

Benchmarking LLMs on Ollama with Nvidia Tesla P100 | Performance & Hosting
With the growing demand for local AI inference, running large language models (LLMs) on Ollama with affordable GPU servers has become a hot topic. In this benchmark, we test the Nvidia Tesla P100—a 16GB HBM2 Pascal-based GPU—to evaluate its performance for 7B to 16B LLMs on Ollama 0.5.11. If you're considering a P100 for LLM inference, this guide will help you decide.
Server Setup: Nvidia Tesla P100 Hosting Environment
Server Configuration:
- Price: $159~199/month
- CPU: Dual 10-Core Xeon E5-2660v2
- RAM: 128GB DDR3
- Storage: 120GB NVMe + 960GB SSD
- Network: 100Mbps Unmetered
- OS: Windows
GPU Details:
- GPU: Nvidia Tesla P100
- Compute Capability: 6.0
- Microarchitecture: Pascal
- CUDA Cores: 3584
- Memory: 16GB HBM2
- FP32 Performance: 9.5 TFLOPS
This configuration provides ample RAM and storage for smooth model loading and execution, while the P100's 16GB VRAM enables running larger models compared to the RTX2060 Ollama benchmark we previously conducted.
Benchmark Results: Running LLMs on Tesla P100 with Ollama
| Models | deepseek-r1 | deepseek-r1 | deepseek-r1 | deepseek-coder-v2 | llama2 | llama2 | llama3.1 | gemma2 | qwen2.5 | qwen2.5 |
|---|---|---|---|---|---|---|---|---|---|---|
| Parameters | 7b | 8b | 14b | 16b | 7b | 13b | 8b | 9b | 7b | 14b |
| Size(GB) | 4.7 | 4.9 | 9 | 8.9 | 3.8 | 7.4 | 4.9 | 5.4 | 4.7 | 9.0 |
| Quantization | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Running on | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 |
| Downloading Speed(mb/s) | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 |
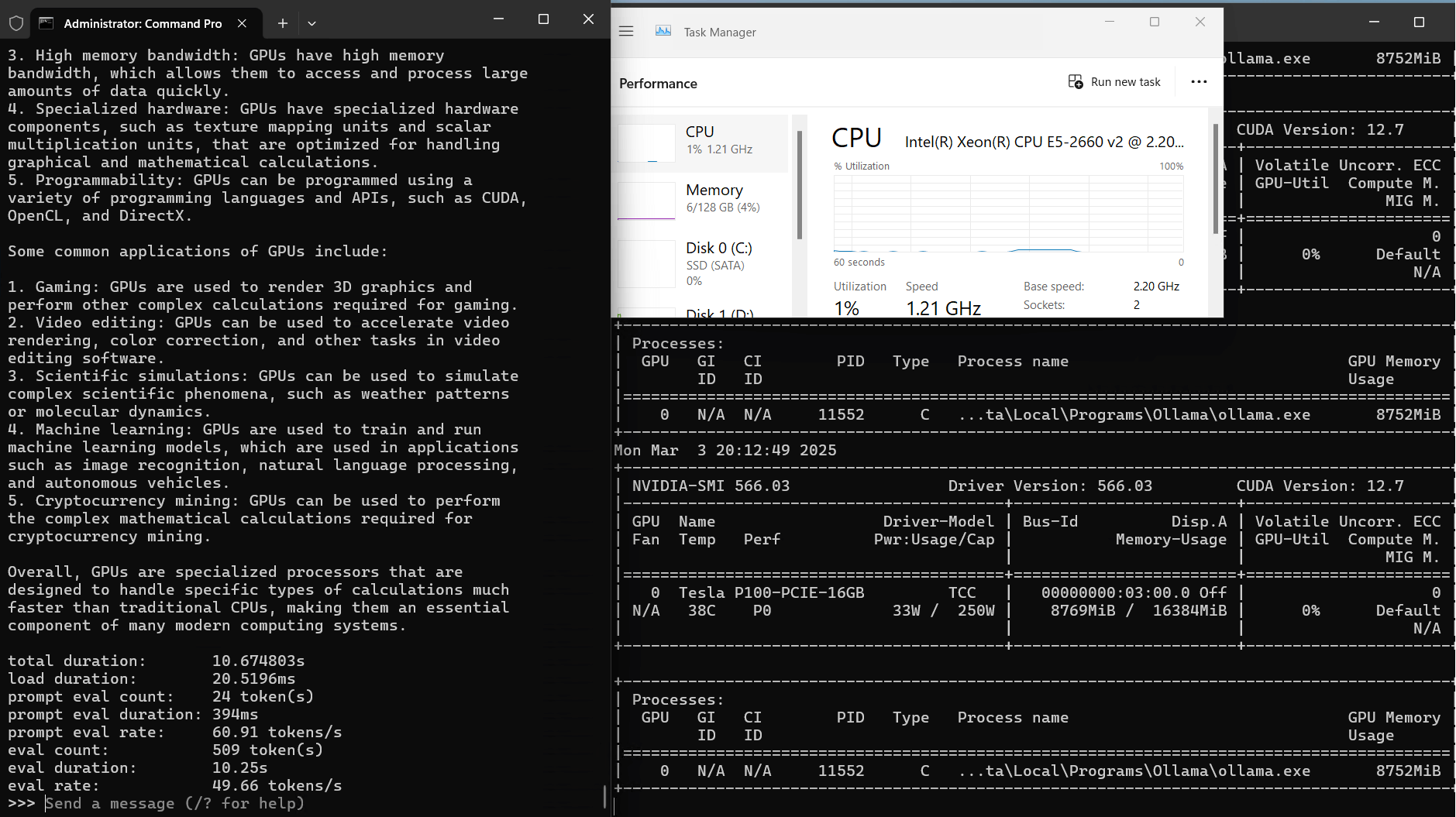
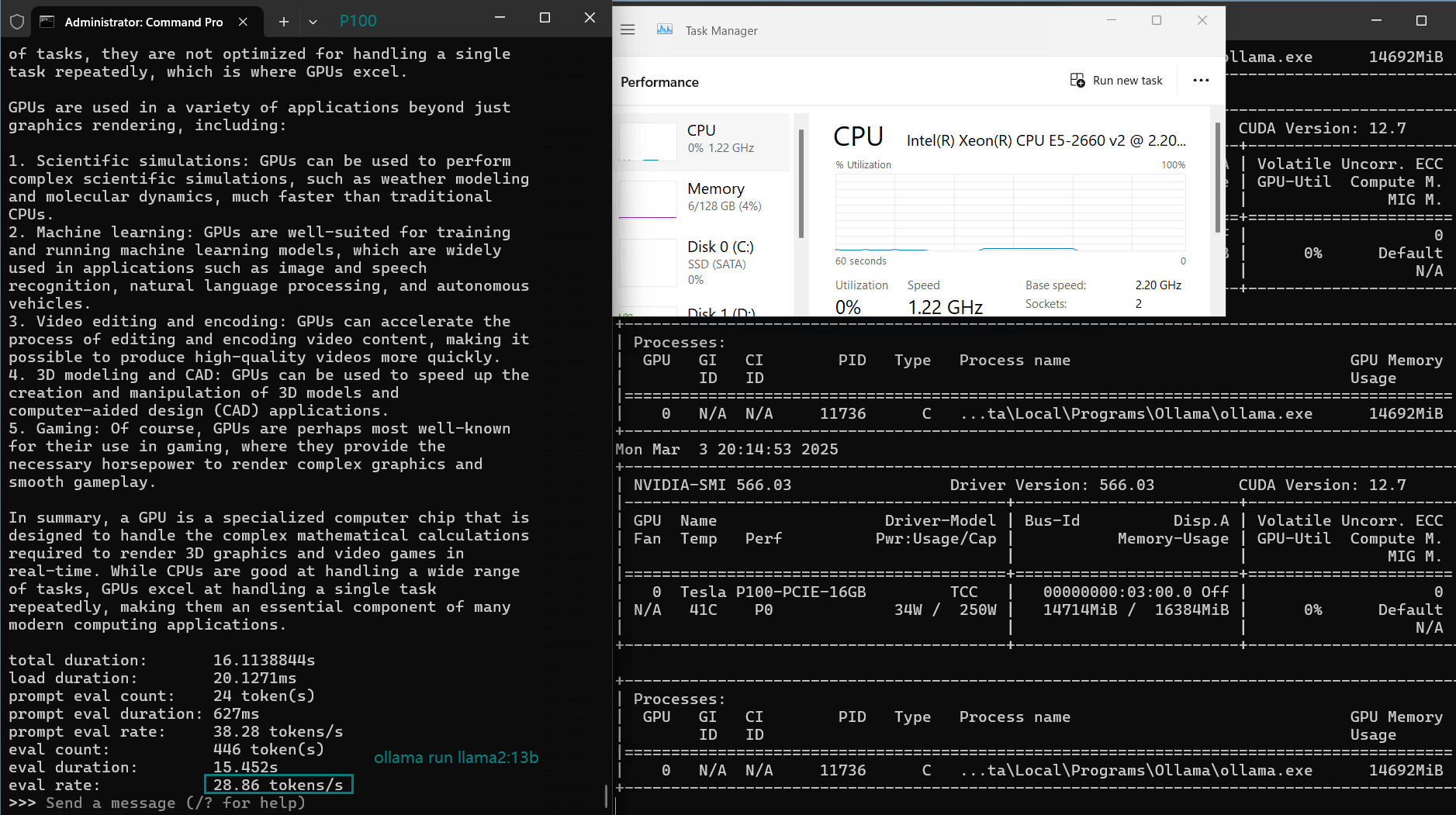
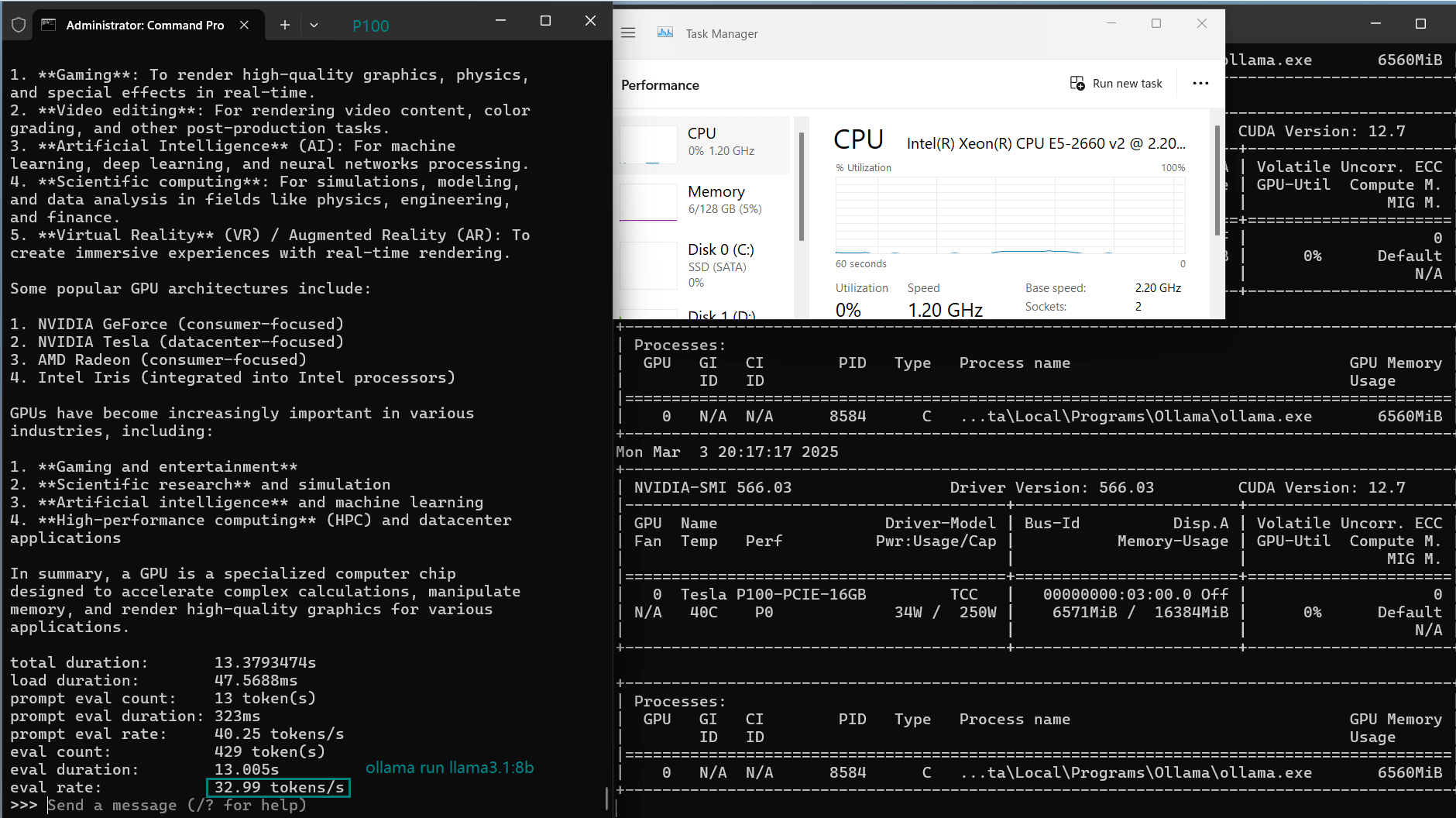
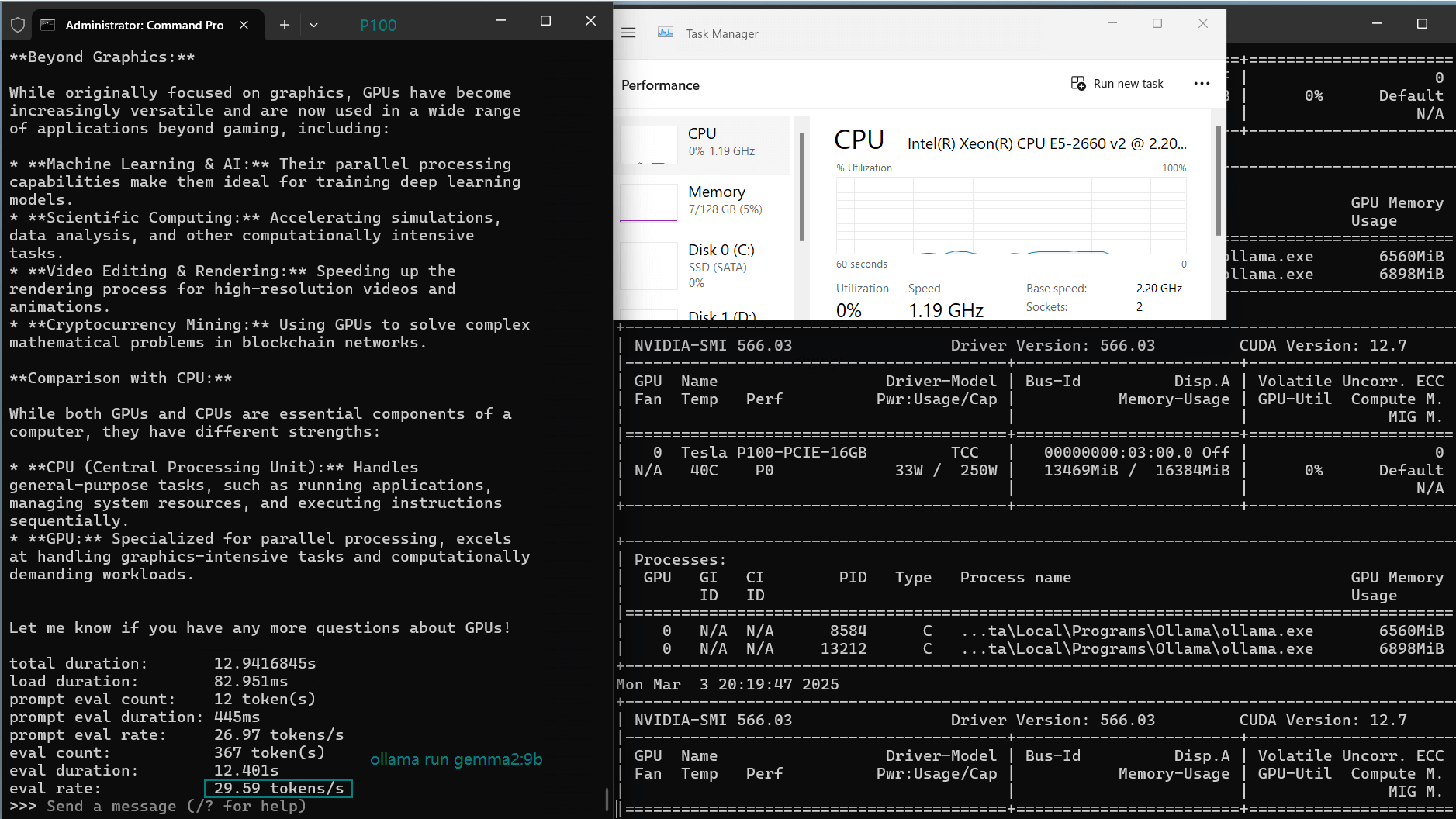
| CPU Rate | 3% | 3% | 3% | 3% | 4% | 3% | 3% | 3% | 3% | 3% |
| RAM Rate | 5% | 5% | 5% | 4% | 4% | 4% | 5% | 5% | 5% | 5% |
| GPU UTL | 85% | 89% | 90% | 65% | 91% | 95% | 88% | 81% | 87% | 91% |
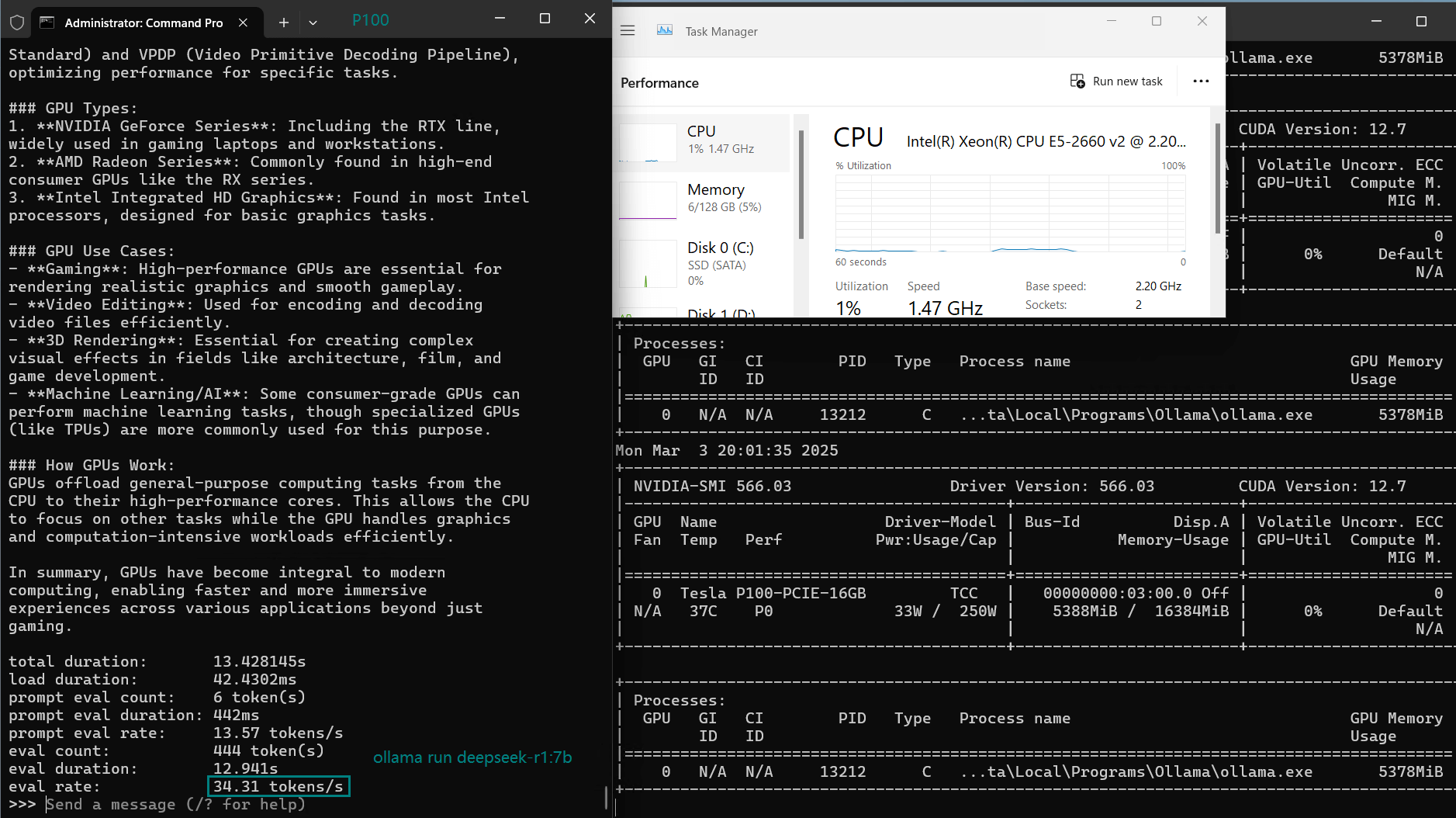
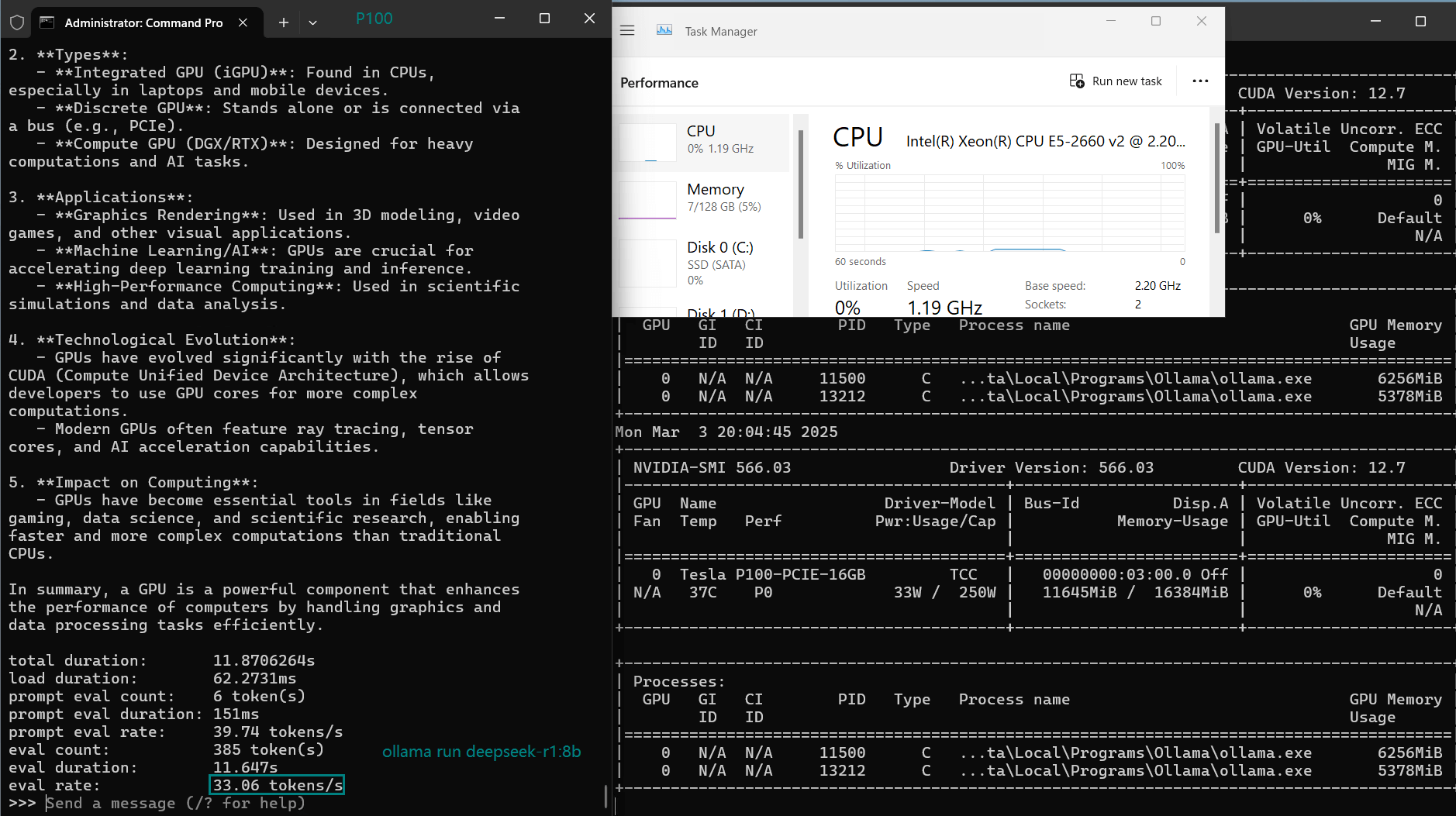
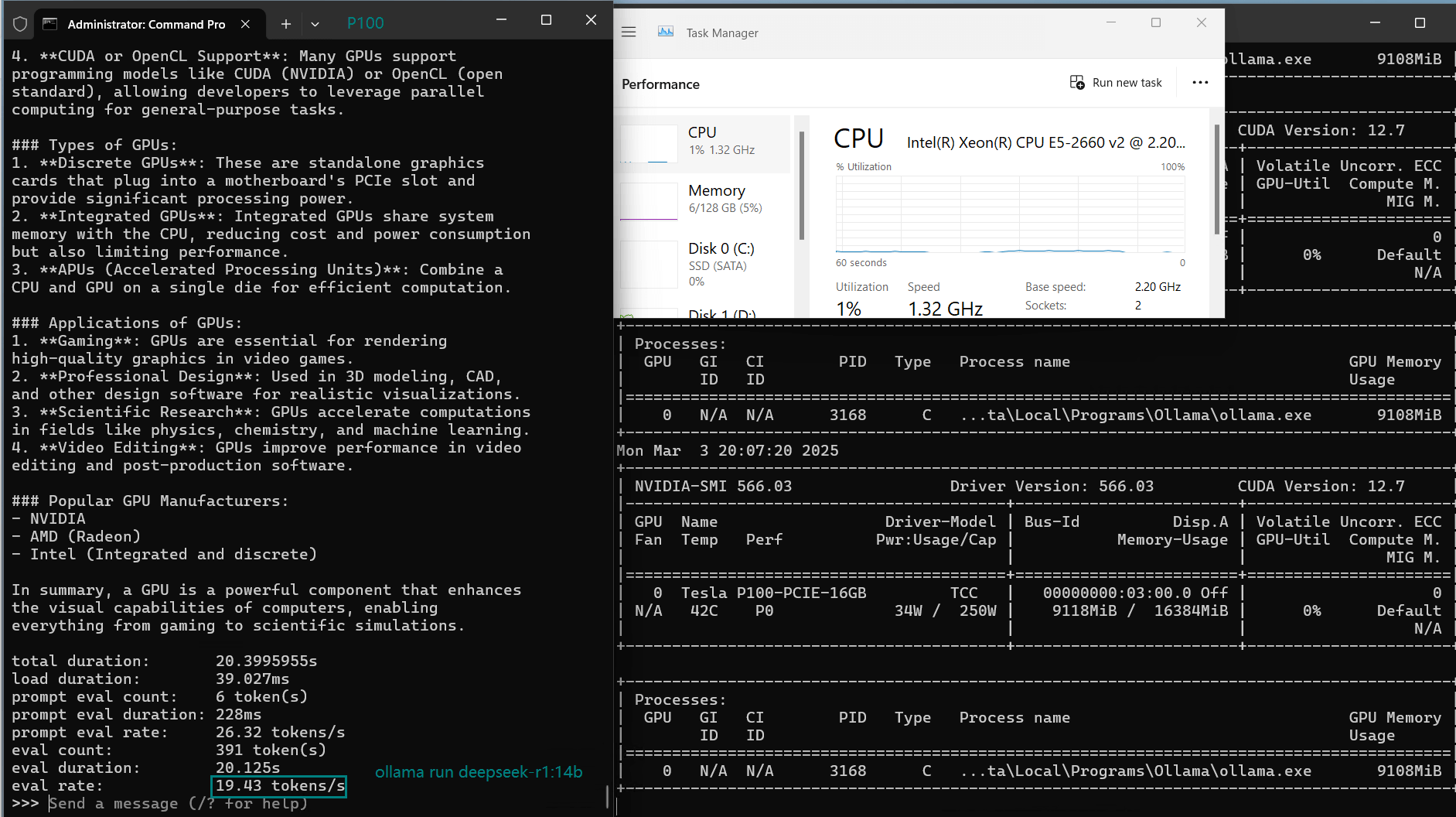
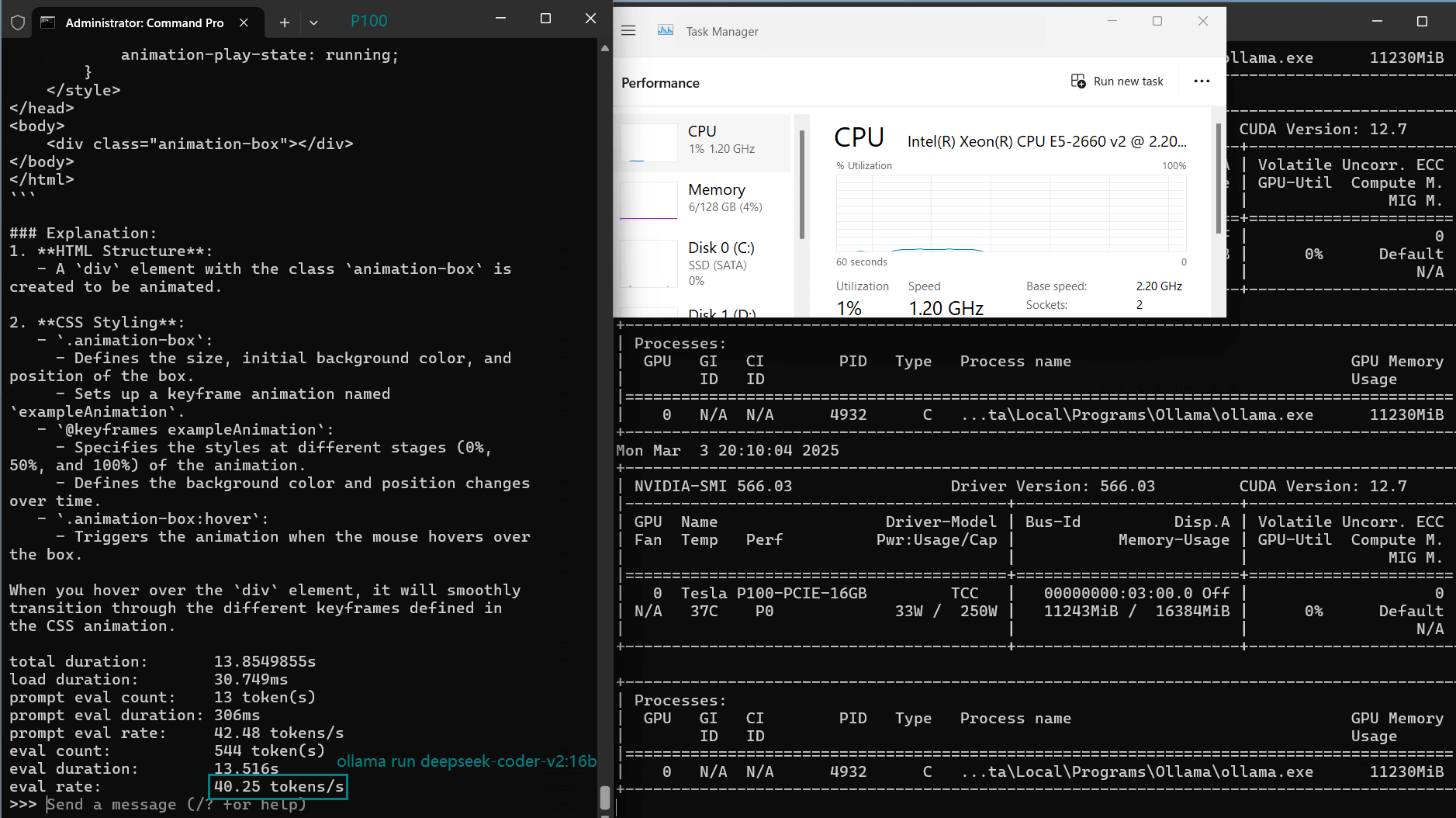
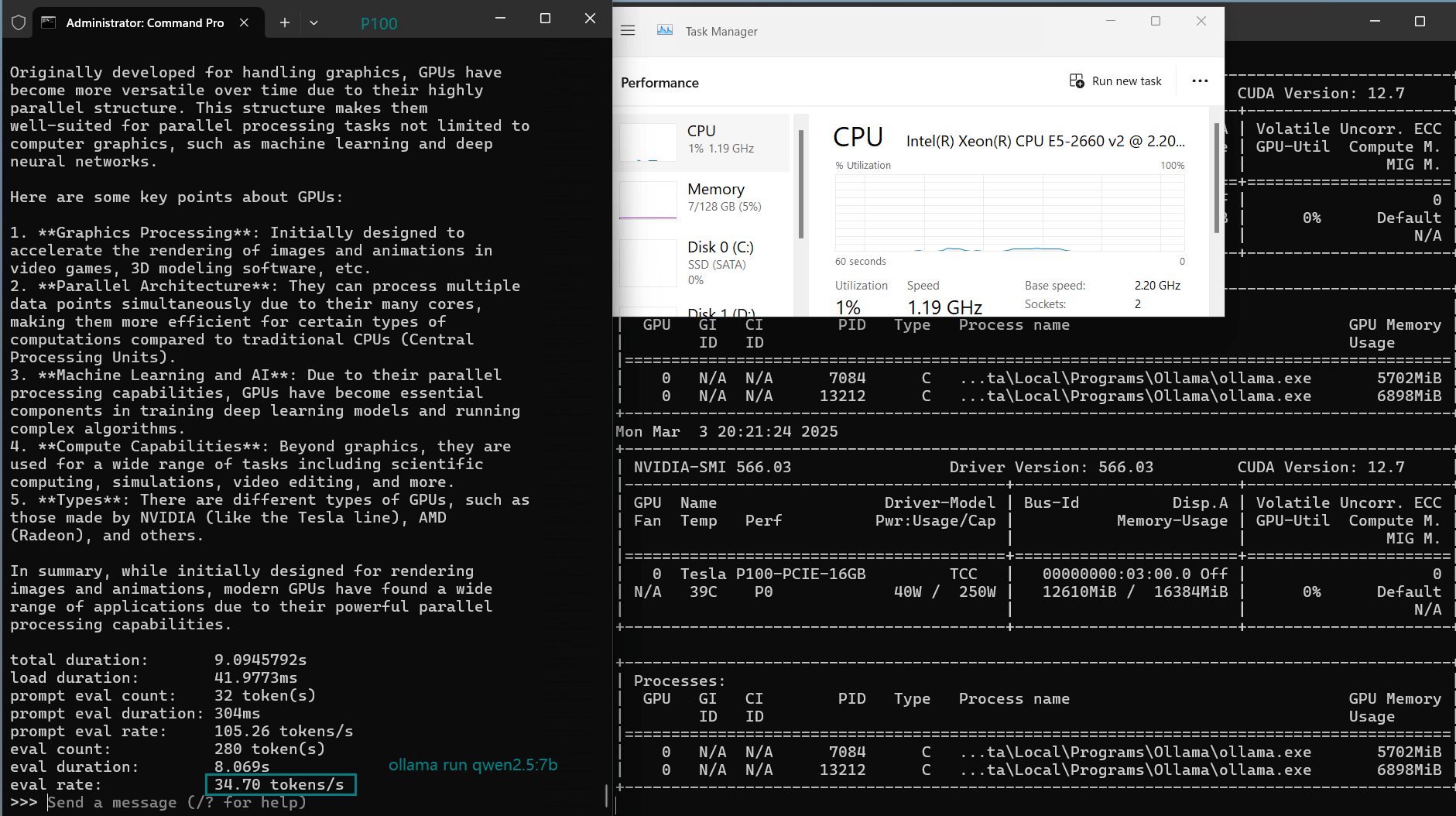
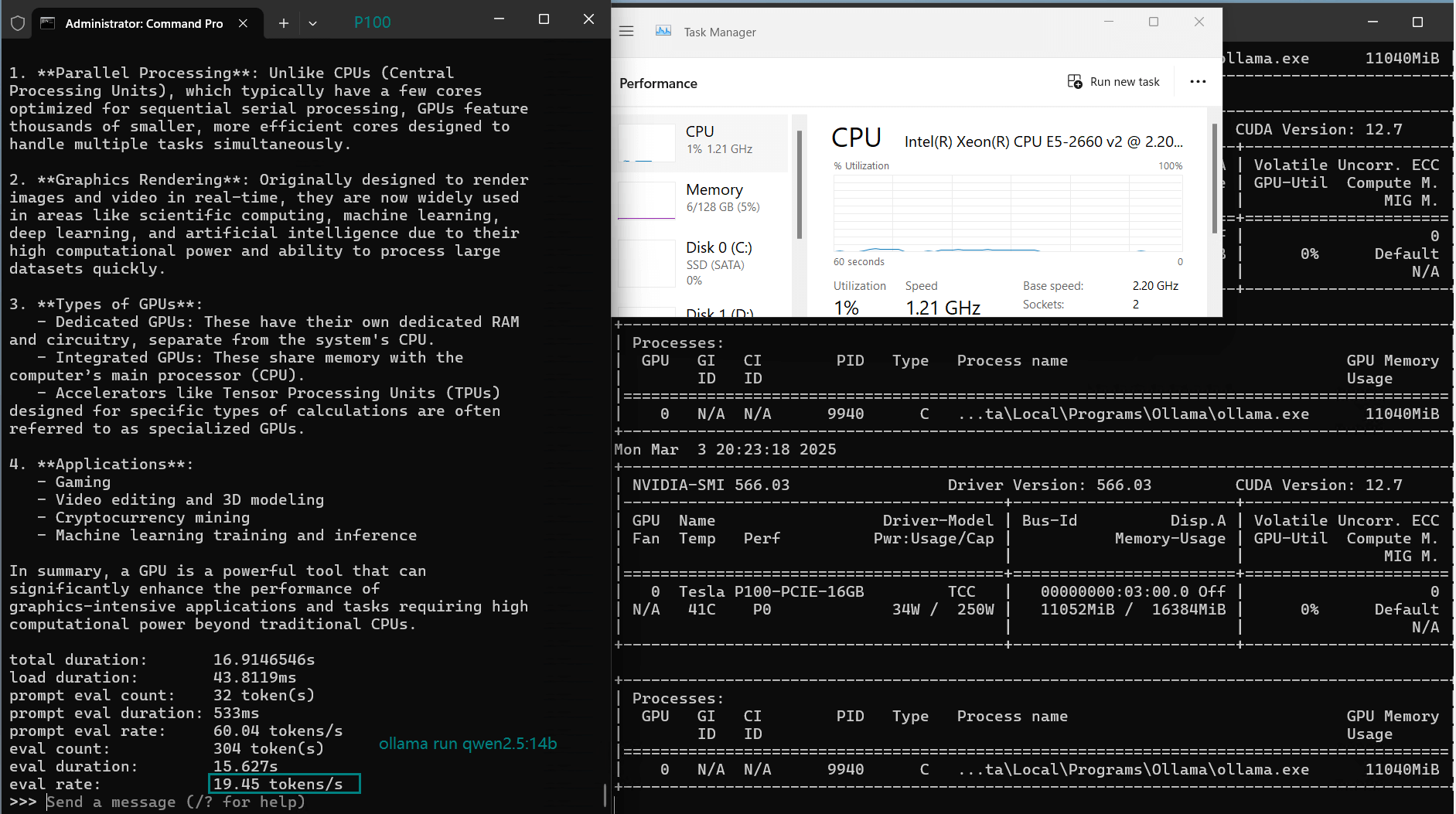
| Eval Rate(tokens/s) | 34.31 | 33.06 | 19.43 | 40.25 | 49.66 | 28.86 | 32.99 | 29.54 | 34.70 | 19.45 |
Key Takeaways from the Benchmark
- 7B models run best on the Tesla P100 Ollama setup, with Llama2-7B achieving 49.66 tokens/s.
- 14B+ models push the limits—performance drops, with DeepSeek-r1-14B running at 19.43 tokens/s, still acceptable.
- Qwen2.5 and DeepSeek models offer balanced performance, staying between 33–35 tokens/s at 7B.
- Llama2-13B achieves 28.86 tokens/s, making it usable but slower than its 7B counterpart.
- DeepSeek-Coder-v2-16B surprisingly outperformed 14B models (40.25 tokens/s), but lower GPU utilization (65%) suggests inefficiencies.
Is Tesla P100 Good for LLMs on Ollama?
✅ Pros of Using NVIDIA P100 for Ollama
- Handles 7B-13B models efficiently
- Lower cost than A4000 or V100
- Better than RTX2060 for 7B+ LLMs
❌ Limitations of NVIDIA P100 for Ollama
- Struggles with 16B+ models
- Older Pascal architecture lacks Tensor Cores
Get Started with Tesla P100 Hosting for 3-16B LLMs
Professional GPU Dedicated Server - P100
- 128GB RAM
- GPU: Nvidia Tesla P100
- Dual 8-Core E5-2660
- 120GB + 960GB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Pascal
- CUDA Cores: 3584
- GPU Memory: 16 GB HBM2
- FP32 Performance: 9.5 TFLOPS
Professional GPU VPS - A4000
- 28GB RAM
- 24 CPU Cores
- 320GB SSD
- 300Mbps Unmetered Bandwidth
- Once per 2 Weeks Backup
- OS: Windows / Linux
- Dedicated GPU: Quadro RTX A4000
- CUDA Cores: 6,144
- Tensor Cores: 192
- GPU Memory: 16GB GDDR6
- FP32 Performance: 19.2 TFLOPS
Advanced GPU Dedicated Server - V100
- 128GB RAM
- GPU: Nvidia V100
- Dual 12-Core E5-2690v3
- 240GB SSD + 2TB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Volta
- CUDA Cores: 5,120
- Tensor Cores: 640
- GPU Memory: 16GB HBM2
- FP32 Performance: 14 TFLOPS
Enterprise GPU Dedicated Server - RTX 4090
- 256GB RAM
- GPU: GeForce RTX 4090
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ada Lovelace
- CUDA Cores: 16,384
- Tensor Cores: 512
- GPU Memory: 24 GB GDDR6X
- FP32 Performance: 82.6 TFLOPS
Final Thoughts: Best Models for Tesla P100 on Ollama
For Nvidia P100 rental users, the best models for small-scale AI inference on Ollama are:
- Llama2-7B (Fastest: 49.66 tokens/s)
- DeepSeek-r1-7B (Balanced: 34.31 tokens/s)
- Qwen2.5-7B (Strong alternative: 34.70 tokens/s)
- DeepSeek-Coder-v2-16B (Best large model: 40.25 tokens/s)
Ollama P100, Tesla P100 LLMs, Ollama Tesla P100, Nvidia P100 hosting, benchmark P100, Ollama benchmark, P100 for 7B-14B LLMs inference, Nvidia P100 rental, Tesla P100 performance, Ollama LLMs, deepseek-r1 P100, Llama2 P100 benchmark, Qwen2.5 Tesla P100, Nvidia P100 AI inference