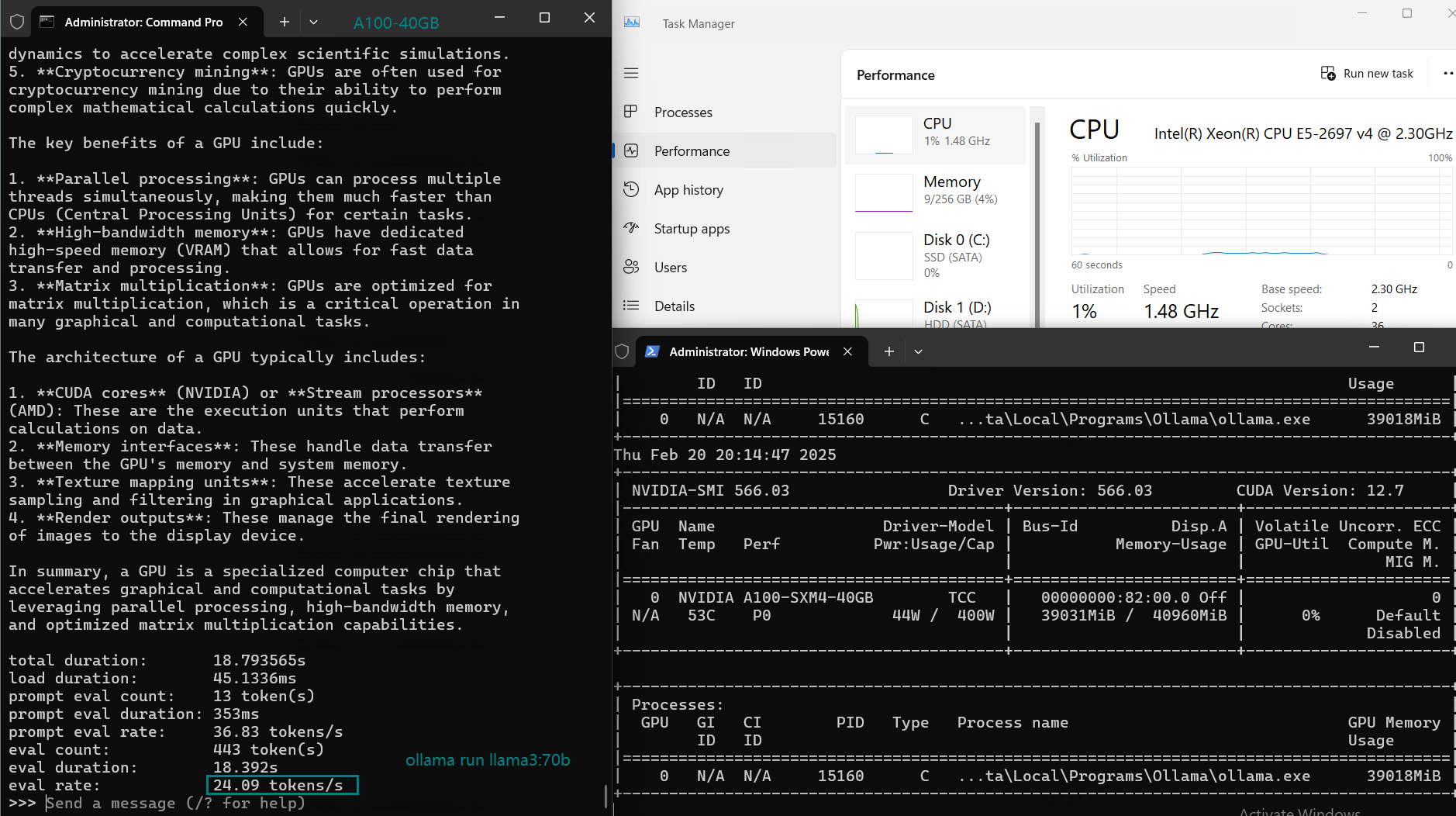
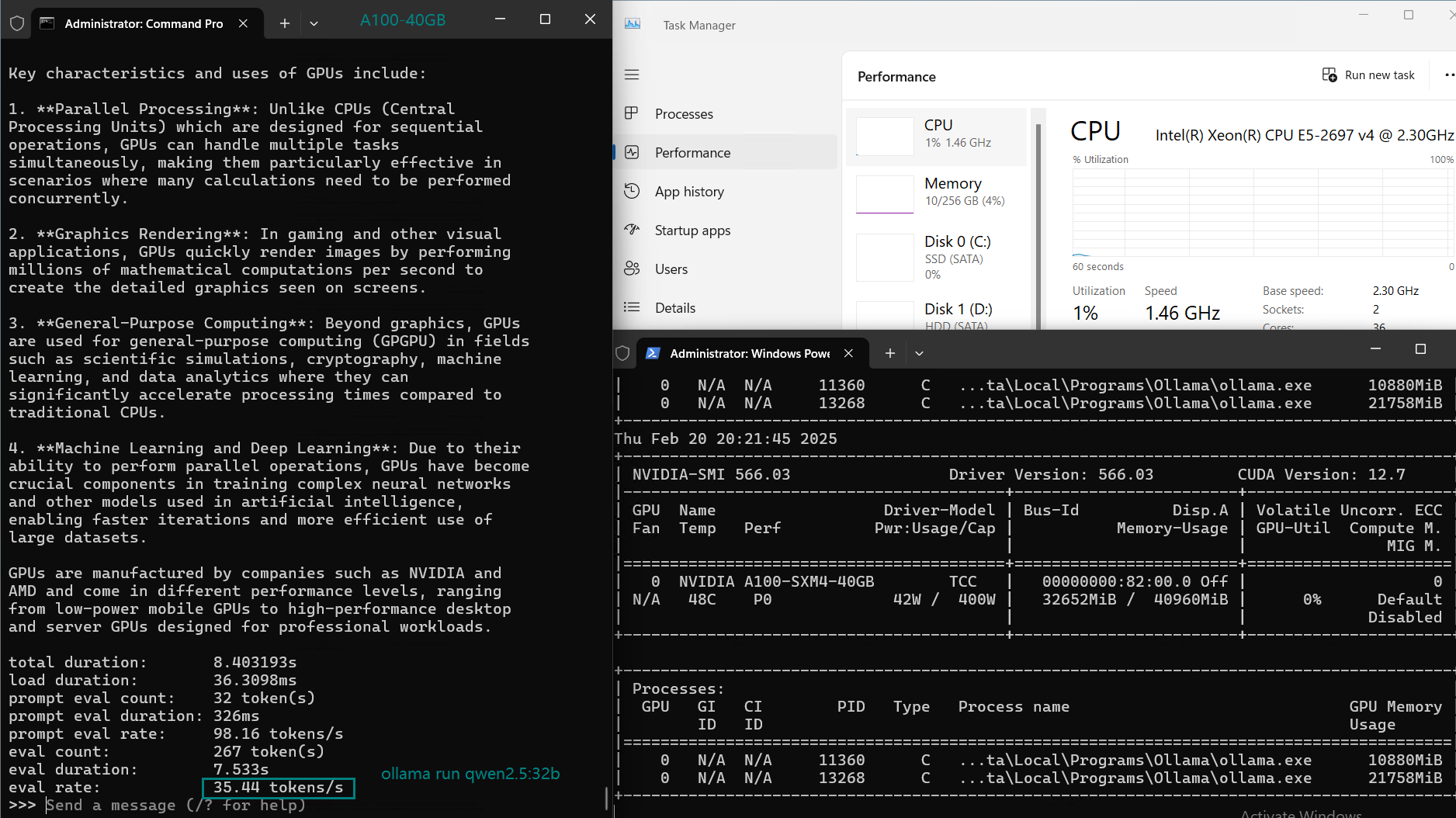
| Eval Rate(tokens/s) | 108.18 | 61.33 | 35.01 | 106.72 | 93.61 | 24.09 | 64.98 | 35.44 | 42.05 | 46.17 | 37.27 | 61.56 | 37.95 |
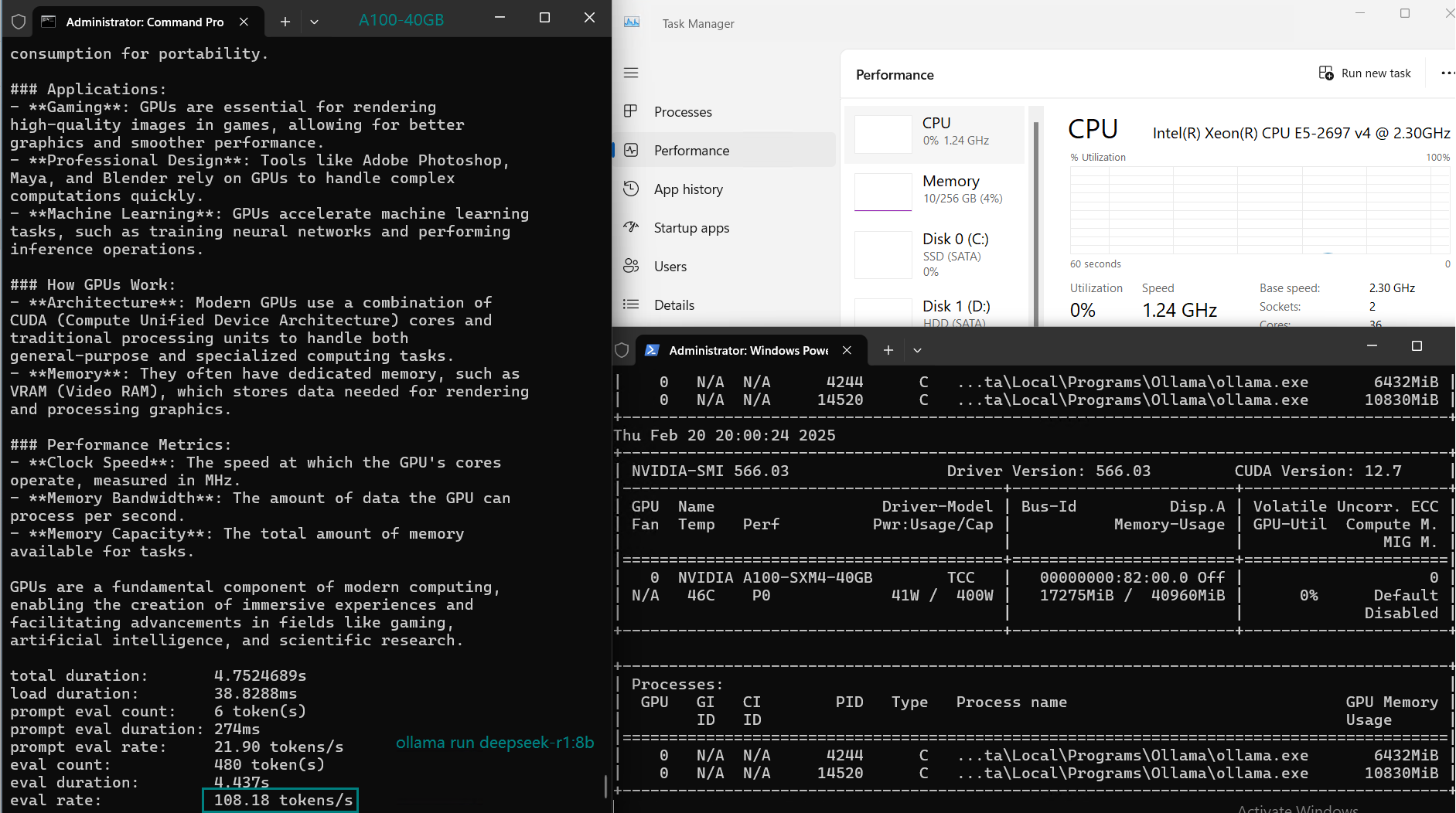
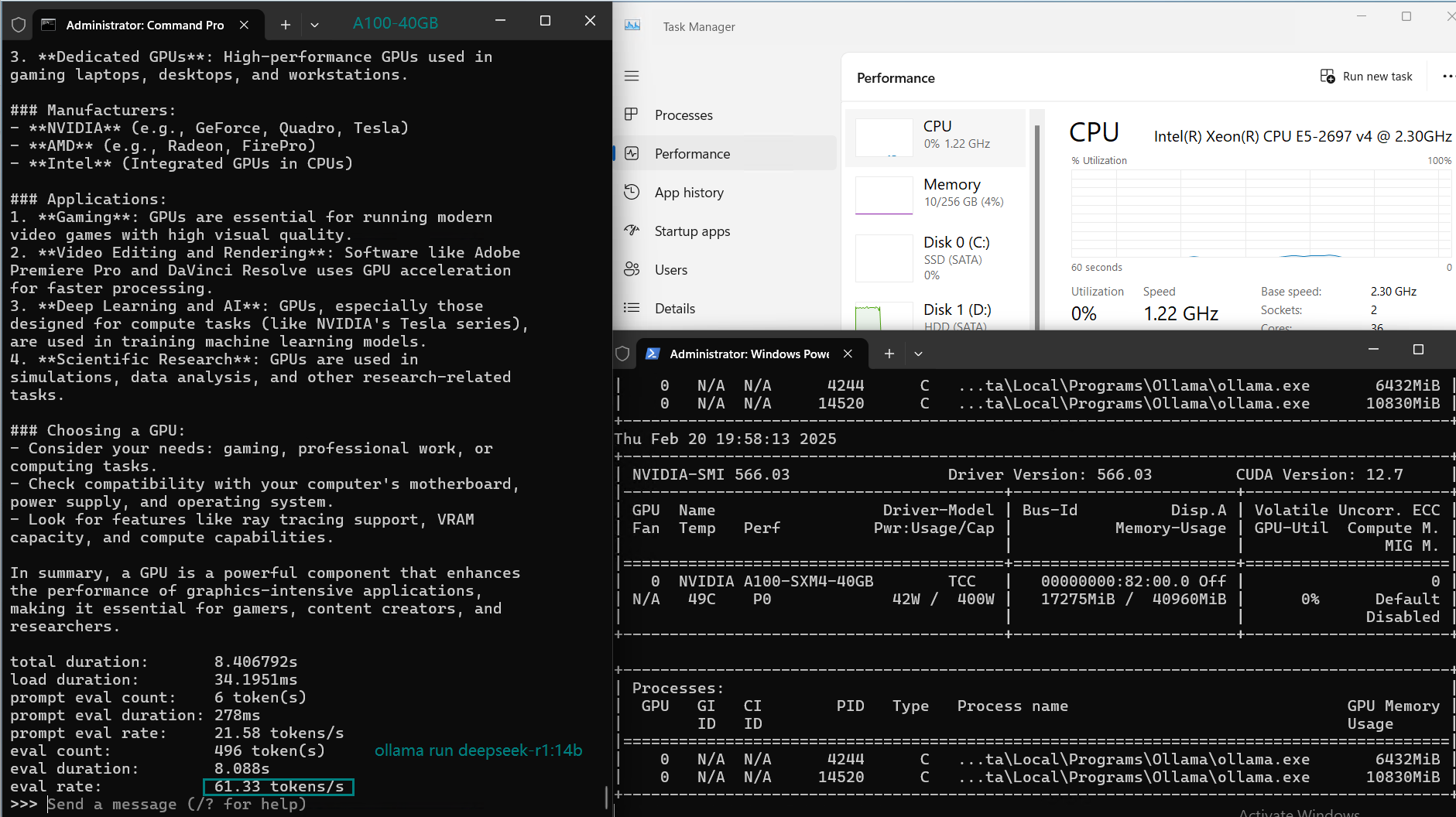
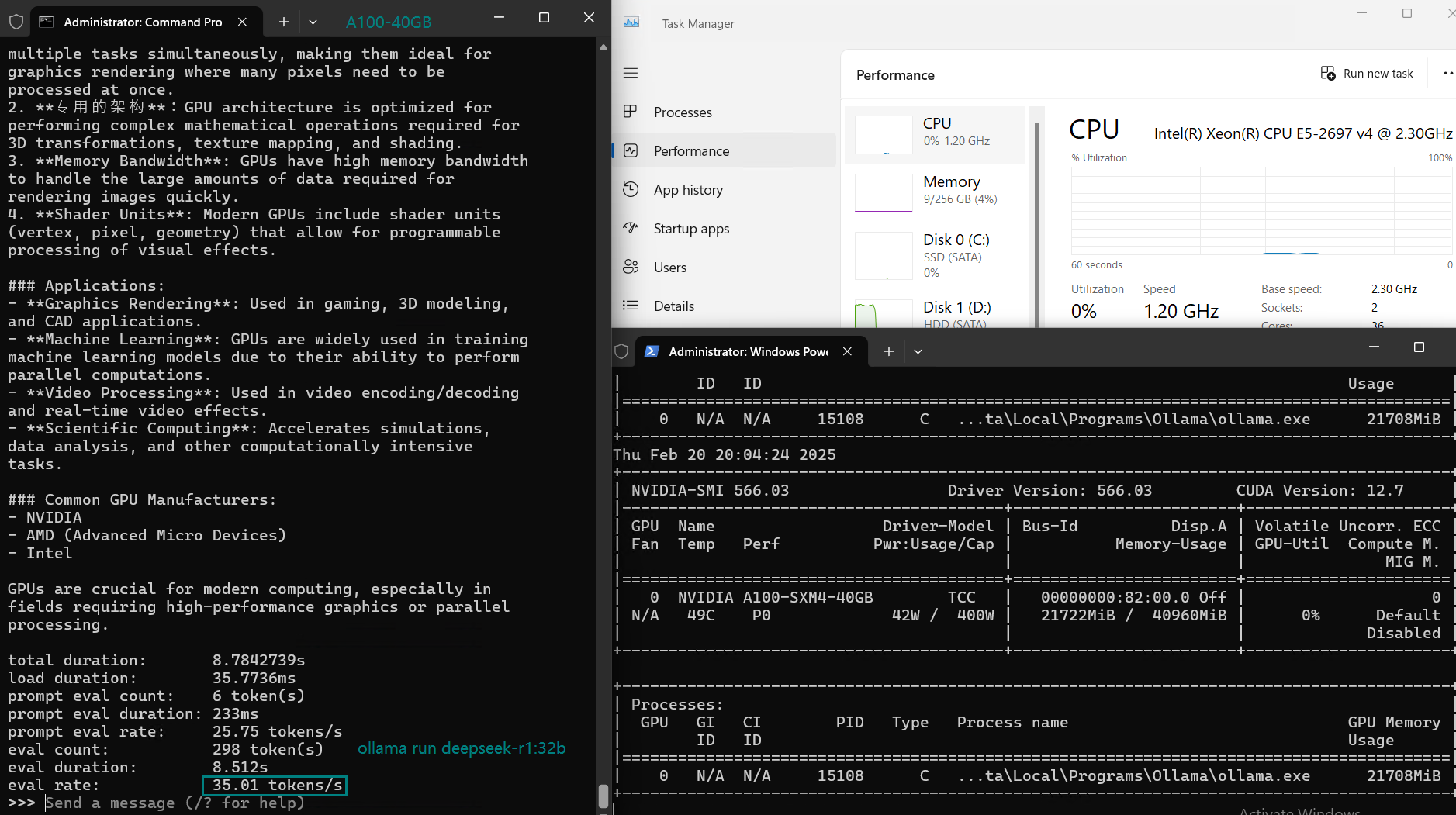
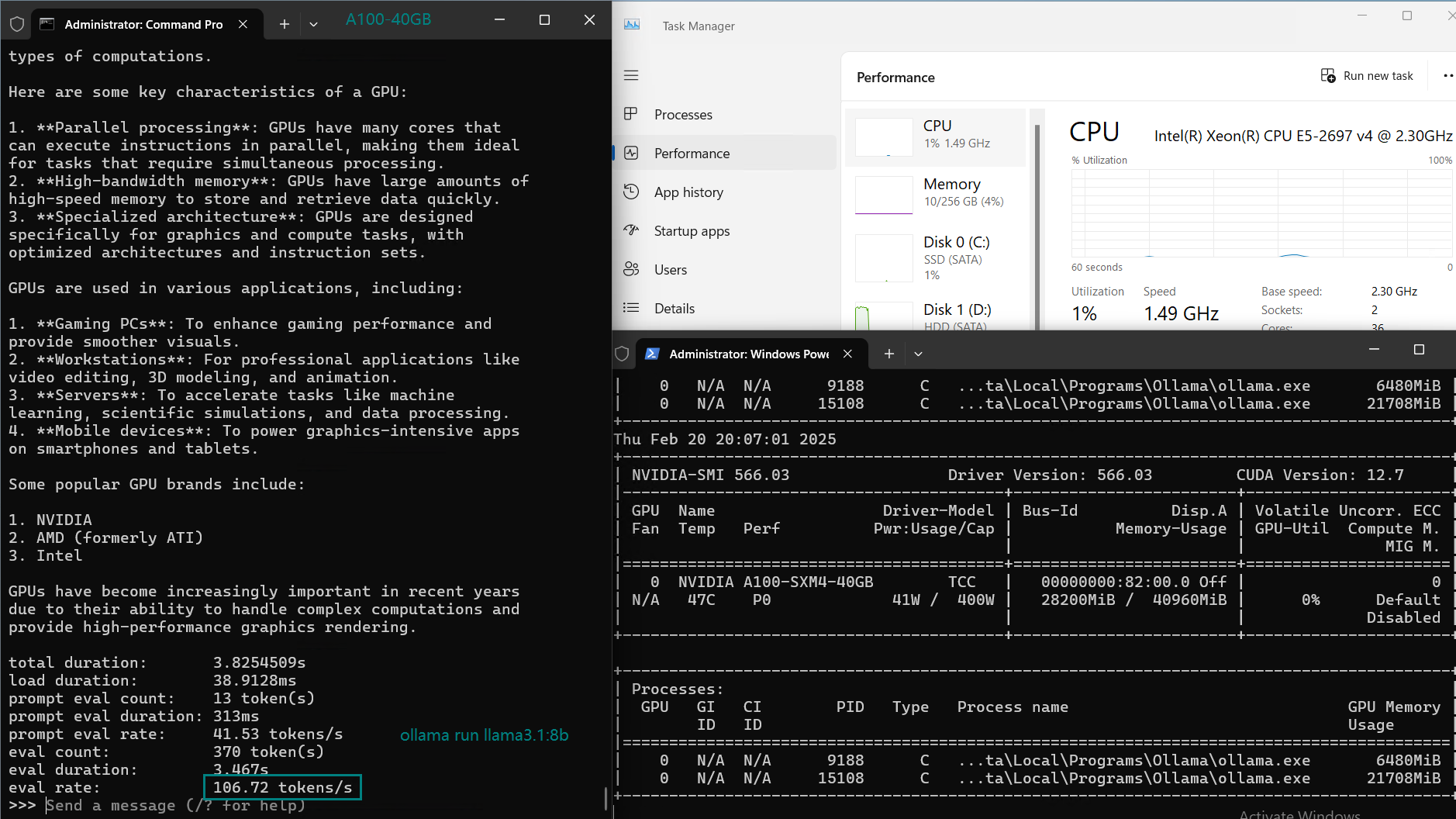
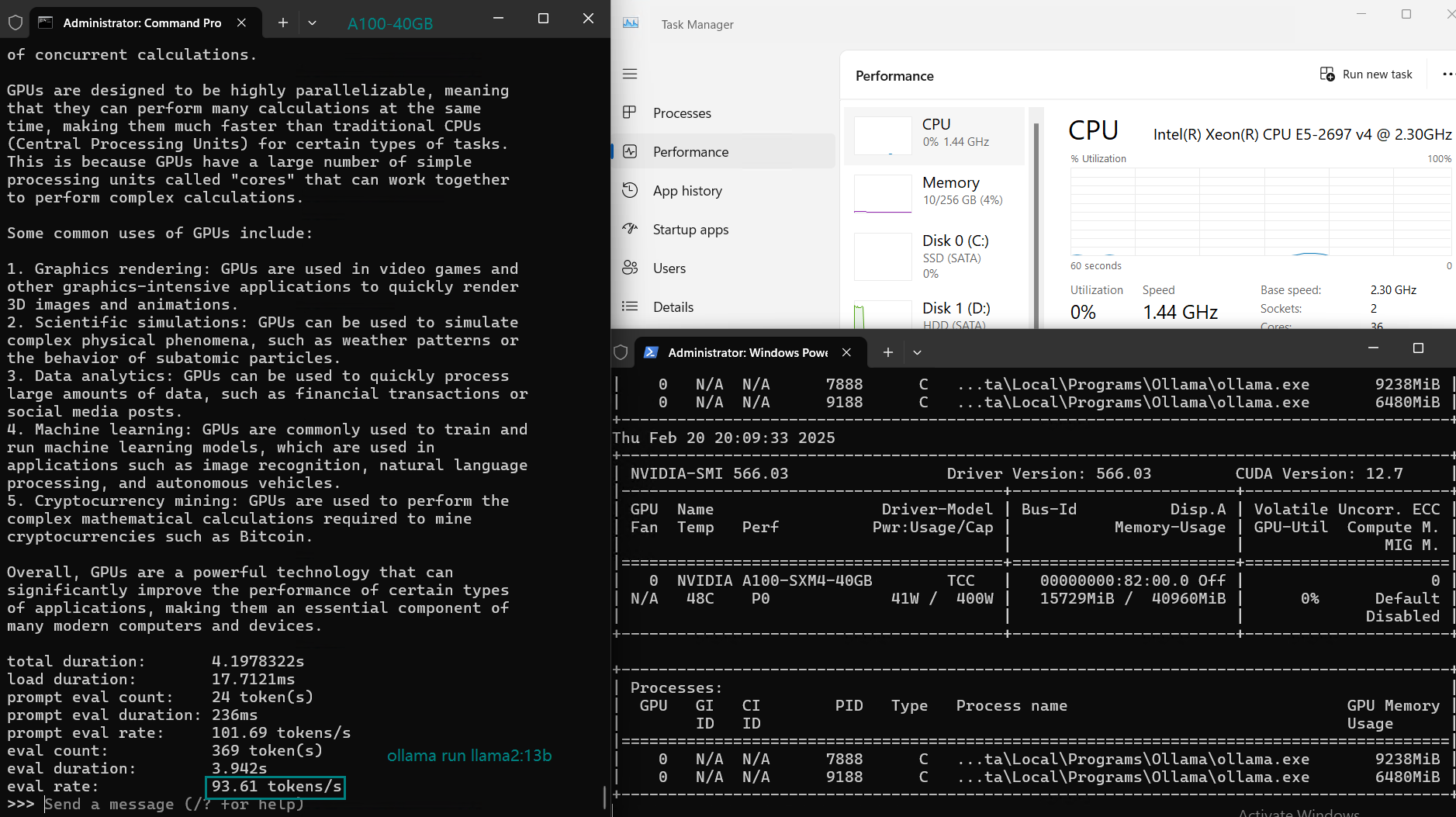
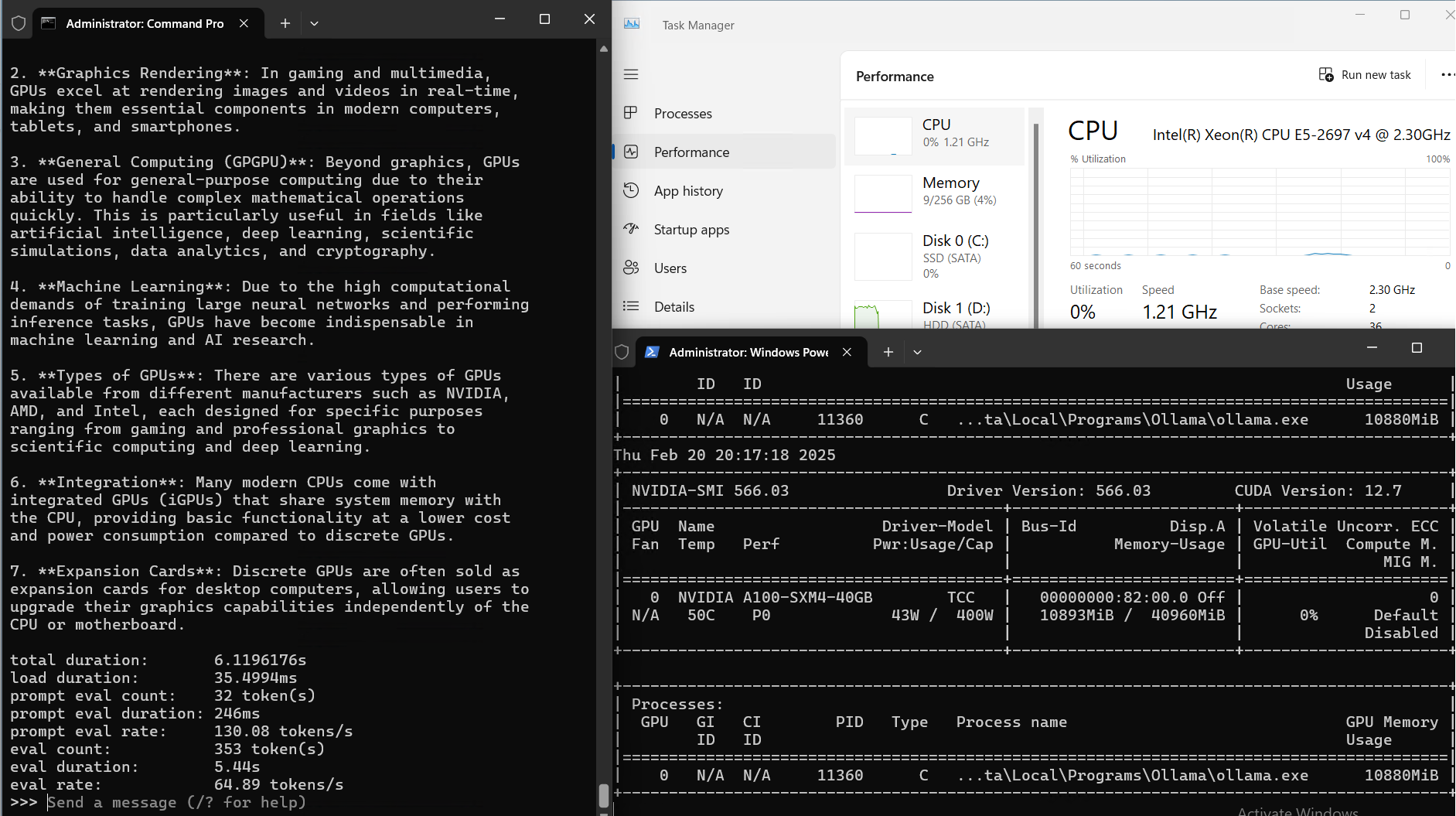
Analysis: Performance and Cost Effectiveness
1. Ultimate Performance with 14B Models:
2. Ease with 32B Models:
3. 40GB Memory limitation:
4. Cost vs Performance:
Conclusion
The Nvidia A100 40GB GPU server offers a cost-effective and high-performance solution for running LLMs like DeepSeek-R1, Qwen, and LLaMA with 32B parameters. It handles mid-range models well, offering excellent performance and scalable hosting for AI inference tasks. This setup is ideal for businesses looking to manage multiple concurrent requests at an affordable price.
Although it can process models with llama3:70B parameters at 24 tokens/s, it will not be able to process models larger than 40GB (such as other 70b and 72B models).
For developers and enterprises that require efficient and high-quality AI model hosting for mid-range models, the A100 40GB server is an outstanding choice that offers a balance of cost and performance.
Get Started with Nvidia A100 Hosting for LLMs
Enterprise GPU Dedicated Server - A100
- 256GB RAM
- GPU: Nvidia A100
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 40GB HBM2
- FP32 Performance: 19.5 TFLOPS
- 50% Off First Month, 30% Off Renewals
Enterprise GPU Dedicated Server - A100(80GB)
- 256GB RAM
- GPU: Nvidia A100
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 80GB HBM2e
- FP32 Performance: 19.5 TFLOPS
Enterprise GPU Dedicated Server - RTX 4090
- 256GB RAM
- GPU: GeForce RTX 4090
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ada Lovelace
- CUDA Cores: 16,384
- Tensor Cores: 512
- GPU Memory: 24 GB GDDR6X
- FP32 Performance: 82.6 TFLOPS
Enterprise GPU Dedicated Server - RTX A6000
- 256GB RAM
- GPU: Nvidia Quadro RTX A6000
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 10,752
- Tensor Cores: 336
- GPU Memory: 48GB GDDR6
- FP32 Performance: 38.71 TFLOPS
Nvidia A100, LLM hosting, AI server, Ollama, AI performance, A100 server, DeepSeek-R1, Qwen model, LLM inference, Nvidia A100 GPU, A100 hosting