

Performance Analysis: Running LLMs on Ollama with an RTX 3060 Ti GPU Server
In this article, we evaluate the performance of large language models (LLMs) running on Ollama 0.5.4 on a dedicated GPU server equipped with an NVIDIA GeForce RTX 3060 Ti. This setup is commonly sought after by AI enthusiasts and developers seeking an affordable yet powerful solution for hosting AI workloads. With 128GB of RAM and 24-core Xeon processors, this server promises excellent computational power for machine learning benchmarks and RTX 3060 hosting solutions.
Using popular LLMs like Llama 2, Mistral, and Falcon 2, we ran a series of Ollama benchmarks to assess GPU utilization, memory consumption, and inference speeds. If you're looking to understand how the RTX 3060 compares to other GPUs in LLM benchmarking, this review will provide actionable insights.
Hardware Introduction: RTX 3060 Ti Overview
Server Configuration:
- CPU: Dual 12-Core E5-2697v2 (24 Cores & 48 Threads)
- Memory: 128GB RAM
- Storage: 240GB SSD + 2TB SSD
- Network: 100Mbps-1Gbps
- Operating system: Windows
GPU Details:
- GPU:GeForce RTX 3060 Ti
- Microarchitecture: Ampere
- Compute Capability: 8.6
- CUDA cores: 4864
- Tensor Cores: 152
- vRAM: 8GB GDDR6
- FP32 performance: 16.2 TFLOPS
This GPU strikes a balance between cost and performance, making it ideal for AI workloads and gaming benchmarks alike. For LLM hosting, the 8GB VRAM is sufficient for running quantized models (4-bit precision), which drastically reduce memory requirements without significant loss in performance.
Results: LLM Benchmarking on Ollama
| Models | llama2 | llama2 | llama3.1 | mistral | gemma | gemma2 | llava | wizardlm2 | qwen2 | qwen2.5 | stablelm2 | falcon2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Parameters | 7b | 13b | 8b | 7b | 7b | 9b | 7b | 7b | 7b | 7b | 12b | 11b |
| Size(GB) | 3.8 | 7.4 | 4.9 | 4.1 | 5.0 | 5.4 | 4.7 | 4.1 | 4.4 | 4.7 | 7.0 | 6.4 |
| Quantization | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Running on | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 |
| Downloading Speed(mb/s) | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| CPU Rate | 2% | 27-42% | 3% | 3% | 20% | 21% | 3% | 3% | 3% | 3% | 15% | 8 |
| RAM Rate | 3% | 7% | 5% | 5% | 9% | 6% | 5% | 5% | 5% | 5% | 5% | 5% |
| GPU vRAM | 63% | 84% | 80% | 70% | 81% | 83% | 80% | 70% | 65% | 68% | 90% | 85% |
| GPU UTL | 98% | 30-40% | 98% | 88% | 93% | 68% | 98% | 100% | 98% | 96% | 90% | 80% |
| Eval Rate(tokens/s) | 73.07 | 9.25 | 57.34 | 71.16 | 31.95 | 23.80 | 72.00 | 70.79 | 63.73 | 58.13 | 18.73 | 31.20 |
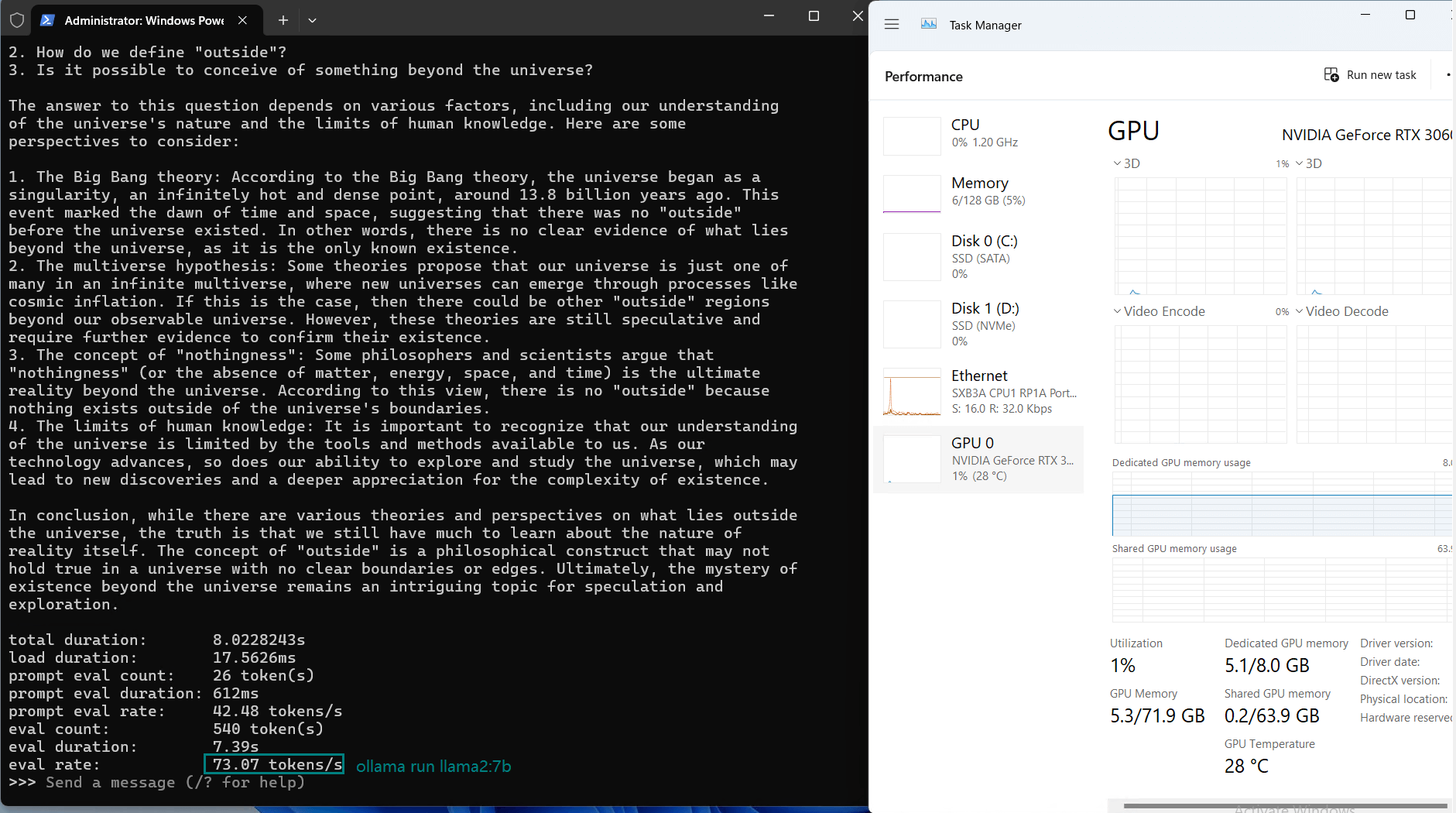
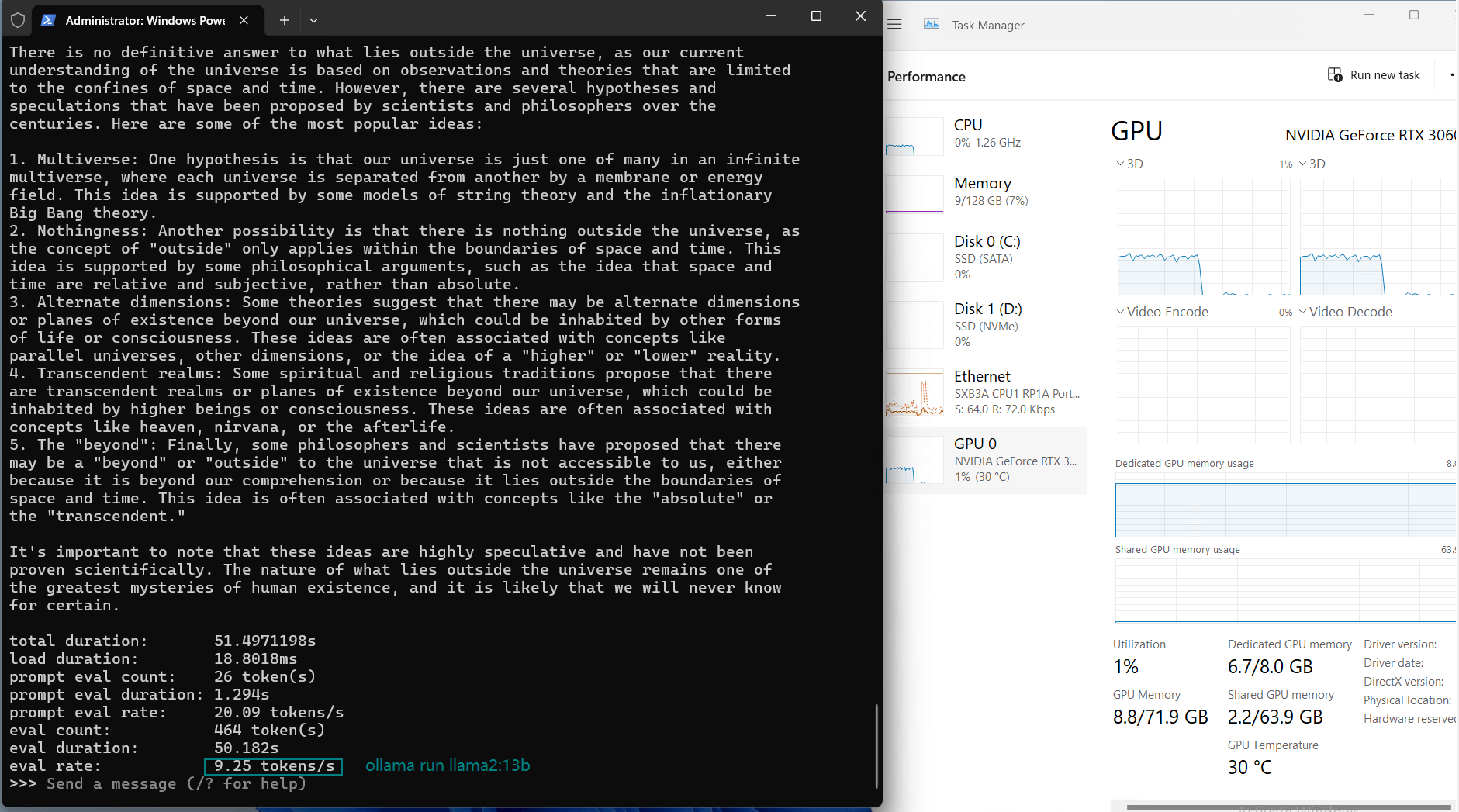
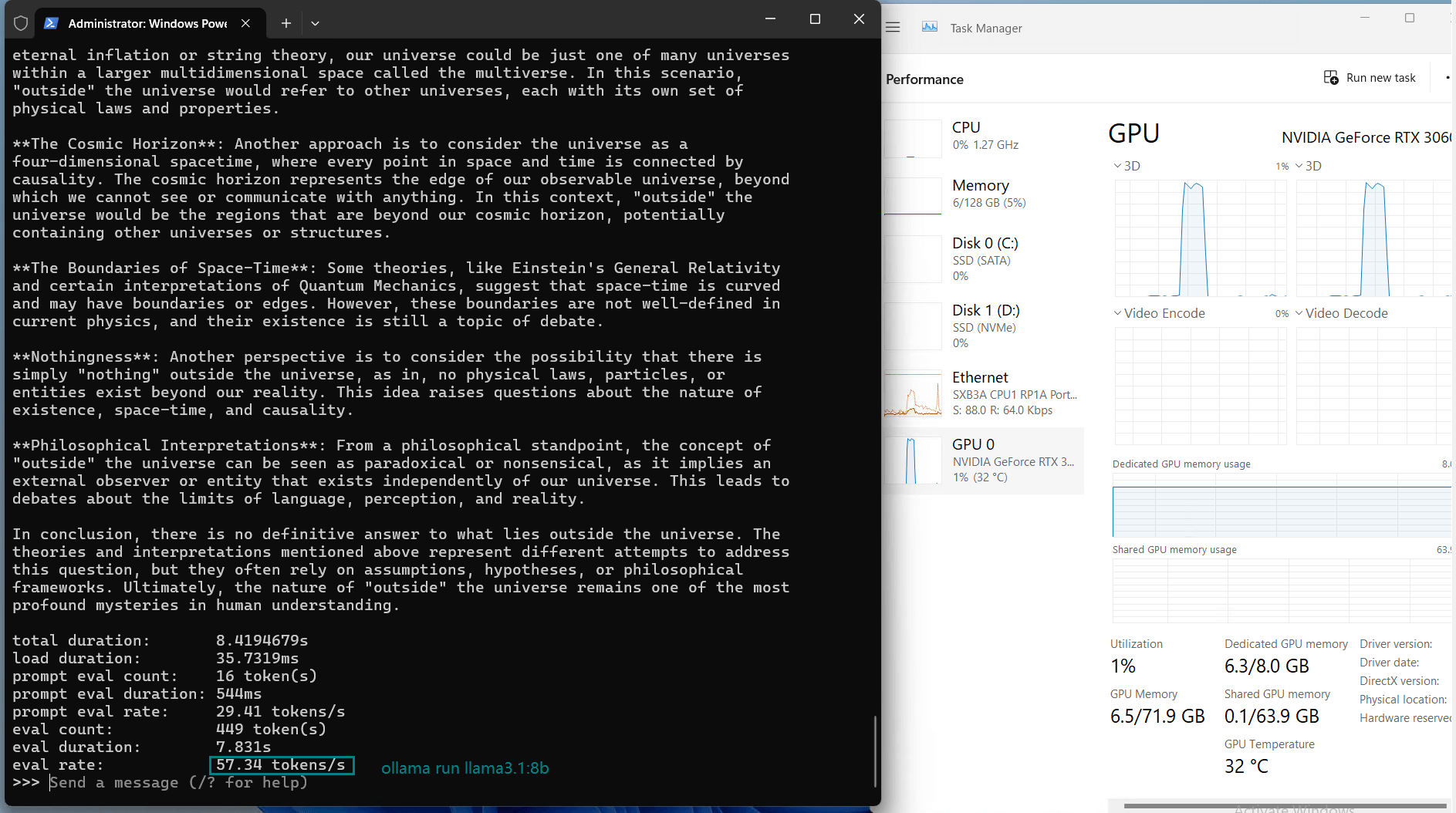
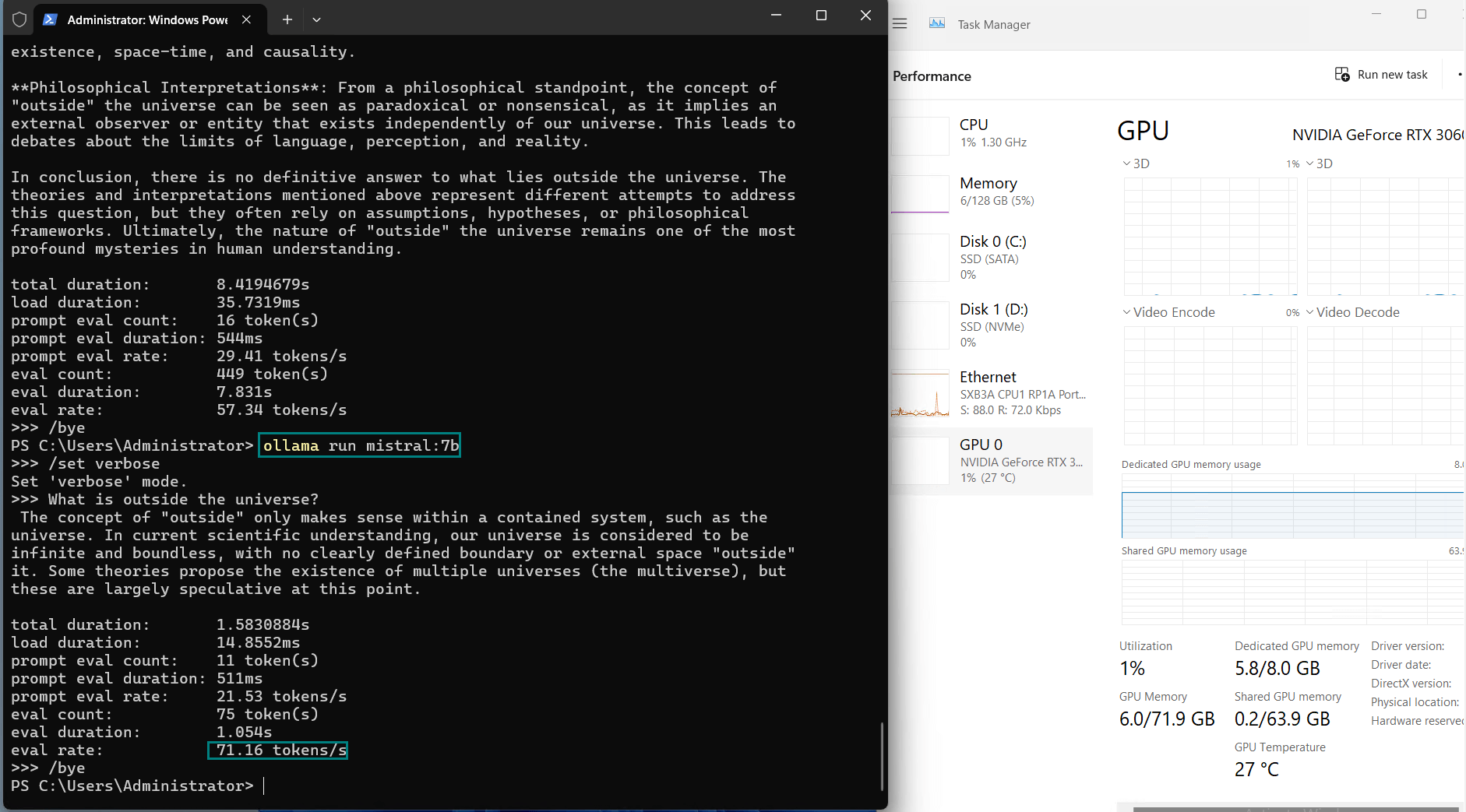
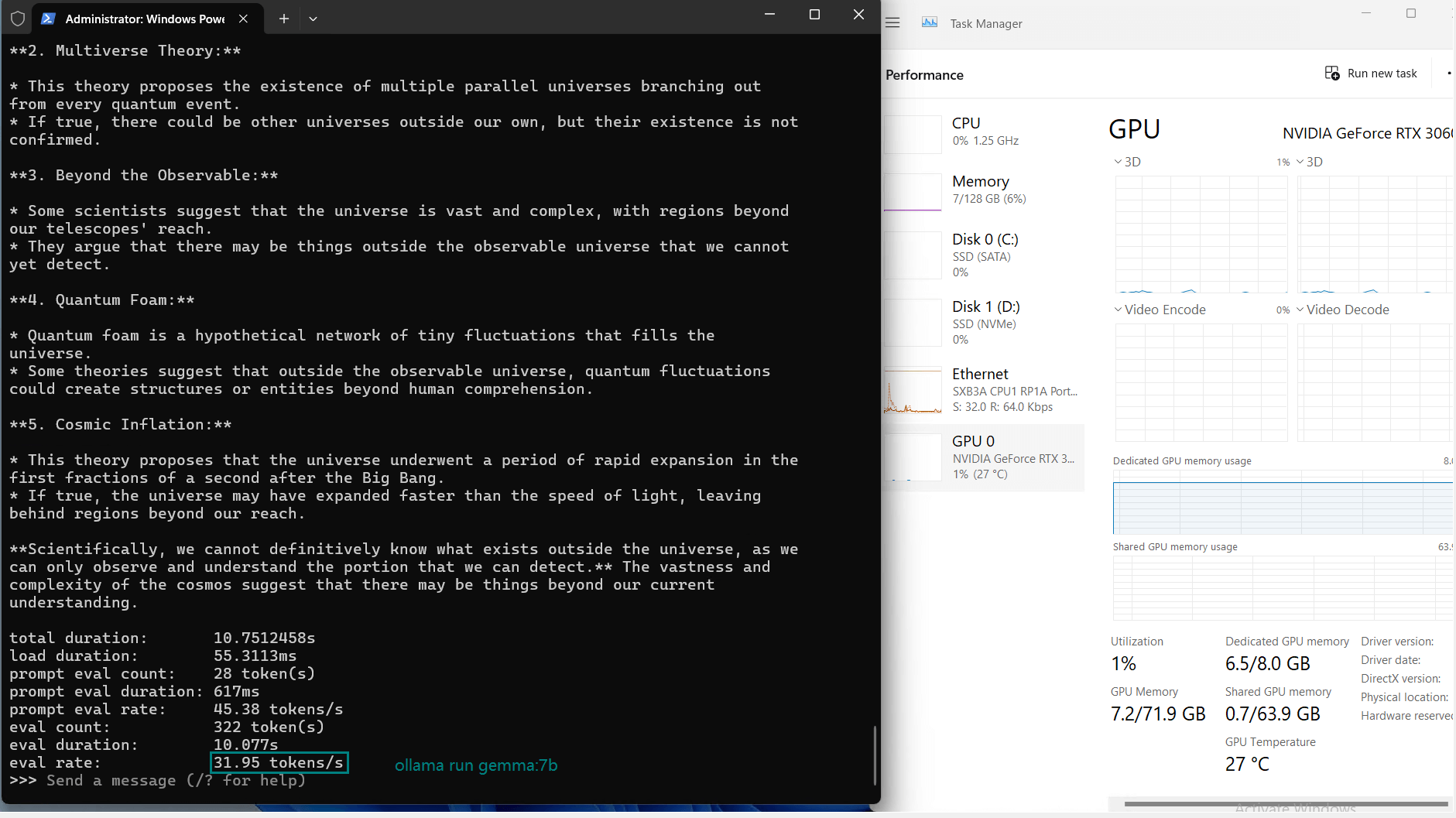
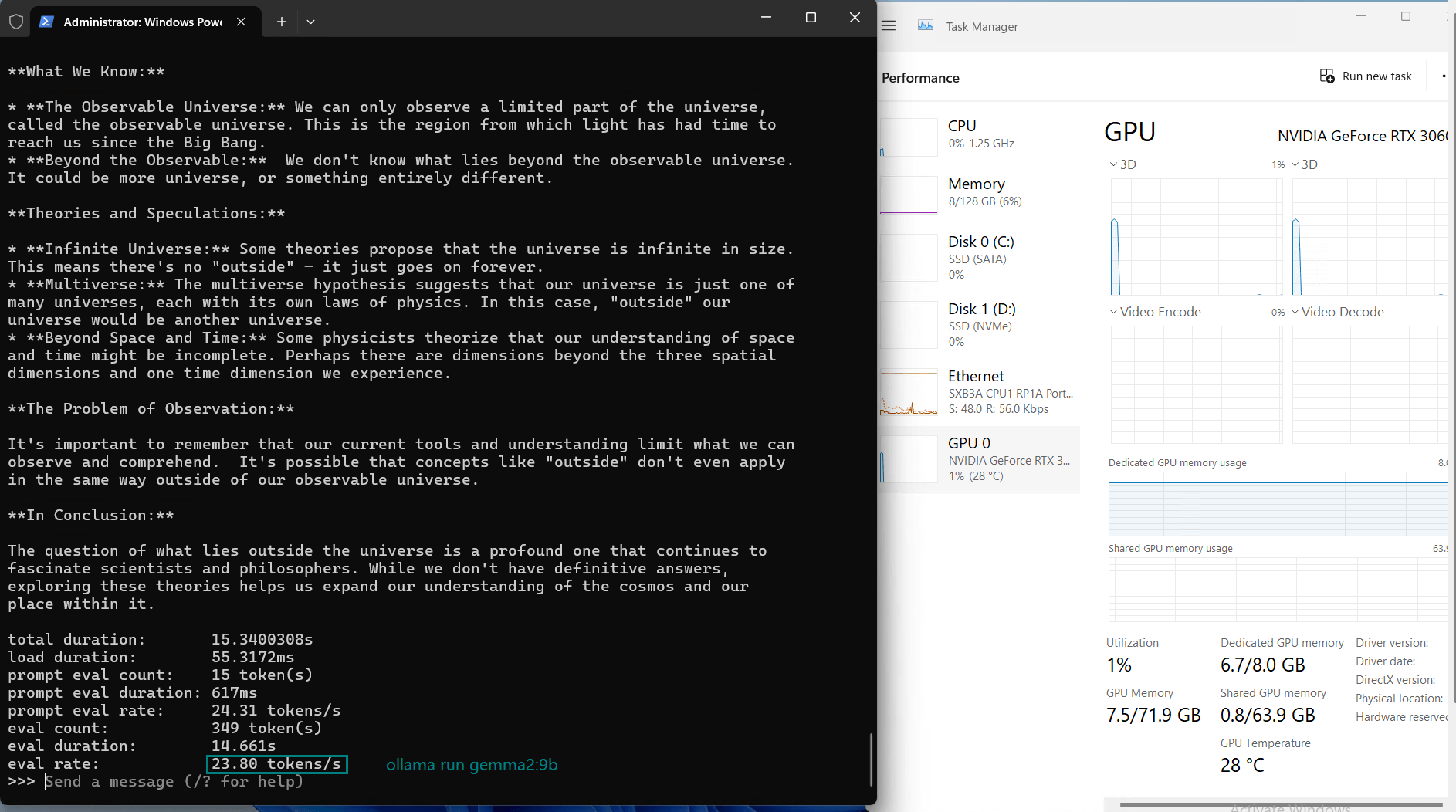
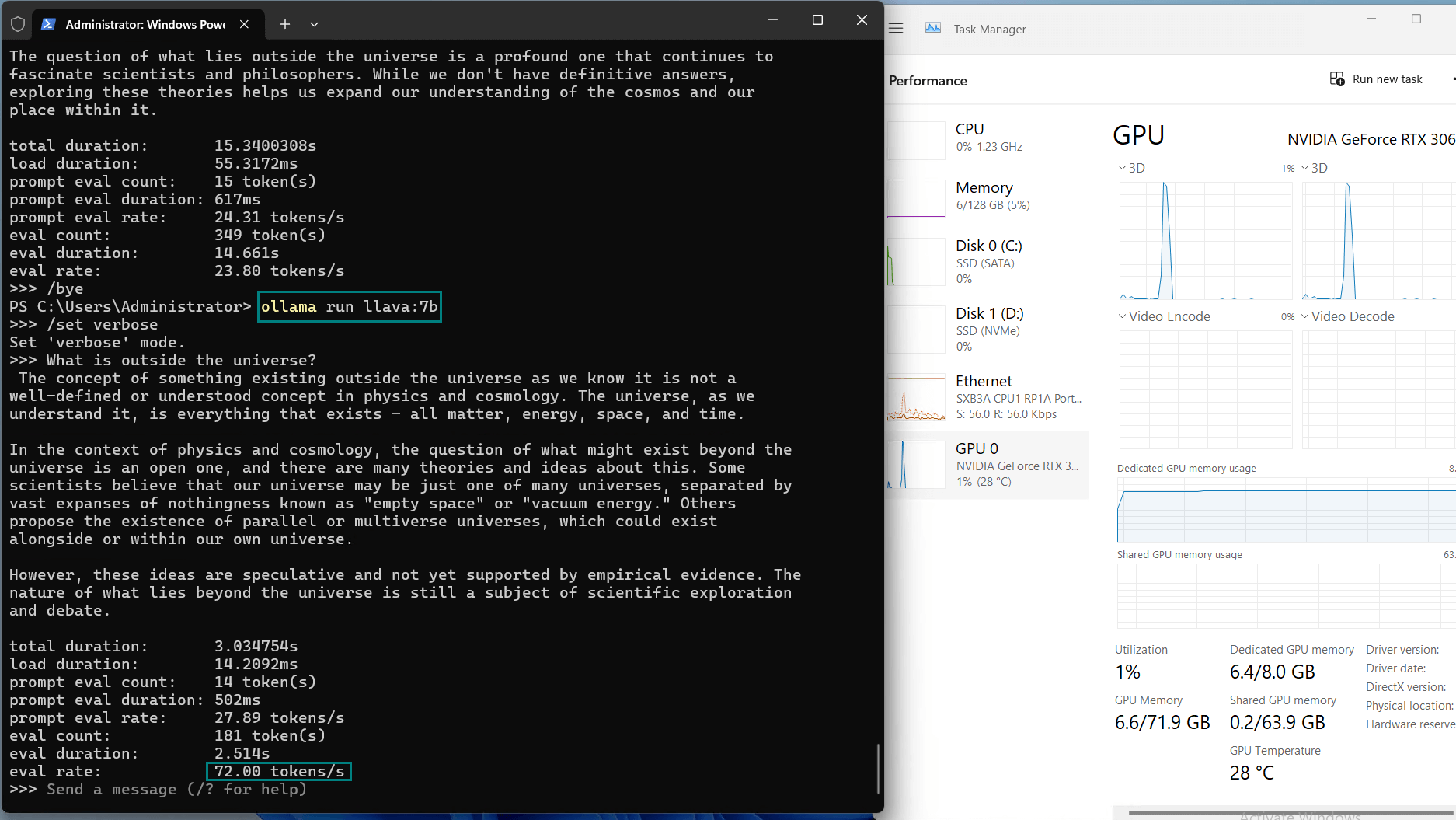
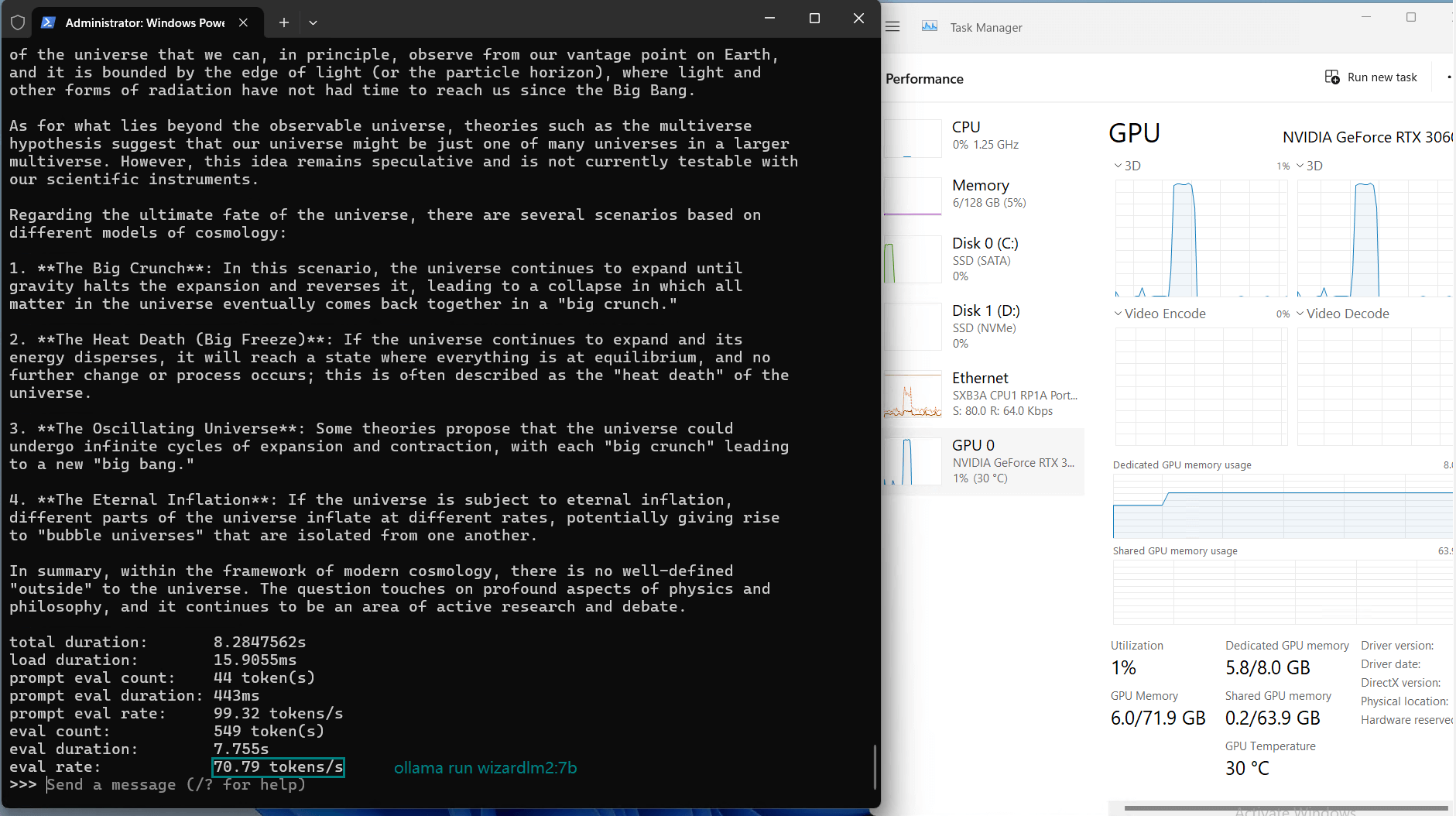
Observations on Nvidia RTX 3060 Ti Server
1. Efficiency of Smaller Models
2. Challenges with Larger Models
3. Quantization is Essential
4. CPU and RAM Usage
Get Started with RTX 3060 Ti Server
Basic GPU Dedicated Server - T1000
- 64GB RAM
- GPU: Nvidia Quadro T1000
- Eight-Core Xeon E5-2690
- 120GB + 960GB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Turing
- CUDA Cores: 896
- GPU Memory: 8GB GDDR6
- FP32 Performance: 2.5 TFLOPS
Advanced GPU Dedicated Server - RTX 3060 Ti
- 128GB RAM
- GPU: GeForce RTX 3060 Ti
- Dual 12-Core E5-2697v2
- 240GB SSD + 2TB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 4864
- Tensor Cores: 152
- GPU Memory: 8GB GDDR6
- FP32 Performance: 16.2 TFLOPS
Enterprise GPU Dedicated Server - RTX 4090
- 256GB RAM
- GPU: GeForce RTX 4090
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ada Lovelace
- CUDA Cores: 16,384
- Tensor Cores: 512
- GPU Memory: 24 GB GDDR6X
- FP32 Performance: 82.6 TFLOPS
Enterprise GPU Dedicated Server - RTX A6000
- 256GB RAM
- GPU: Nvidia Quadro RTX A6000
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 10,752
- Tensor Cores: 336
- GPU Memory: 48GB GDDR6
- FP32 Performance: 38.71 TFLOPS
Conclusion: Is RTX 3060 Ti Good for LLM Hosting?
The RTX 3060 Ti proves to be a cost-effective choice for LLM benchmarks, especially when paired with Ollama's efficient quantization. For tasks involving models under 13 billion parameters, this setup offers competitive performance, high efficiency, and low resource consumption. If you're searching for an affordable RTX 3060 hosting solution to run LLMs on Ollama, this GPU delivers solid results without breaking the bank.
- Run small and mid-sized large language models (4B-12B parameters).
- Developers want to test the reasoning capabilities of LLM with low power consumption.
- The budget is limited but high performance GPU Dedicated Server is required.
RTX 3060 benchmark, Ollama benchmark, LLM benchmark, Ollama test, Nvidia RTX 3060 benchmark, Ollama 3060, RTX 3060 Hosting, Ollama RTX Server