

Exploring Ollama's Performance on A5000 GPU Servers: A Comprehensive Benchmark
As the AI landscape evolves, the demand for high-performance hardware to deploy and host large language models (LLMs) like DeepSeek-R1, Llama2, and others continues to grow. This article explores Ollama's performance on an NVIDIA Quadro RTX A5000-powered server, analyzing benchmark results and evaluating the suitability of this setup for hosting LLMs.
Server Specifications
Server Configuration:
- CPU: Dual 12-Core E5-2697v2 (24 cores, 48 threads)
- Memory: 128GB RAM
- Storage: 240GB SSD + 2TB SSD
- Operating System: Windows
- Network: 100Mbps~1Gbps bandwidth
- Software: Ollama versions 0.5.7
GPU Details:
- GPU: Nvidia Quadro RTX A5000
- Compute Capability: 8.6
- Microarchitecture: Ampere
- CUDA Cores: 8192
- Tensor Cores: 256
- GPU Memory: 24GB GDDR6
- FP32 Performance: 27.8 TFLOPS
This robust configuration positions the A5000 as a top-tier GPU server for AI applications, balancing performance, memory, and compatibility with modern LLM frameworks.
Benchmark Results for LLMs on A5000
| Models | deepseek-r1 | deepseek-r1 | llama2 | qwen | qwen2.5 | qwen2.5 | gemma2 | mistral-small | qwq | llava |
|---|---|---|---|---|---|---|---|---|---|---|
| Parameters | 14b | 32b | 13b | 32b | 14b | 32b | 27b | 22b | 32b | 34b |
| Size | 7.4GB | 20GB | 8.2GB | 18GB | 9GB | 20GB | 9.1GB | 13GB | 20GB | 19GB |
| Quantization | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Running on | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 |
| Downloading Speed(mb/s) | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 |
| CPU Rate | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 3% |
| RAM Rate | 6% | 6% | 6% | 6% | 6% | 6% | 6% | 5% | 6% | 6% |
| GPU vRAM | 43% | 90% | 60% | 72% | 36% | 90% | 80% | 50% | 80% | 78% |
| GPU UTL | 95% | 97% | 97% | 96% | 94% | 92% | 93% | 97% | 97% | 96% |
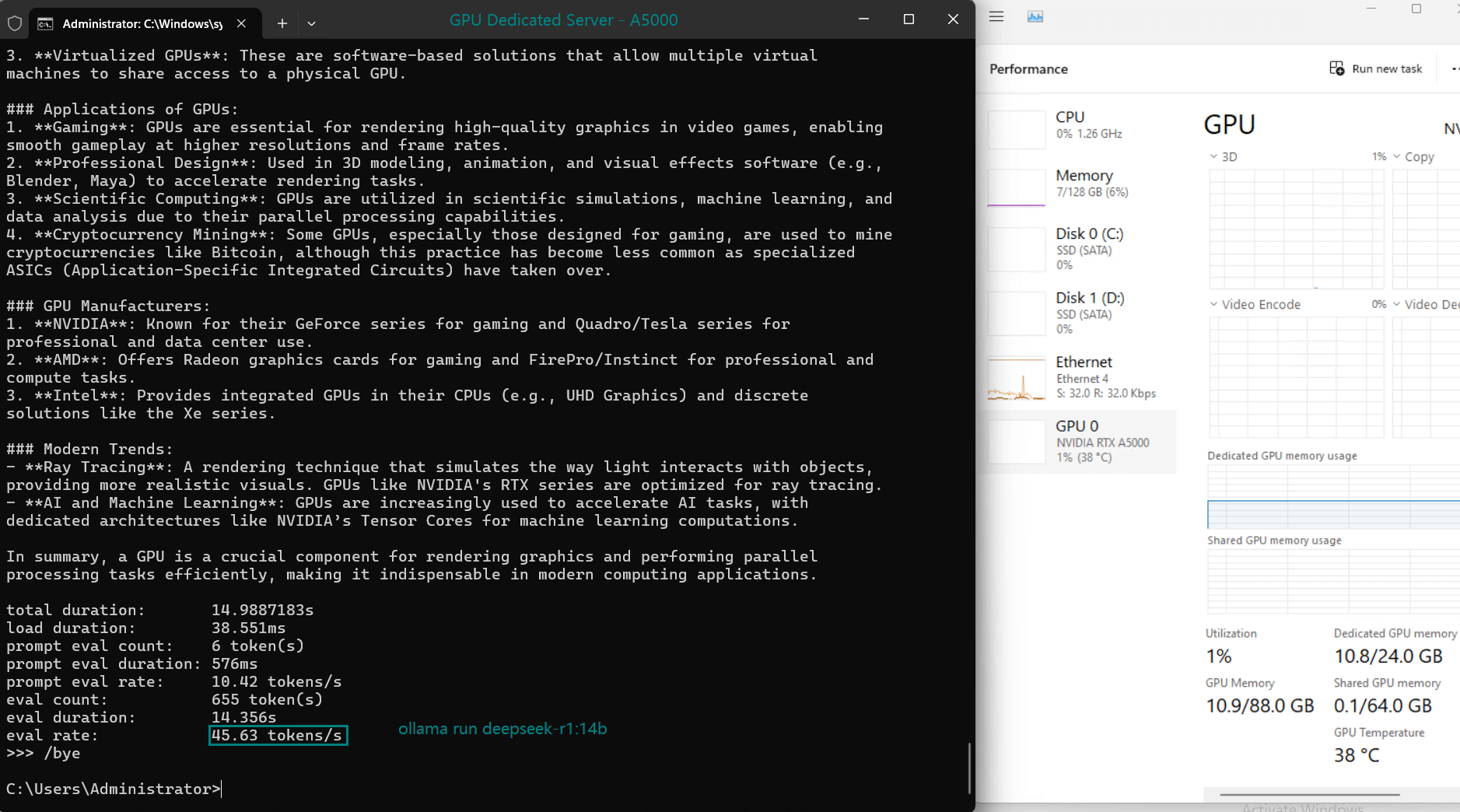
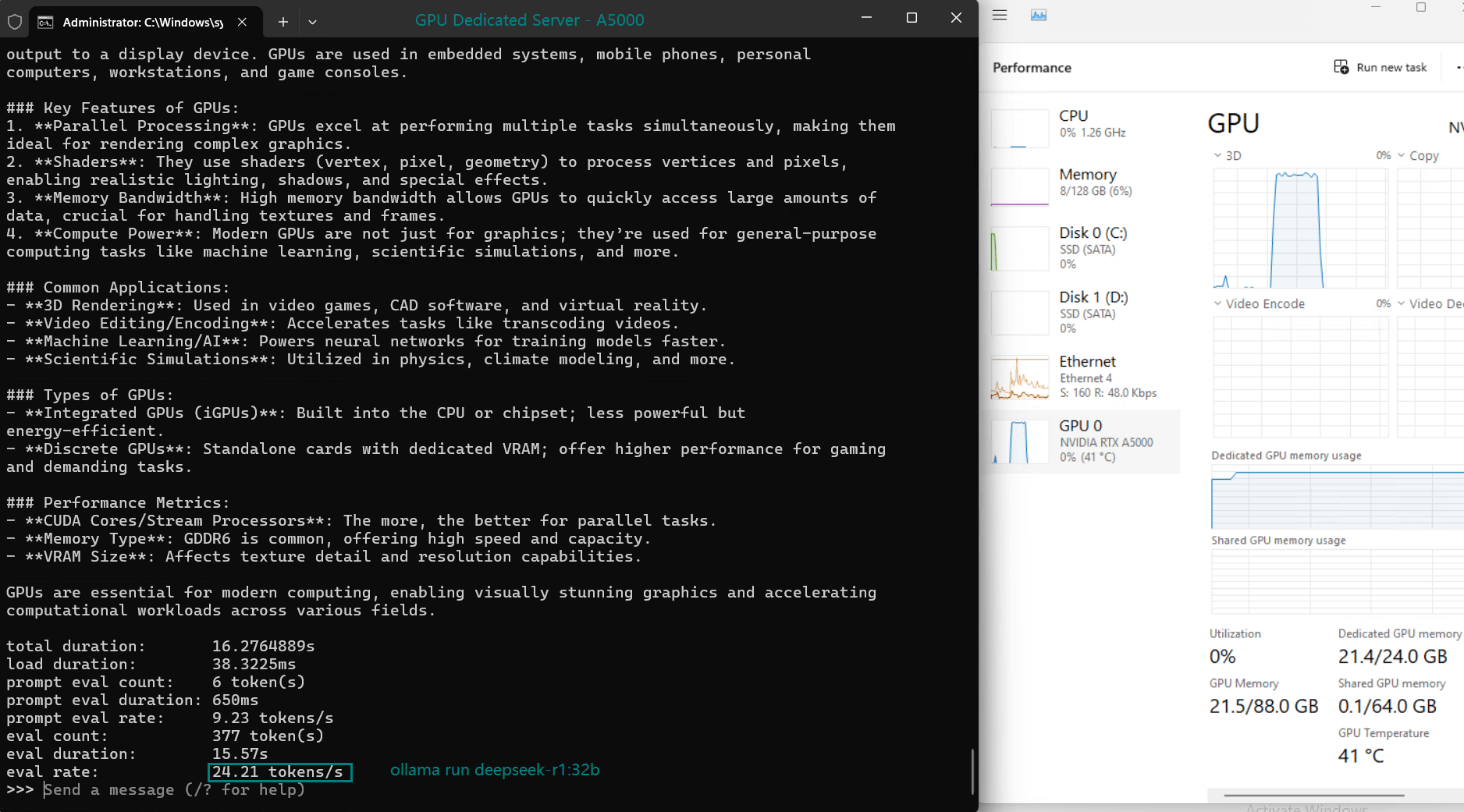
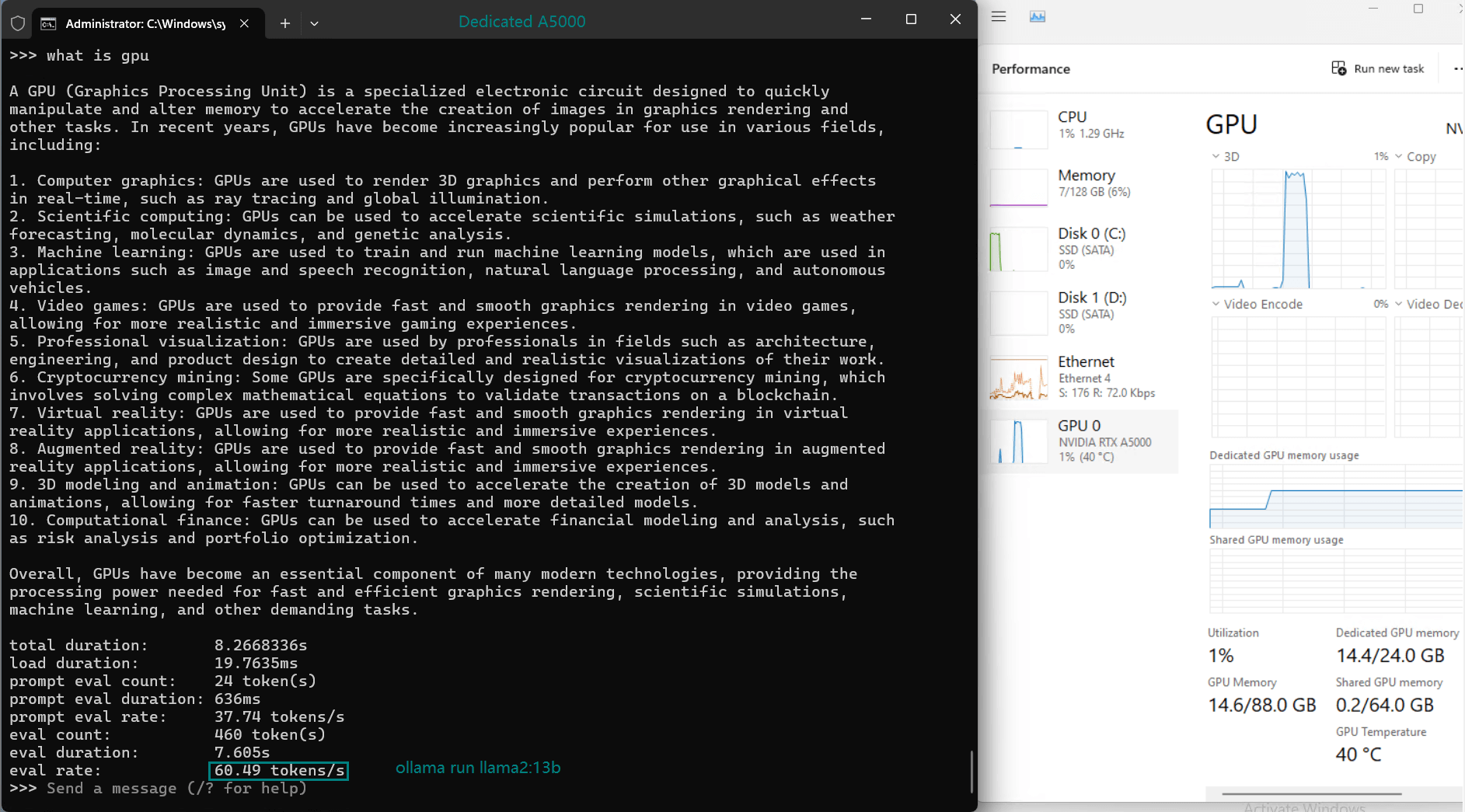
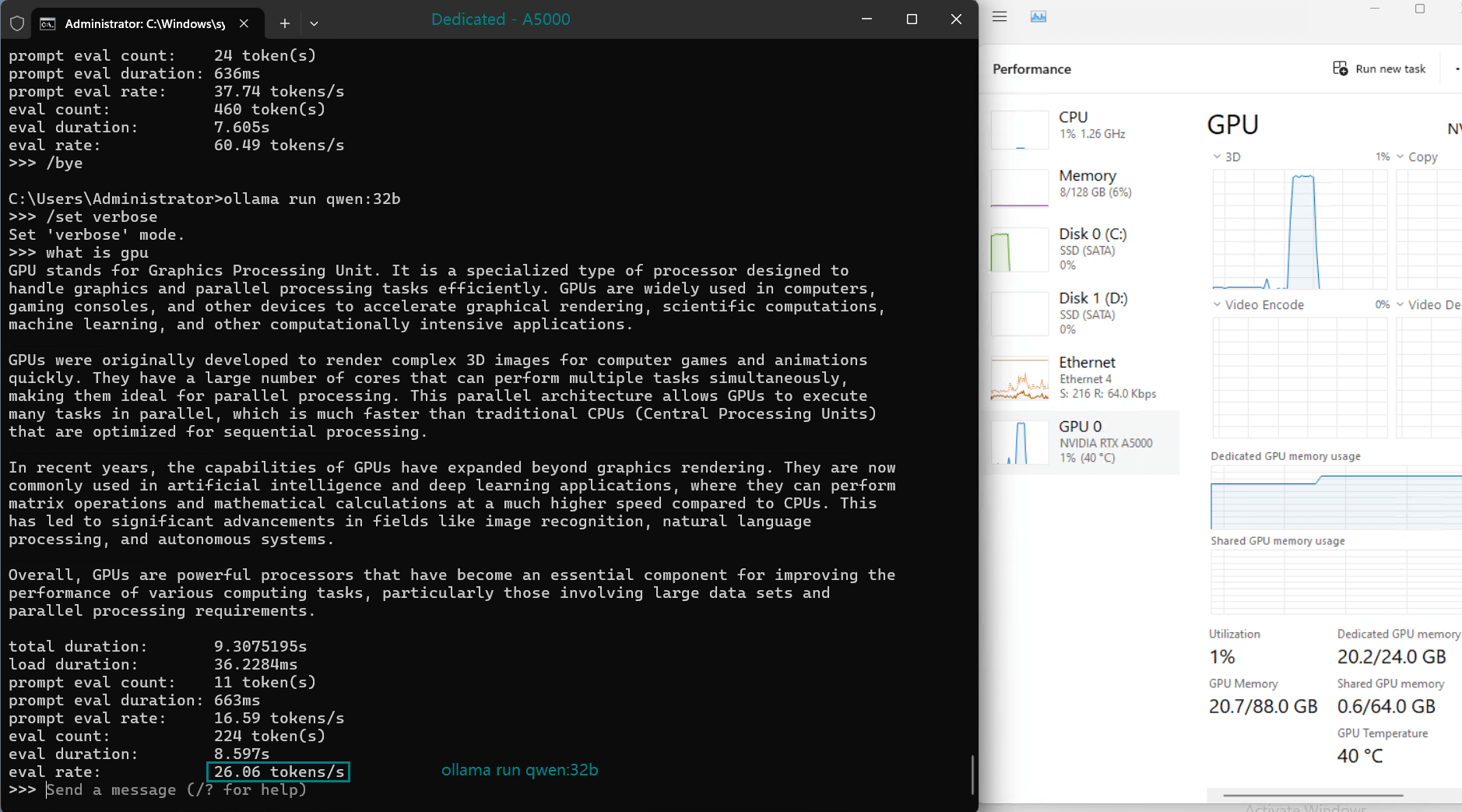
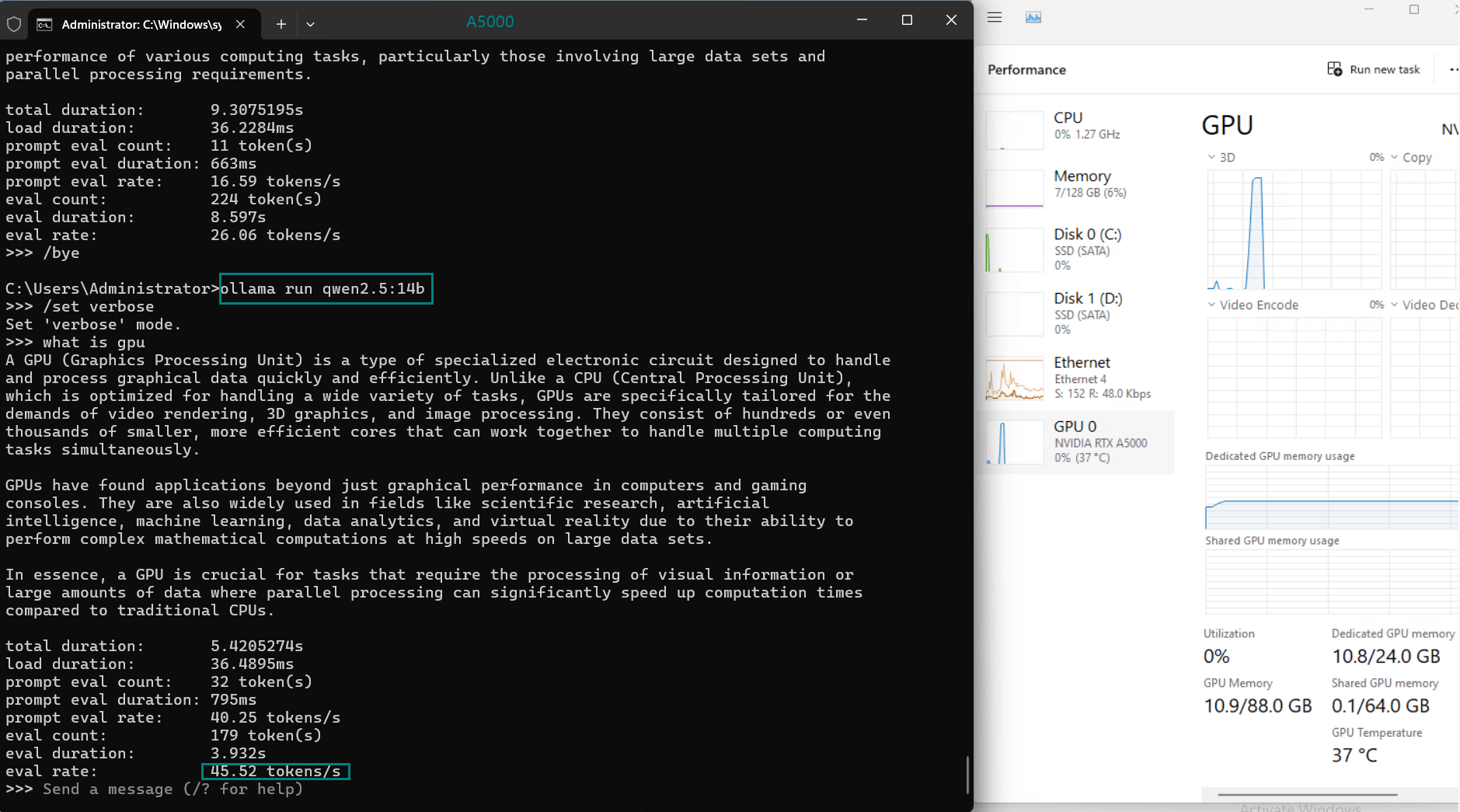
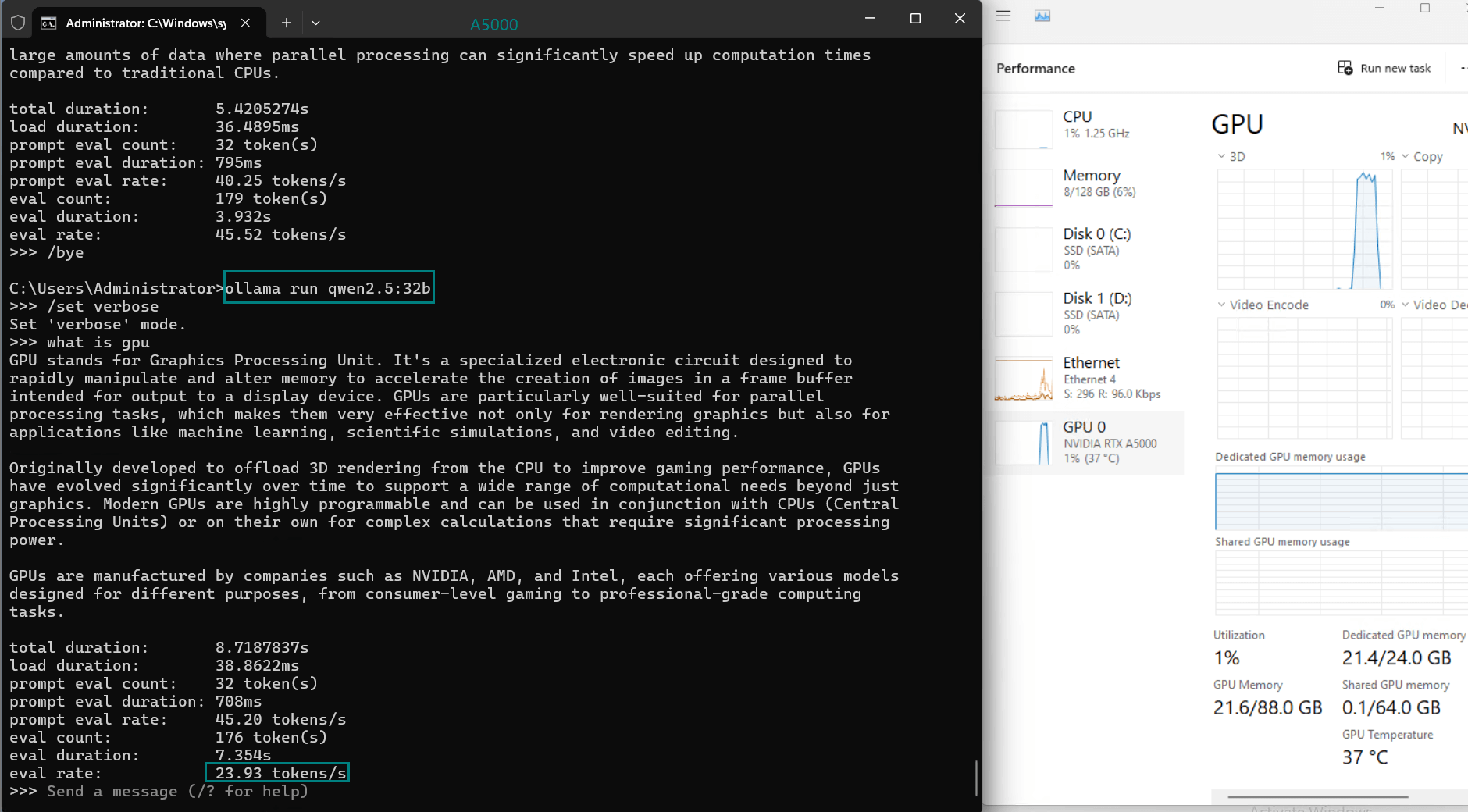
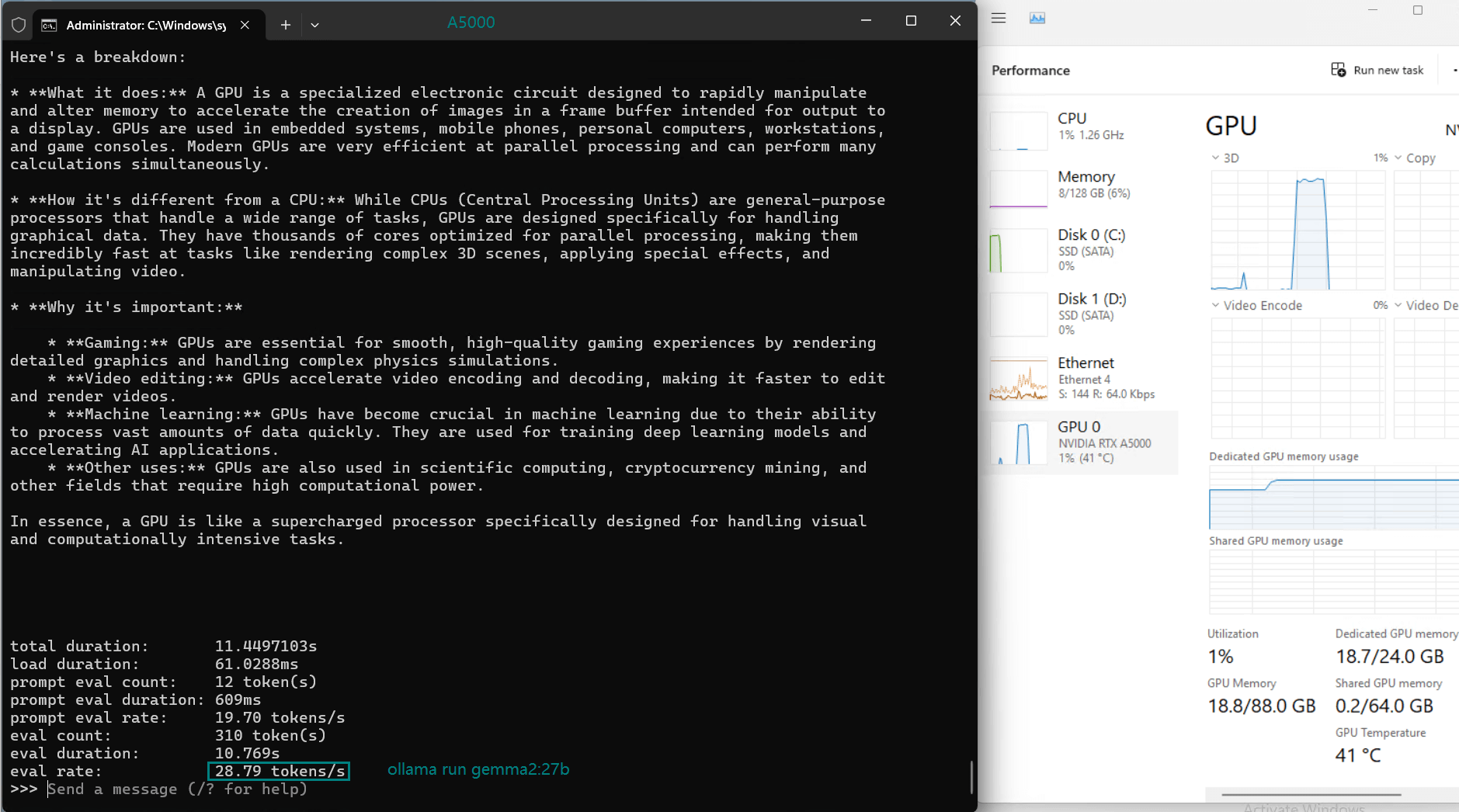
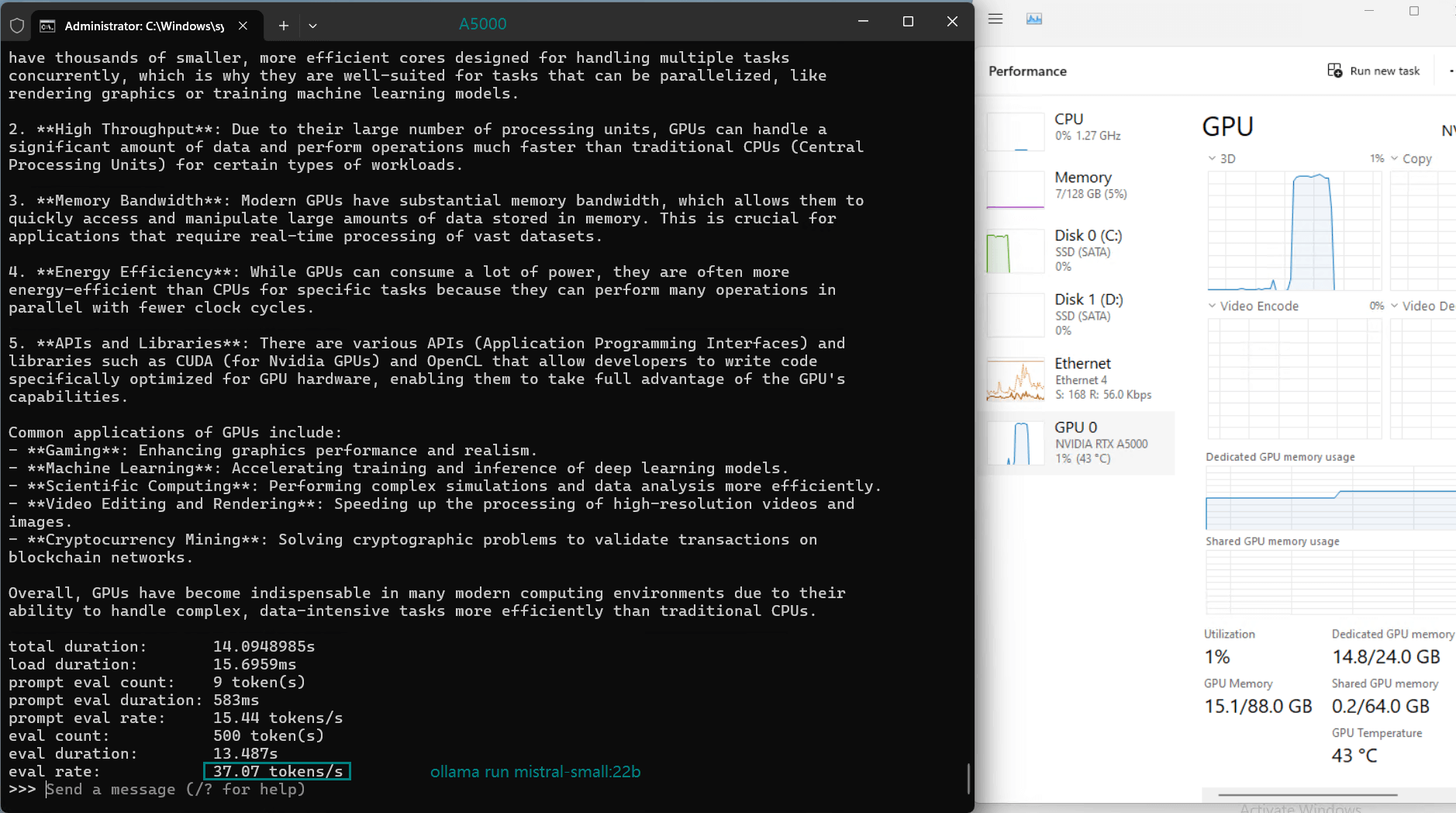
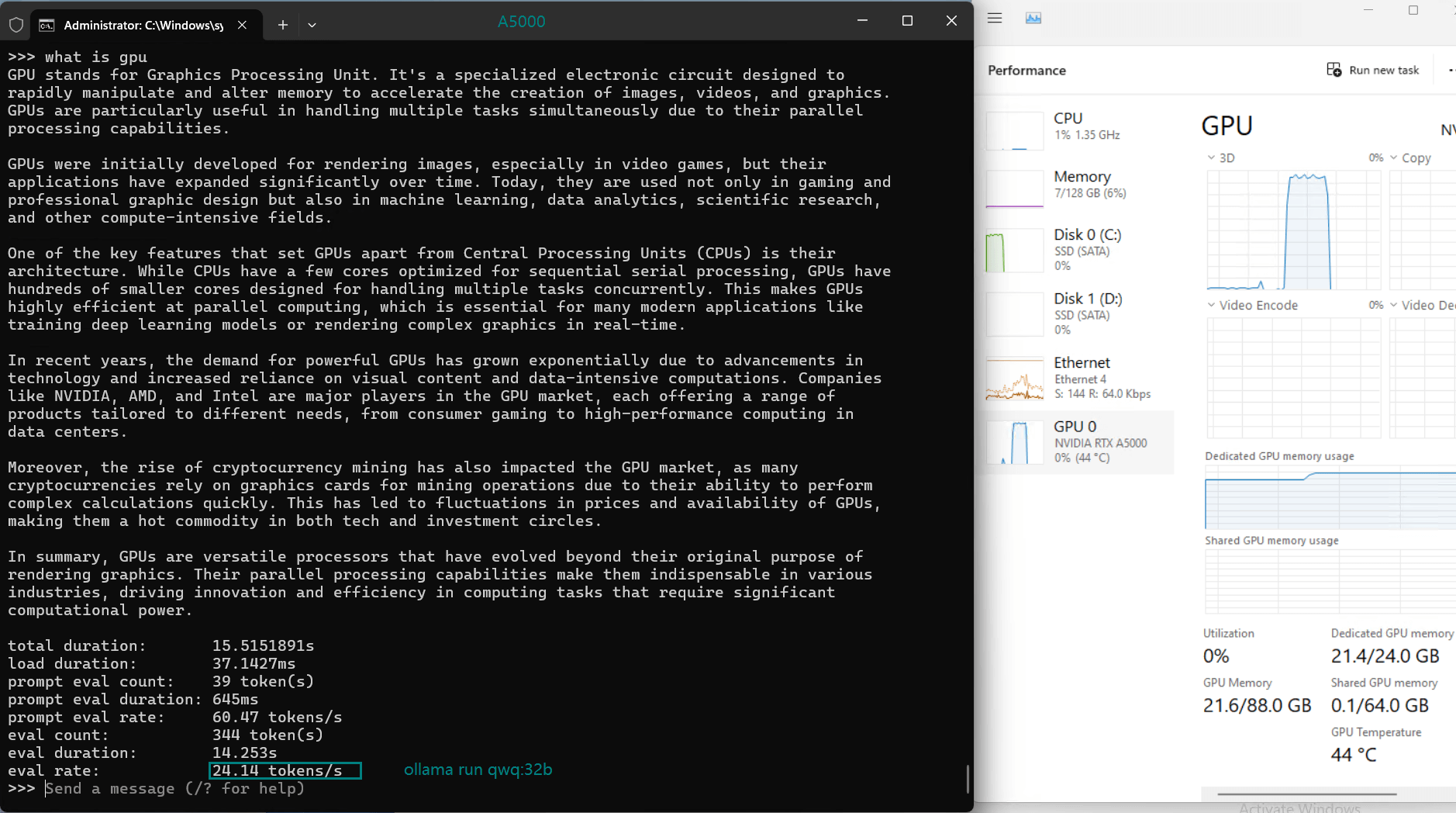
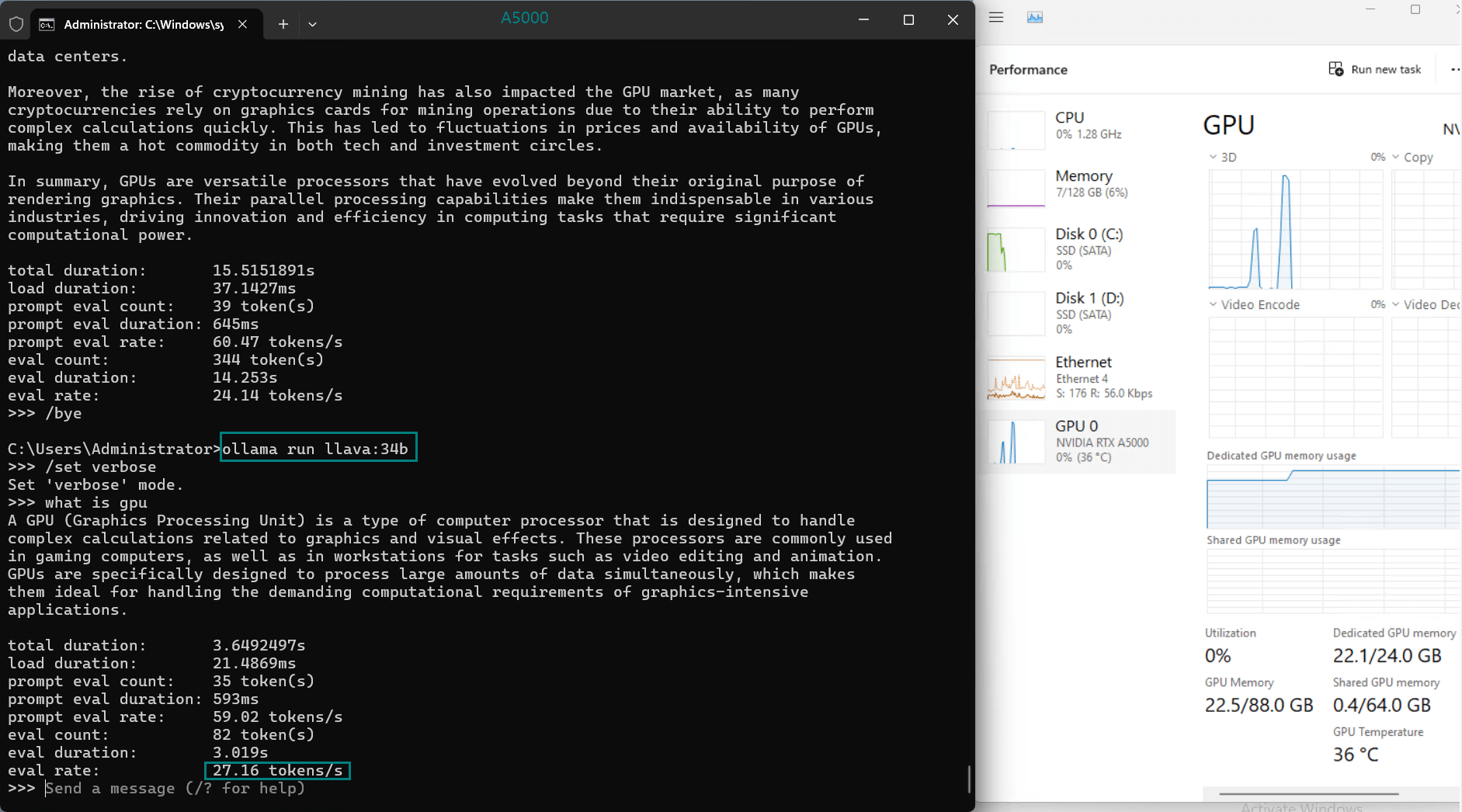
| Eval Rate(tokens/s) | 45.63 | 24.21 | 60.49 | 26.06 | 45.52 | 23.93 | 28.79 | 37.07 | 24.14 | 27.16 |
Performance Analysis
1. Token Evaluation Rate
- Llama2 (13b) leads the pack with an impressive rate of 60.49 tokens/s, thanks to its smaller parameter size and efficient architecture.
- DeepSeek-R1 (14b) performs admirably with 45.63 tokens/s, leveraging its optimized quantization to achieve fast processing speeds.
- Larger models like Gemma2 (27b) and LLaVA (34b) show moderate rates, indicating their suitability for tasks requiring higher accuracy over speed.
2. GPU Utilization and Memory Usage
- The A5000's 24GB GDDR6 memory provides ample room for most models, with DeepSeek-R1 (32b) utilizing 90% VRAM at peak.
- Utilization rates remain consistently high (93%-97%), demonstrating efficient GPU resource usage across all tested models.
3. CPU and RAM Efficiency
- The CPU rate remains low at 3% for all models, highlighting the GPU-centric nature of LLM hosting on this server.
- RAM usage hovers around 6%, ensuring the system's memory remains available for additional workloads.
Advantages of Hosting LLMs on A5000
Optimal Use Cases
- Real-Time Applications: Models like Llama2 and Qwen2.5 deliver high token evaluation rates, making them suitable for chatbots and conversational AI.
- Research and Development: The flexibility to host diverse models like DeepSeek-R1 and Mistral-Small enables experimentation with state-of-the-art architectures.
- Content Generation: Larger models such as Gemma2 and LLaVA are ideal for tasks requiring rich, context-aware outputs.
Get Started with A5000 Dedicated Server
Professional GPU Dedicated Server - P100
- 128GB RAM
- GPU: Nvidia Tesla P100
- Dual 8-Core E5-2660
- 120GB + 960GB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Pascal
- CUDA Cores: 3584
- GPU Memory: 16 GB HBM2
- FP32 Performance: 9.5 TFLOPS
Advanced GPU Dedicated Server - A5000
- 128GB RAM
- GPU: Nvidia Quadro RTX A5000
- Dual 12-Core E5-2697v2
- 240GB SSD + 2TB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 8192
- Tensor Cores: 256
- GPU Memory: 24GB GDDR6
- FP32 Performance: 27.8 TFLOPS
Enterprise GPU Dedicated Server - RTX 4090
- 256GB RAM
- GPU: GeForce RTX 4090
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ada Lovelace
- CUDA Cores: 16,384
- Tensor Cores: 512
- GPU Memory: 24 GB GDDR6X
- FP32 Performance: 82.6 TFLOPS
Enterprise GPU Dedicated Server - A100
- 256GB RAM
- GPU: Nvidia A100
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 40GB HBM2
- FP32 Performance: 19.5 TFLOPS
- 50% Off First Month, 30% Off Renewals
Conclusion
The NVIDIA Quadro RTX A5000, paired with Ollama, is a powerhouse for LLM hosting. Its exceptional GPU performance, efficient resource usage, and flexibility make it a top choice for developers, researchers, and enterprises deploying AI solutions.
Whether you're running DeepSeek-R1, Llama2, or other cutting-edge models, the A5000 delivers the performance you need to unlock their full potential. For AI enthusiasts and professionals alike, this GPU server represents a smart investment in the future of machine learning.
NVIDIA A5000, Ollama benchmark, LLM hosting, DeepSeek-R1, Llama2, AI GPU server, GPU performance test, AI hardware, Language model hosting, AI research tools