

Benchmarking LLMs on Ollama with NVIDIA A4000 GPU VPS
As large language models (LLMs) continue to evolve, running them efficiently on GPU-optimized virtual private servers (VPS) is becoming a crucial factor for AI developers and businesses. In this benchmark, we evaluate the performance of various LLMs on Ollama using an NVIDIA A4000 GPU VPS. This test aims to help users determine the best AI models for inference, comparing key factors such as evaluation speed, GPU utilization, and overall system performance.
Test Server Configuration
Server Configuration:
- Price: $179/month
- CPU: 24 cores
- RAM: 32GB
- Storage: 320GB SSD
- Network: 300Mbps Unmetered
- OS: Windows
- Backup: Once per 2 weeks
GPU Details:
- GPU: NVIDIA Quadro RTX A4000
- Compute Capability: 8.6
- Microarchitecture: Ampere
- CUDA Cores: 6144
- Tensor Cores: 192
- Memory: 16GB GDDR6
- FP32 Performance: 19.2 TFLOPS
This configuration ensures optimal performance for AI inference workloads, making it a solid choice for Ollama VPS hosting and LLM inference tasks.
Ollama Benchmark: Testing LLMs on NVIDIA A4000 VPS
| Models | deepseek-r1 | deepseek-r1 | deepseek-r1 | deepseek-coder-v2 | llama2 | llama2 | llama3.1 | mistral | gemma2 | gemma2 | qwen2.5 | qwen2.5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Parameters | 7b | 8b | 14b | 16b | 7b | 13b | 8b | 7b | 9b | 27b | 7b | 14b |
| Size(GB) | 4.7 | 4.9 | 9 | 8.9 | 3.8 | 7.4 | 4.9 | 4.1 | 5.4 | 16 | 4.7 | 9.0 |
| Quantization | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Running on | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 |
| Downloading Speed(mb/s) | 36 | 36 | 36 | 36 | 36 | 36 | 36 | 36 | 36 | 36 | 36 | 36 |
| CPU Rate | 8% | 7% | 8% | 8% | 8% | 8% | 8% | 8% | 7% | 70-86% | 8% | 7% |
| RAM Rate | 16% | 18% | 17% | 16% | 15% | 15% | 15% | 18% | 19% | 21% | 16% | 17% |
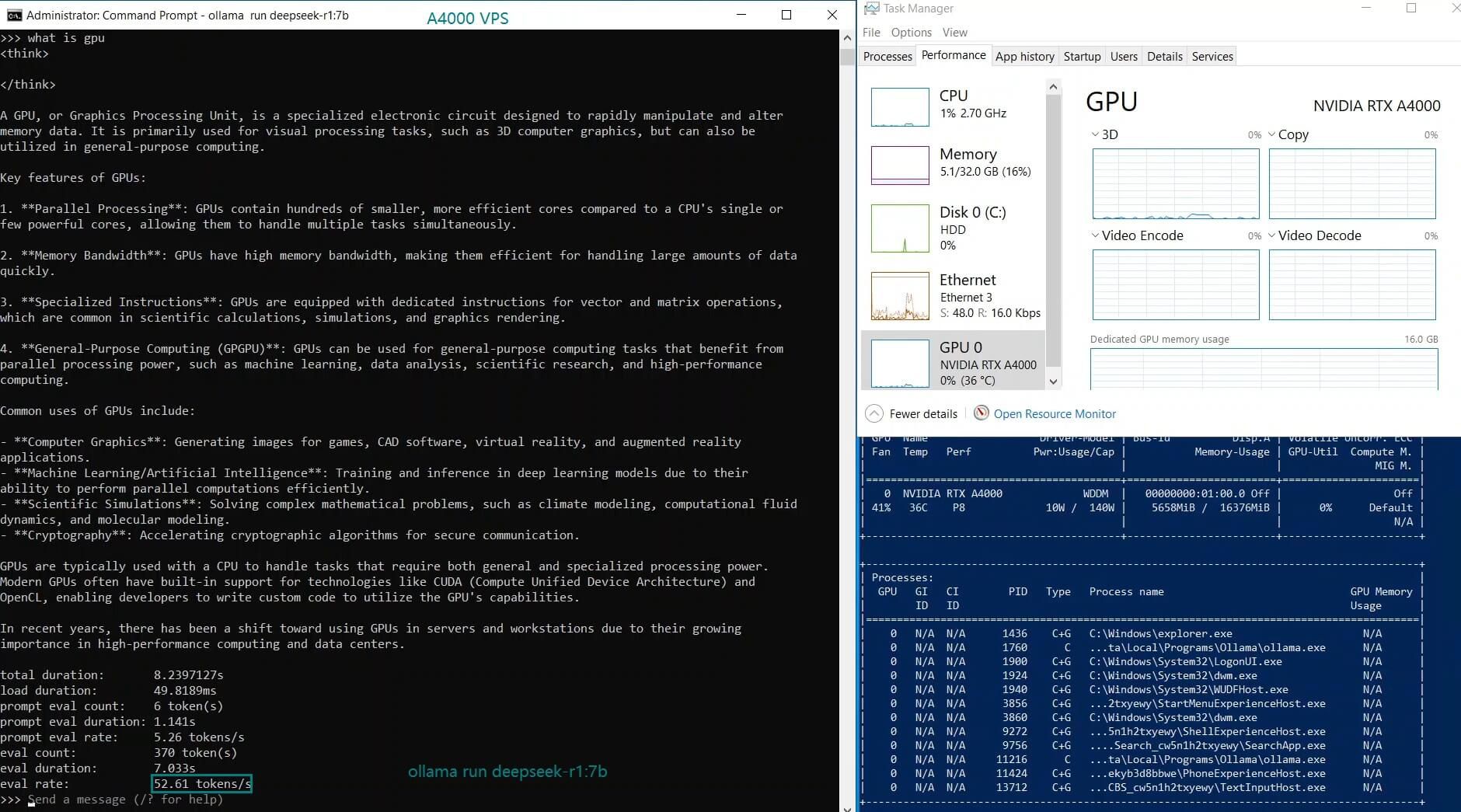
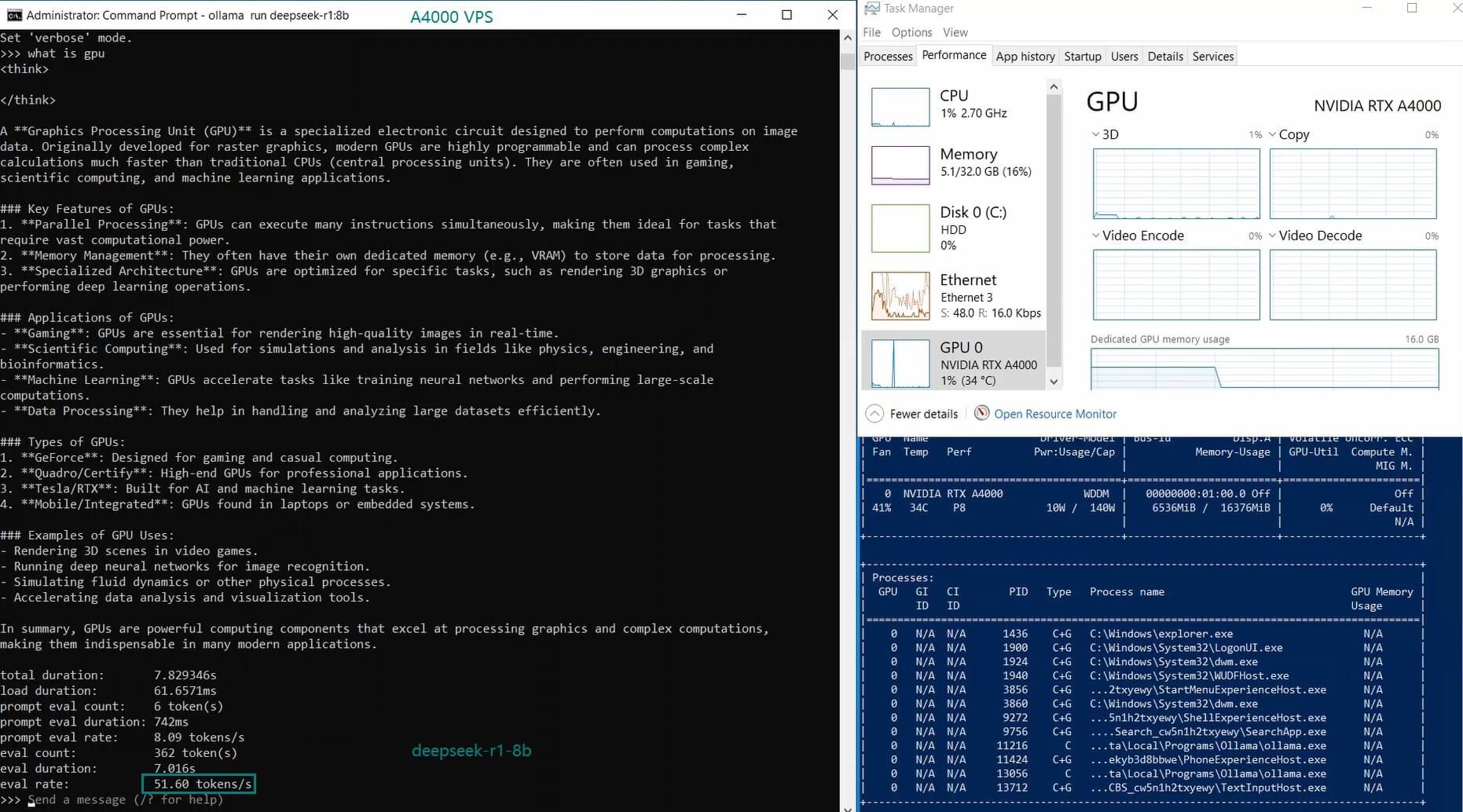
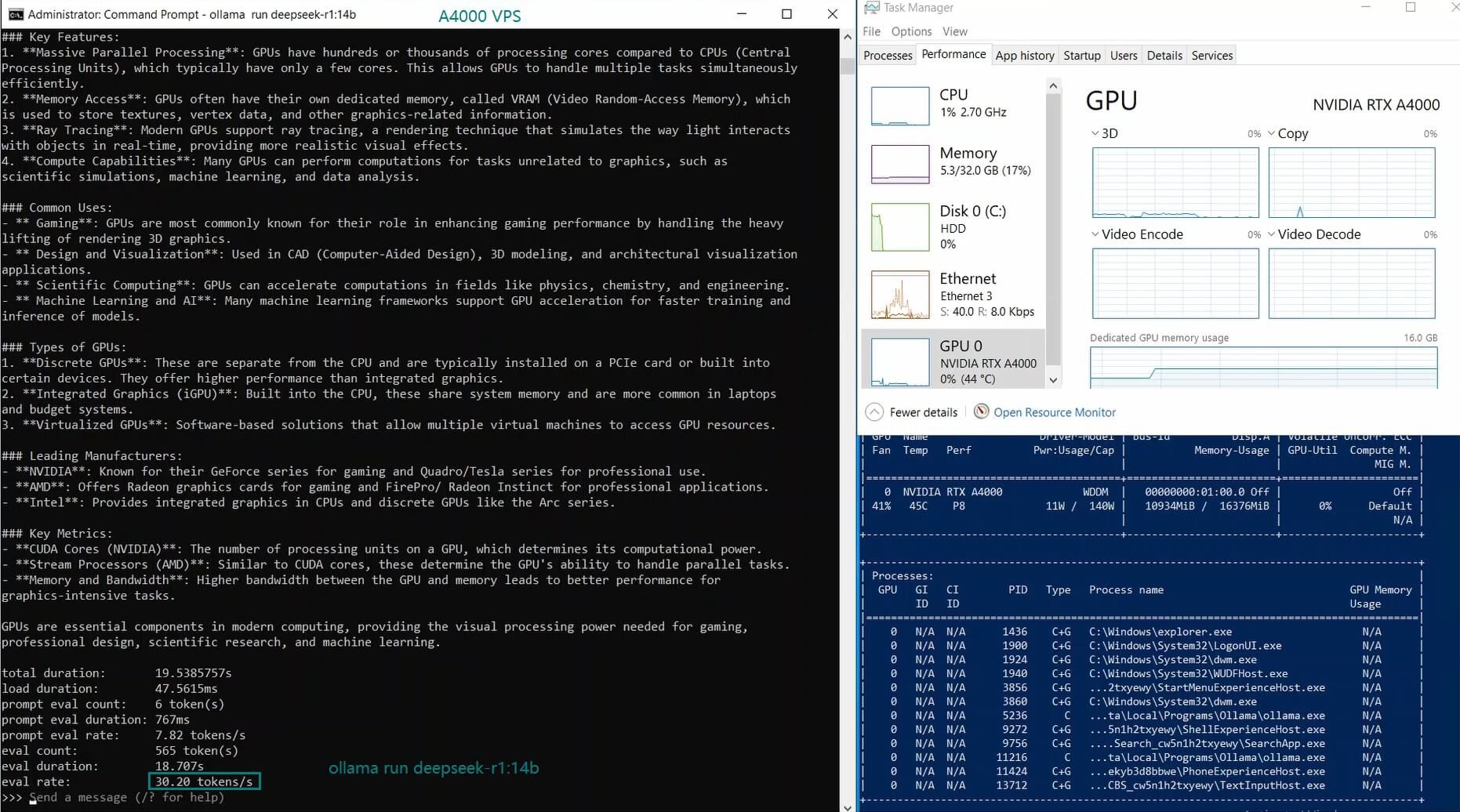
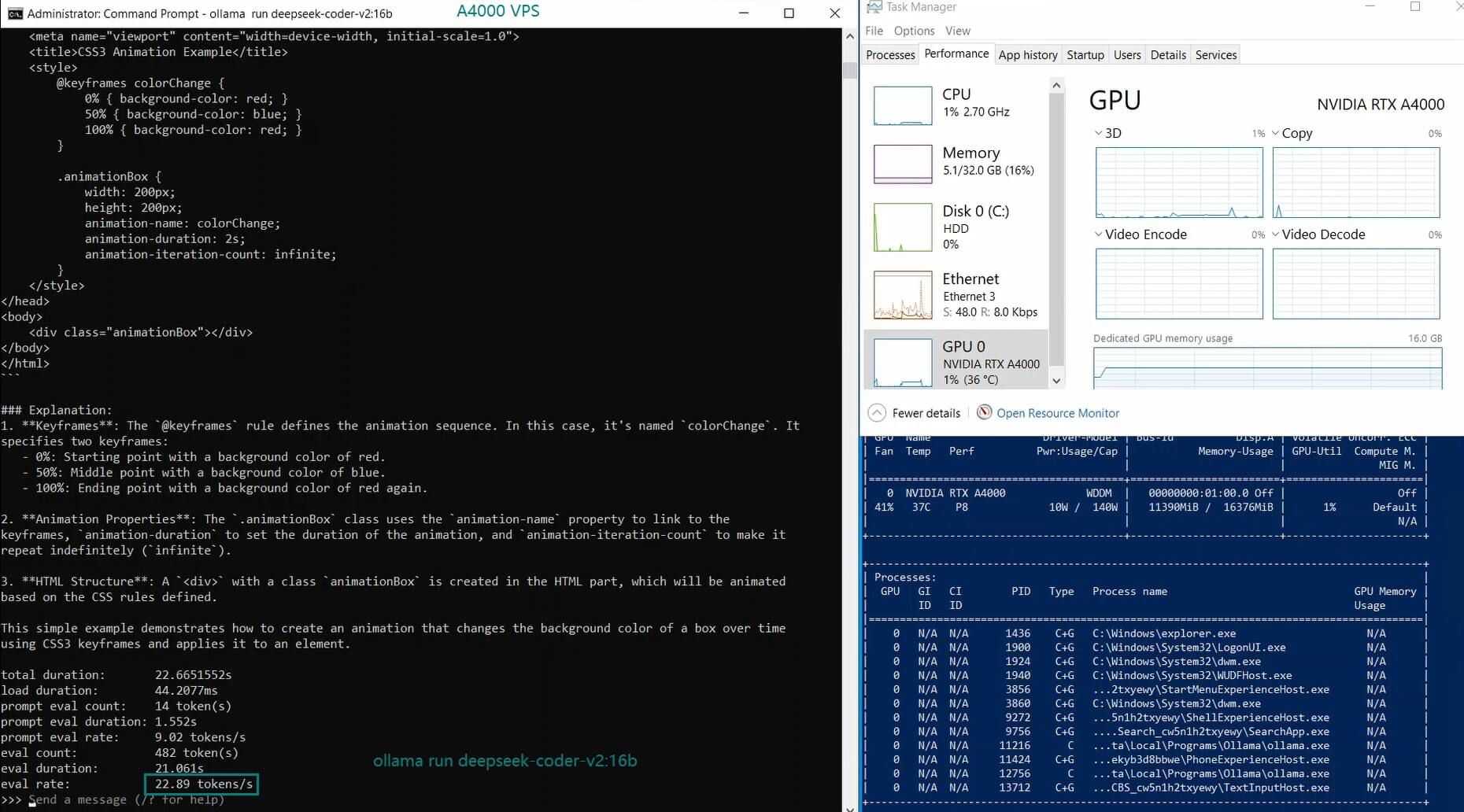
| GPU UTL | 77% | 78% | 83% | 40% | 82% | 89% | 78% | 81% | 73% | 1% | 12% | 80% |
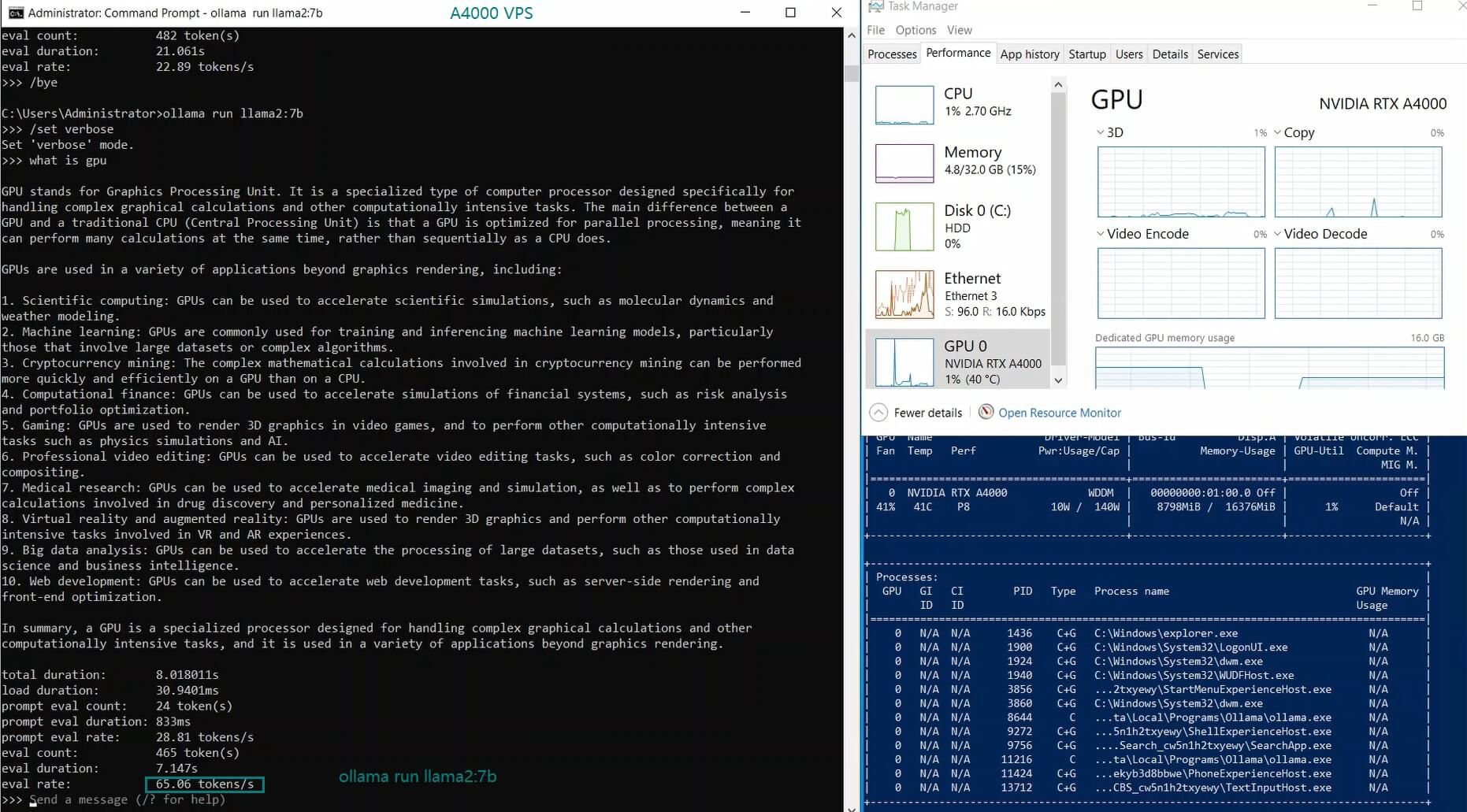
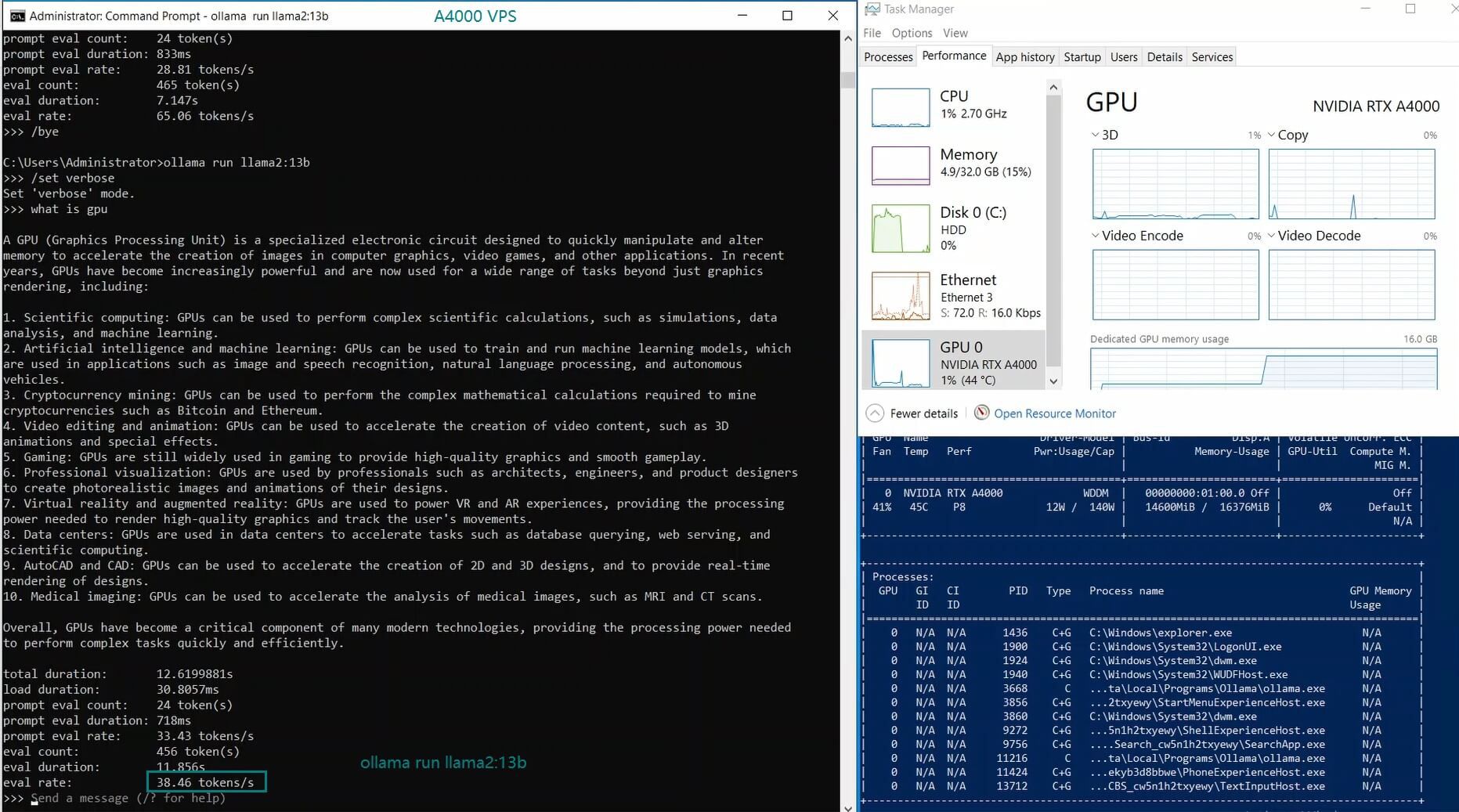
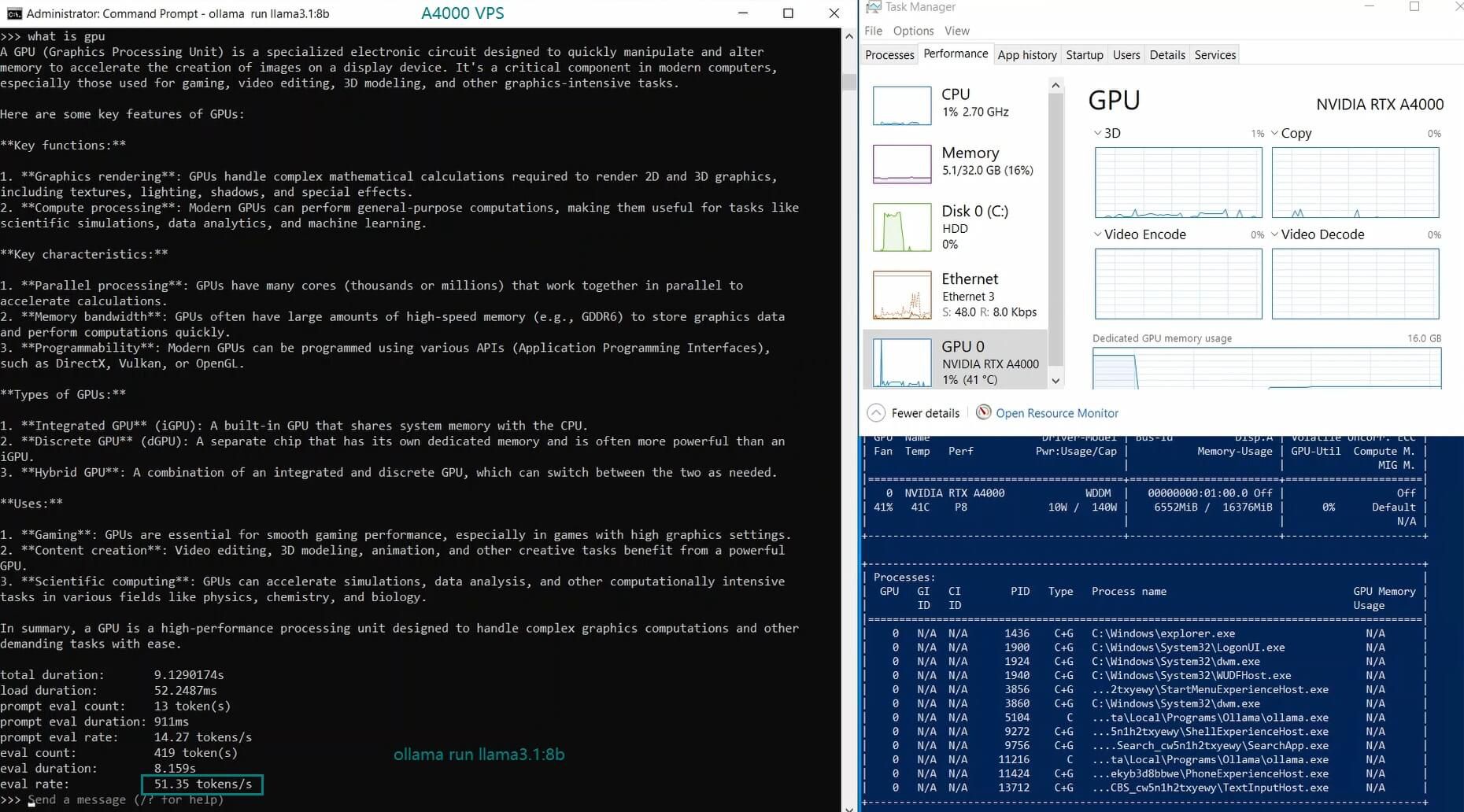
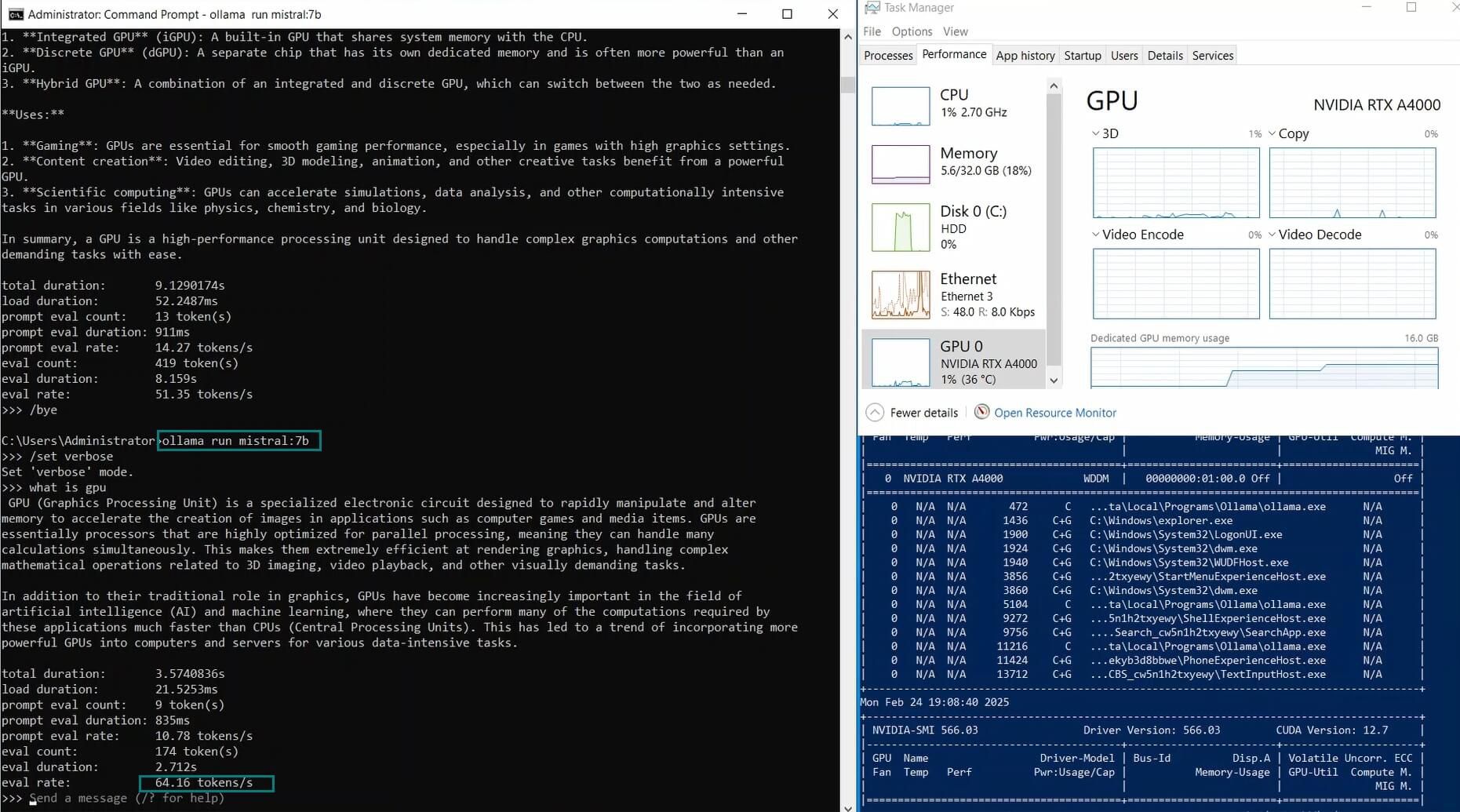
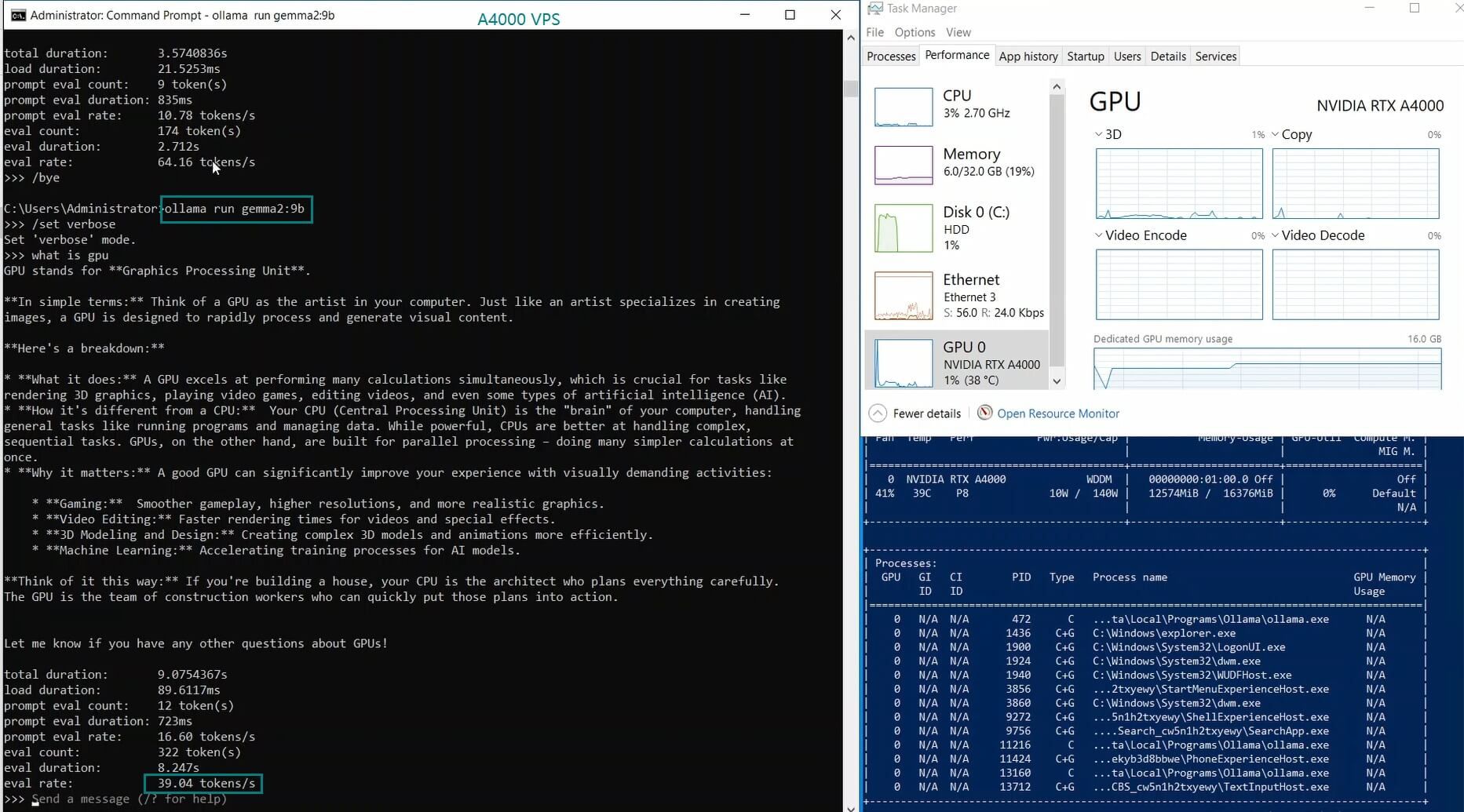
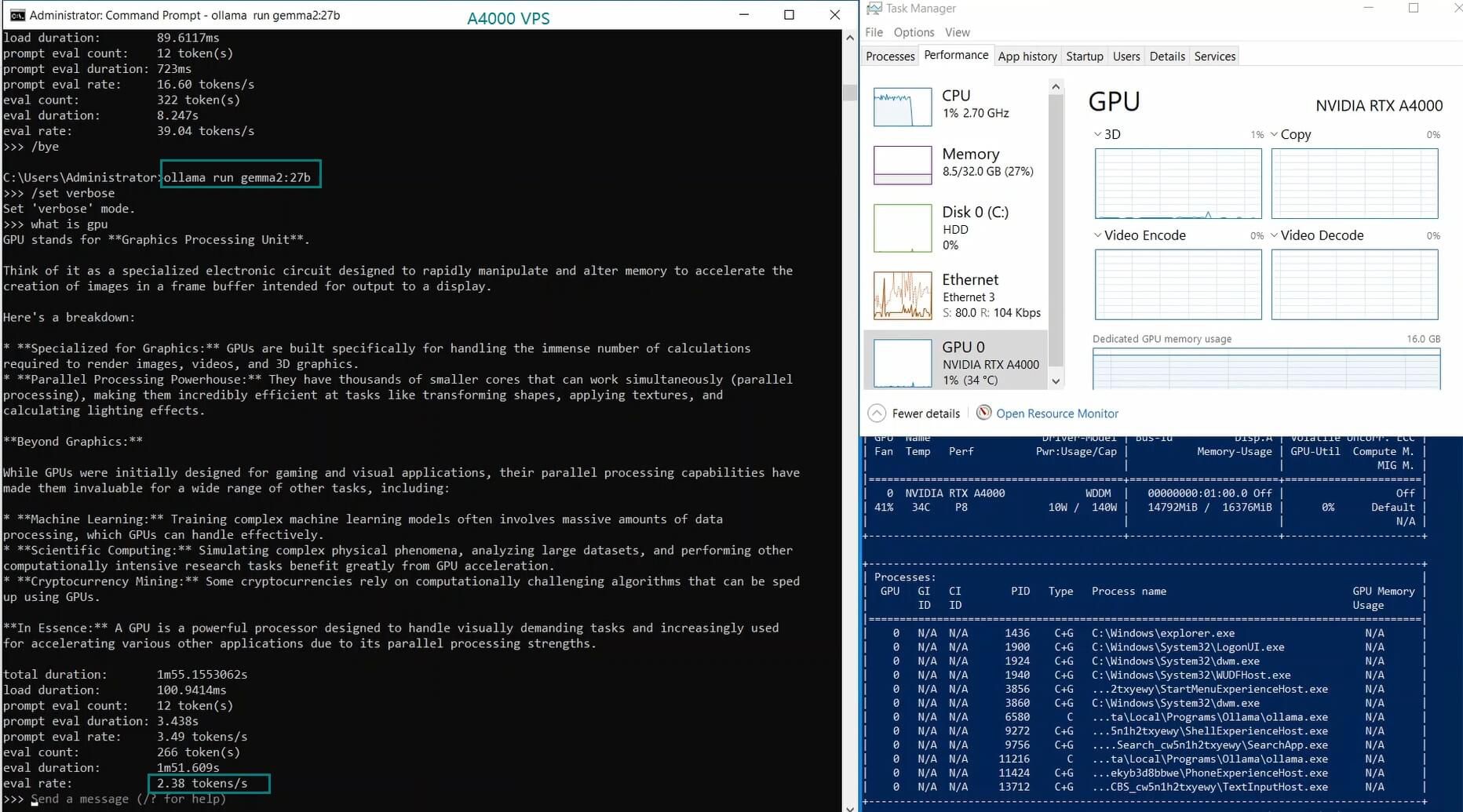
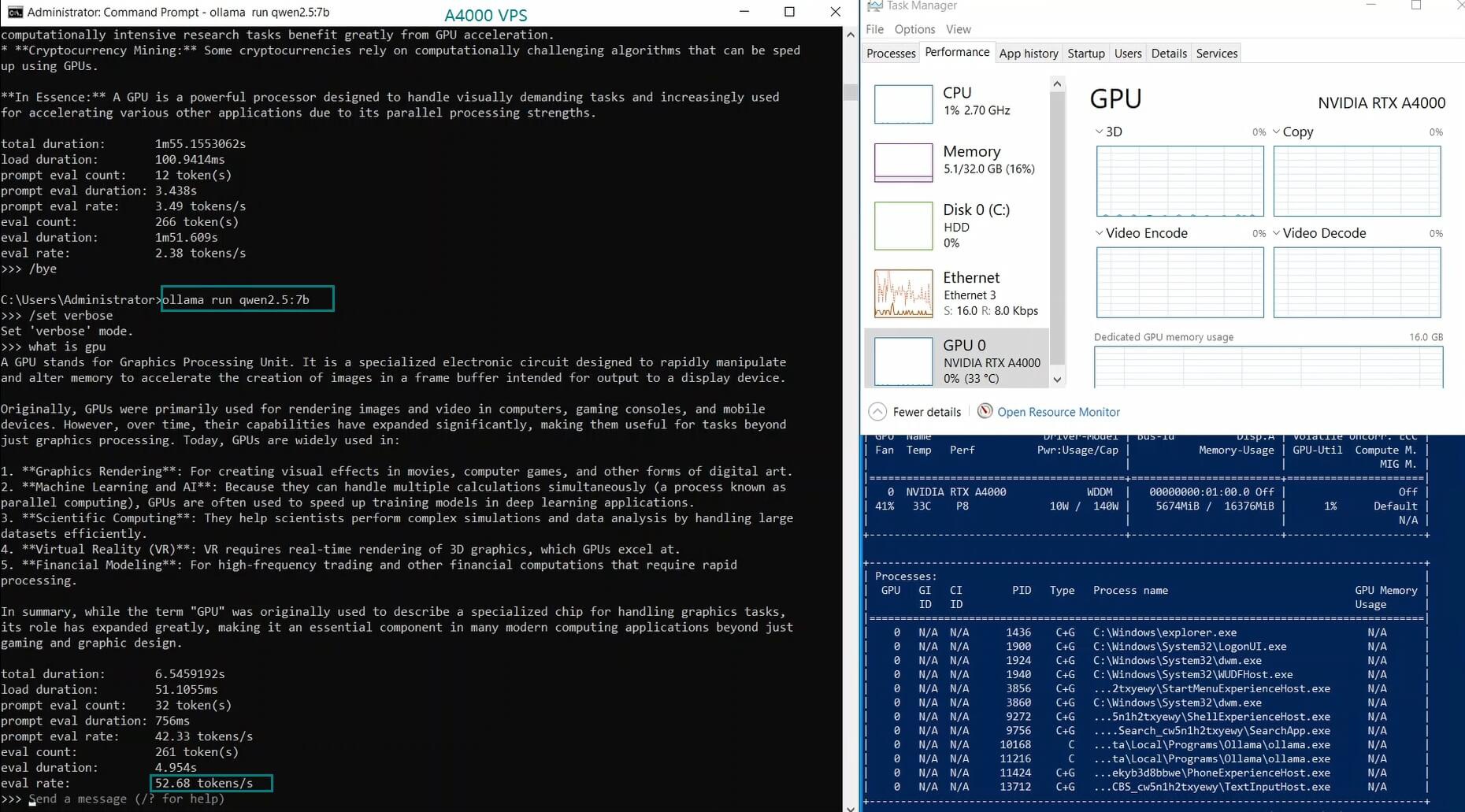
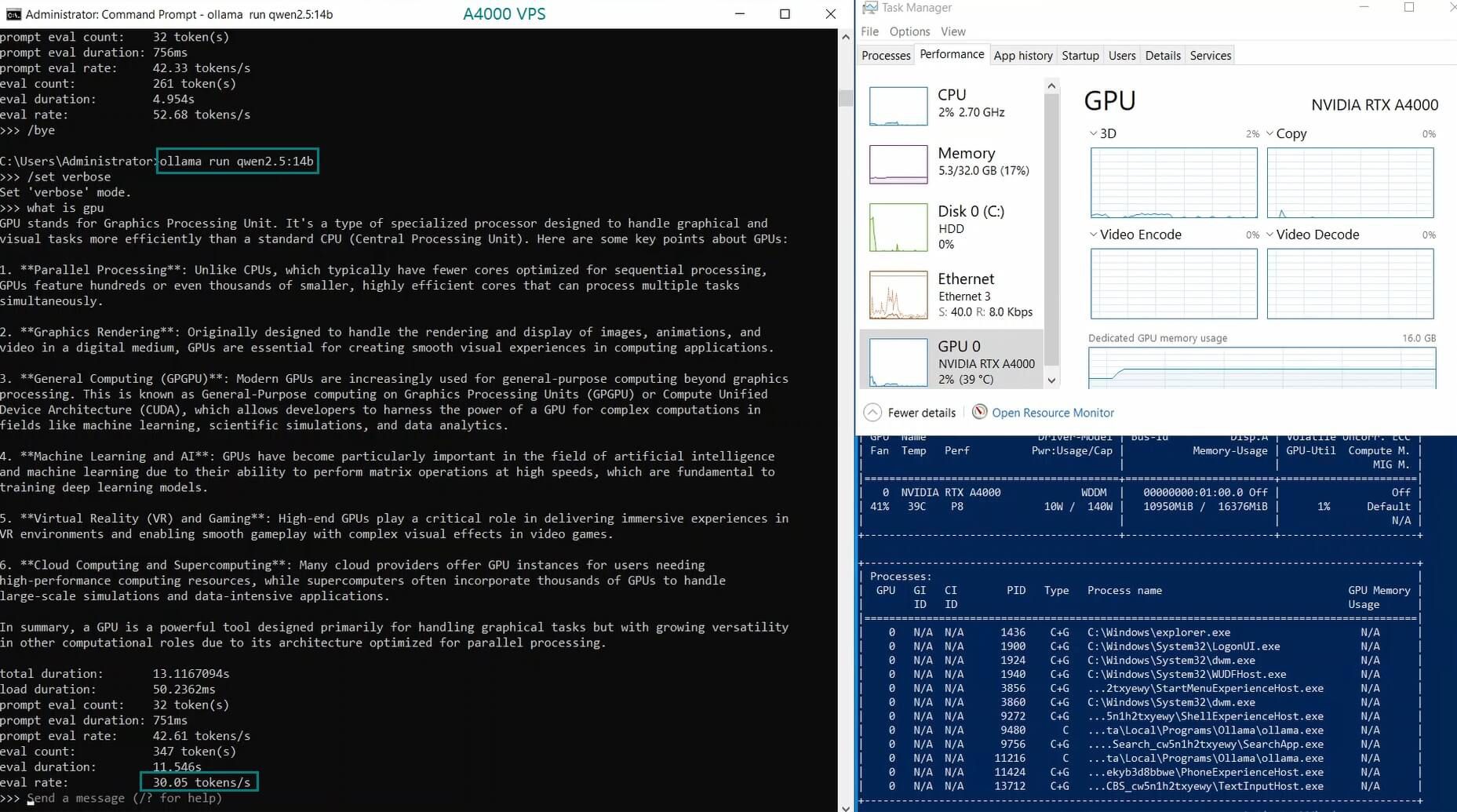
| Eval Rate(tokens/s) | 52.61 | 51.60 | 30.20 | 22.89 | 65.06 | 38.46 | 51.35 | 64.16 | 39.04 | 2.38 | 52.68 | 30.05 |
Key Takeaways from the Benchmark
1. A4000 GPU Can Handle Mid-Sized Models Efficiently
2. Best Models for High-Speed Inference on A4000 VPS
The LLaMA 2 7B and Mistral 7B models performed exceptionally well, achieving evaluation speeds of 65.06 tokens/s and 64.16 tokens/s, respectively. Their balance between GPU utilization and inference speed makes them ideal for real-time applications on an Ollama A4000 VPS.
3. DeepSeek-Coder Is Efficient But Slower
4. 24B+ Large Models Struggle
Is NVIDIA A4000 VPS Good for LLM Inference?
✅ Pros of Using NVIDIA A4000 for Ollama
- Excellent performance for 7B-14B models like LLaMA 2 and Mistral
- Cost-effective Ollama VPS hosting option compared to higher-end GPUs
- Good balance between GPU utilization and token evaluation rate
❌ Limitations of NVIDIA A4000 for Ollama
- Struggles with large models (24B+)
- Performance can drop significantly for complex LLMs like DeepSeek-Coder
Recommended Use Cases for A4000 VPS in AI
- Chatbots & AI Assistants (LLaMA 2 7B, Mistral 7B)
- Code Completion & AI Coding (DeepSeek-Coder 16B)
- AI Research & Experimentation (Qwen 7B, Gemma 9B)
Get Started with A4000 VPS Hosting for LLMs
Professional GPU VPS - A4000
- 28GB RAM
- 24 CPU Cores
- 320GB SSD
- 300Mbps Unmetered Bandwidth
- Once per 2 Weeks Backup
- OS: Windows / Linux
- Dedicated GPU: Quadro RTX A4000
- CUDA Cores: 6,144
- Tensor Cores: 192
- GPU Memory: 16GB GDDR6
- FP32 Performance: 19.2 TFLOPS
Advanced GPU Dedicated Server - V100
- 128GB RAM
- GPU: Nvidia V100
- Dual 12-Core E5-2690v3
- 240GB SSD + 2TB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Volta
- CUDA Cores: 5,120
- Tensor Cores: 640
- GPU Memory: 16GB HBM2
- FP32 Performance: 14 TFLOPS
Enterprise GPU Dedicated Server - RTX 4090
- 256GB RAM
- GPU: GeForce RTX 4090
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ada Lovelace
- CUDA Cores: 16,384
- Tensor Cores: 512
- GPU Memory: 24 GB GDDR6X
- FP32 Performance: 82.6 TFLOPS
Enterprise GPU Dedicated Server - A100
- 256GB RAM
- GPU: Nvidia A100
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 40GB HBM2
- FP32 Performance: 19.5 TFLOPS
Final Thoughts
This benchmark clearly shows that NVIDIA A4000 VPS hosting can be an excellent choice for those running medium-sized AI models on Ollama. If you’re looking for a cost-effective VPS with solid LLM performance, A4000 VPS hosting should be on your radar. However, larger models (24B-32B) may require a more powerful GPU solution.
For more Ollama benchmarks, GPU VPS hosting reviews, and AI performance tests, stay tuned for future updates!
ollama vps, ollama a4000, a4000 vps hosting, benchmark a4000, ollama benchmark, a4000 for llms inference, nvidia a4000 rental, gpu vps for ai, ollama model performance, deep learning vps, ollama deployment on a4000