

Benchmarking Large Language Models (LLMs) on Ollama with an NVIDIA V100 GPU Server
With the rising demand for LLM inference and AI model deployment, finding the best GPU hosting solution is crucial. The NVIDIA V100 server is a popular choice for LLM reasoning due to its balance of compute power, affordability, and availability. In this benchmark, we test various LLMs on Ollama running on an NVIDIA V100 (16GB) GPU server, analyzing performance metrics such as token evaluation rate, GPU utilization, and resource consumption.
Test Server Configuration
Server Configuration:
- Price: $229.00/month
- CPU: Dual 12-Core E5-2690v3 (24 cores & 48 threads)
- RAM: 128GB
- Storage: 240GB SSD + 2TB SSD
- Network: 100Mbps
- OS: Windows
GPU Details:
- GPU: NVIDIA V100 16GB
- Compute Capability 7.0
- Microarchitecture: Volta
- CUDA Cores: 5,120
- Tensor Cores: 640
- GPU Memory: 16GB HBM2
- FP32 Performance: 14 TFLOPS
This NVIDIA V100 hosting setup ensures an optimal balance between cost and performance, making it a great option for AI hosting, deep learning, and LLM deployment.
Benchmarking LLMs on Ollama with NVIDIA V100 Server
| Models | deepseek-r1 | deepseek-r1 | deepseek-r1 | deepseek-coder-v2 | llama2 | llama2 | llama3.1 | mistral | gemma2 | gemma2 | qwen2.5 | qwen2.5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Parameters | 7b | 8b | 14b | 16b | 7b | 13b | 8b | 7b | 9b | 27b | 7b | 14b |
| Size(GB) | 4.7 | 4.9 | 9 | 8.9 | 3.8 | 7.4 | 4.9 | 4.1 | 5.4 | 16 | 4.7 | 9.0 |
| Quantization | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Running on | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 |
| Downloading Speed(mb/s) | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| CPU Rate | 2% | 2% | 3% | 3% | 2% | 3% | 3% | 3% | 3% | 42% | 3% | 3 |
| RAM Rate | 5% | 6% | 5% | 5% | 5% | 5% | 5% | 6% | 6% | 7% | 5% | 6% |
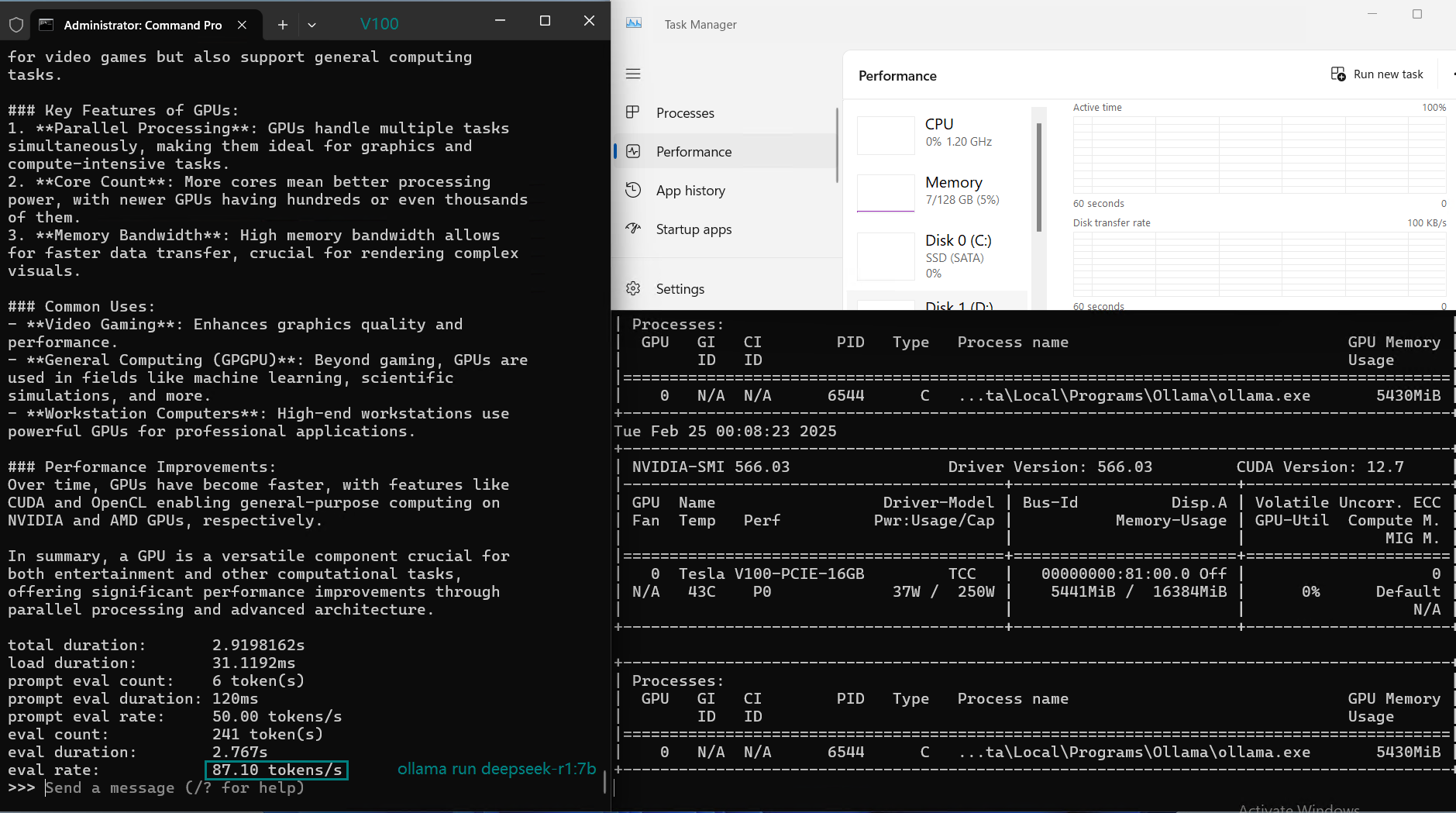
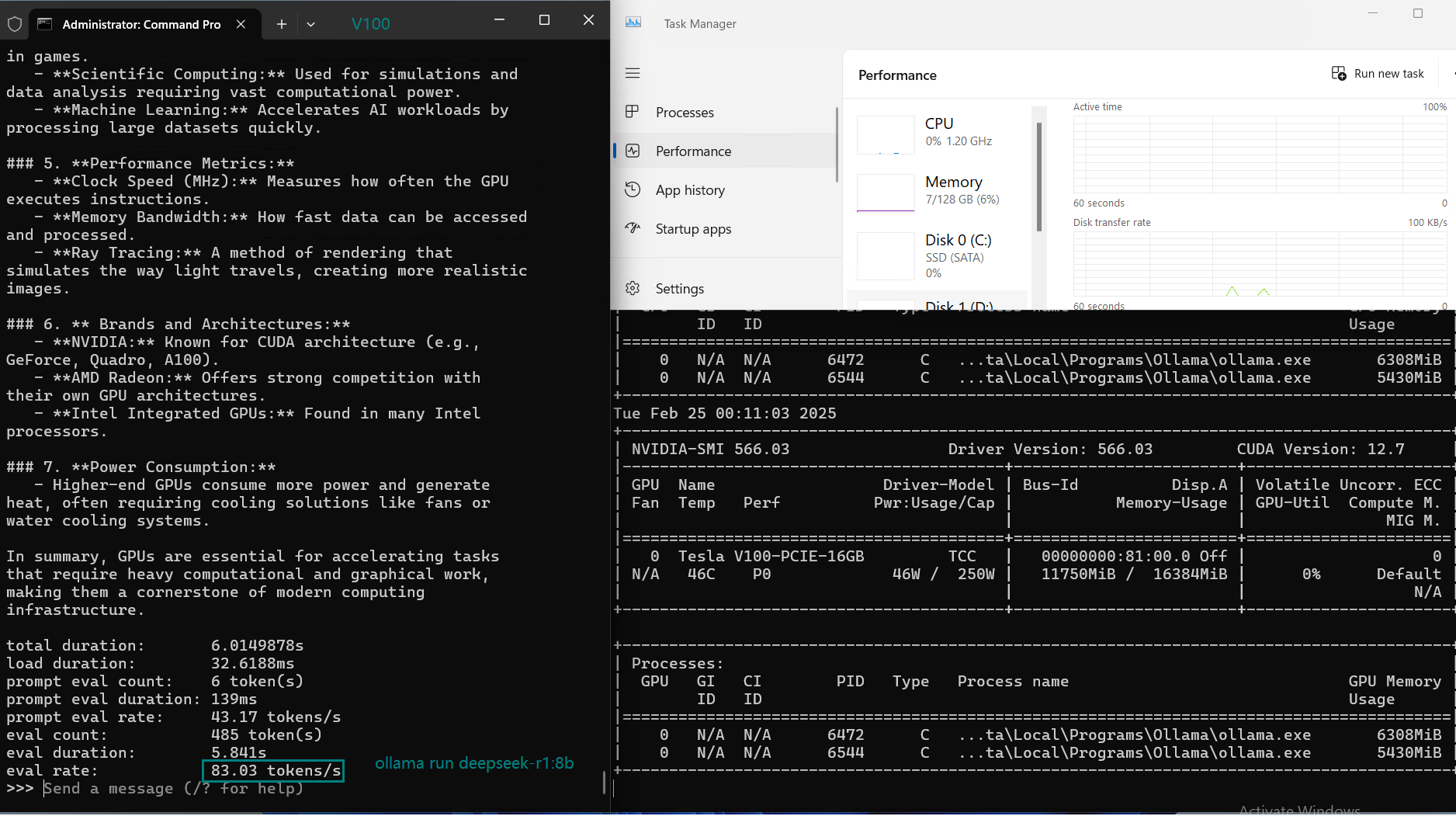
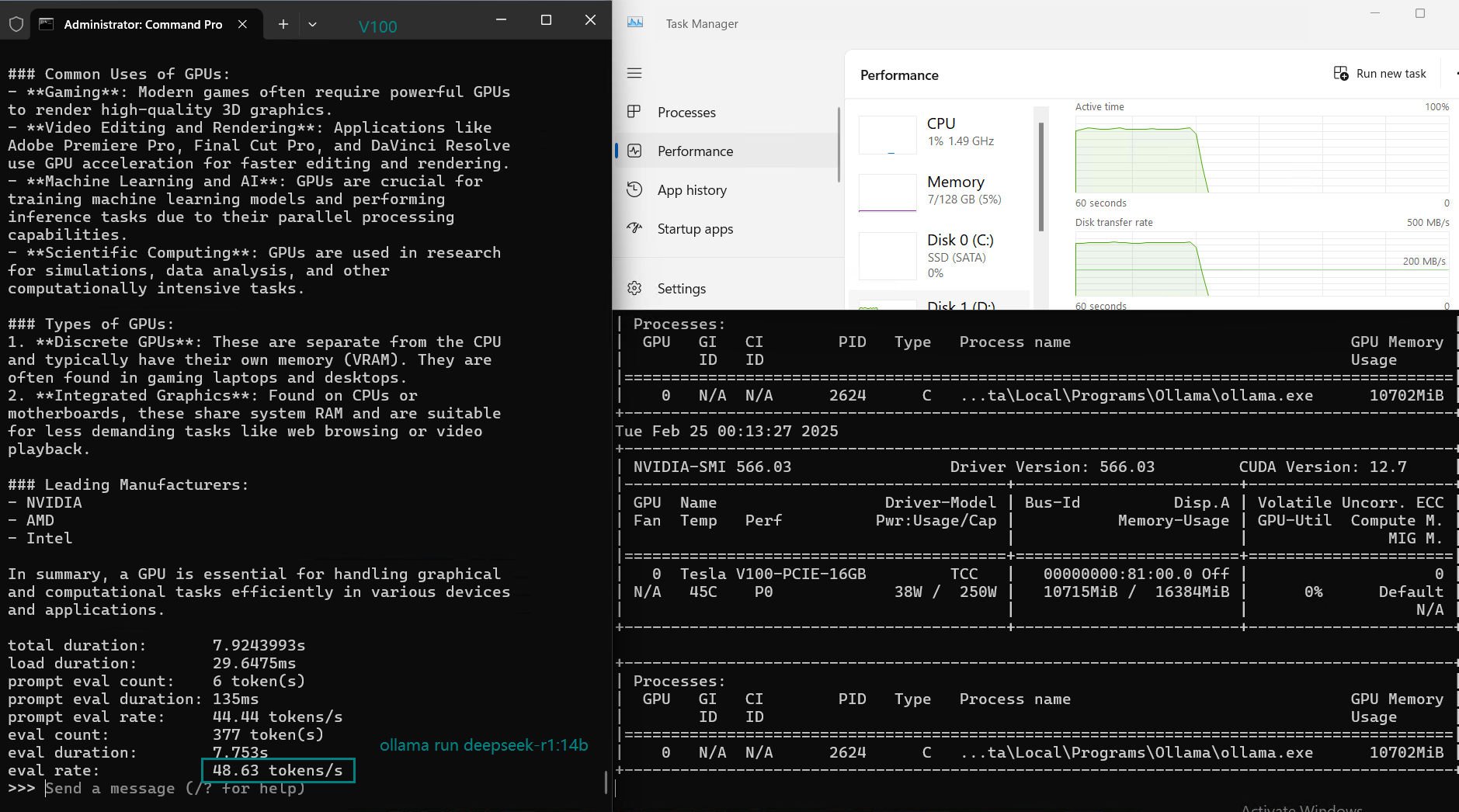
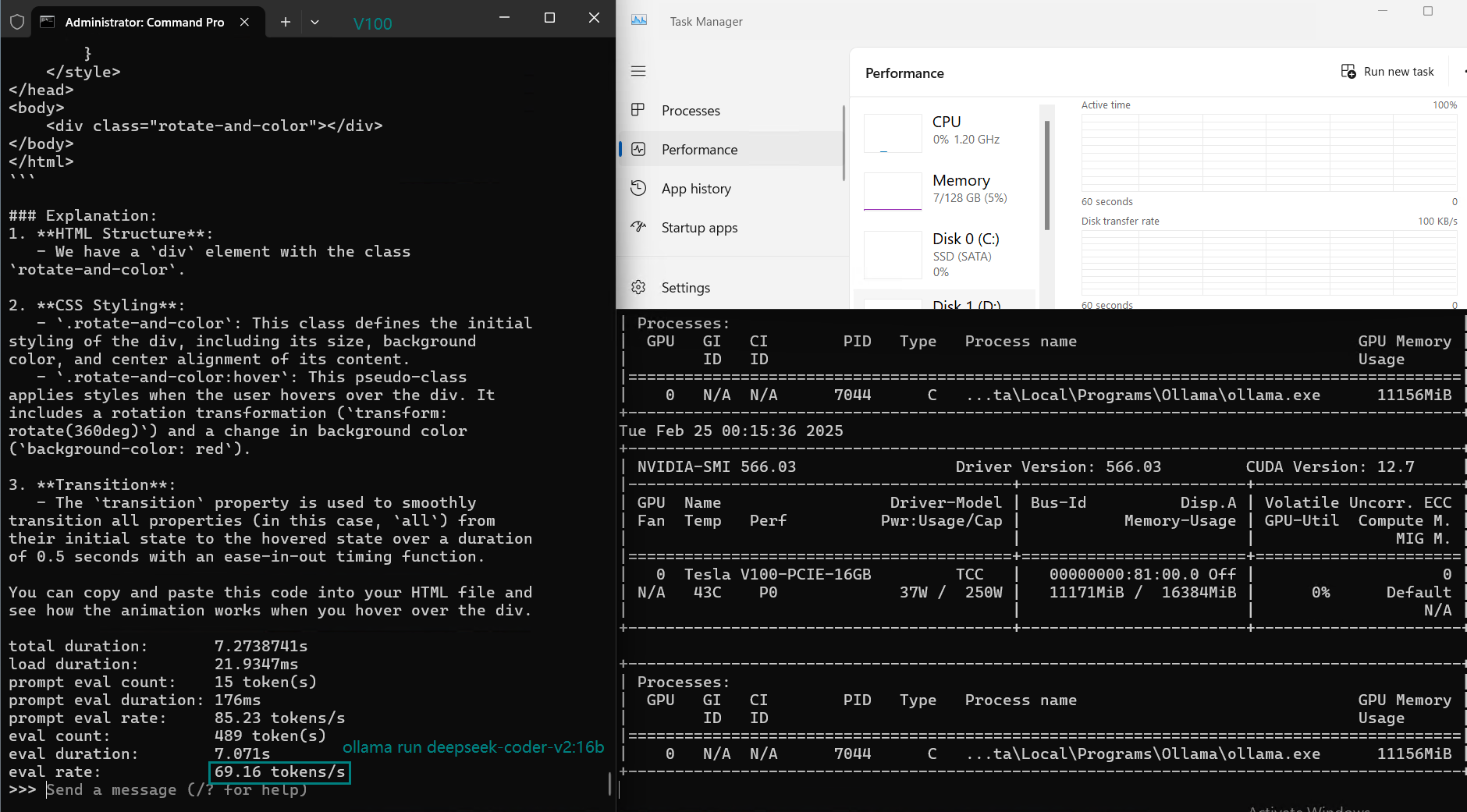
| GPU UTL | 71% | 78% | 80% | 70% | 85% | 87% | 76% | 84% | 69% | 13~24% | 73% | 80% |
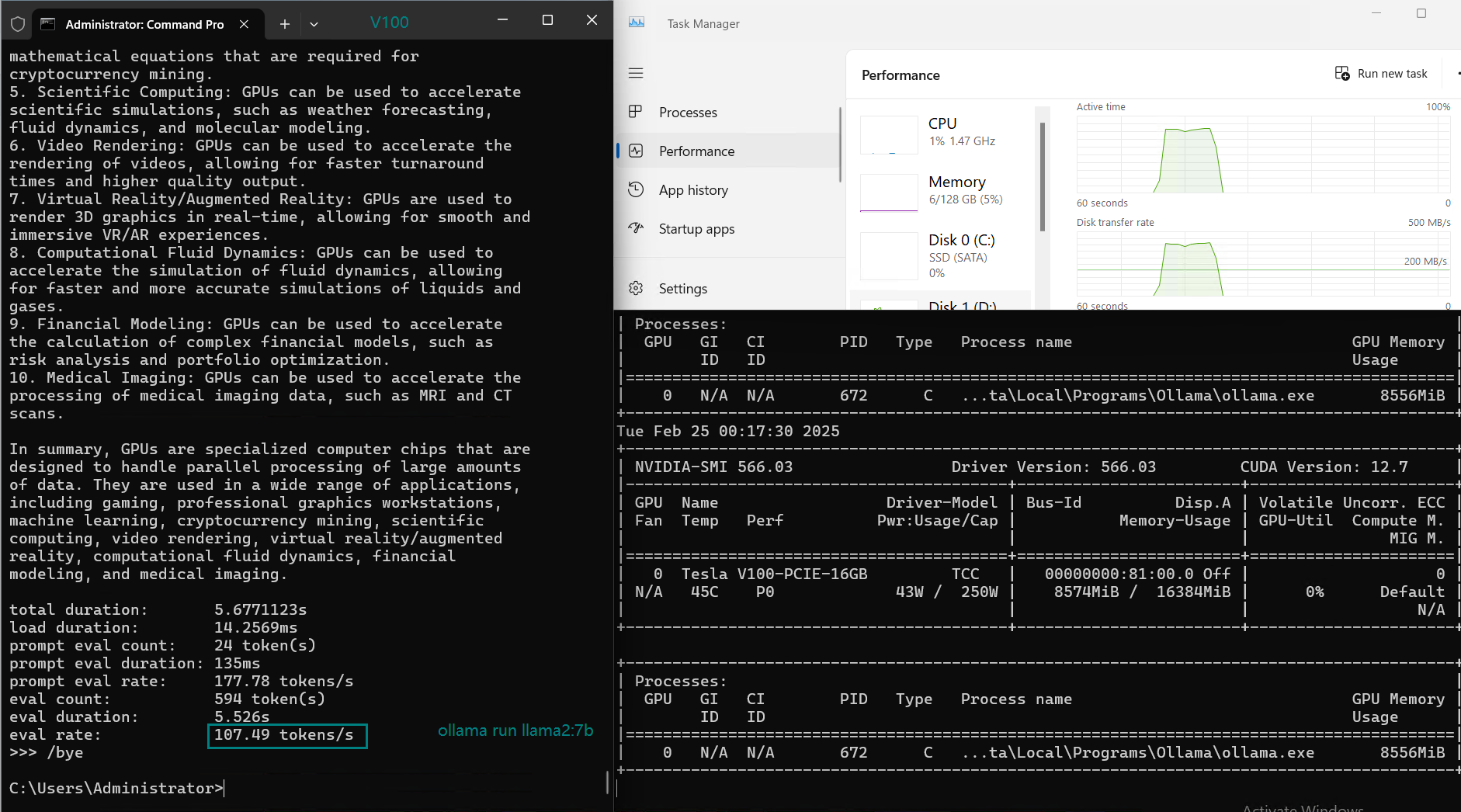
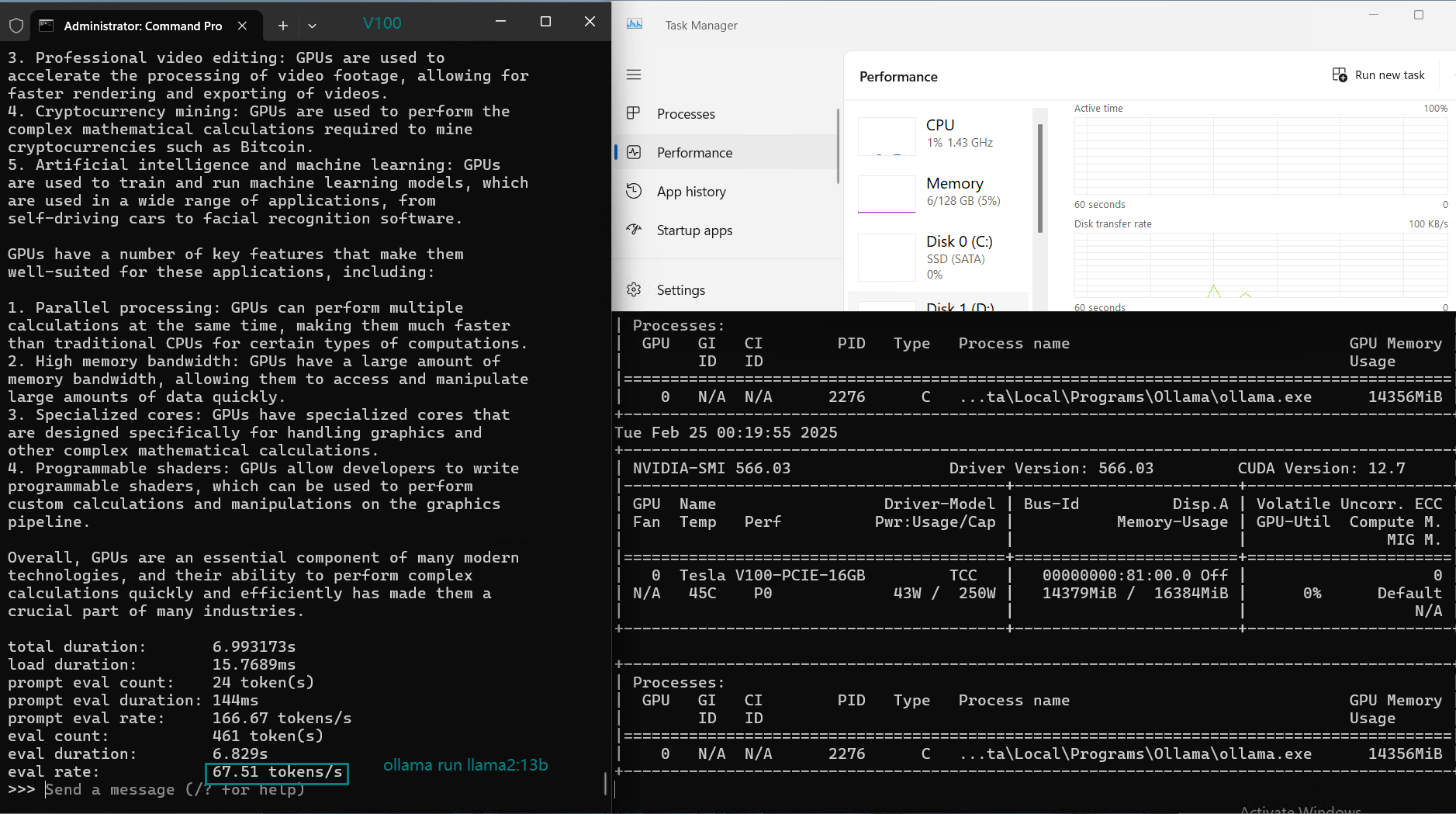
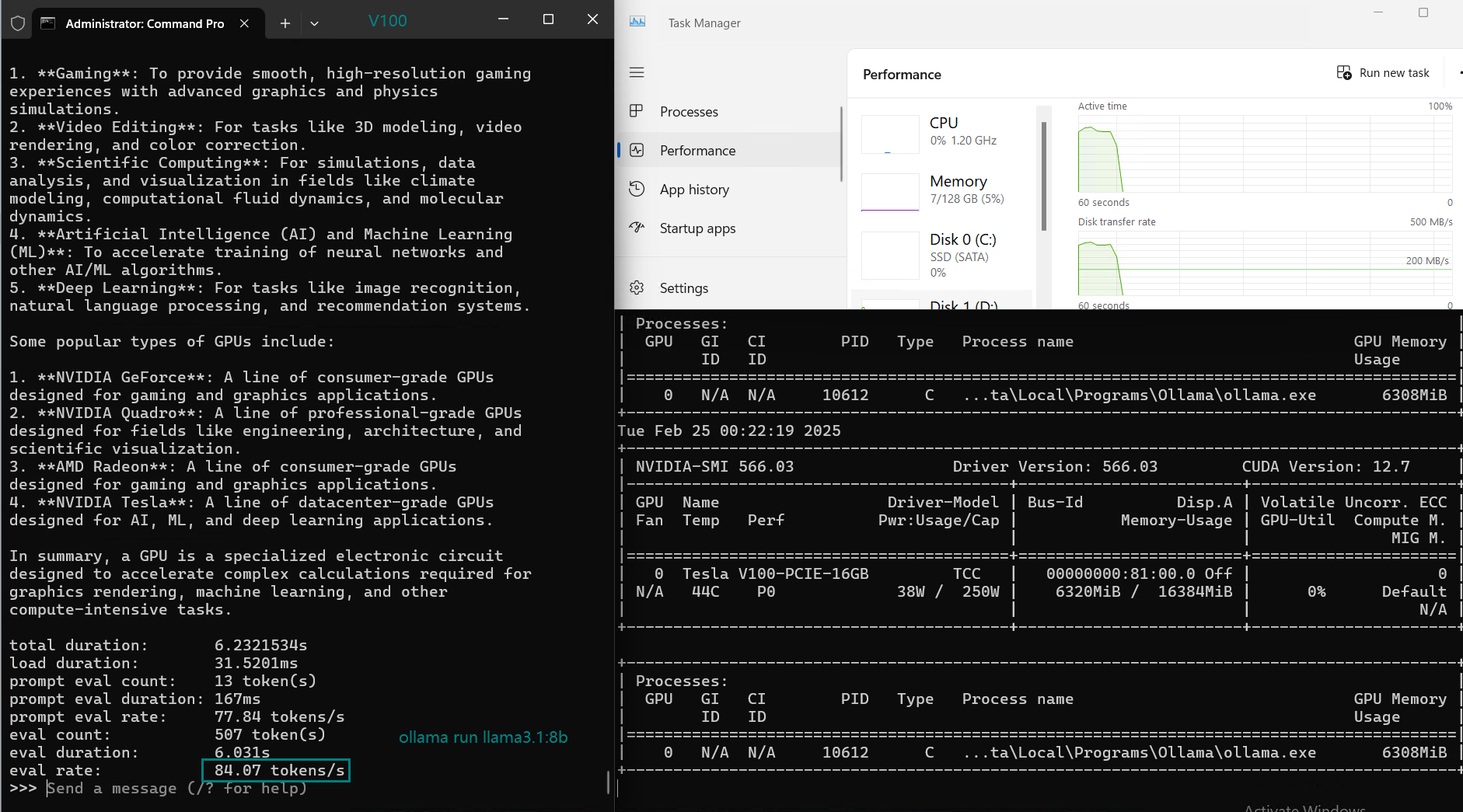
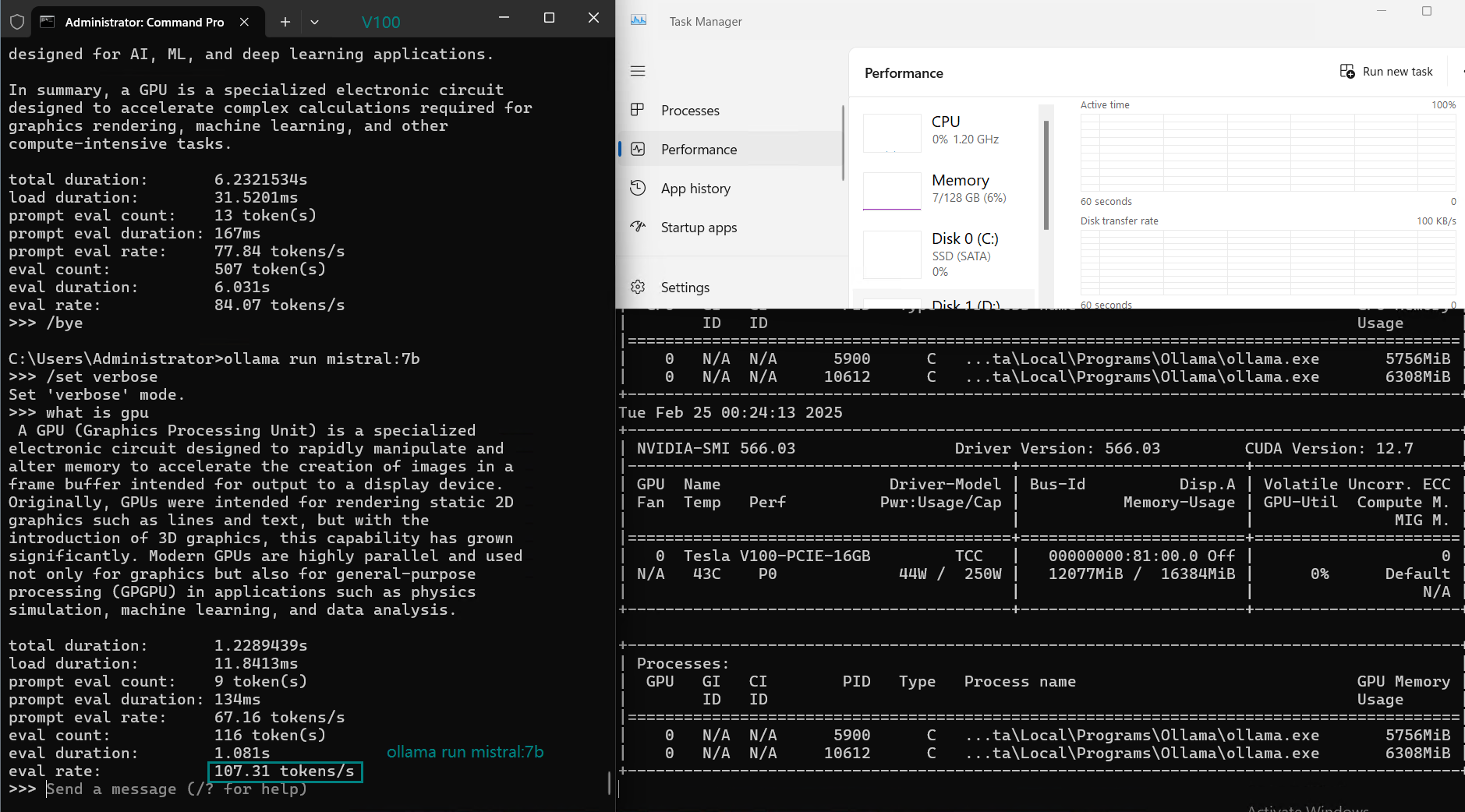
| Eval Rate(tokens/s) | 87.10 | 83.03 | 48.63 | 69.16 | 107.49 | 67.51 | 84.07 | 107.31 | 59.90 | 8.37 | 86.00 | 49.38 |
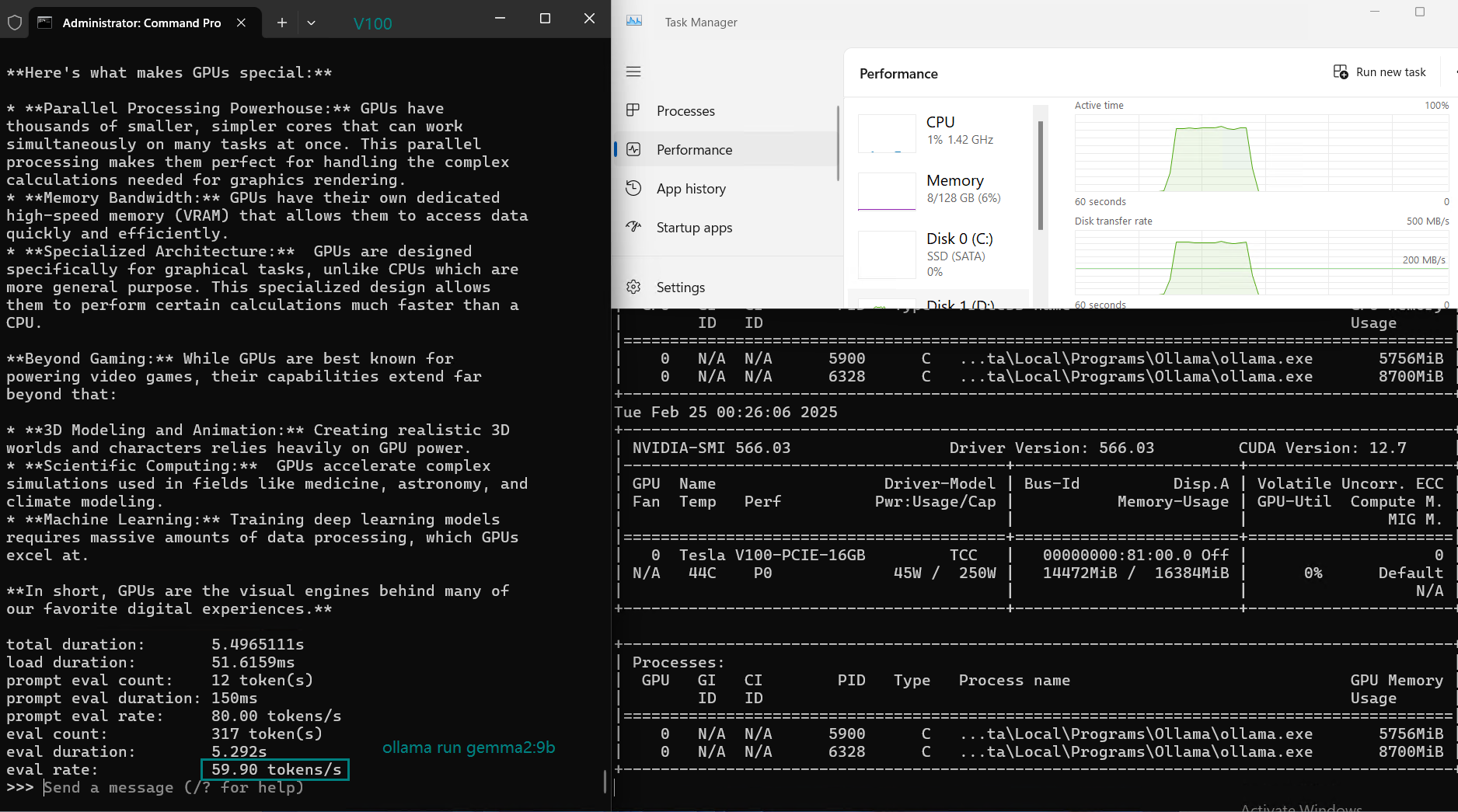
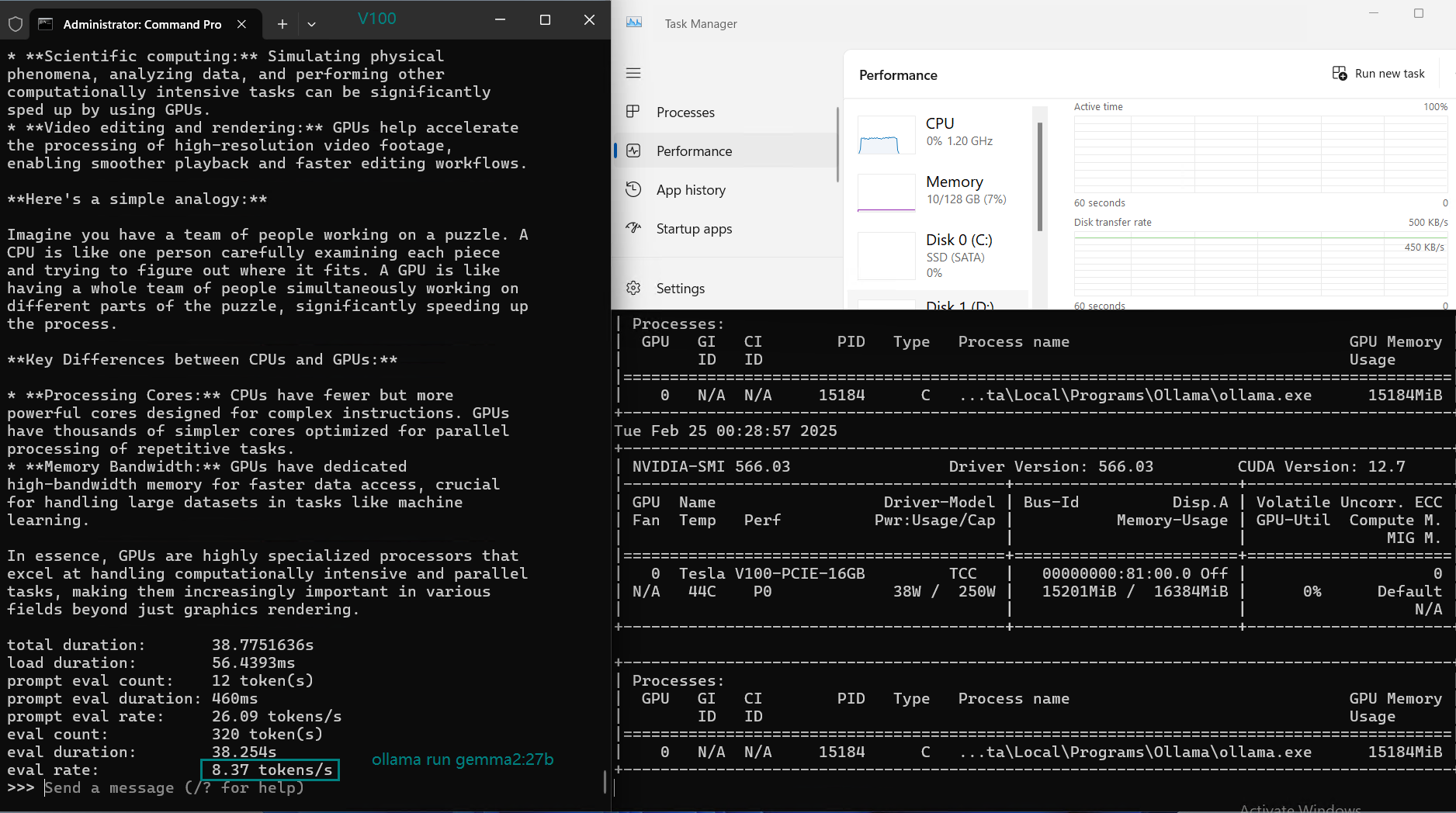
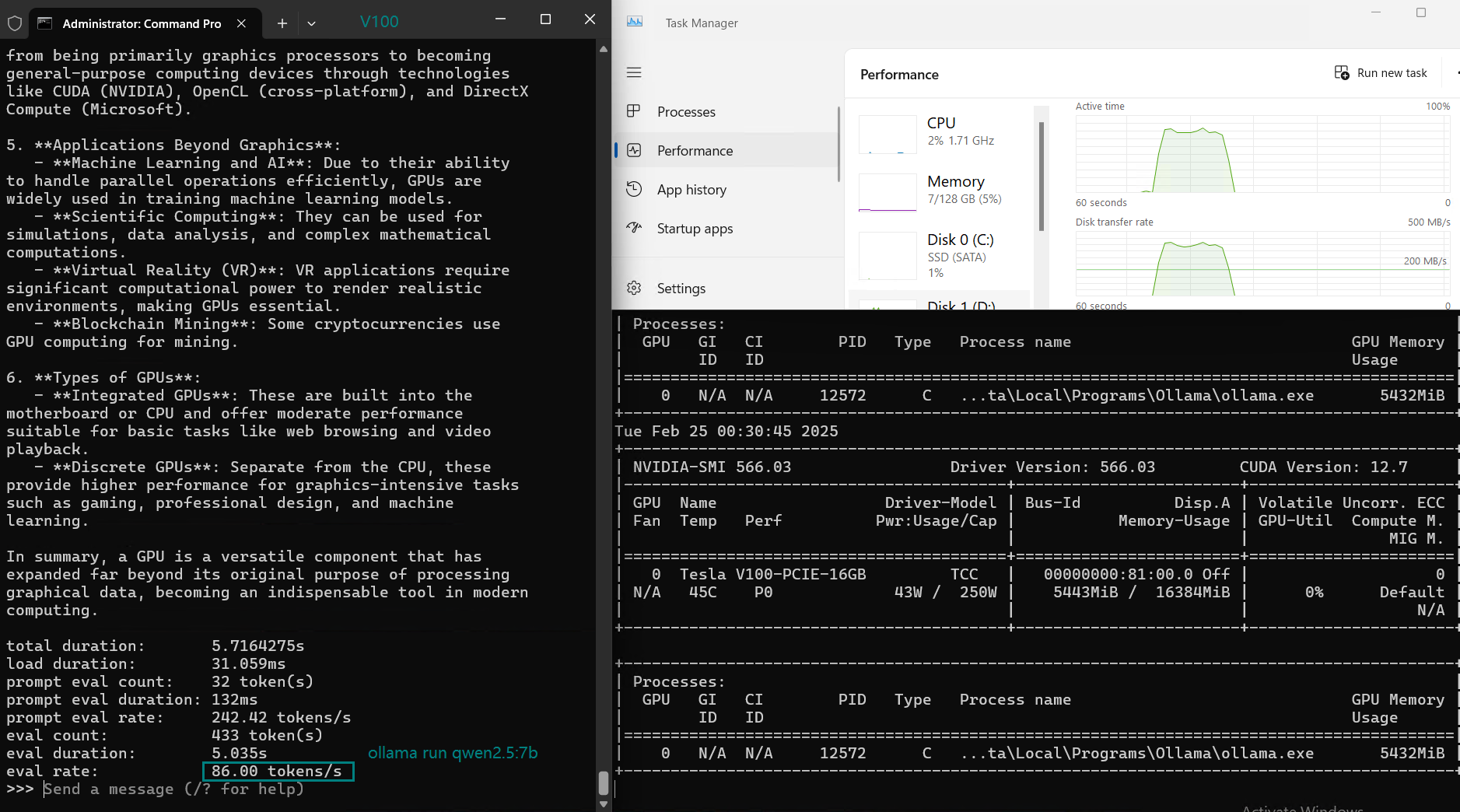
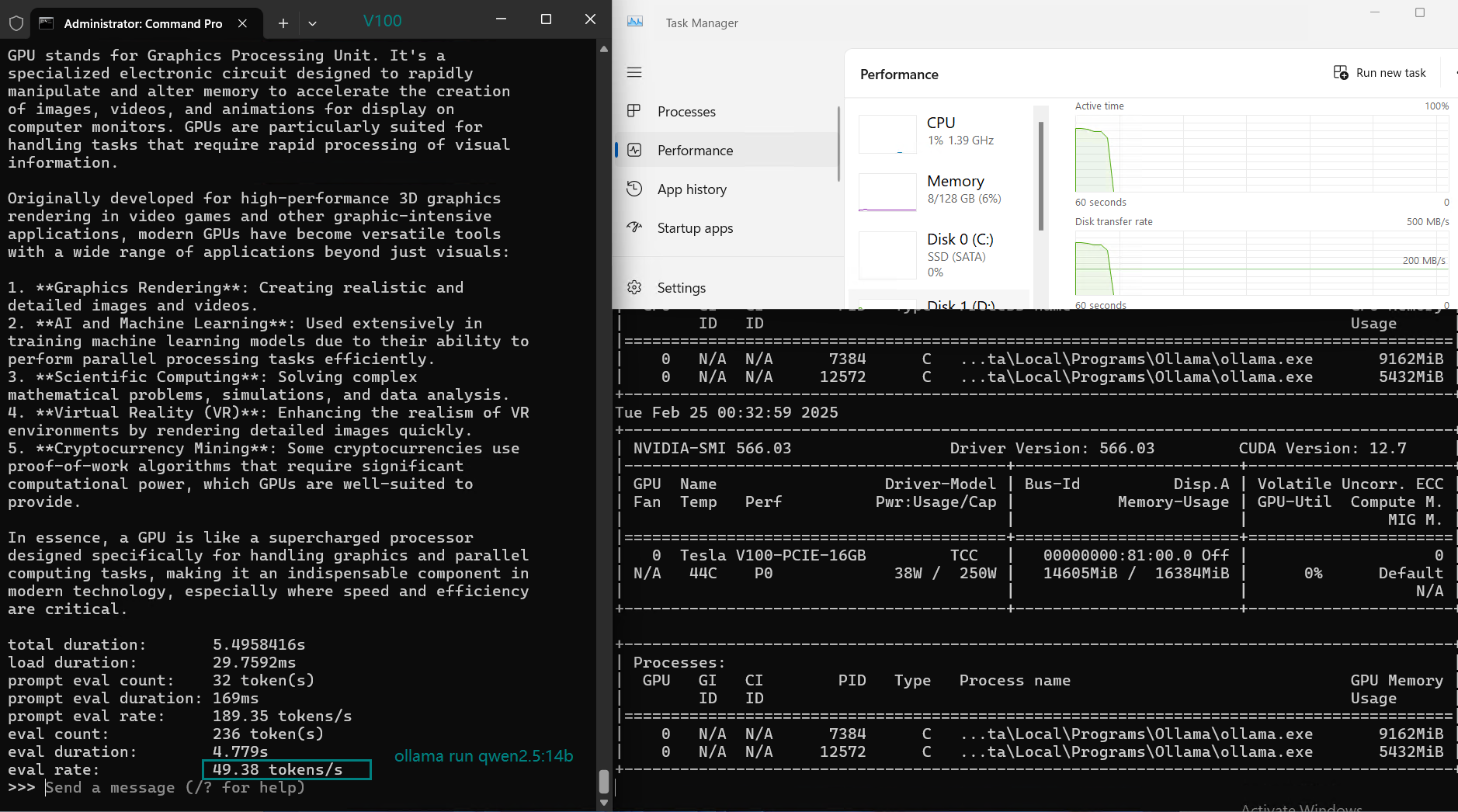
Key Takeaways from the NVIDIA V100 Ollama Benchmark
1. Best LLM for Performance: LLaMA 2 (7B) & Mistral (7B)
- Both LLaMA 2 (7B) and Mistral (7B) deliver the highest token evaluation rates (107+ tokens/s).
- Ideal for real-time inference, chatbots, and AI applications requiring fast response times.
2. Medium Models (13-14B) Have Slightly Reduced Performance
- DeepSeek 14B, Qwen 14B, and LLaMA 2 13B have reduced evaluation rates (~50 tokens/s).
- Higher GPU utilization (~80-87%) results in increased latency.
- NVIDIA V100 hosting remains the best choice for 13B-14B models.
3. Not suitable for running large models (27B+)
- gemma2:27B drops to 8.37 tokens/s, indicating that v100 will not be able to reason models larger than 27B.
4. GPU Utilization & Resource Efficiency
- GPU utilization varies from 70% to 87%, indicating Ollama on V100 efficiently manages workload.
- CPU & RAM usage remain low (~2-6%), allowing for potential multi-instance deployments.
Is NVIDIA V100 Hosting a Good Choice for Ollama LLM Inference?
1. Pros of Using NVIDIA V100 for Ollama
- Affordable & widely available compared to newer A100/H100 servers.
- Good balance of memory (16GB) and compute power for models up to 7B-24B.
- Strong inference speed for optimized models like LLaMA 2 and Mistral.
- Can run multiple smaller models efficiently due to moderate CPU/RAM requirements.
2. Limitations of NVIDIA V100 for Ollama
- Struggles with larger models (27B+), leading to slower evalu,/liation rates.
- 16GB VRAM is limiting for multi-GPU scaling.
- Not ideal for training—only suitable for inference workloads.
Get Started with V100 Server Hosting for LLMs
Advanced GPU Dedicated Server - V100
- 128GB RAM
- GPU: Nvidia V100
- Dual 12-Core E5-2690v3
- 240GB SSD + 2TB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Volta
- CUDA Cores: 5,120
- Tensor Cores: 640
- GPU Memory: 16GB HBM2
- FP32 Performance: 14 TFLOPS
Professional GPU VPS - A4000
- 28GB RAM
- 24 CPU Cores
- 320GB SSD
- 300Mbps Unmetered Bandwidth
- Once per 2 Weeks Backup
- OS: Windows / Linux
- Dedicated GPU: Quadro RTX A4000
- CUDA Cores: 6,144
- Tensor Cores: 192
- GPU Memory: 16GB GDDR6
- FP32 Performance: 19.2 TFLOPS
Advanced GPU Dedicated Server - RTX 3060 Ti
- 128GB RAM
- GPU: GeForce RTX 3060 Ti
- Dual 12-Core E5-2697v2
- 240GB SSD + 2TB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 4864
- Tensor Cores: 152
- GPU Memory: 8GB GDDR6
- FP32 Performance: 16.2 TFLOPS
Professional GPU Dedicated Server - P100
- 128GB RAM
- GPU: Nvidia Tesla P100
- Dual 8-Core E5-2660
- 120GB + 960GB SSD
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Pascal
- CUDA Cores: 3584
- GPU Memory: 16 GB HBM2
- FP32 Performance: 9.5 TFLOPS
Final Verdict: Is V100 Hosting Worth It for Ollama?
For those looking for an affordable LLM hosting solution, NVIDIA V100 rental services offer a cost-effective option for deploying models like LLaMA 2, Mistral, and DeepSeek-R1. With Ollama’s efficient inference engine, the V100 performs well on models up to 7-24B parameters, making it a great choice for chatbots, AI assistants, and other real-time NLP applications.
However, for larger models (24B+), upgrading to an RTX4090(24GB) or A100(40GB) would be necessary. What LLMs are you running on your NVIDIA V100 server? Let us know in the comments!
Ollama, LLM, NVIDIA V100, AI, Deep Learning, Mistral, LLaMA2, DeepSeek, GPU, Machine Learning, AI Inference