

Running LLMs on Ollama: Performance Benchmark on Nvidia H100 GPU Server
With the rise of large language models (LLMs) and AI applications, the need for high-performance GPU hosting has never been greater. The Nvidia H100 GPU, powered by the Hopper architecture, is one of the most powerful GPUs for AI and deep learning workloads. This article benchmarks Ollama's performance on an H100 GPU server, analyzing its ability to handle LLMs efficiently.
Server Specifications
Server Configuration:
- Price: $2599.0/month
- CPU: Dual 18-Core Intel Xeon E5-2697v4
- RAM: 192GB
- Storage: 240GB SSD + 2TB NVMe + 8TB SATA
- Network: 1Gbps
- OS: Windows Server 2022
GPU Details:
- GPU: Nvidia H100
- Microarchitecture: Hopper
- Compute Capability:9.0
- CUDA Cores: 14,592
- Tensor Cores: 456
- Memory: 80GB HBM2e
- FP32 Performance: 183 TFLOPS
This configuration makes it an ideal H100 hosting solution for deep learning, LLM inference, and AI model training.
Benchmarking Ollama on H100 GPU
| Models | deepseek-r1 | deepseek-r1 | deepseek-r1 | qwen | qwen | qwen | qwen2 | llama3 | llama3.1 | llama3.3 | zephyr | mixtral |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Parameters | 14b | 32b | 70b | 32b | 72b | 110b | 72b | 70b | 70b | 70b | 141b | 8x22b |
| Size | 9GB | 20GB | 43GB | 18GB | 41GB | 63GB | 41GB | 40GB | 43GB | 43GB | 80GB | 80GB |
| Quantization | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Running on | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 | Ollama0.5.7 |
| Downloading Speed(mb/s) | 113 | 113 | 113 | 113 | 113 | 113 | 113 | 113 | 113 | 113 | 113 | 113 |
| CPU Rate | 5% | 4% | 4% | 4% | 3% | 3% | 4% | 3% | 4% | 3% | 2% | 3% |
| RAM Rate | 4% | 3% | 4% | 4% | 4% | 3% | 3% | 3% | 3% | 3% | 4% | 4% |
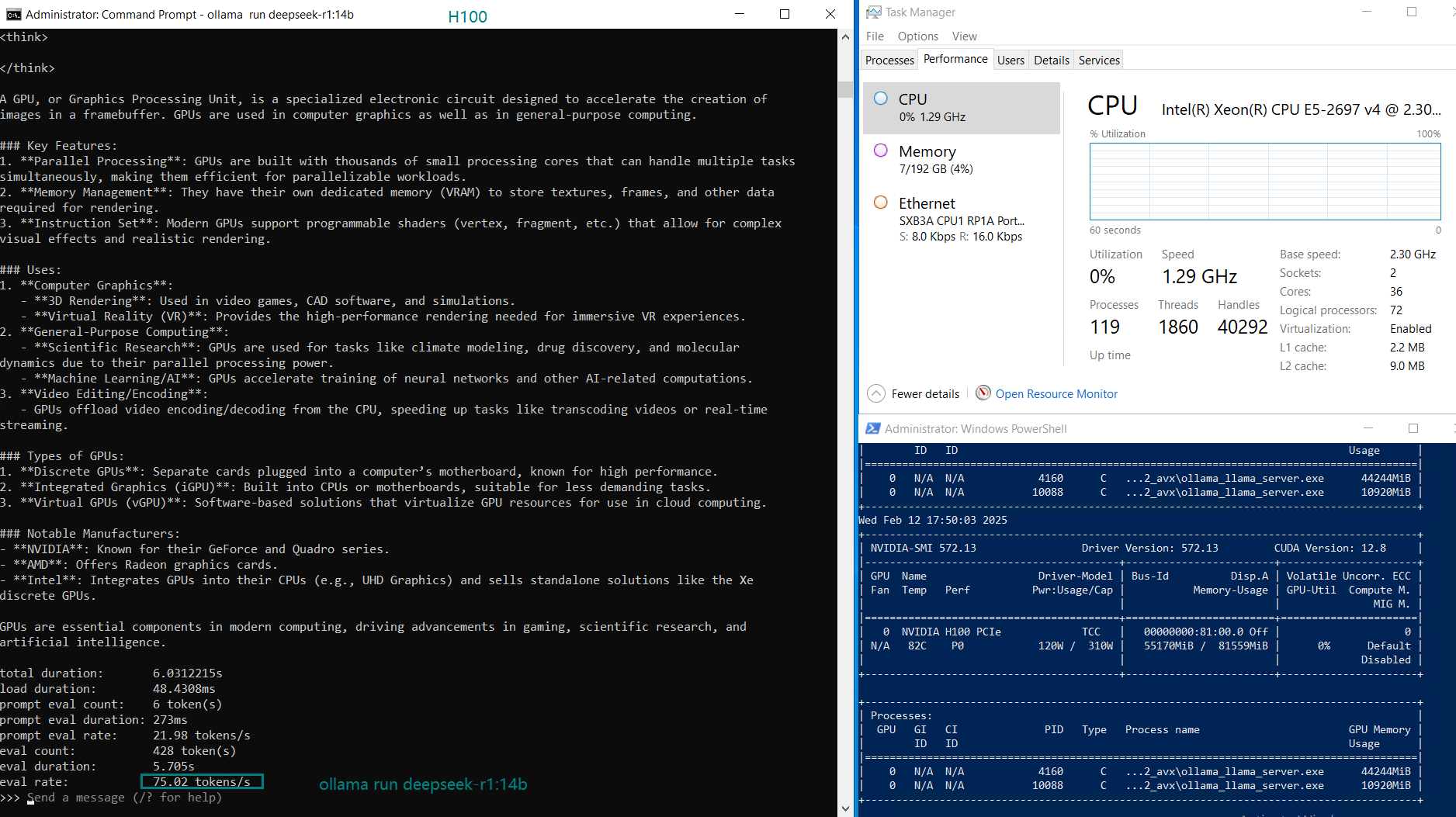
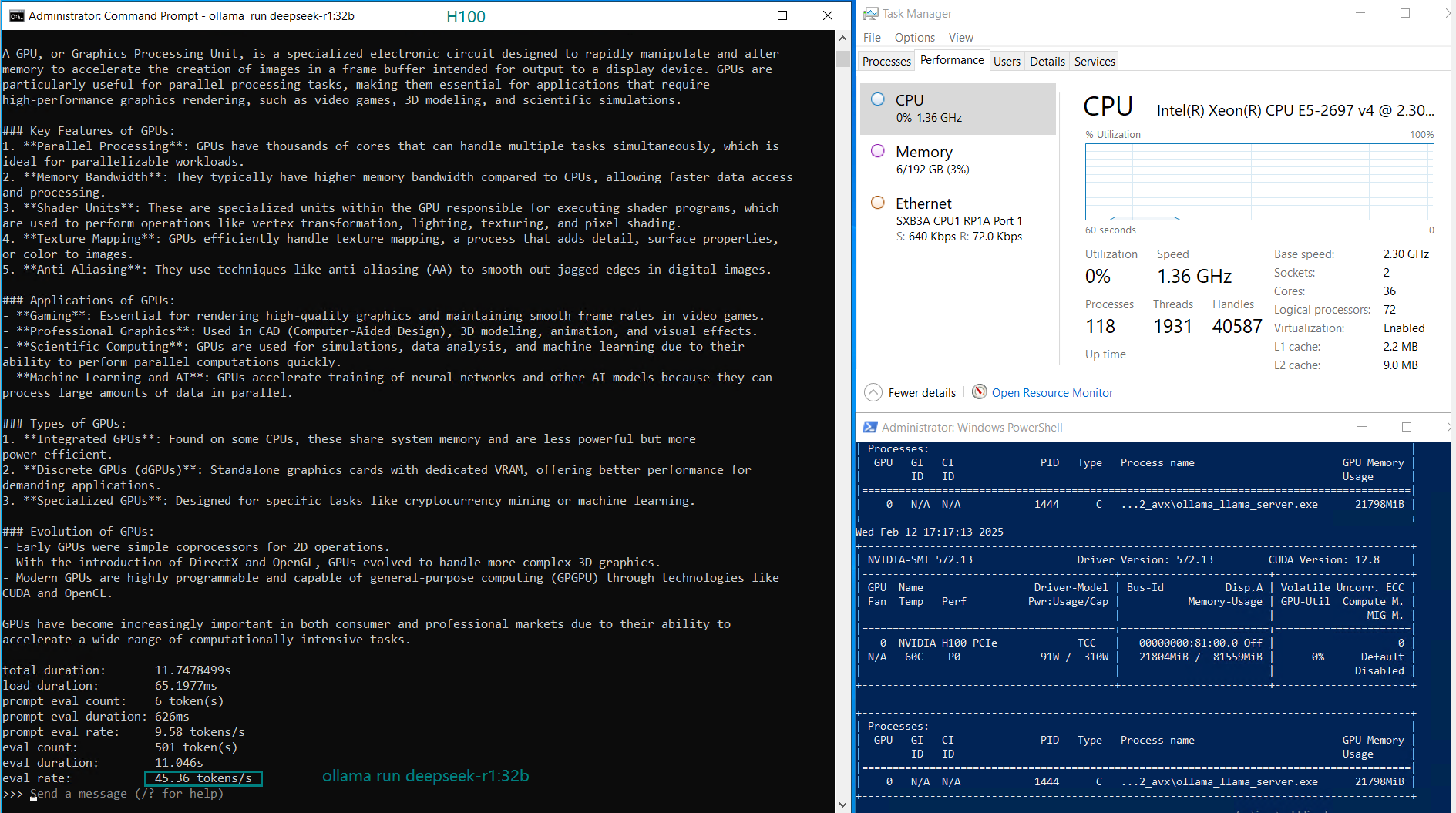
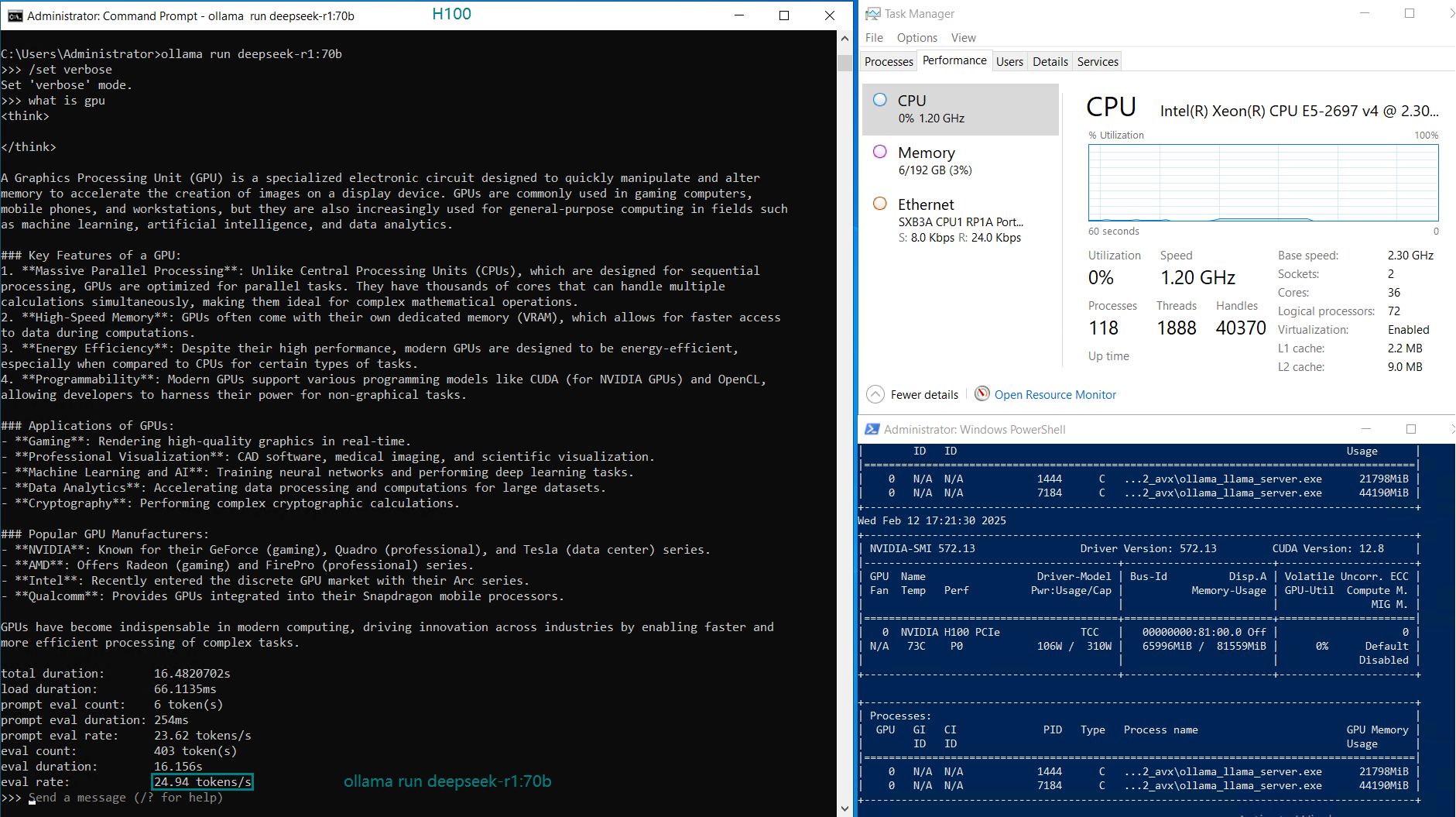
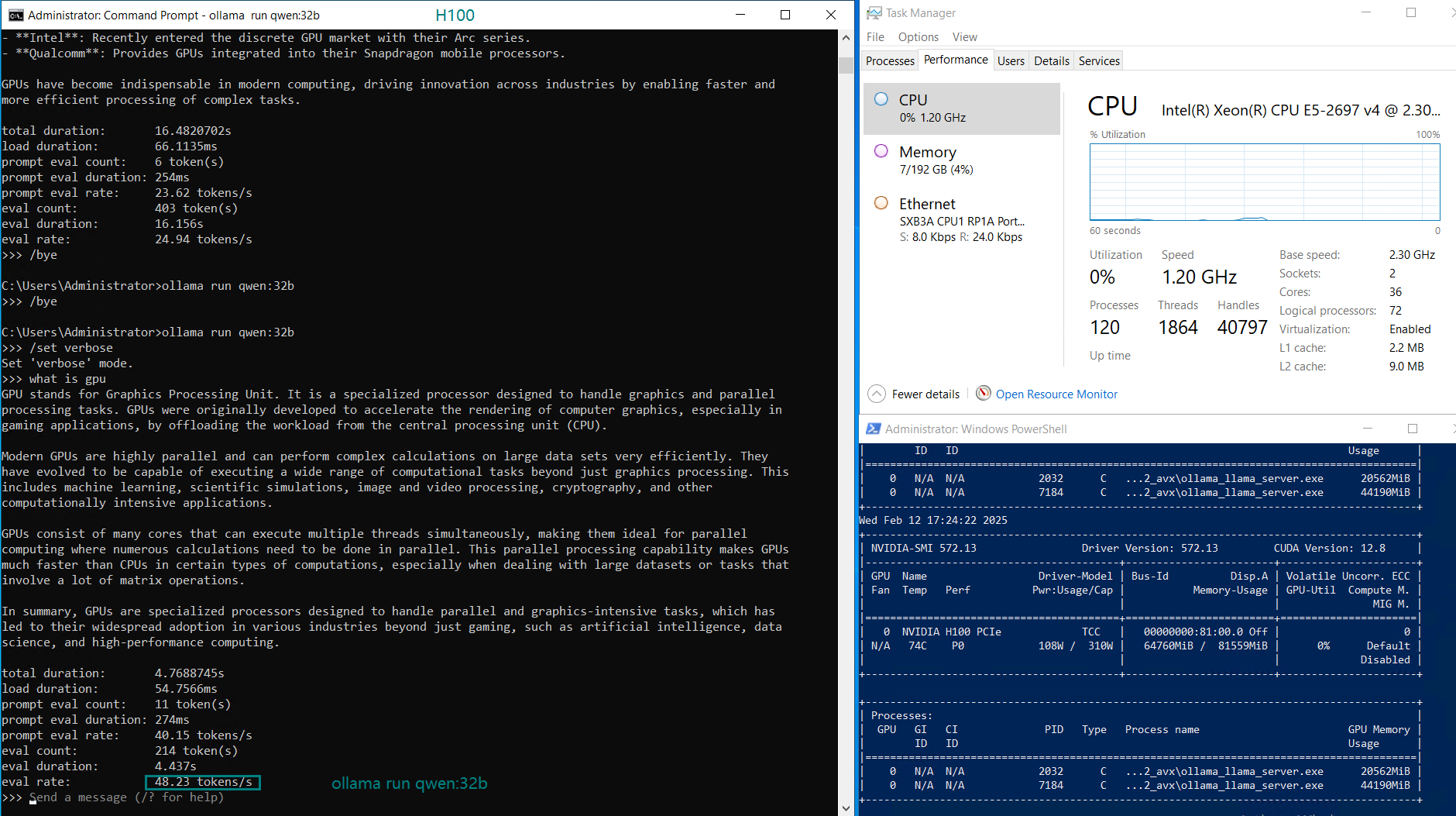
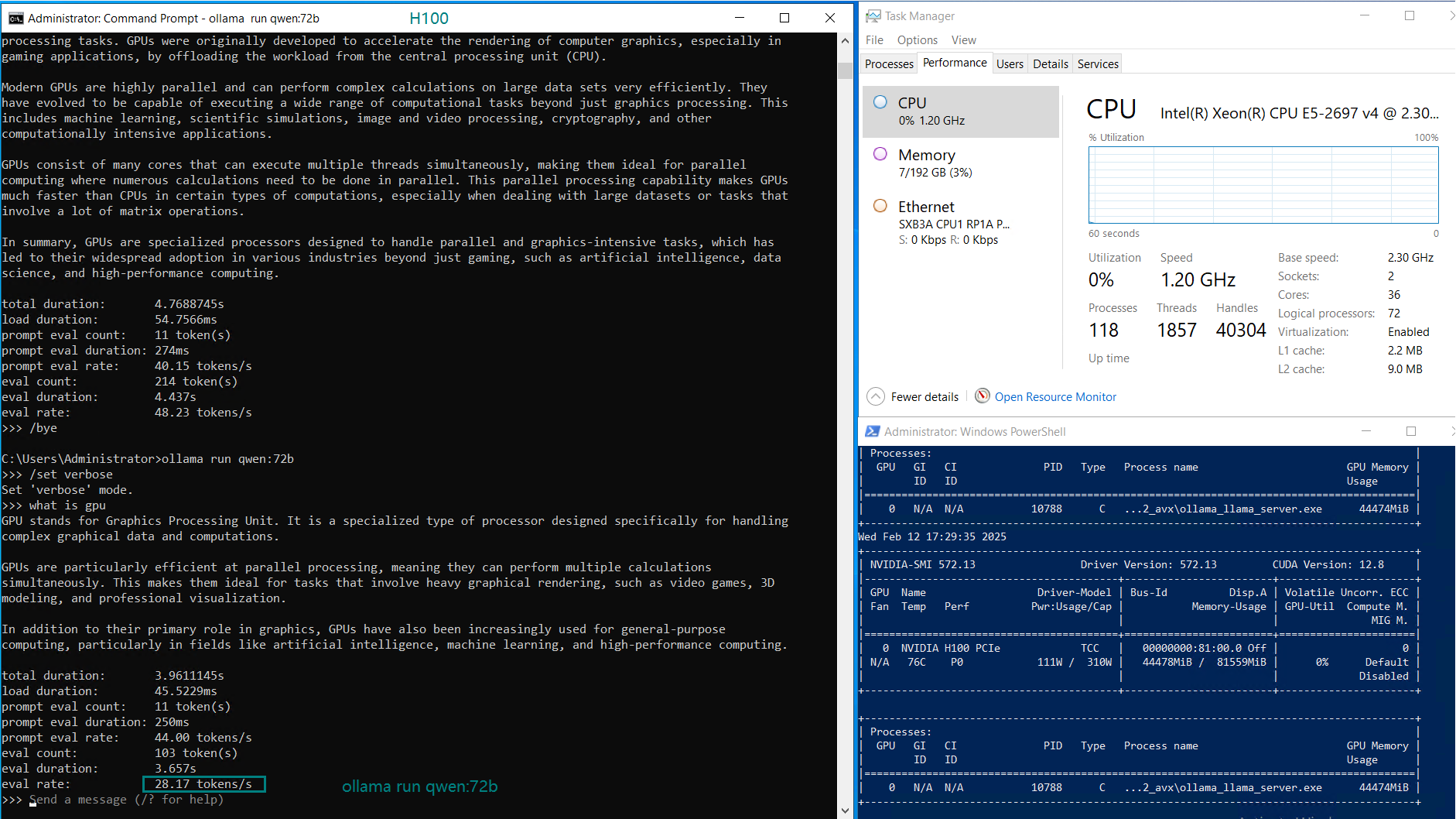
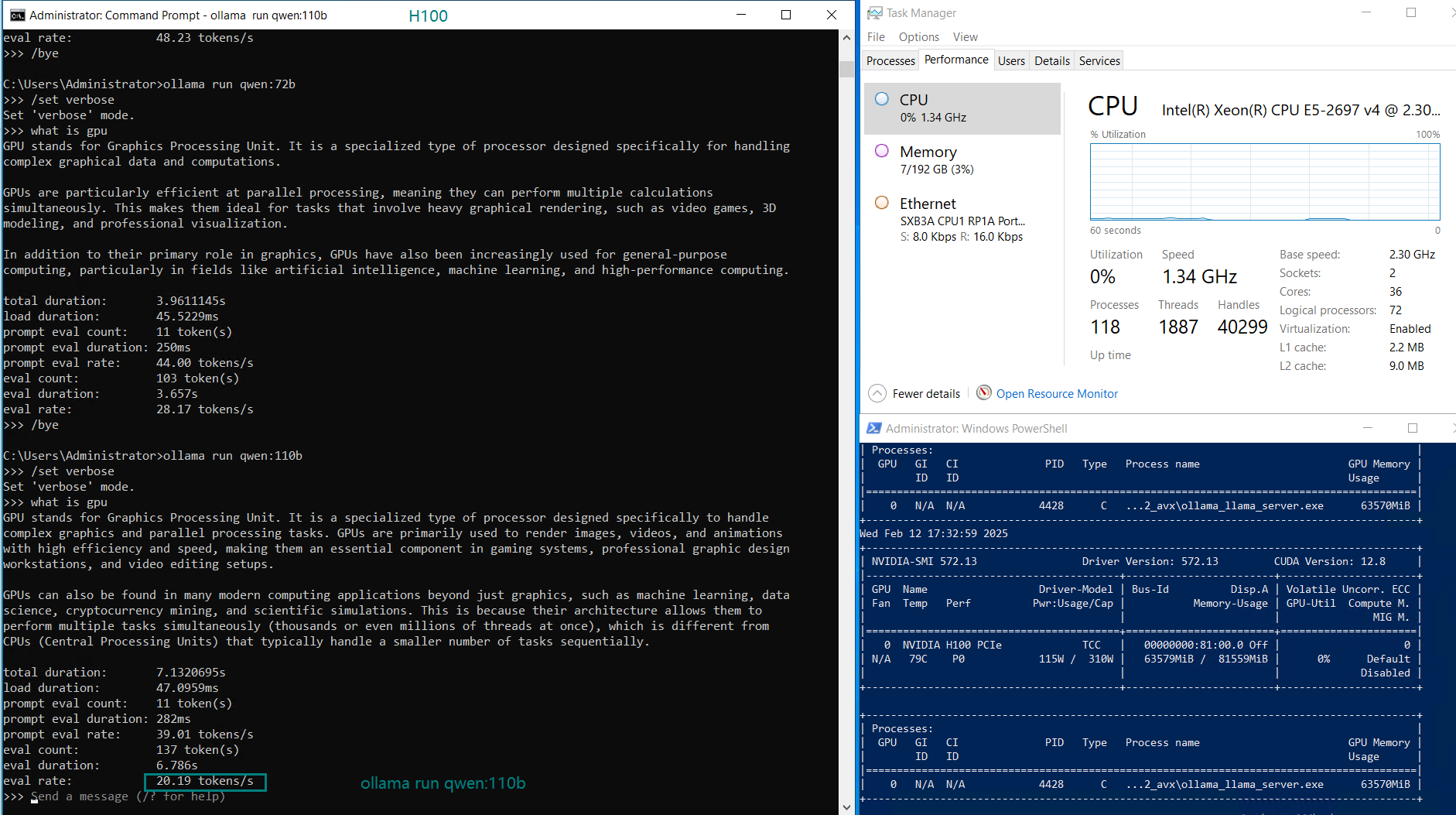
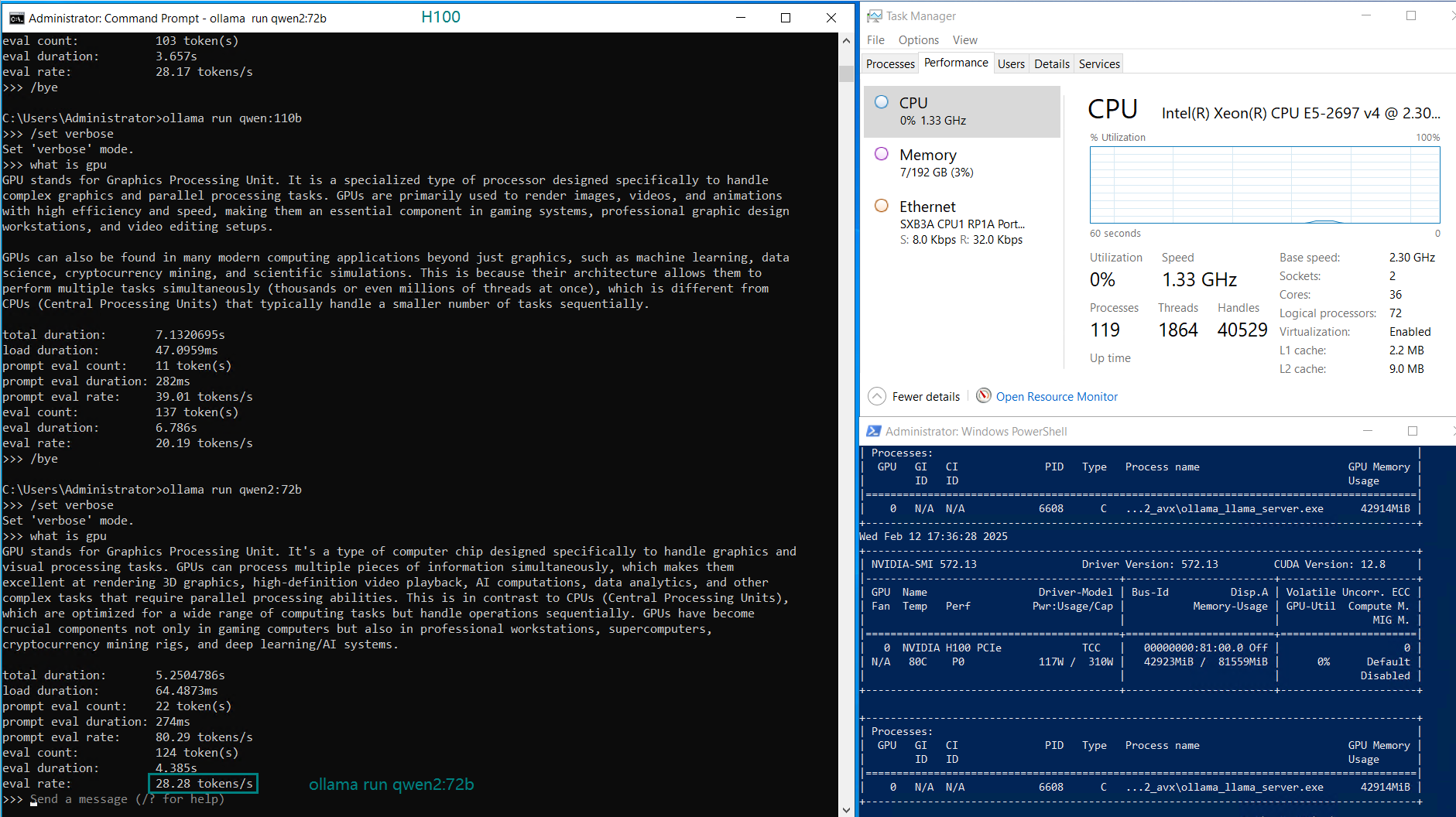
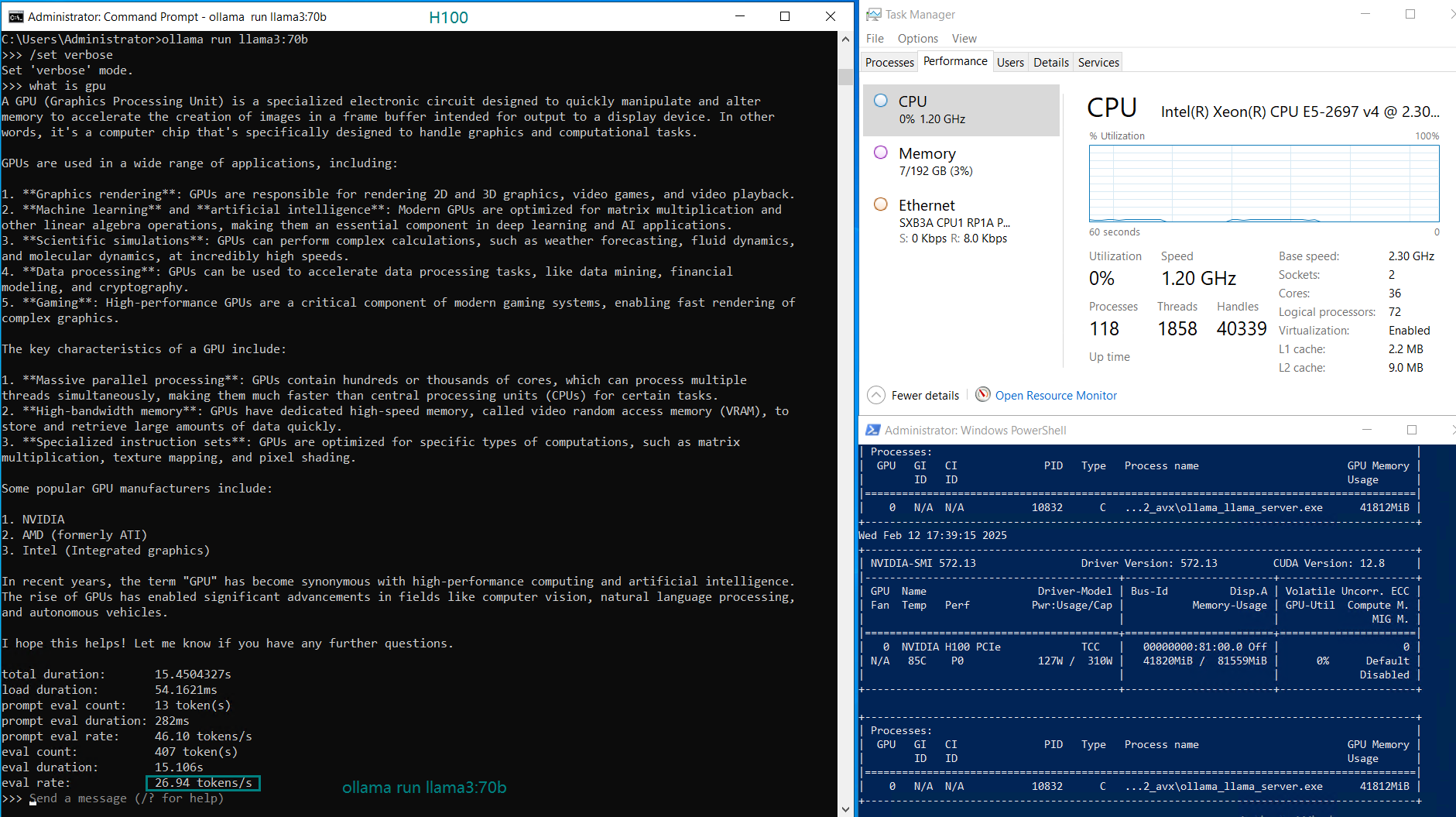
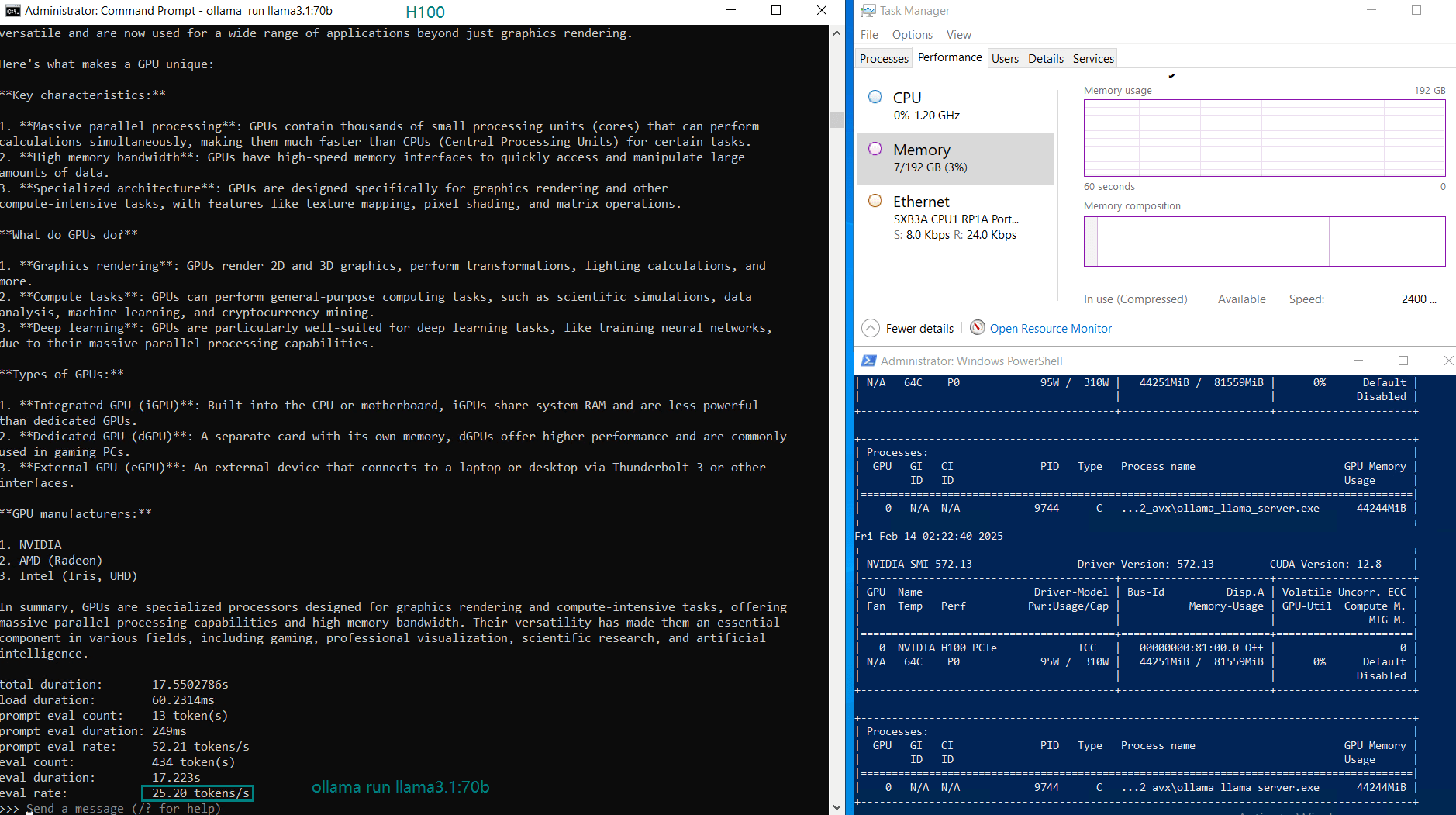
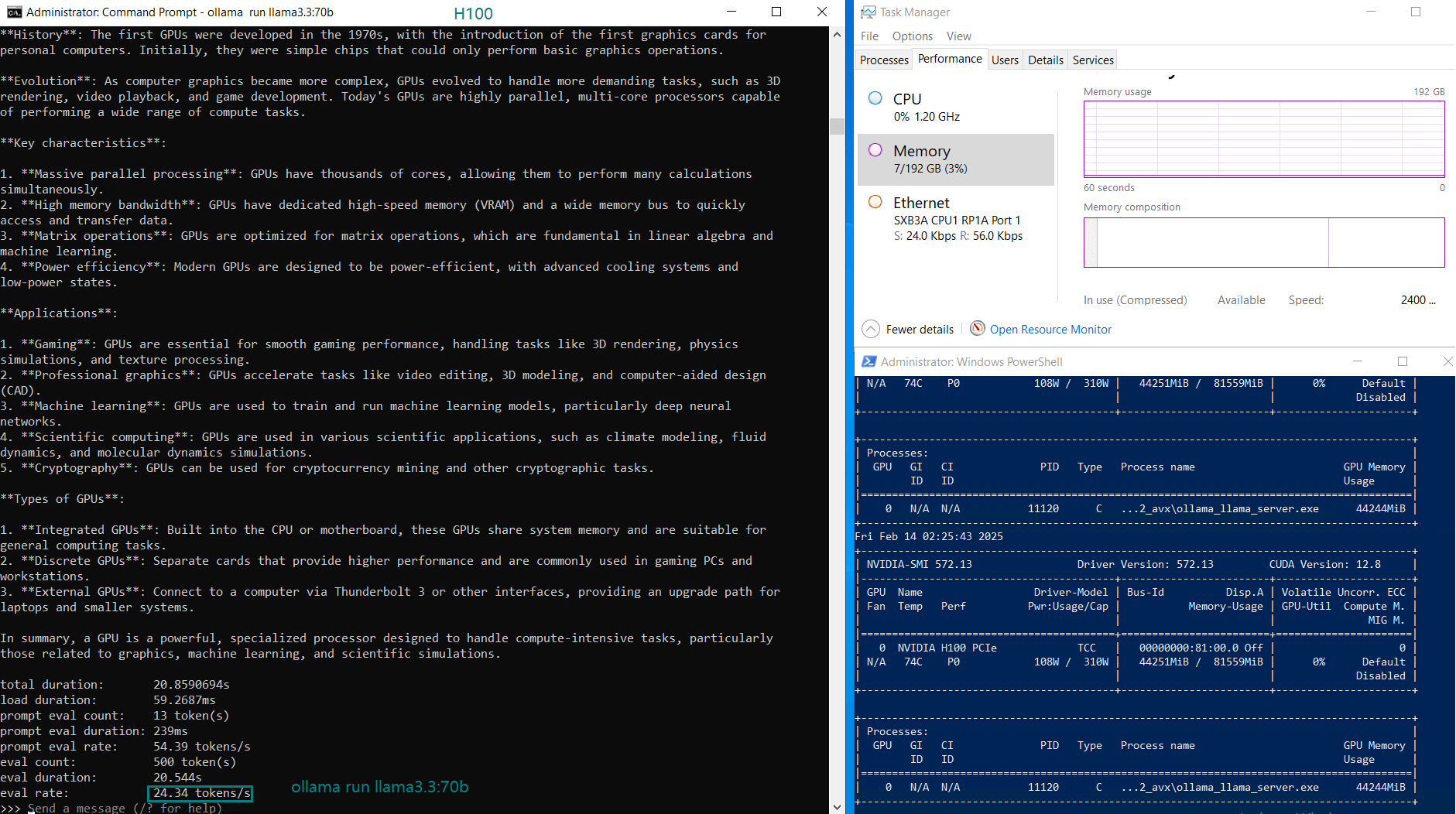
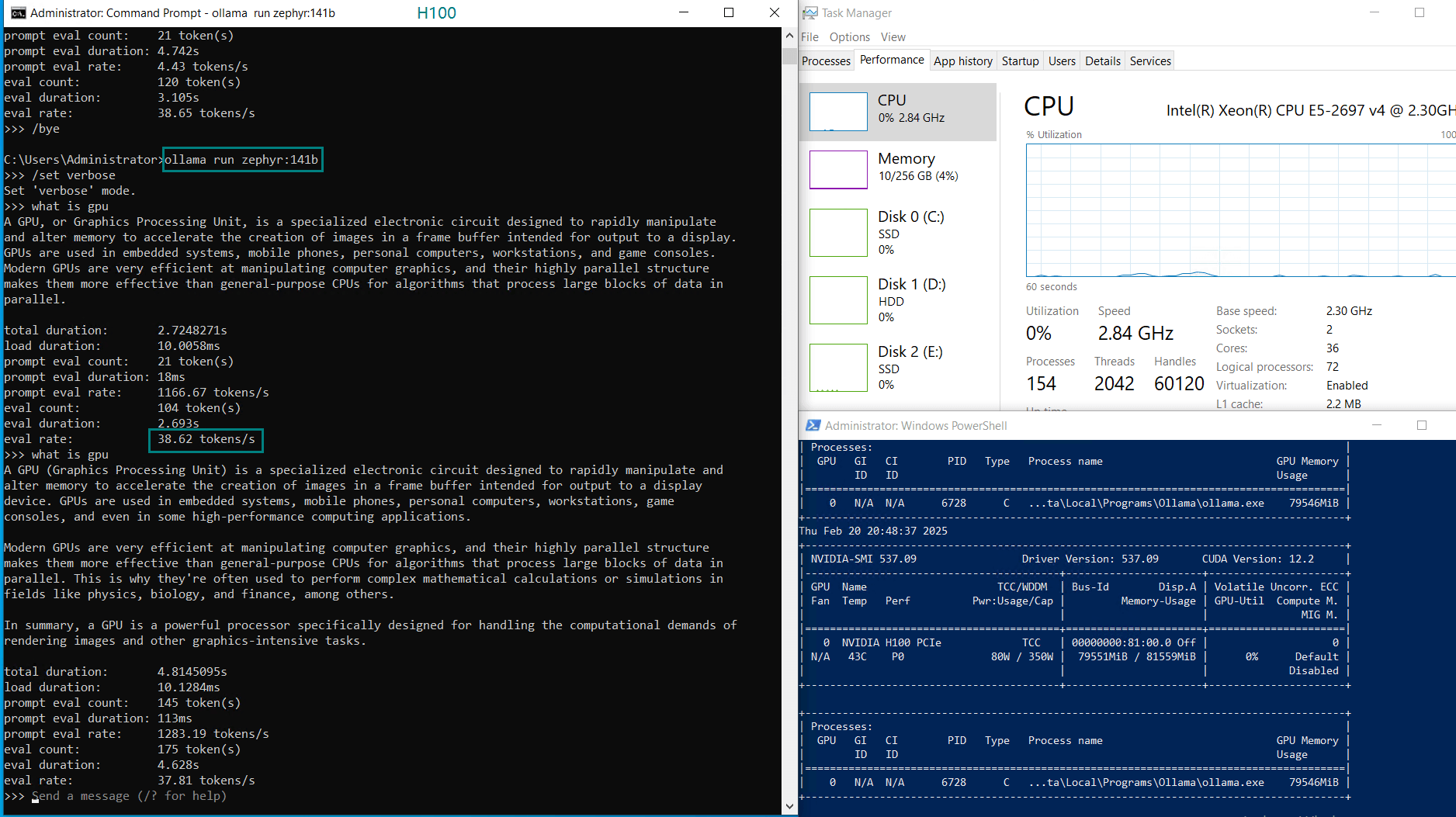
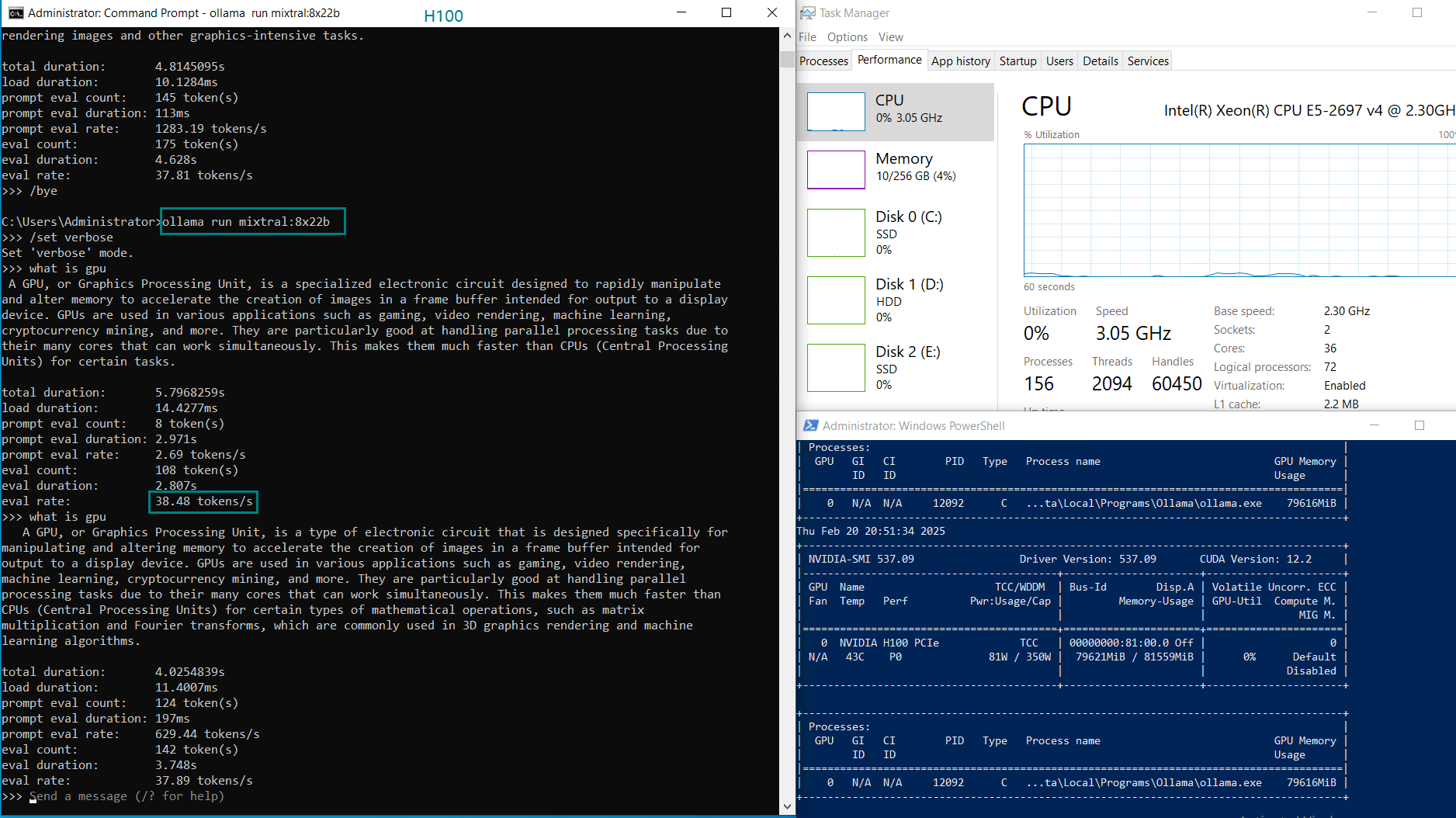
| GPU UTL | 75% | 83% | 92% | 72% | 83% | 90% | 86% | 91 | 90% | 93% | 83% | 83% |
| Eval Rate(tokens/s) | 75.02 | 45.36 | 24.94 | 48.23 | 28.17 | 20.19 | 28.28 | 26.94 | 25.20 | 24.34 | 38.62 | 38.28 |
Analysis & Insights
1. CPU Utilization
2. RAM Utilization
3. Ollama's Performance on H100
- The DeepSeek 14B model had the highest token throughput at 75.02 tokens/s, making it the most efficient for lower-end LLM applications.
- Larger models like Qwen 110B and LLaMA 3.3 70B saw increased GPU utilization (90-100%), with a corresponding drop in evaluation speed (~20 tokens/s).
- The H100 GPU handled 70B+ models efficiently, even under high workloads, making it ideal for LLM hosting and AI inference.
H100 vs. A100 for LLMs
- The H100 significantly outperforms the A100 for Ollama benchmarks and LLM inference, thanks to its higher FLOPS and more advanced tensor cores.
- If you need to run 70B~110B models, H100 is the better choice, especially for real-time applications.
| Metric | Nvidia H100 | Nvidia A100 80GB |
|---|---|---|
| Architecture | Hopper | Ampere |
| CUDA Cores | 14,592 | 6,912 |
| Tensor Cores | 456 | 432 |
| Memory | 80GB HBM2e | 80GB HBM2 |
| FP32 TFLOPS | 183 | 19.5 |
| LLM Performance | 2x Faster | Baseline |
H100 GPU Hosting for LLMs
Enterprise GPU Dedicated Server - RTX 4090
- 256GB RAM
- GPU: GeForce RTX 4090
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ada Lovelace
- CUDA Cores: 16,384
- Tensor Cores: 512
- GPU Memory: 24 GB GDDR6X
- FP32 Performance: 82.6 TFLOPS
Enterprise GPU Dedicated Server - RTX A6000
- 256GB RAM
- GPU: Nvidia Quadro RTX A6000
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 10,752
- Tensor Cores: 336
- GPU Memory: 48GB GDDR6
- FP32 Performance: 38.71 TFLOPS
Enterprise GPU Dedicated Server - A100
- 256GB RAM
- GPU: Nvidia A100
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 40GB HBM2
- FP32 Performance: 19.5 TFLOPS
Enterprise GPU Dedicated Server - H100
- 256GB RAM
- GPU: Nvidia H100
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Hopper
- CUDA Cores: 14,592
- Tensor Cores: 456
- GPU Memory: 80GB HBM2e
- FP32 Performance: 183TFLOPS
Summary and Recommendations
The Nvidia H100 GPU delivers outstanding performance for LLM inference and AI workloads. Running Ollama on an H100 server allows users to efficiently process large-scale AI models, with high throughput and low latency.
For anyone needing LLM hosting, H100 hosting, or high-performance AI computing, our dedicated H100 GPU server is the best choice.
Nvidia H100, GPU server, LLM inference, Ollama AI Reasoning, large model, deep learning, GPU cloud computing, H100 vs A100, AI hosting