

Ollama GPU Benchmark: Run LLMs on Ollama P1000 GPU Dedicated Servers
For developers and researchers exploring large language models (LLMs), Ollama has emerged as a powerful platform for testing and deploying models on various hardware configurations. In this article, we explore the benchmark performance of Ollama on a dedicated GPU server featuring the Nvidia Quadro P1000 GPU. We evaluate its capability to run popular models such as Llama, Gemma, and Qwen, among others, and provide detailed insights into its performance metrics.
Test Environment Specifications
Server Configuration:
- CPU: Eight-Core Xeon E5-2690
- RAM: 32GB
- Storage: 120GB SSD + 960GB SSD
- Bandwidth: 100Mbps-1Gbps
- Operating System: Ubuntu 24.0
GPU Details:
- GPU Model: Nvidia Quadro P1000
- Microarchitecture: Pascal
- Compute Capacity: 6.1
- CUDA Cores: 640
- GPU Memory: 4GB GDDR5
- FP32 Performance: 1.894 TFLOPS
Models Tested on Ollama GPU Platform
These models were evaluated on Ollama version 0.5.4, utilizing 4-bit quantization for memory efficiency:
- Llama3.2 (1B, 3B parameters)
- Gemma2 (2B parameters)
- CodeGemma (2B parameters)
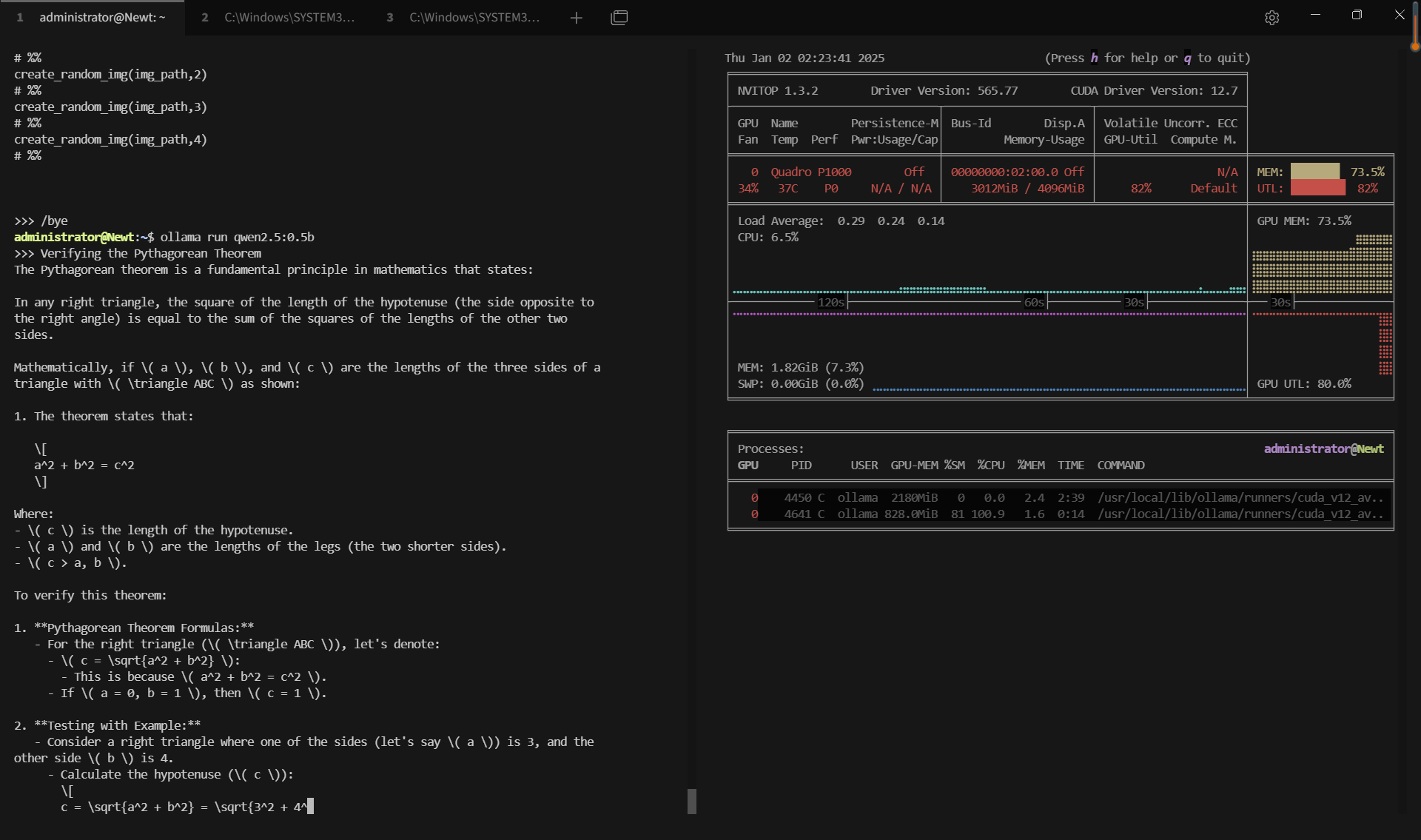
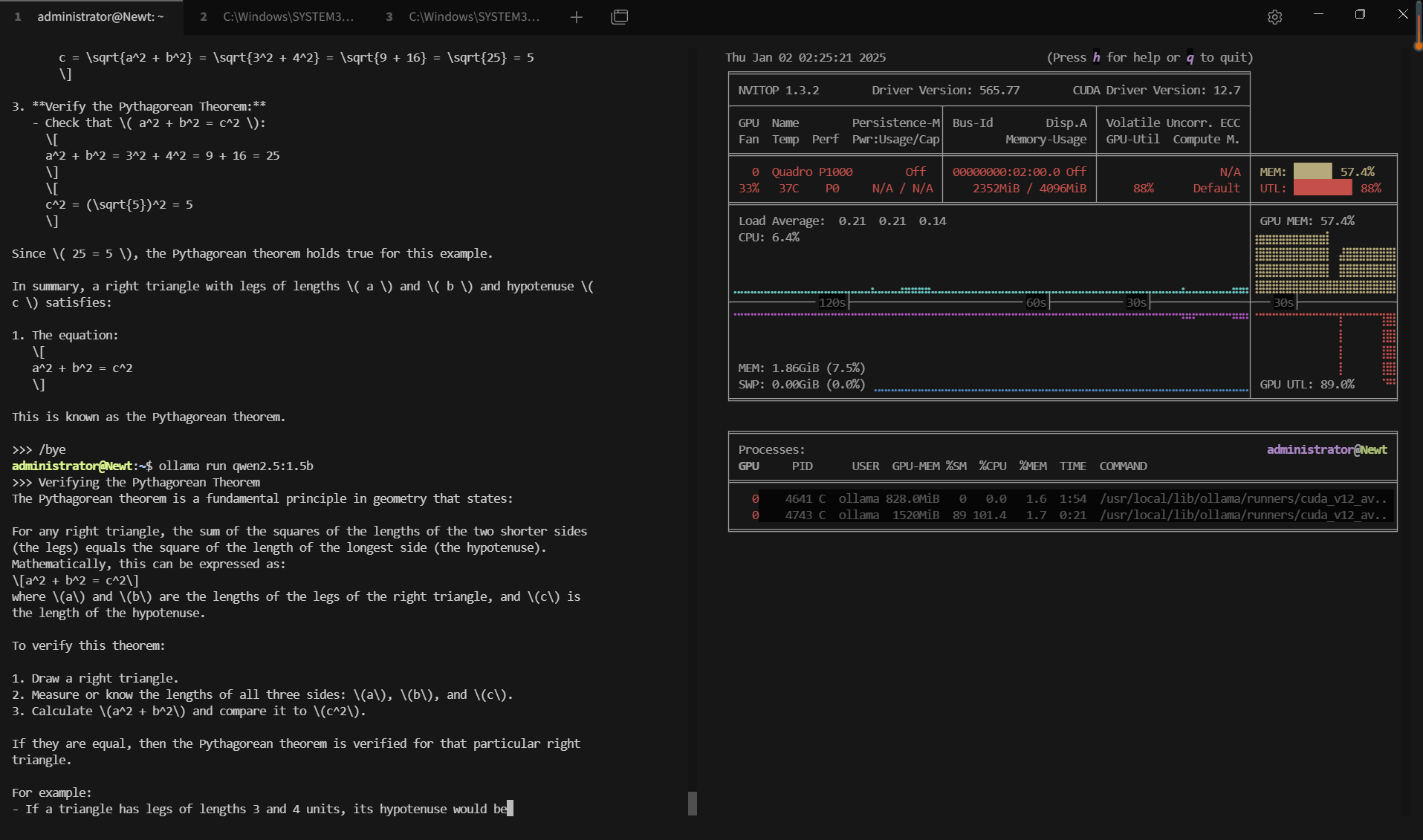
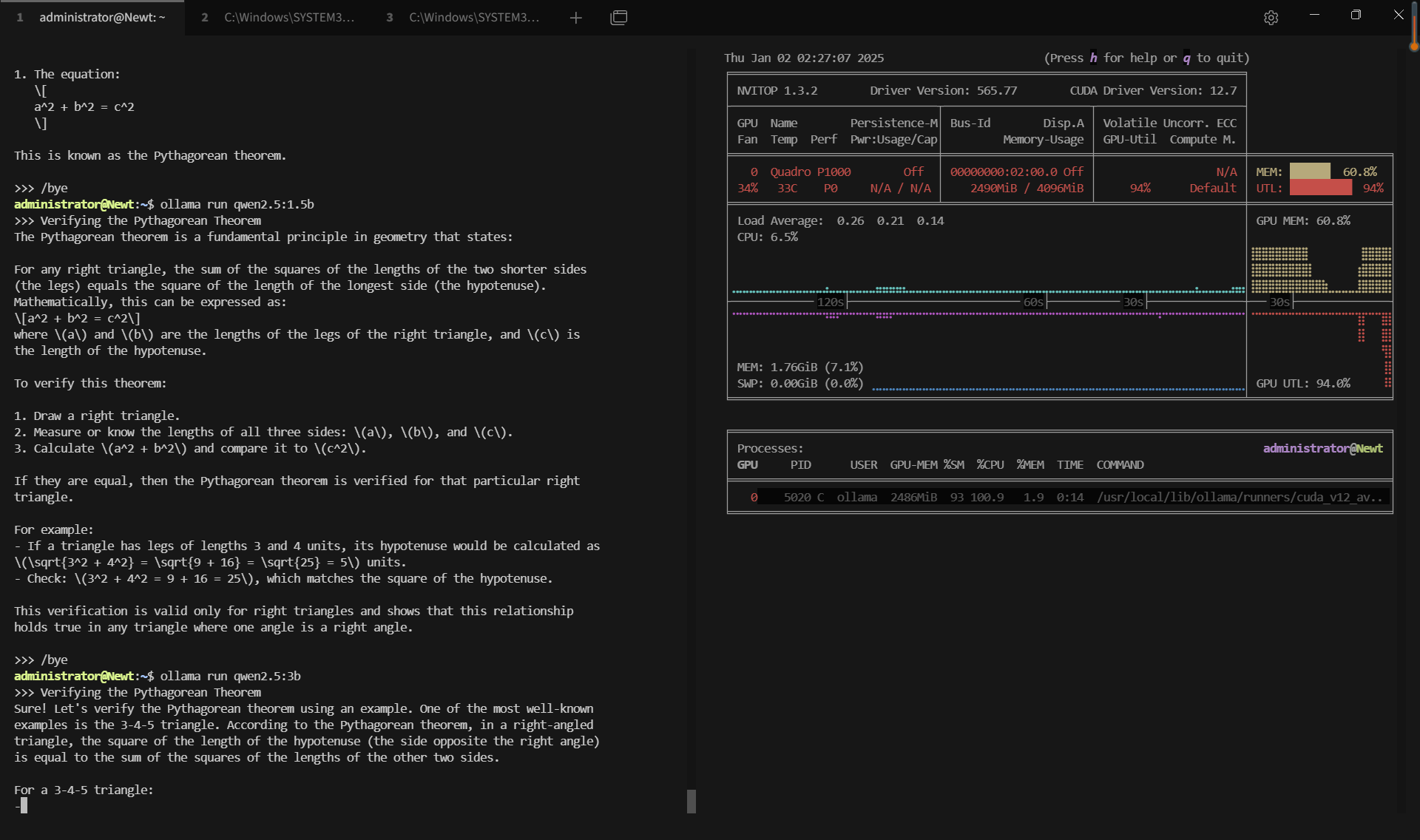
- Qwen2.5 (0.5B, 1.5B, 3B parameters)
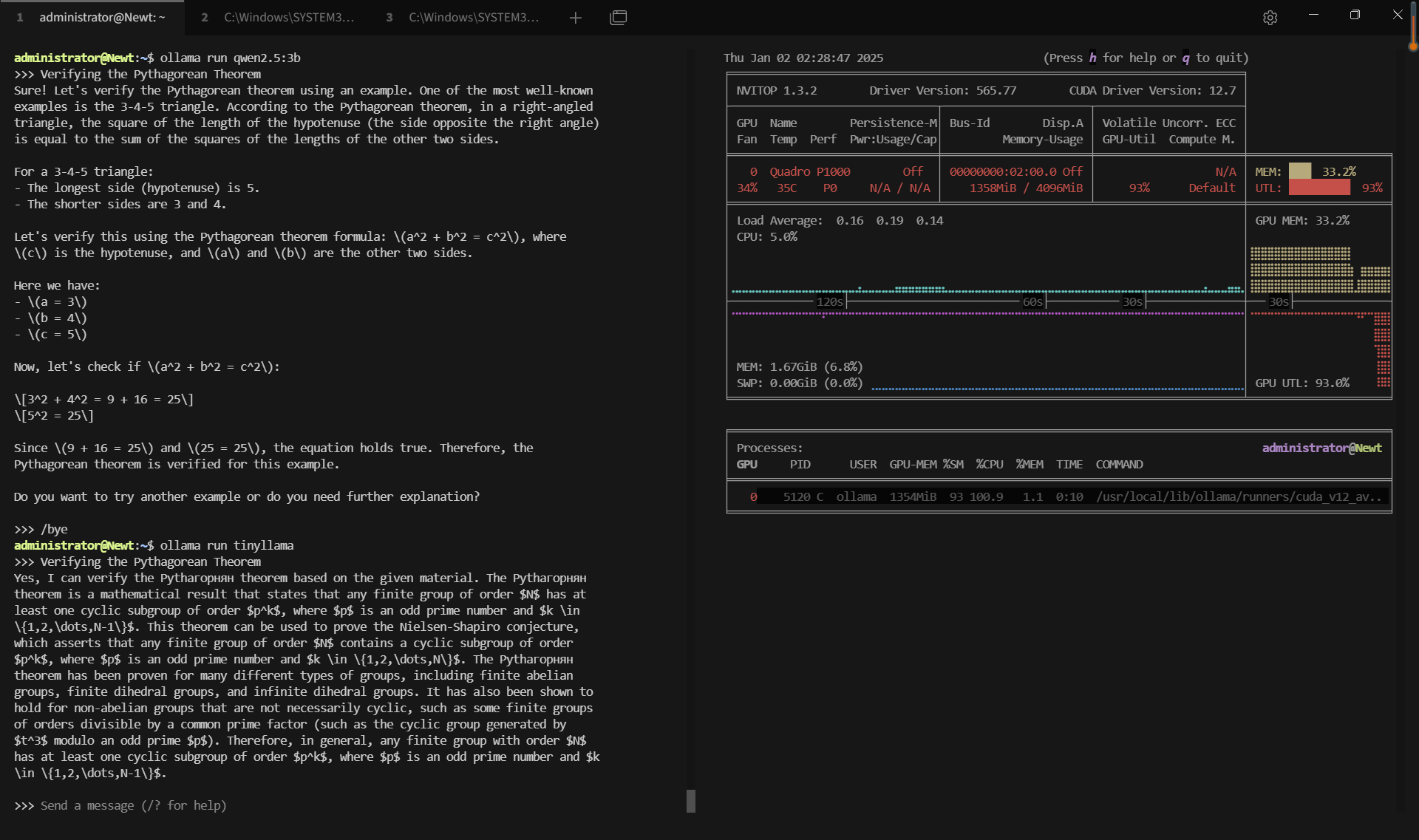
- TinyLlama (1.1B parameters)
- Phi3.5 (3.8B parameters)
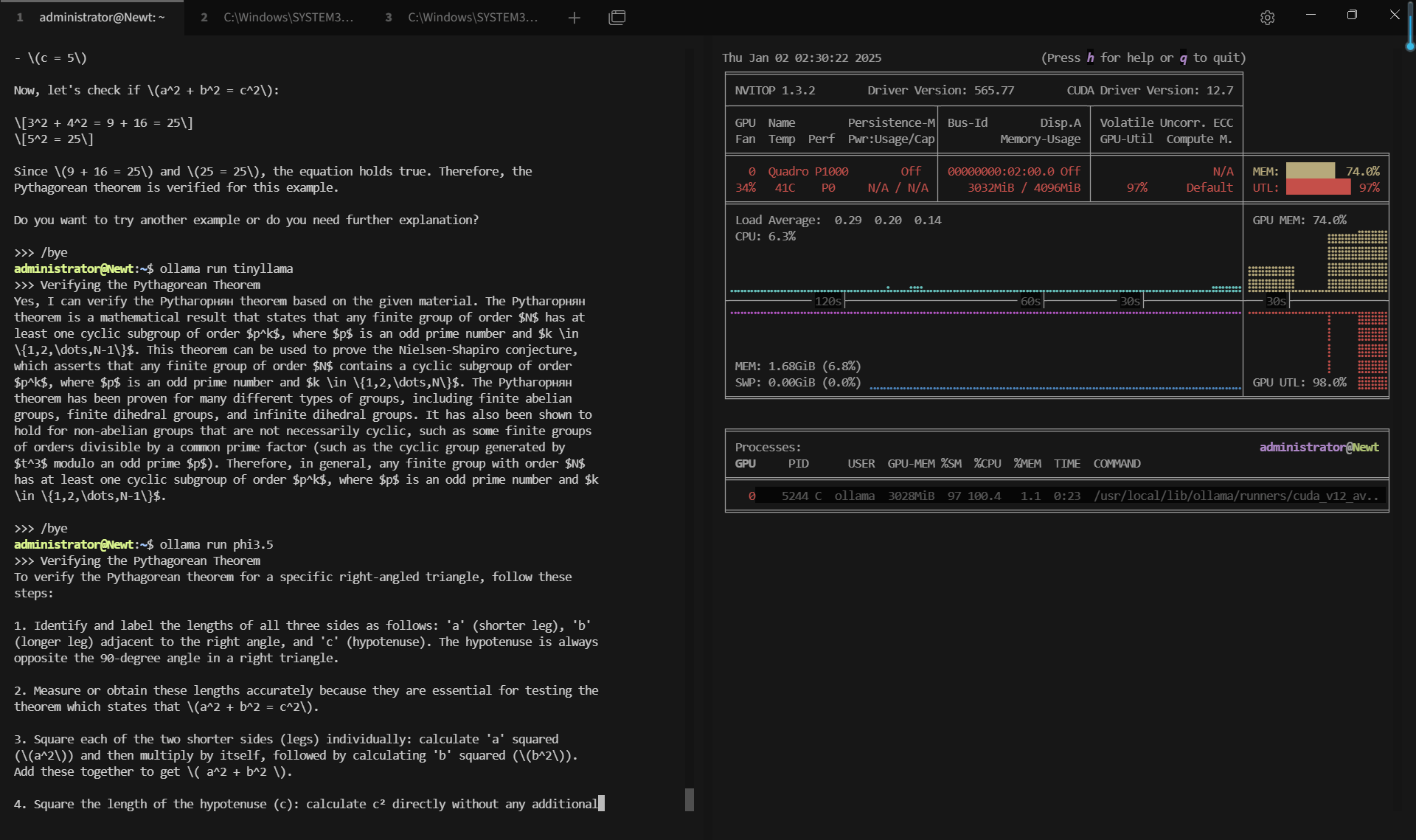
Benchmark Results: Ollama GPU P1000 Performance Metrics
| Models | llama3.2 | llama3.2 | gemma2 | codegemma | qwen2.5 | qwen2.5 | qwen2.5 | tinyllama | phi3.5 |
|---|---|---|---|---|---|---|---|---|---|
| Parameters | 1b | 3b | 2b | 2b | 0.5b | 1.5b | 3b | 1.1b | 3.8b |
| Size | 1.3GB | 2GB | 1.6GB | 1.6GB | 395MB | 1.1GB | 1.9GB | 638MB | 2.2GB |
| Quantization | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Running on | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 |
| Downloading Speed(mb/s) | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| CPU Rate | 6.7% | 6.3% | 6.3% | 6.3% | 6.5% | 6.3% | 6.3% | 6.4% | 6.4% |
| RAM Rate | 4.5% | 4.8% | 4.9% | 5.0% | 5.4% | 5.4% | 4.0% | 4.0% | 4.2% |
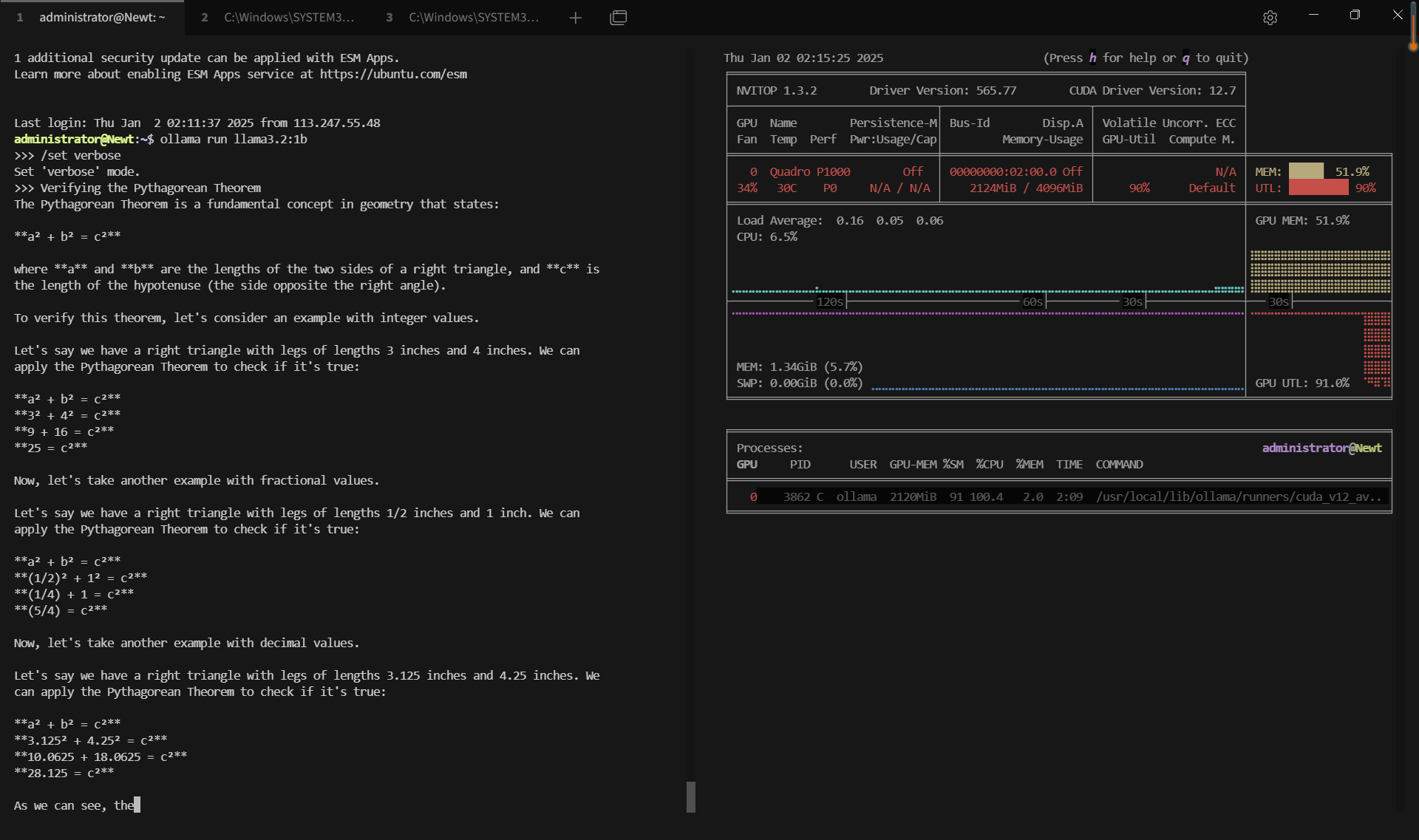
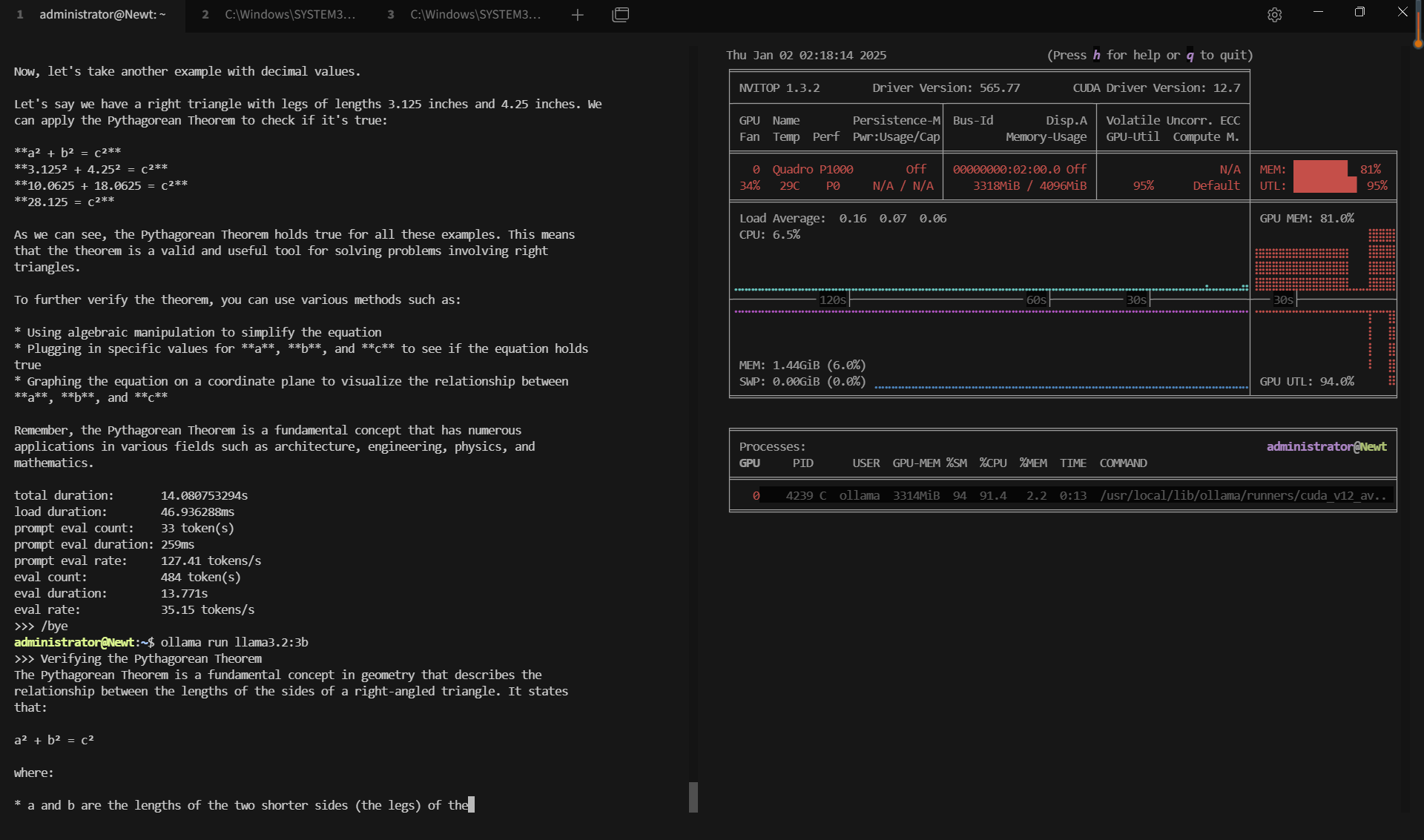
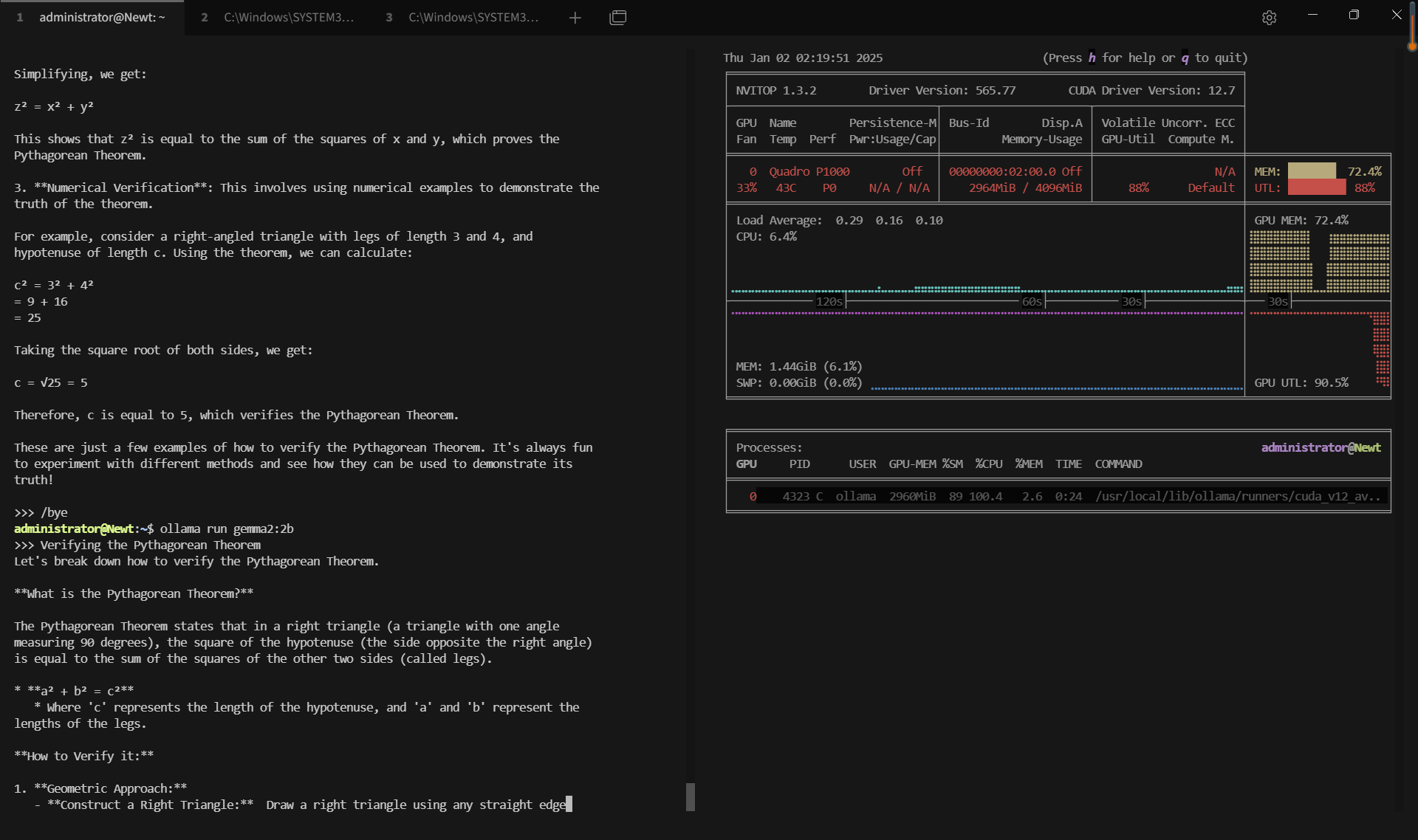
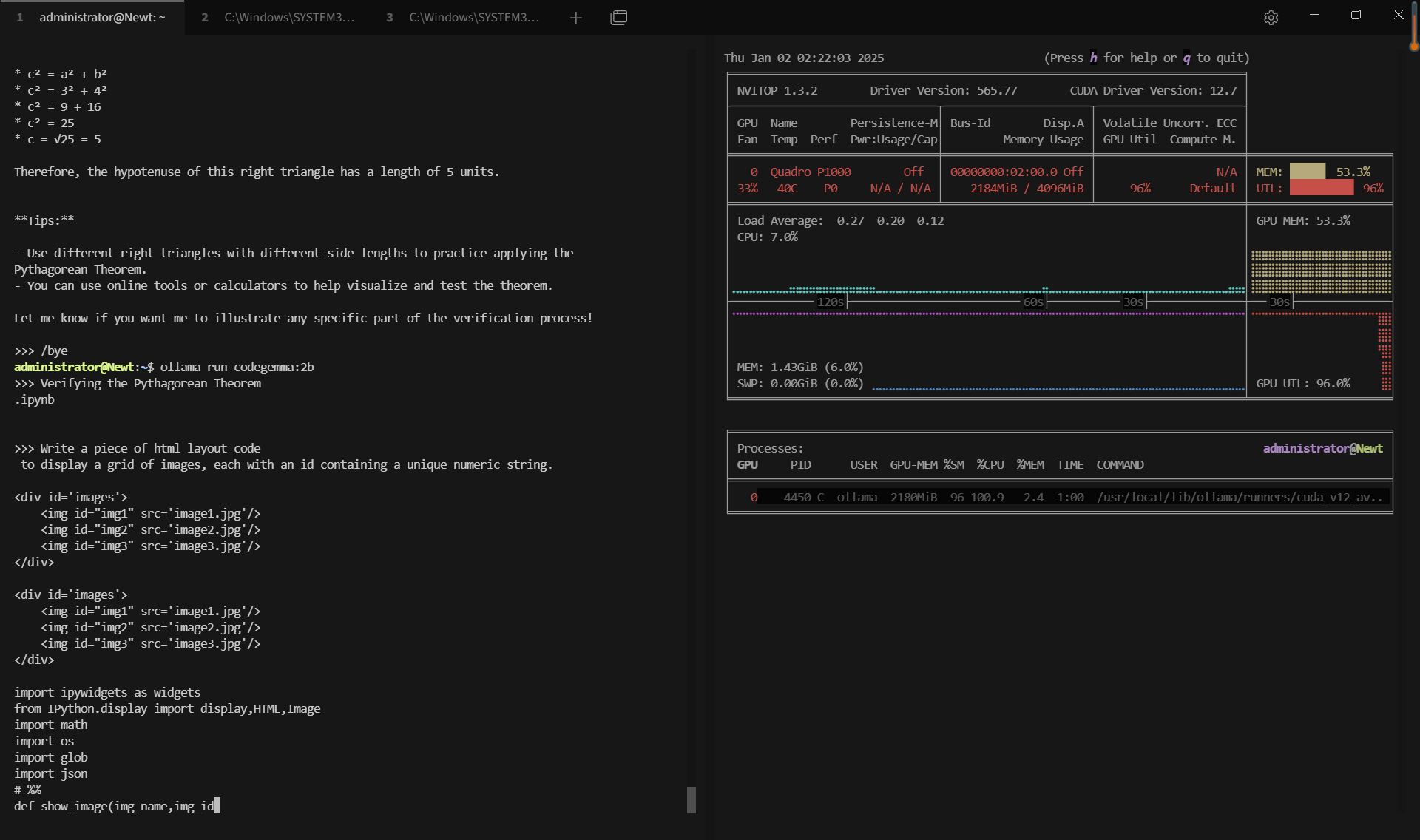
| GPU vRAM | 51.9% | 80.2% | 72.4% | 53.4% | 20% | 37.2% | 60.8% | 33.2% | 74% |
| GPU UTL | 92% | 95% | 89% | 96% | 80% | 89% | 95% | 93% | 97% |
| Eval Rate(tokens/s) | 28.90 | 19.97 | 19.46 | 30.59 | 54.78 | 34.43 | 17.92 | 62.33 | 18.87 |
Key Takeaways
1. Impressive GPU Efficiency on Limited Resources
2. Evaluation Rates Vary by Model Size
3. Minimal CPU and RAM Overheads
| Metric | Value for Various Models |
|---|---|
| Downloading Speed | 11 MB/s for all models |
| CPU Utilization Rate | Ranged from 6.3% to 6.7% across all models |
| RAM Utilization Rate | Consistently between 4% and 5.4% |
| GPU vRAM Utilization | 20% (Qwen2.5) to 80.2% (Llama3.2-3B) |
| GPU Utilization | Ranged from 89% to 97%, showcasing high GPU efficiency |
| Evaluation Speed | Spanned from 17.92 tokens/s (Qwen2.5) to 62.33 tokens/s (TinyLlama) |
Use Cases for P1000 GPU Servers with Ollama
- Edge AI Deployments: For businesses seeking cost-efficient deployment of AI applications on mid-range servers.
- LLM Testing and Prototyping: Developers can test different models under constrained GPU environments, gaining valuable insights into their behavior before scaling to larger infrastructure.
- Educational Purposes: Universities and labs can use such setups to train students or perform small-scale research projects on LLMs.
📢 Get Started with P1000 GPU Hosting for LLMs
Express GPU Dedicated Server - P1000
- 32GB RAM
- GPU: Nvidia Quadro P1000
- Eight-Core Xeon E5-2690
- 120GB + 960GB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Pascal
- CUDA Cores: 640
- GPU Memory: 4GB GDDR5
- FP32 Performance: 1.894 TFLOPS
Basic GPU Dedicated Server - T1000
- 64GB RAM
- GPU: Nvidia Quadro T1000
- Eight-Core Xeon E5-2690
- 120GB + 960GB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Turing
- CUDA Cores: 896
- GPU Memory: 8GB GDDR6
- FP32 Performance: 2.5 TFLOPS
Basic GPU Dedicated Server - GTX 1650
- 64GB RAM
- GPU: Nvidia GeForce GTX 1650
- Eight-Core Xeon E5-2667v3
- 120GB + 960GB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Turing
- CUDA Cores: 896
- GPU Memory: 4GB GDDR5
- FP32 Performance: 3.0 TFLOPS
Basic GPU Dedicated Server - GTX 1660
- 64GB RAM
- GPU: Nvidia GeForce GTX 1660
- Dual 8-Core Xeon E5-2660
- 120GB + 960GB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Turing
- CUDA Cores: 1408
- GPU Memory: 6GB GDDR6
- FP32 Performance: 5.0 TFLOPS
Conclusion: Optimizing Ollama for GPU Servers
This benchmark demonstrates that Ollama can efficiently leverage a Pascal-based Nvidia Quadro P1000 GPU, even under constrained memory conditions. While not designed for high-end data center applications, servers like this provide a practical solution for testing, development, and smaller-scale LLM deployments.
If you're considering deploying Ollama on similar hardware, ensure proper quantization settings and monitor GPU utilization to maximize throughput. For larger models or production use, upgrading to a GPU with higher memory capacity (e.g., 8GB or 16GB) will provide better performance.