

Ollama Benchmark: Performance of Running LLMs on Nvidia T1000 GPU Server
With the popularity of large language models (LLMs), more and more developers and researchers want to run these models on local or cloud servers. With P1000's Turing microarchitecture and 8GB of GDDR6 GPU memory, the Quadro T1000 delivers an FP32 performance of 2.5 TFLOPS, making it a viable option for AI workloads. In this article, we will benchmark the performance of various LLMs running on the Ollama platform, leveraging the Nvidia Quadro T1000 GPU.
Hardware Overview: GPU Dedicated Server - T1000
Server Configuration:
- Price: $99.00/month
- CPU: Eight-core Xeon E5-2690
- Memory: 64GB RAM
- Storage: 120GB + 960GB SSD
- Network: 100Mbps-1Gbps
- Operating system: Windows
GPU Details:
- GPU:Nvidia Quadro T1000
- Microarchitecture: Turing
- CUDA cores: 896
- Video memory: 8GB GDDR6
- FP32 performance: 2.5 TFLOPS
This configuration has a good price/performance ratio for running Ollama and similar large language models, especially the performance of the graphics card Nvidia Quadro T1000 in computationally intensive tasks is worth exploring.
Tested Several Mainstream LLMs
- Llama2 (7B)
- Llama3.1 (8B)
- Mistral (7B)
- Gemma (7B, 9B)
- Llava (7B)
- WizardLM2 (7B)
- Qwen (4B, 7B)
- Nemotron-Mini (4B)
Benchmark Results: Ollama GPU T1000 Performance Metrics
| Models | llama2 | llama3.1 | mistral | gemma | gemma2 | llava | wizardlm2 | qwen | qwen2 | qwen2.5 | nemotron-mini |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Parameters | 7b | 8b | 7b | 7b | 9b | 7b | 7b | 4b | 7b | 7b | 4b |
| Size(GB) | 3.8 | 4.9 | 4.1 | 5.0 | 5.4 | 4.7 | 4.1 | 2.3 | 4.4 | 4.7 | 2.7 |
| Quantization | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Running on | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 |
| Downloading Speed(mb/s) | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| CPU Rate | 8% | 8% | 7% | 23% | 20% | 8% | 8% | 6% | 8% | 8% | 9% |
| RAM Rate | 8% | 7% | 7% | 9% | 9% | 7% | 7% | 8% | 8% | 8% | 8% |
| GPU vRAM | 63% | 80% | 71% | 81% | 83% | 79% | 70% | 72% | 65% | 65% | 50% |
| GPU UTL | 98% | 98% | 97% | 90% | 96% | 98% | 98% | 95% | 96% | 99% | 97% |
| Eval Rate(tokens/s) | 26.55 | 21.51 | 23.79 | 15.78 | 12.83 | 26.70 | 17.51 | 37.64 | 24.02 | 21.08 | 34.91 |
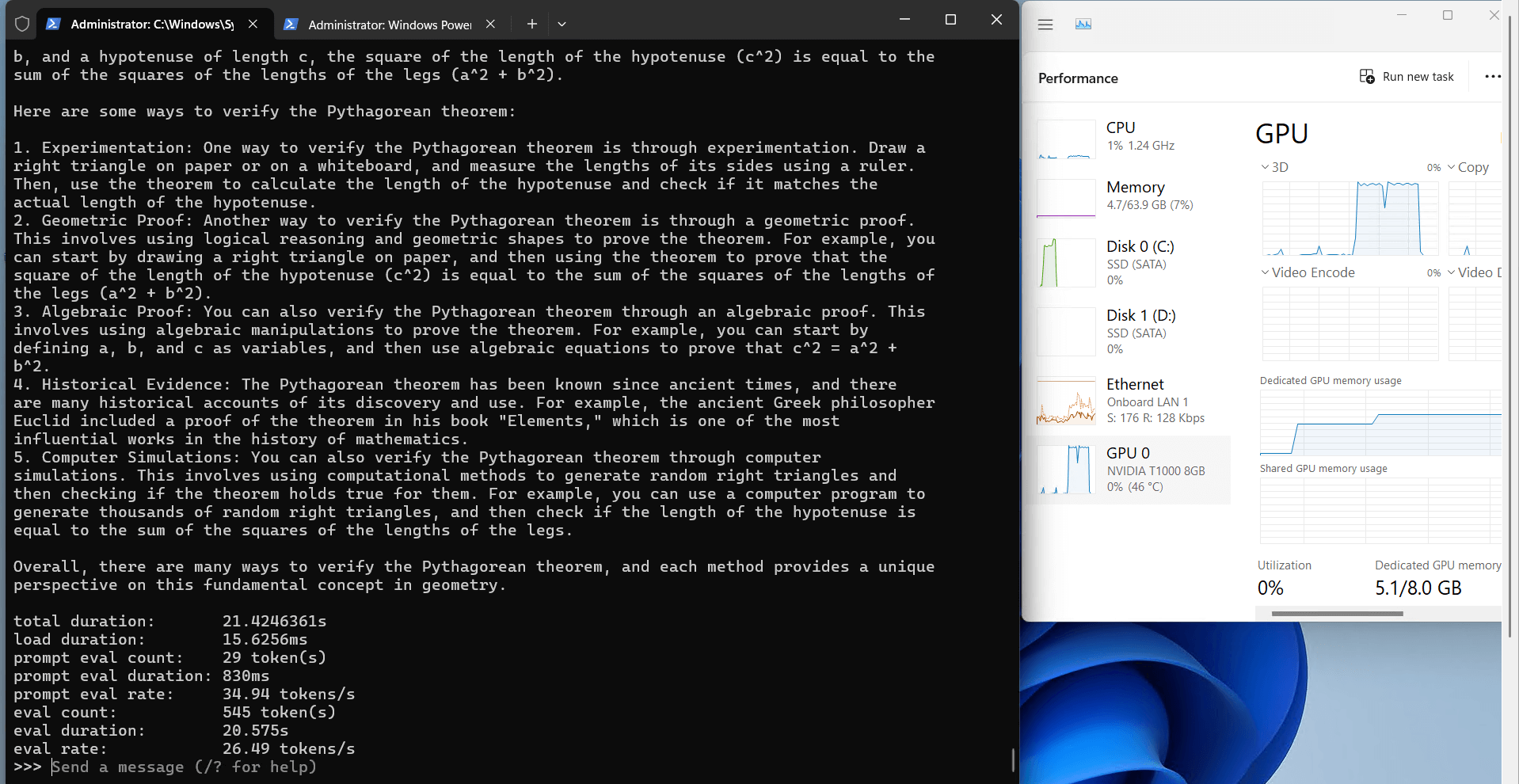
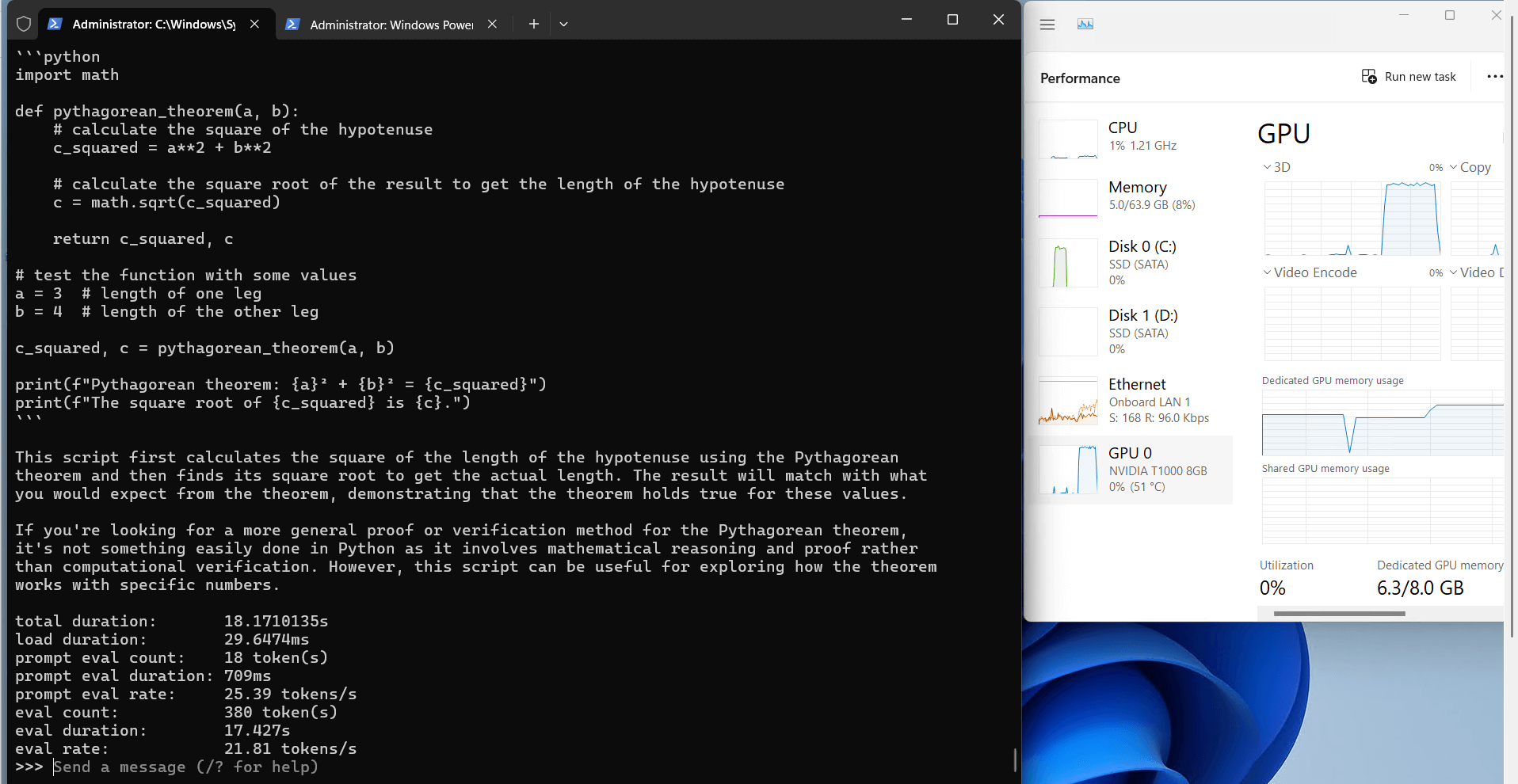
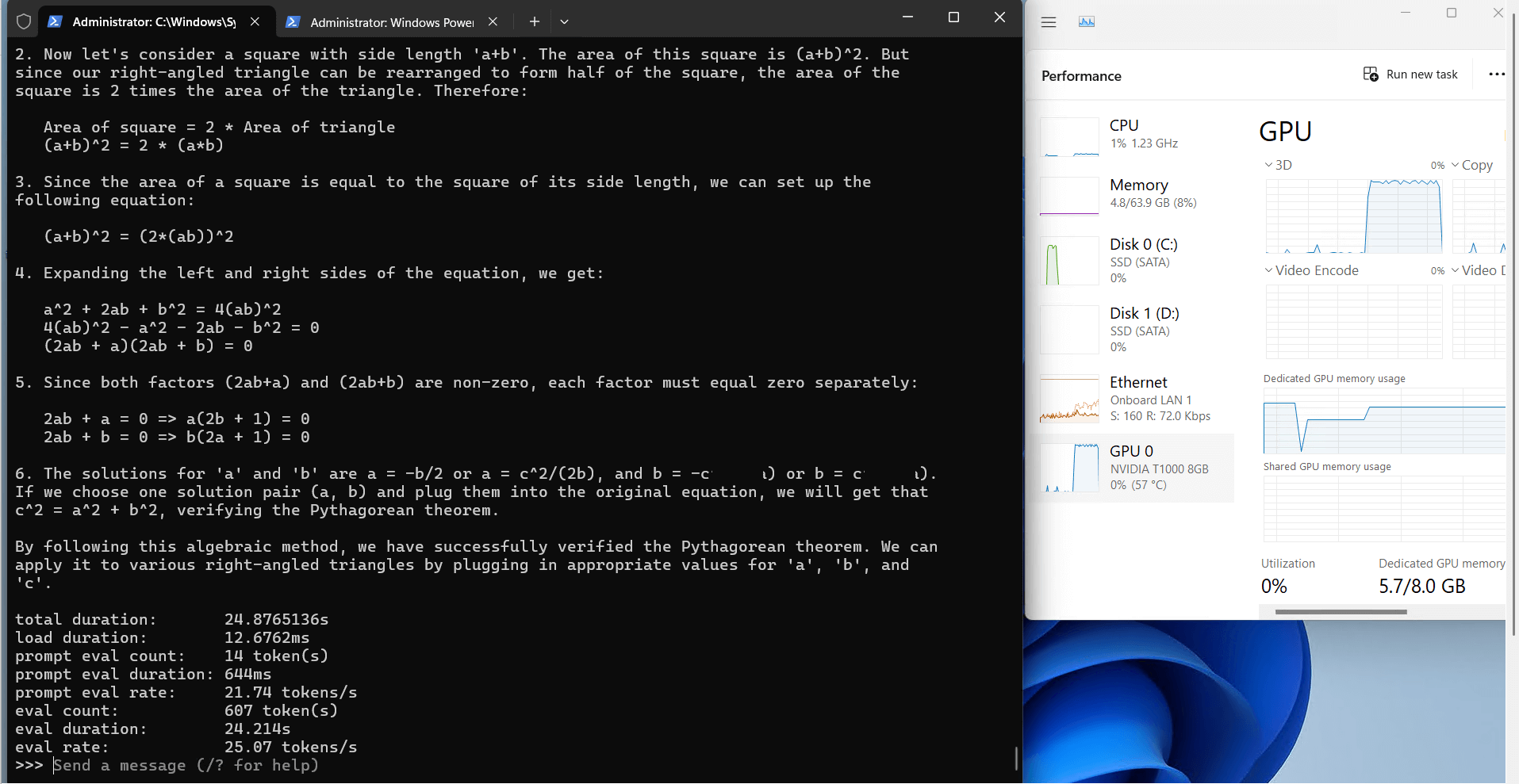
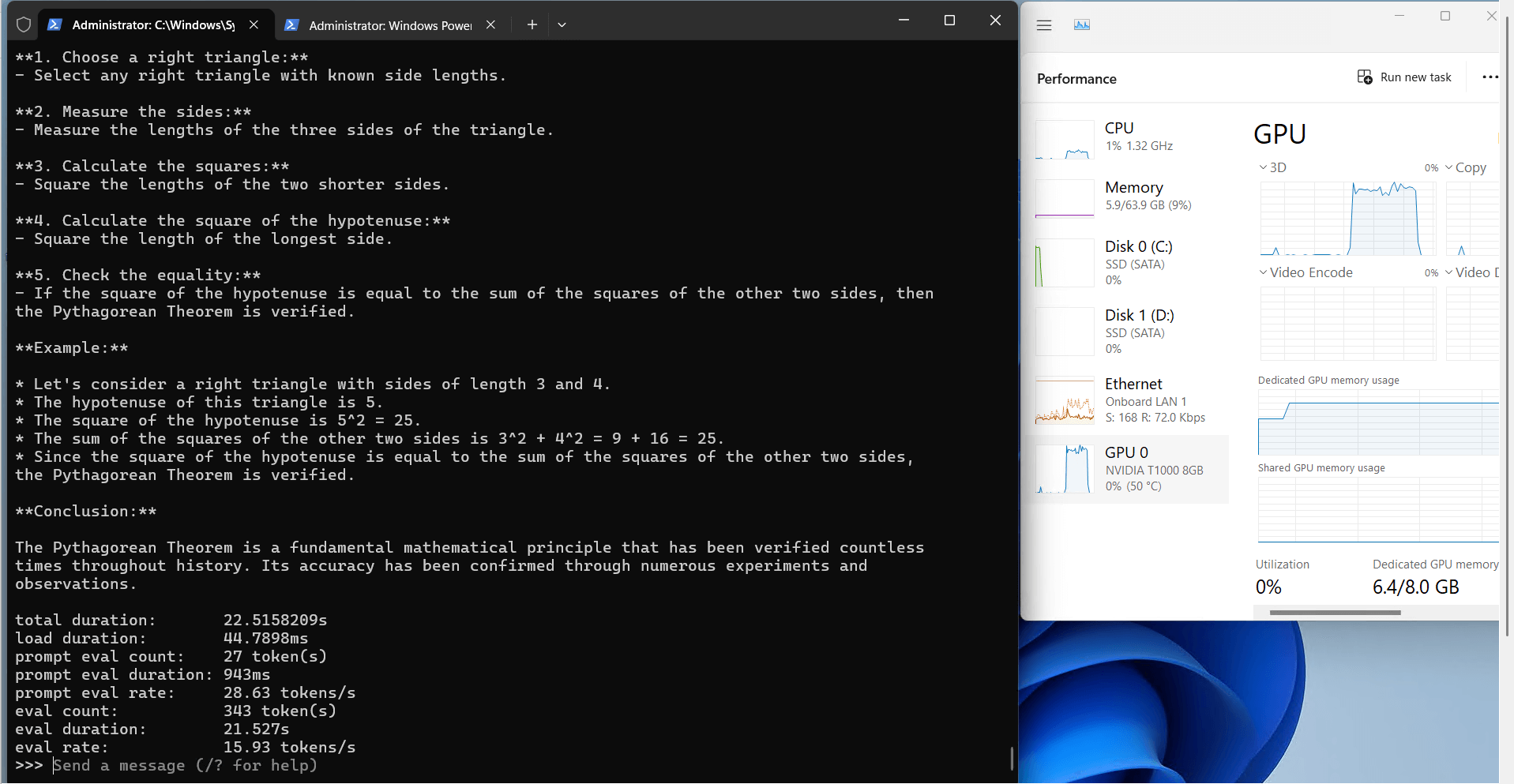
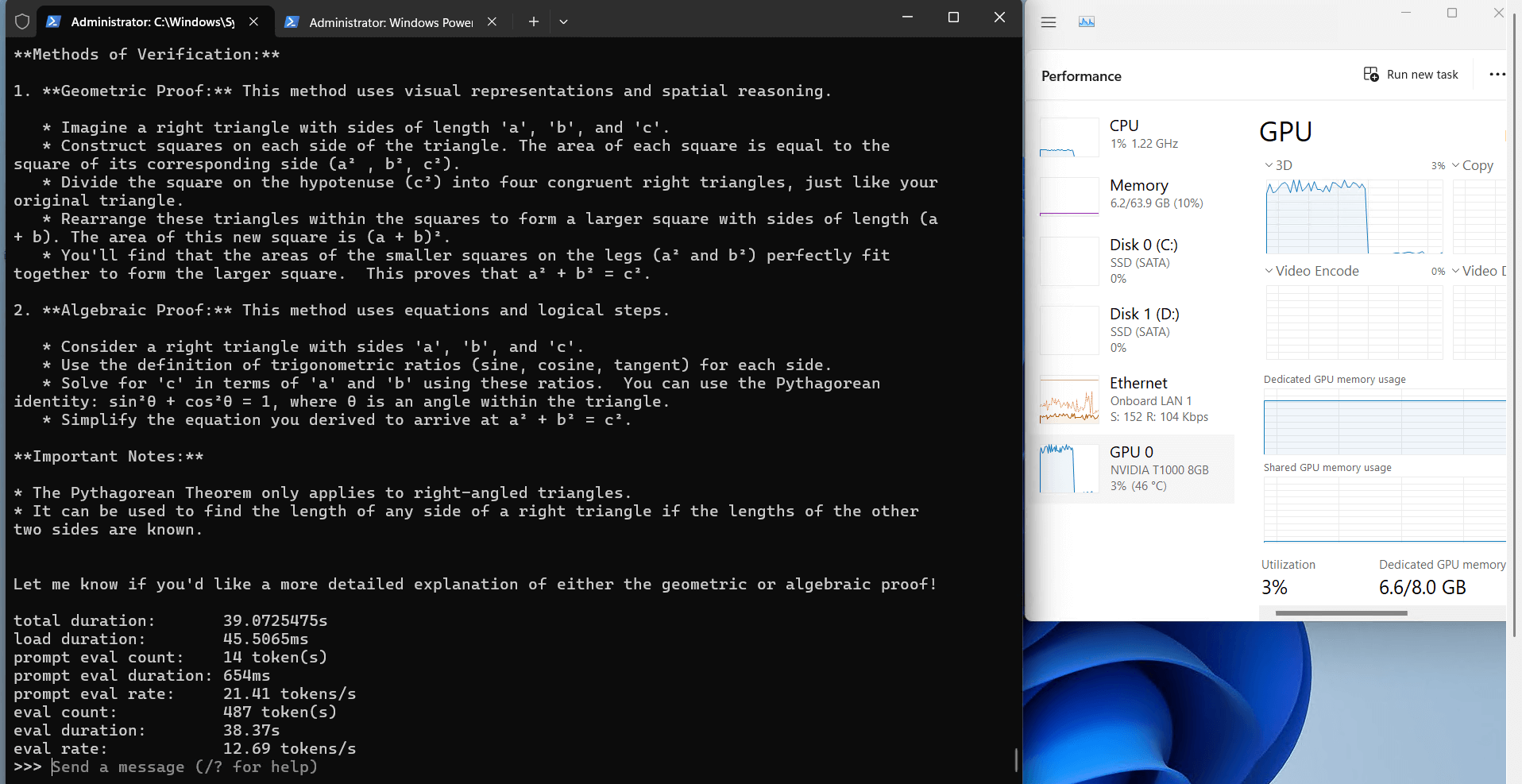
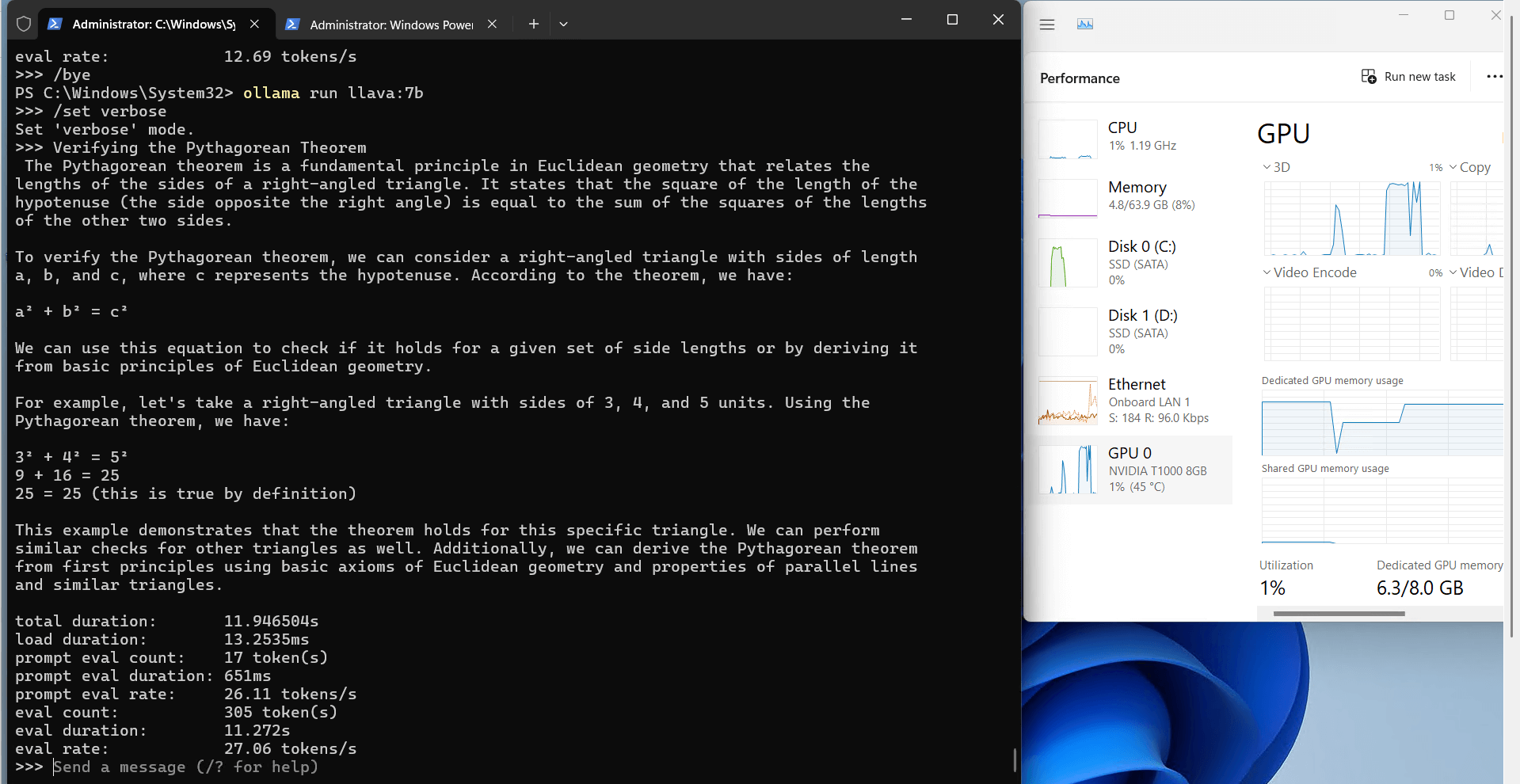
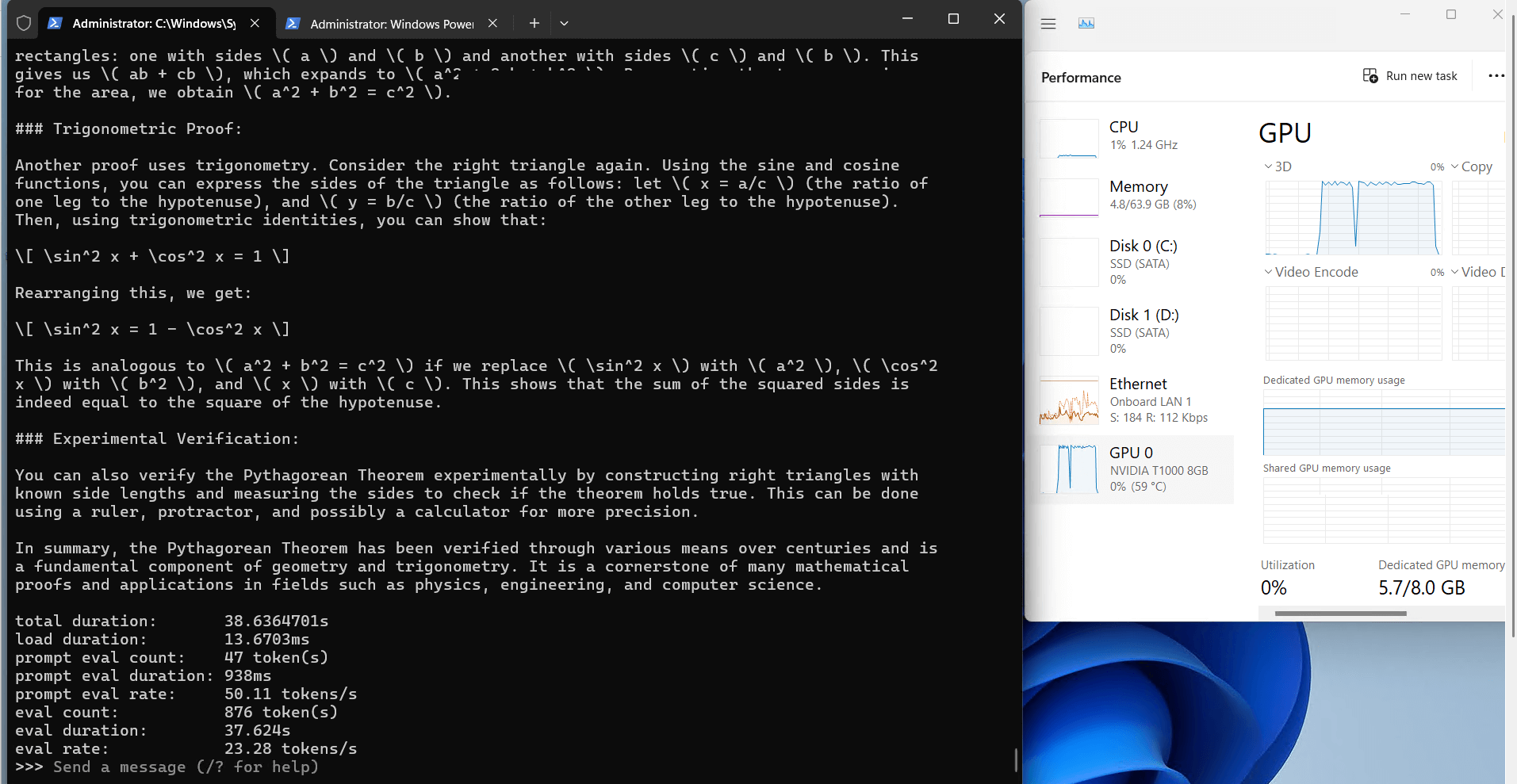
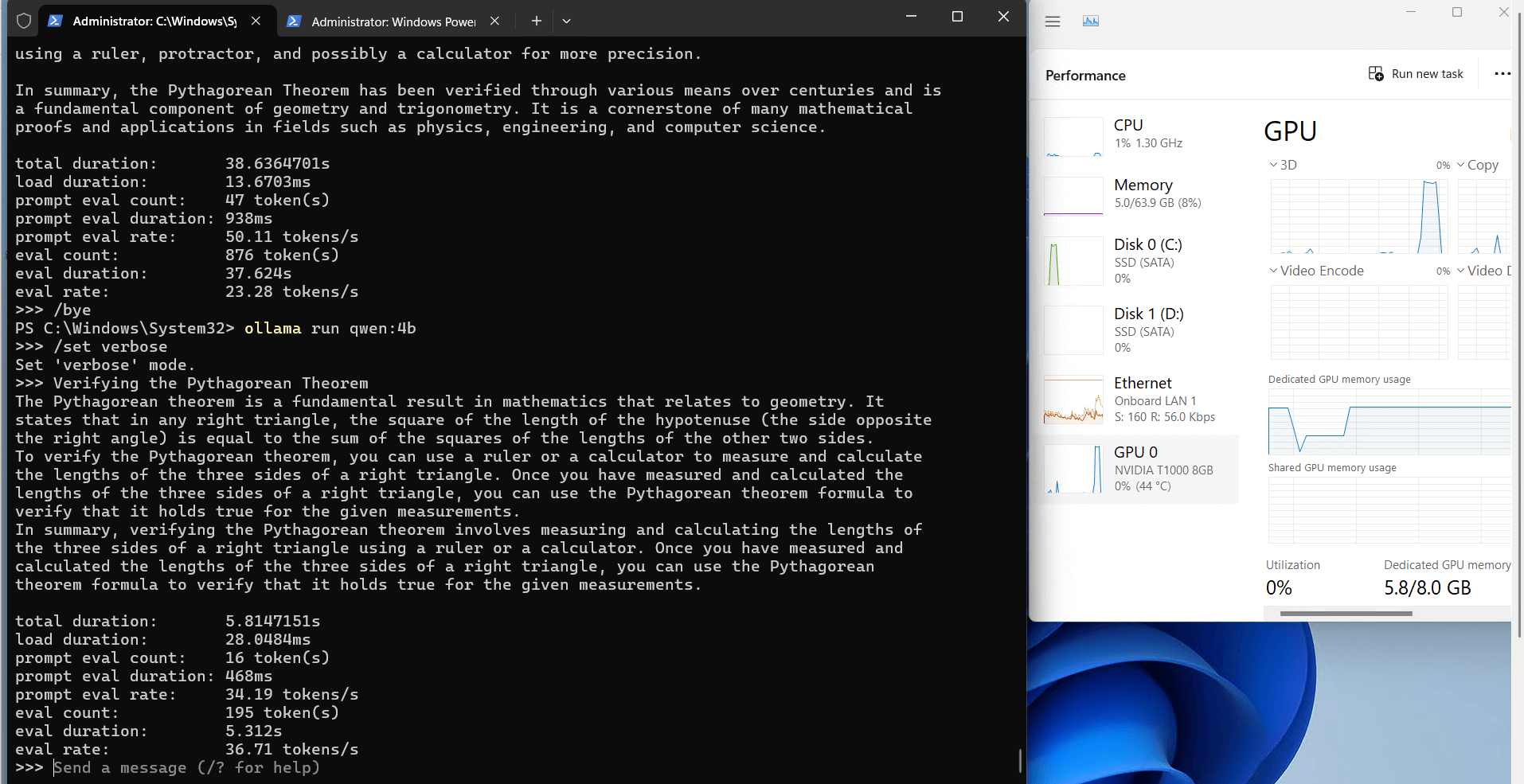
Ollama's Performance Analysis on Nvidia T1000
1. The 8GB video
2. Computational Efficiency
3. Resource Utilization
3. Speed Performance
| Metric | Value for Various Models |
|---|---|
| Downloading Speed | 11 MB/s for all models, 118 MB/s When a 1gbps bandwidth add-on ordered. |
| CPU Utilization Rate | Average 8% |
| RAM Utilization Rate | Average 7-9% |
| GPU vRAM Utilization | 63%-83% |
| GPU Utilization | 95%-99% |
| Evaluation Speed | 12.83 - 37.64 tokens/s |
Comparison with Other Graphics Cards
Basic GPU Dedicated Server - T1000
- 64GB RAM
- GPU: Nvidia Quadro T1000
- Eight-Core Xeon E5-2690
- 120GB + 960GB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Turing
- CUDA Cores: 896
- GPU Memory: 8GB GDDR6
- FP32 Performance: 2.5 TFLOPS
Basic GPU Dedicated Server - GTX 1660
- 64GB RAM
- GPU: Nvidia GeForce GTX 1660
- Dual 8-Core Xeon E5-2660
- 120GB + 960GB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Turing
- CUDA Cores: 1408
- GPU Memory: 6GB GDDR6
- FP32 Performance: 5.0 TFLOPS
Advanced GPU Dedicated Server - RTX 3060 Ti
- 128GB RAM
- GPU: GeForce RTX 3060 Ti
- Dual 12-Core E5-2697v2
- 240GB SSD + 2TB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 4864
- Tensor Cores: 152
- GPU Memory: 8GB GDDR6
- FP32 Performance: 16.2 TFLOPS
Enterprise GPU Dedicated Server - A100
- 256GB RAM
- GPU: Nvidia A100
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 40GB HBM2
- FP32 Performance: 19.5 TFLOPS
- 50% Off First Month, 30% Off Renewals
Summary and Recommendations
This review shows that Nvidia Quadro T1000 is one of the most cost-effective GPUs for running Ollama, especially suitable for the following scenarios:
- Run small and medium-sized large language models (4B-9B parameters).
- Developers want to test the reasoning capabilities of LLM with low power consumption.
- The budget is limited but high performance GPU Dedicated Server is required.
Ollama GPU Performance, Ollama benchmark, Nvidia T1000 benchmark, Nvidia Quadro T1000 benchmark, Ollama T1000, GPU Dedicated Server T1000, Ollama test, Llama2 benchmark, Qwen benchmark, T1000 AI performance, T1000 LLM test, Nvidia T1000 AI tasks, running LLMs on T1000, affordable GPU for LLM.