

Benchmarking LLMs on Ollama with Nvidia GTX 1660 GPU Server
Introduction to GTX 1660 GPU Hosting: The Nvidia GeForce GTX 1660, a mid-tier gaming GPU, is now being employed for running LLMs (Large Language Models) in server environments. With 6GB of GDDR6 memory, 1408 CUDA cores, and a FP32 performance of 5.0 TFLOPS, this GPU is an affordable option for smaller-scale language model inference tasks. Let's dive into the performance analysis of LLMs running on the GTX 1660 GPU server.
Test Server Configuration
Server Configuration:
- Price: $159/month
- CPU: Dual 10-Core Xeon E5-2660v2
- RAM: 64GB
- Storage: 120GB + 960GB SSD
- Network: 100Mbps Unmetered
- OS: Windows
GPU Details:
- GPU: Nvidia GeForce GTX 1660
- Compute Capability: 7.5
- Microarchitecture: Turing
- CUDA Cores: 1408
- Memory: 6GB GDDR6
- FP32 Performance: 5.0 TFLOPS
This setup makes it a viable option for Nvidia GTX 1660 hosting to run small LLM inference workloads efficiently while keeping costs in check.
Ollama Benchmark: Testing LLMs on GTX 1660 Server
| Models | deepseek-r1 | deepseek-r1 | deepseek-r1 | deepseek-coder | llama3.2 | llama3.1 | codellama | mistral | gemma | codegemma | qwen2.5 | qwen2.5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Parameters | 1.5b | 7b | 8b | 6.7b | 3b | 8b | 7b | 7b | 7b | 7b | 3b | 7b |
| Size(GB) | 1.1 | 4.7 | 4.9 | 3.8 | 2.0 | 4.9 | 3.8 | 4.1 | 5.0 | 5.0 | 1.9 | 4.7 |
| Quantization | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Running on | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 |
| Downloading Speed(mb/s) | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 |
| CPU Rate | 6% | 20% | 28% | 18% | 6% | 30% | 17% | 4% | 45% | 30% | 6% | 18% |
| RAM Rate | 8% | 9% | 10% | 9% | 8% | 10% | 8% | 8% | 12% | 12% | 8% | 9% |
| GPU UTL | 38% | 37% | 37% | 42% | 50% | 35% | 42% | 20% | 30% | 36% | 36% | 37% |
| Eval Rate(tokens/s) | 30.16 | 18.29 | 16.26 | 21.31 | 38.36 | 16.67 | 21.42 | 40.2 | 9.69 | 9.39 | 26.28 | 18.24 |
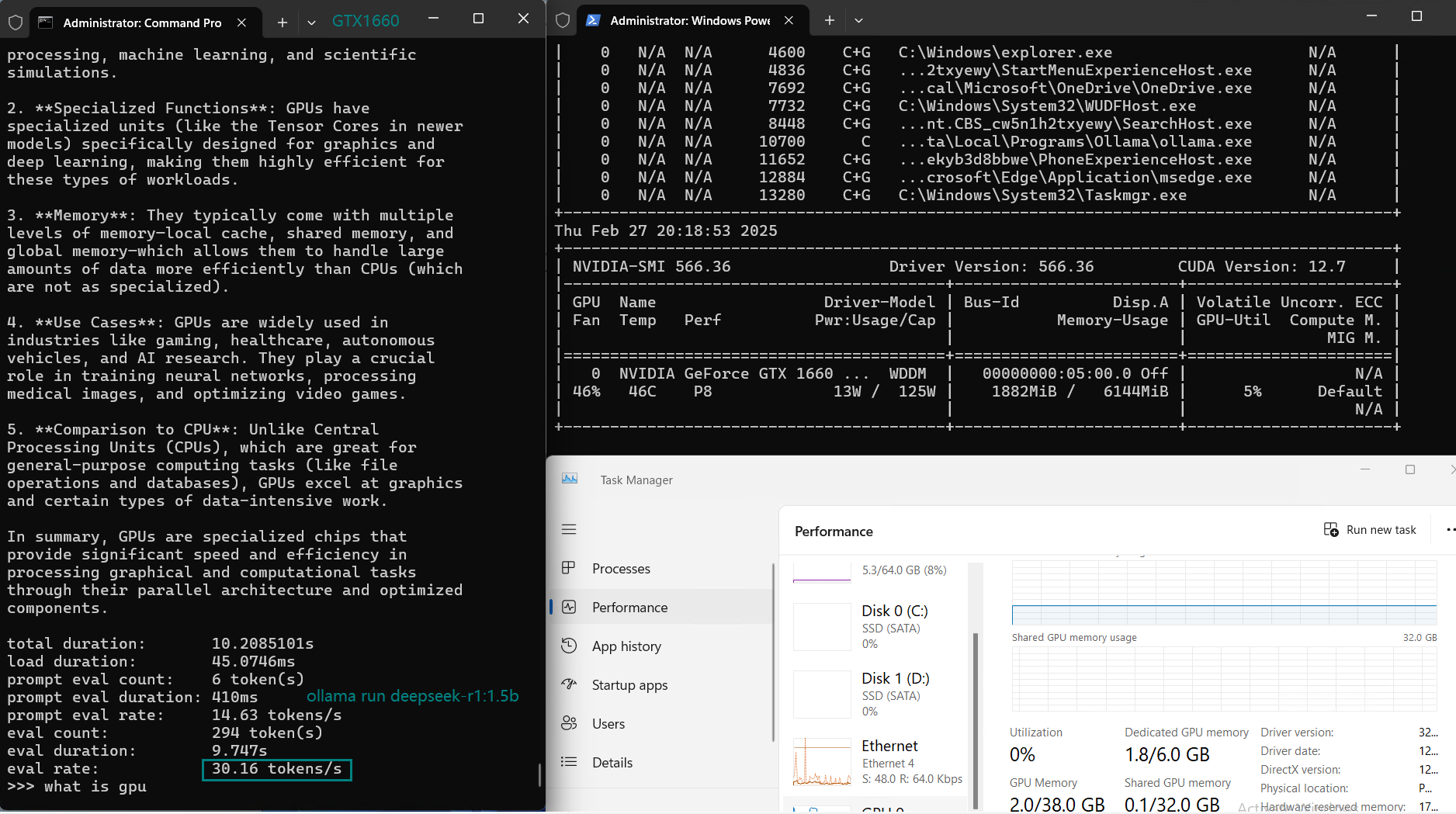
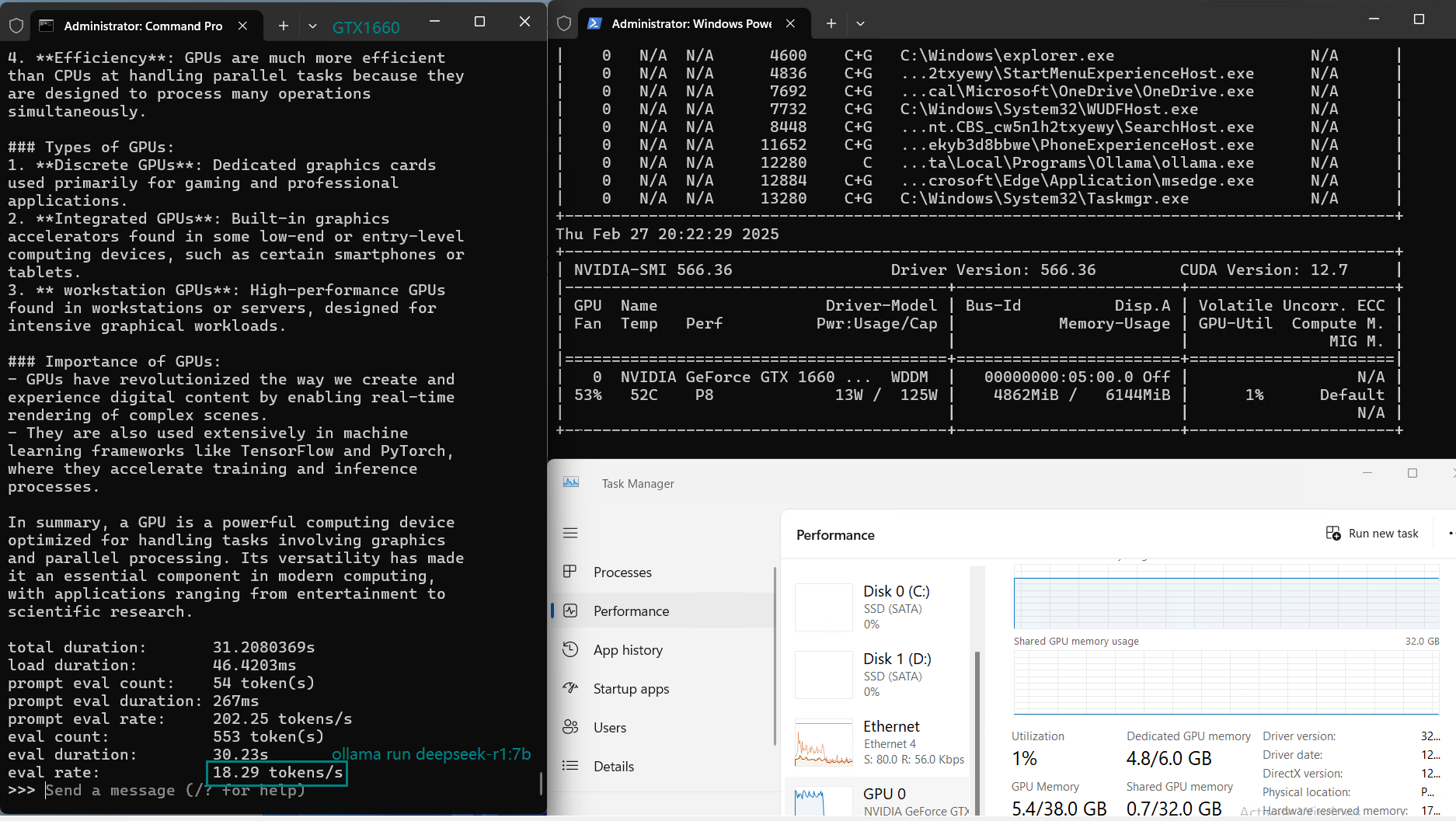
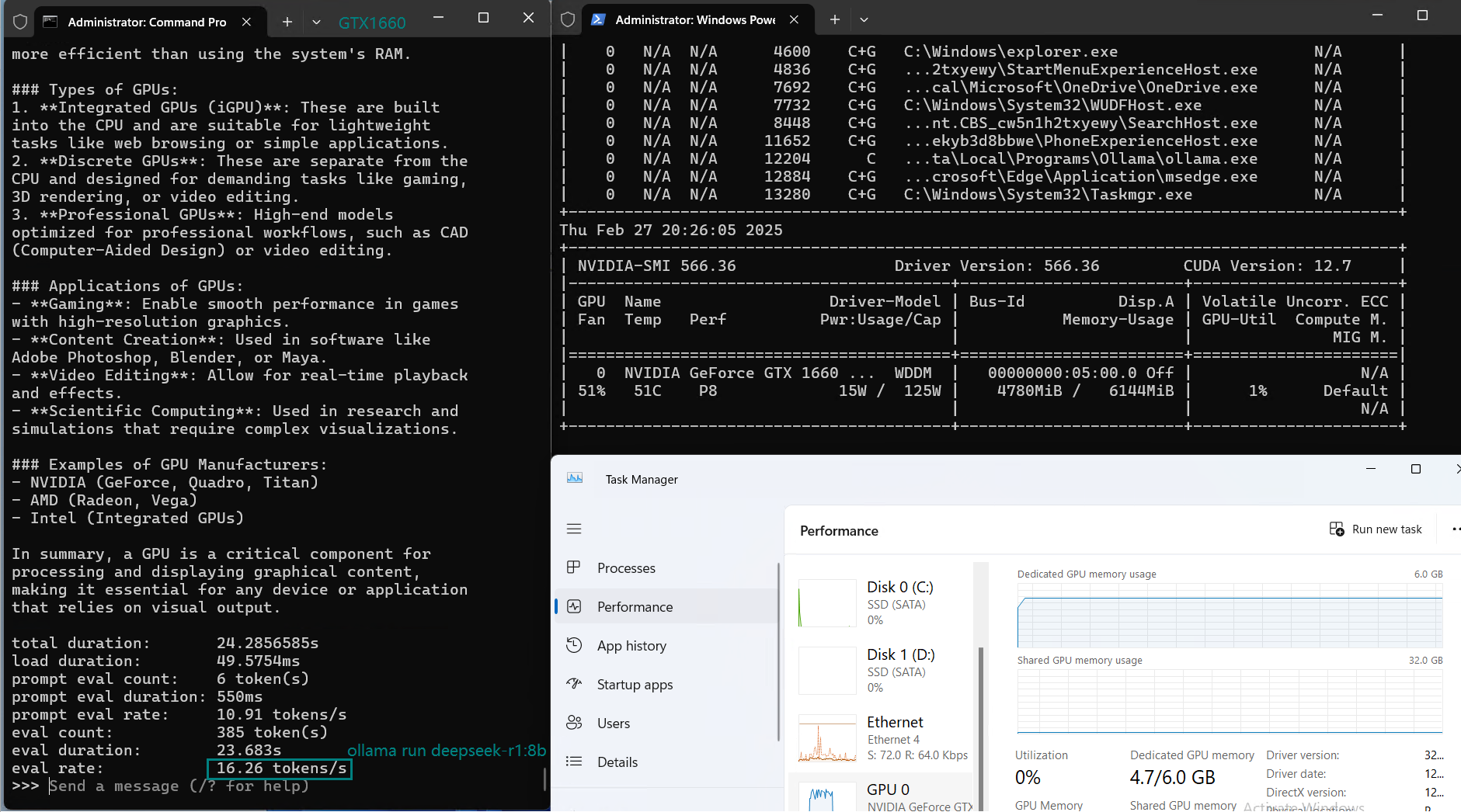
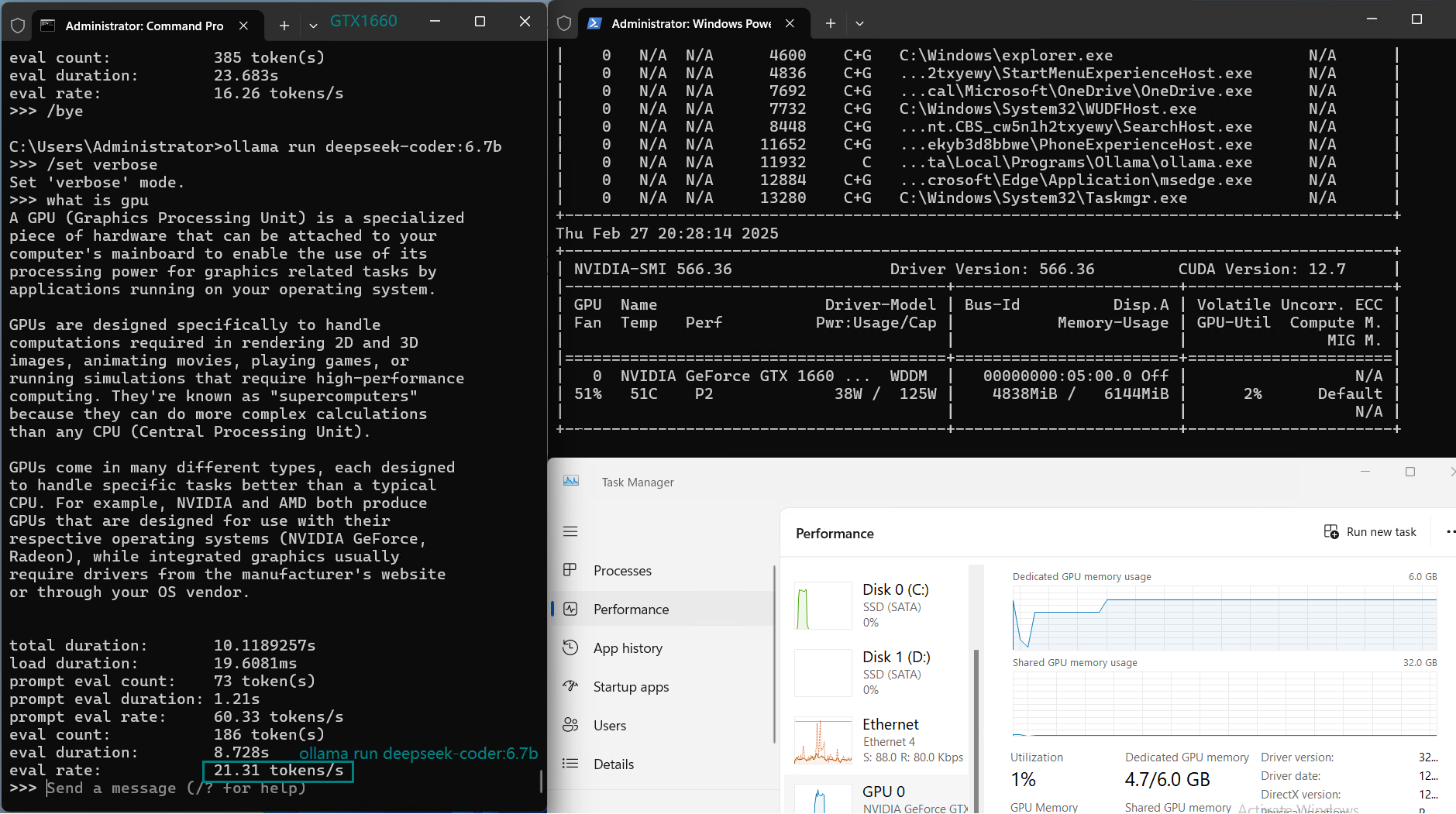
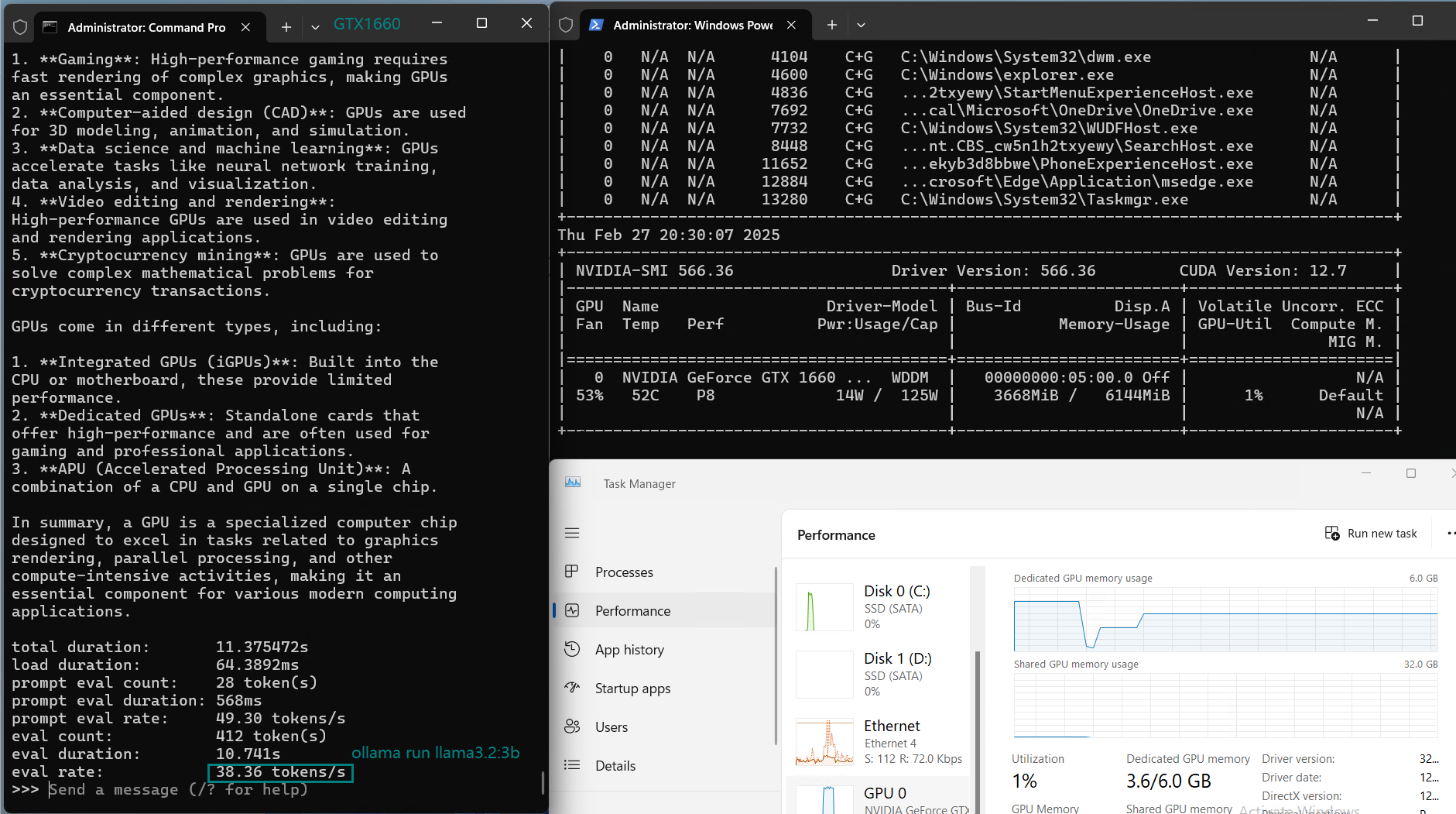
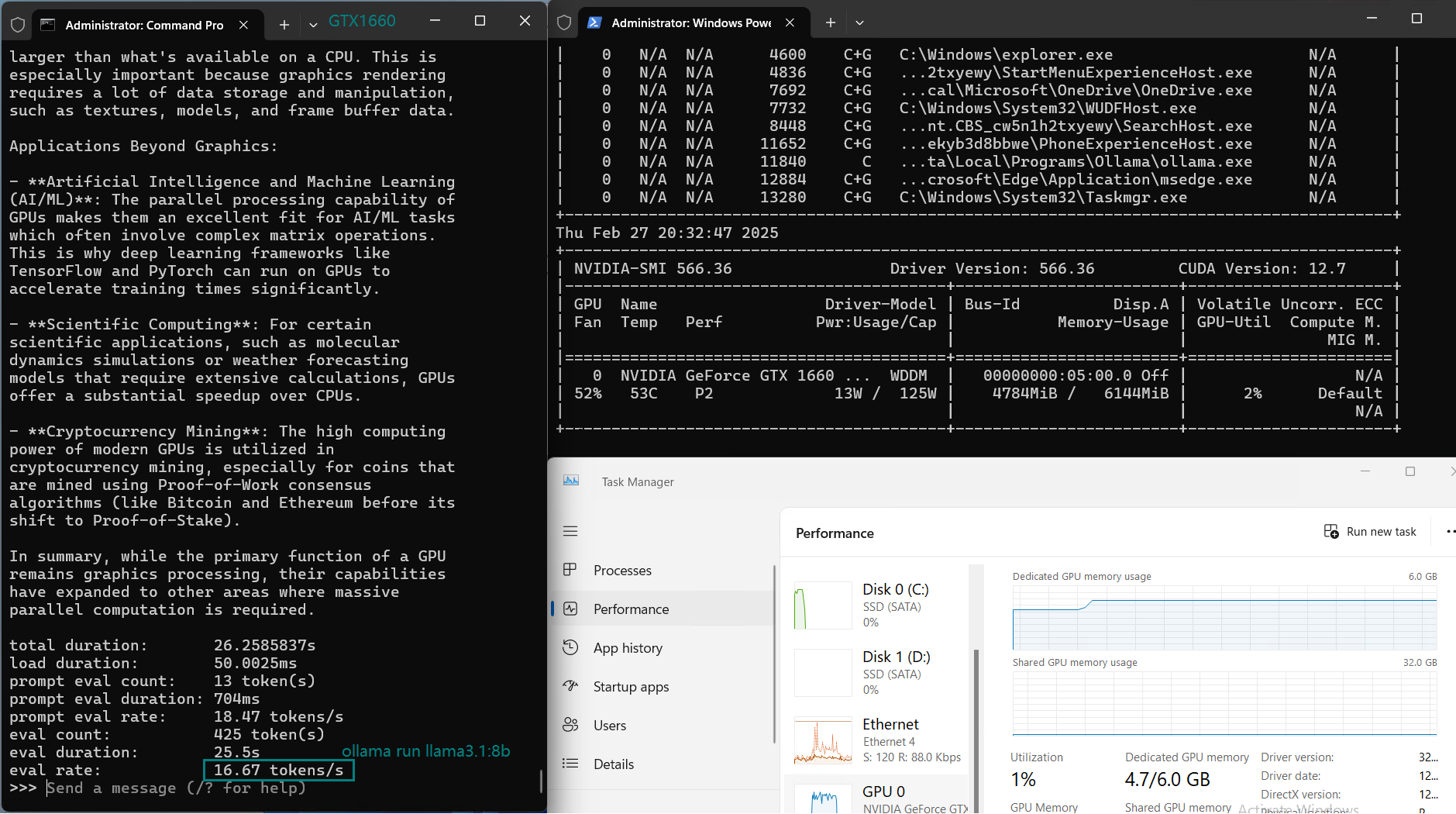

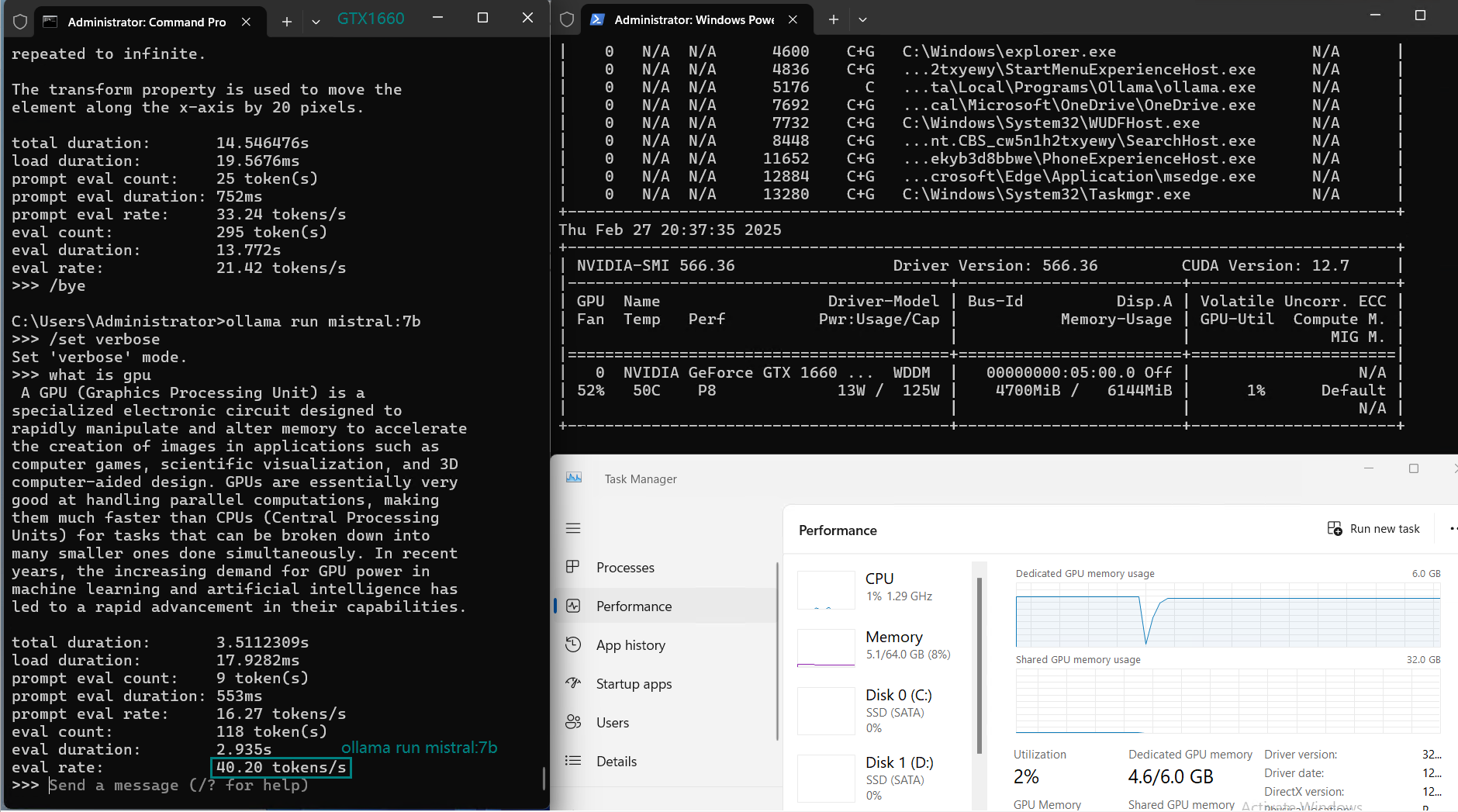
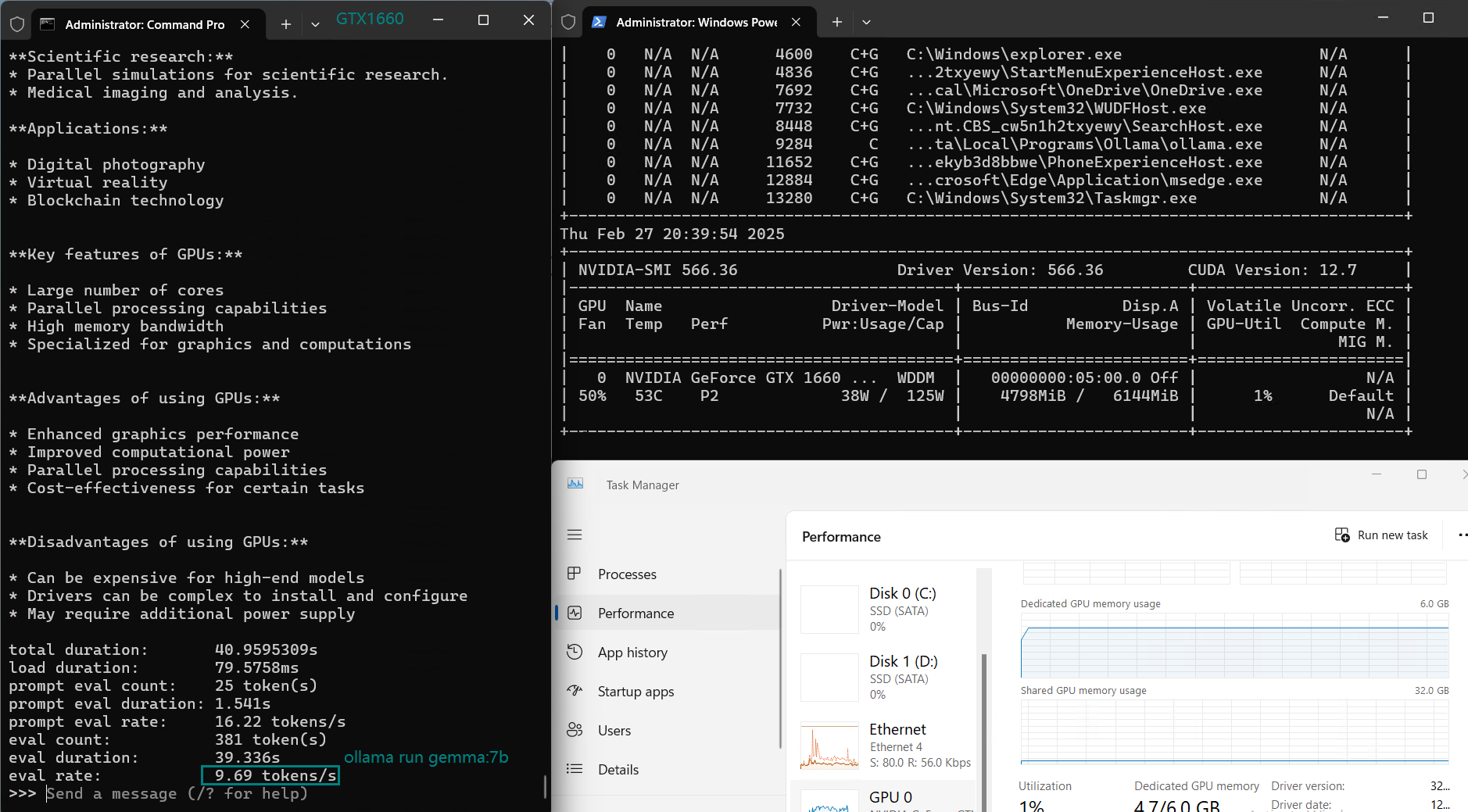
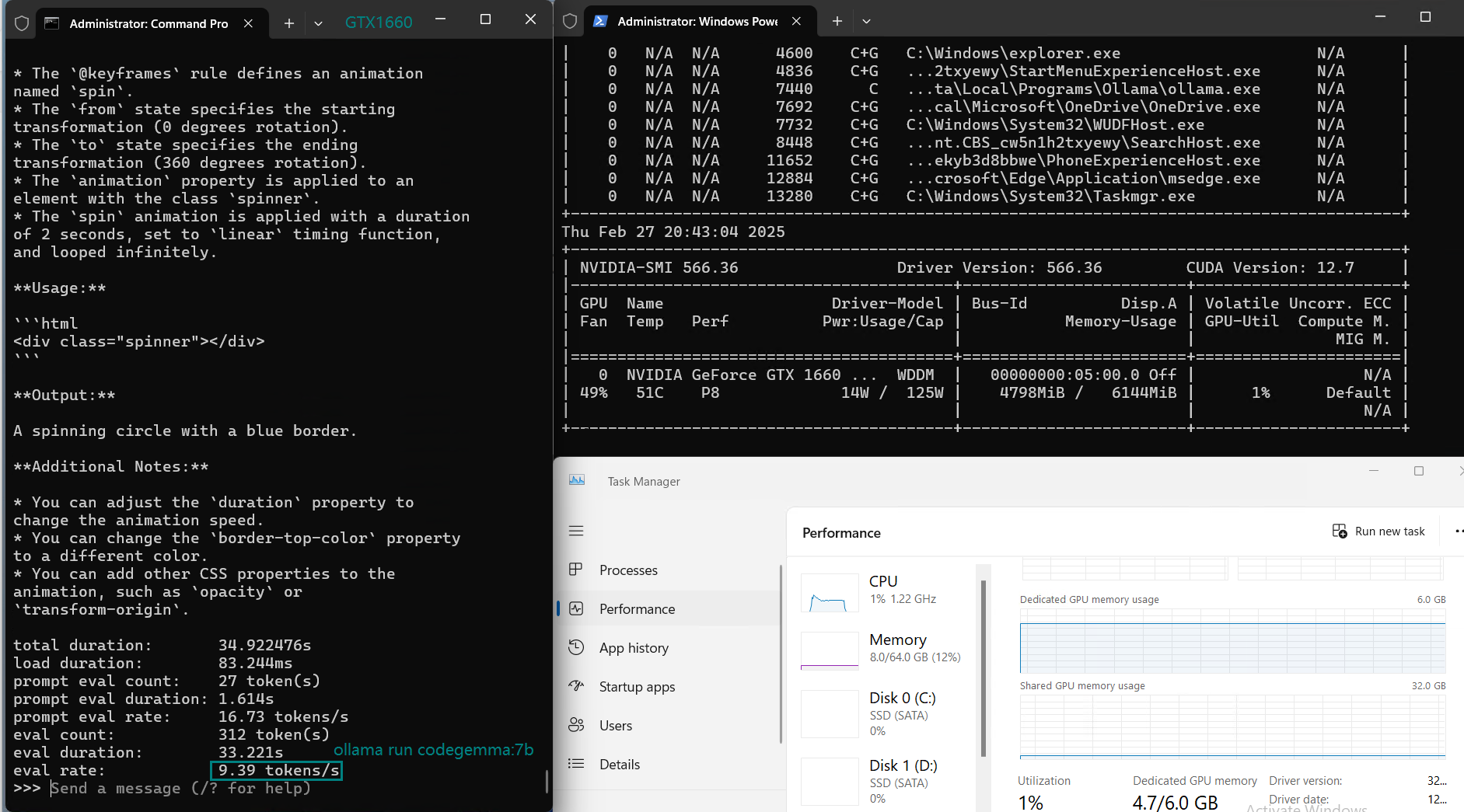
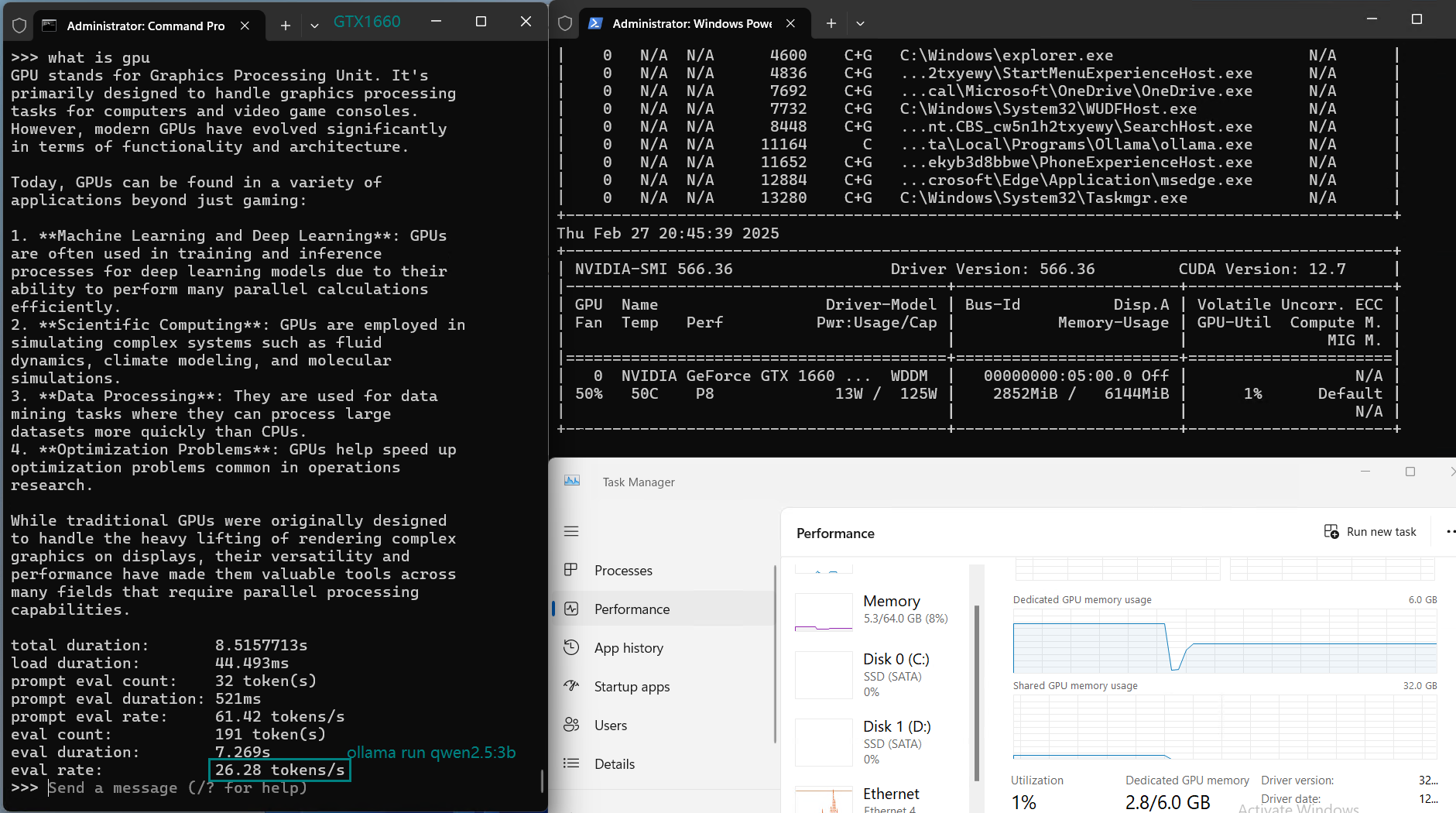
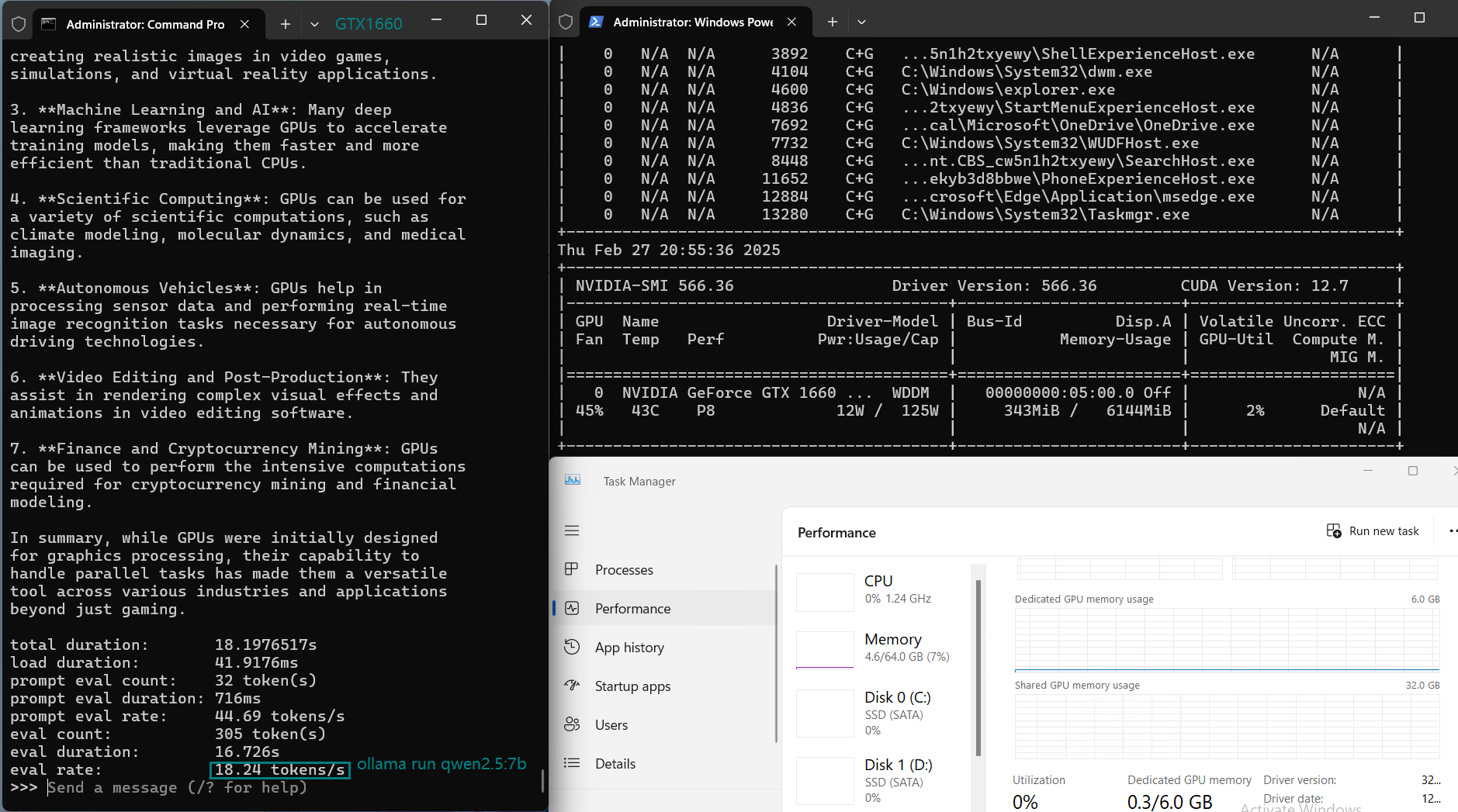
Key Findings from the Benchmark
1️⃣. Best for Small Models (7B and below)
2️⃣. CPU Load Increases with Larger Models
For models above 7B, such as DeepSeek-r1 (8B) and LLama 3.1 (8B), CPU utilization increases, signaling that GPU memory (6GB) becomes a bottleneck, limiting performance.
3️⃣. Suboptimal for 8B+ Models
4️⃣. Performance Drops for Larger 7B+ Models
Get Started with GTX1660 Hosting for Small LLMs
Basic GPU Dedicated Server - GTX 1660
- 64GB RAM
- GPU: Nvidia GeForce GTX 1660
- Dual 8-Core Xeon E5-2660
- 120GB + 960GB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Turing
- CUDA Cores: 1408
- GPU Memory: 6GB GDDR6
- FP32 Performance: 5.0 TFLOPS
Professional GPU Dedicated Server - RTX 2060
- 128GB RAM
- GPU: Nvidia GeForce RTX 2060
- Dual 8-Core E5-2660
- 120GB + 960GB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 1920
- Tensor Cores: 240
- GPU Memory: 6GB GDDR6
- FP32 Performance: 6.5 TFLOPS
Basic GPU Dedicated Server - RTX 4060
- 64GB RAM
- GPU: Nvidia GeForce RTX 4060
- Eight-Core E5-2690
- 120GB SSD + 960GB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ada Lovelace
- CUDA Cores: 3072
- Tensor Cores: 96
- GPU Memory: 8GB GDDR6
- FP32 Performance: 15.11 TFLOPS
Professional GPU VPS - A4000
- 28GB RAM
- 24 CPU Cores
- 320GB SSD
- 300Mbps Unmetered Bandwidth
- Once per 2 Weeks Backup
- OS: Windows / Linux
- Dedicated GPU: Quadro RTX A4000
- CUDA Cores: 6,144
- Tensor Cores: 192
- GPU Memory: 16GB GDDR6
- FP32 Performance: 19.2 TFLOPS
Conclusion
The Nvidia GTX 1660 GPU is a cost-effective solution for running small-scale LLMs (1.5B - 7B) with good inference speeds (30-40 tokens/s) and low-cost hosting options like $159/month. For larger models, such as 8B and above, consider scaling up to GPUs with more VRAM for optimal performance. This GTX 1660 VPS is excellent for developers working with smaller language models, LLMs inference, and budget-conscious projects.
ollama 1660, small llms ollama, ollama GTX1660, Nvidia GTX1660 hosting, benchmark GTX1660, ollama benchmark, GTX1660 for llms inference, nvidia GTX1660 rental, GTX 1660 LLM hosting, Nvidia 1660 performance