

vLLM Distributed Inference Optimization: How to Avoid Performance Pitfalls in Multi-GPU
When deploying large language models (LLMs) like DeepSeek-R1 using vLLM, proper configuration is crucial for maximizing efficiency. Many users assume that simply adding more GPUs will lead to higher throughput and lower latency, but our benchmarks reveal a different story.
This article discover the best practices for optimizing vLLM in multi-GPU inference. Learn why --tensor-parallel-size is crucial, how vLLM’s distributed architecture impacts performance, and how to avoid common pitfalls that slow down your LLM deployment.Three Configs from a vLLM Benchmark Insight:
- 1× RTX 4090, --tensor-parallel-size 1 (Single-GPU configuration)
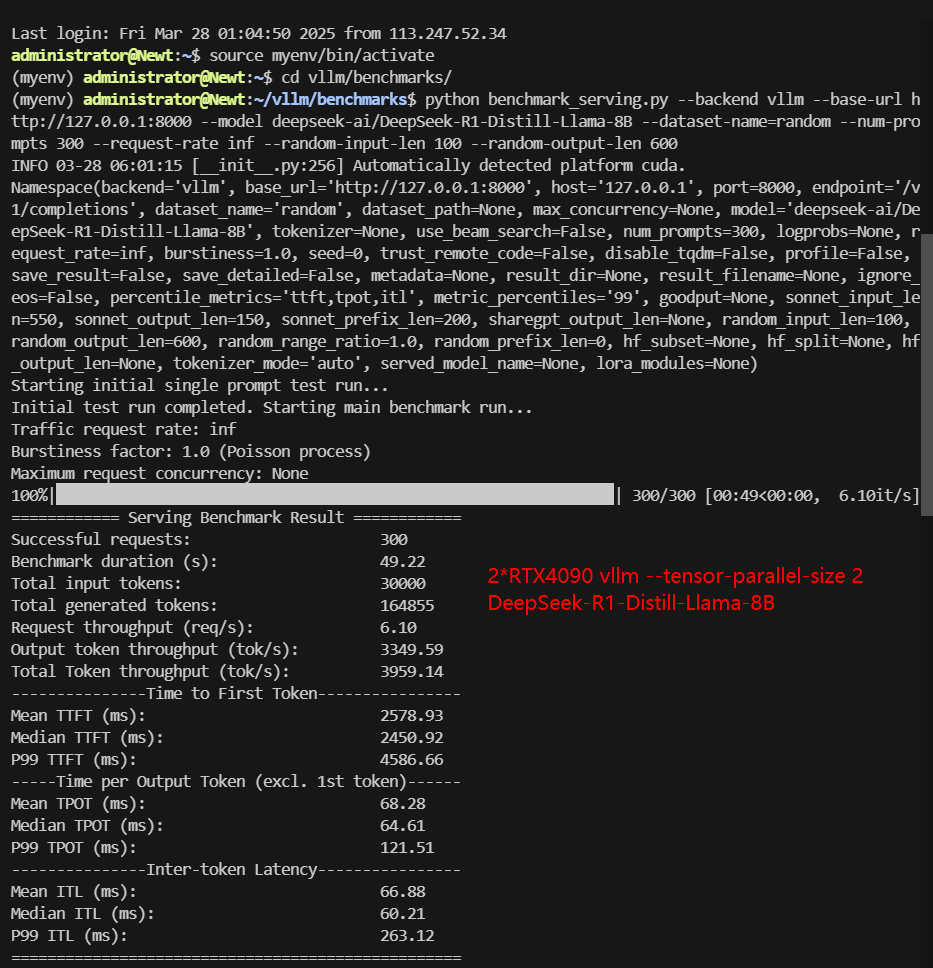
- 2× RTX 4090, --tensor-parallel-size 2 (Multi-GPU configuration, 2 GPUs parallel inference)
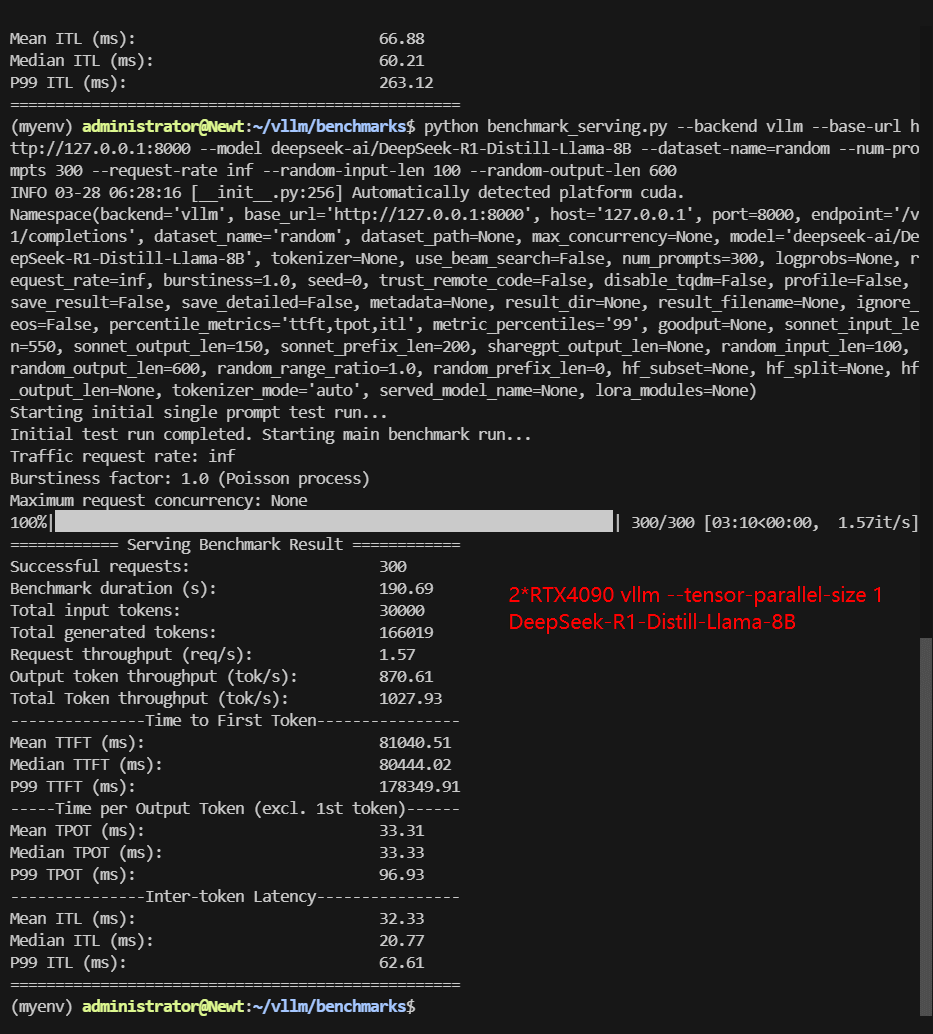
- 2× RTX 4090, --tensor-parallel-size 1 (Multi-GPU configuration but only using one card)
Single-GPU Inference vs. Multi-GPU Parallelism
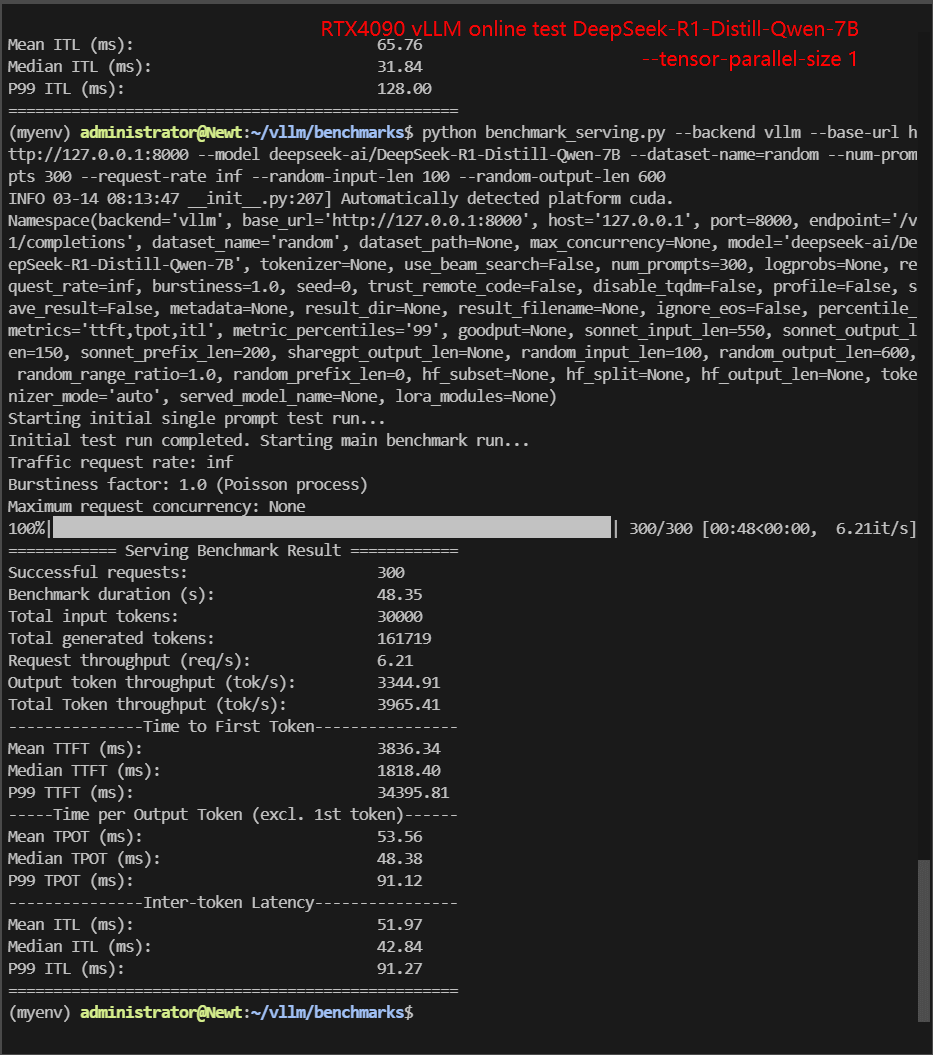
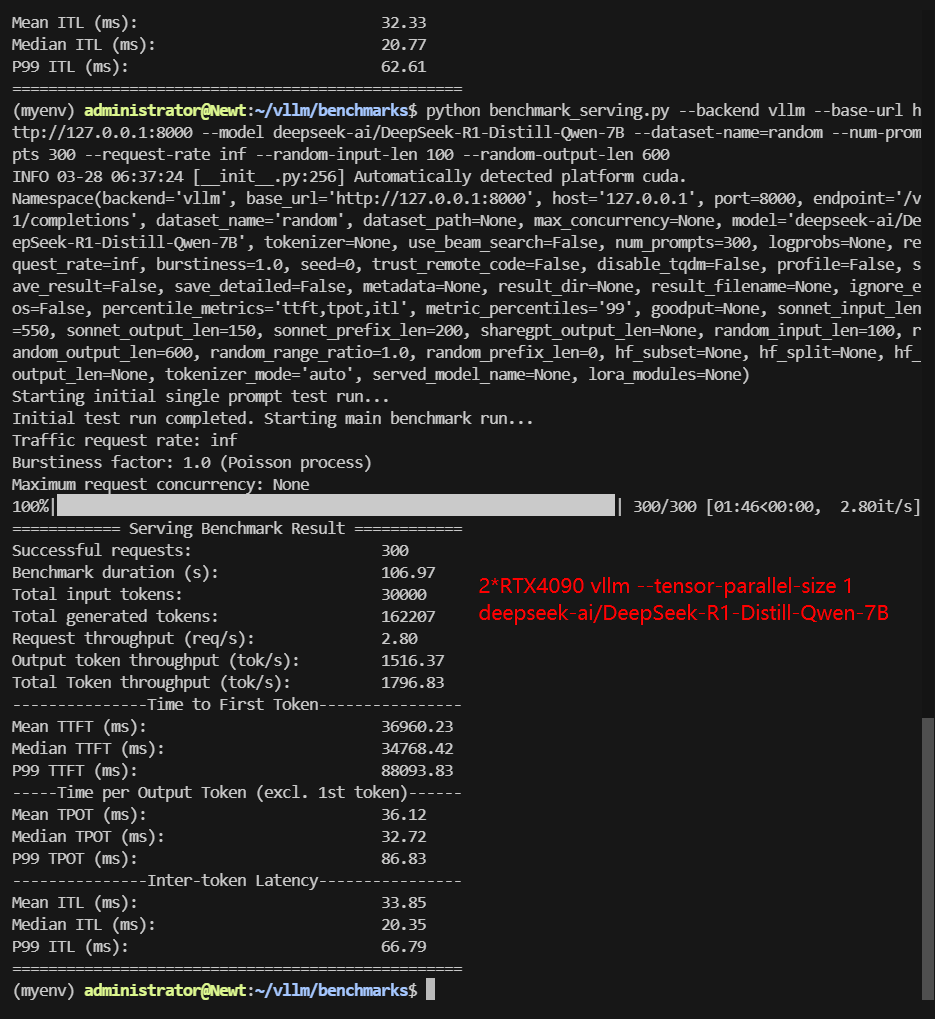
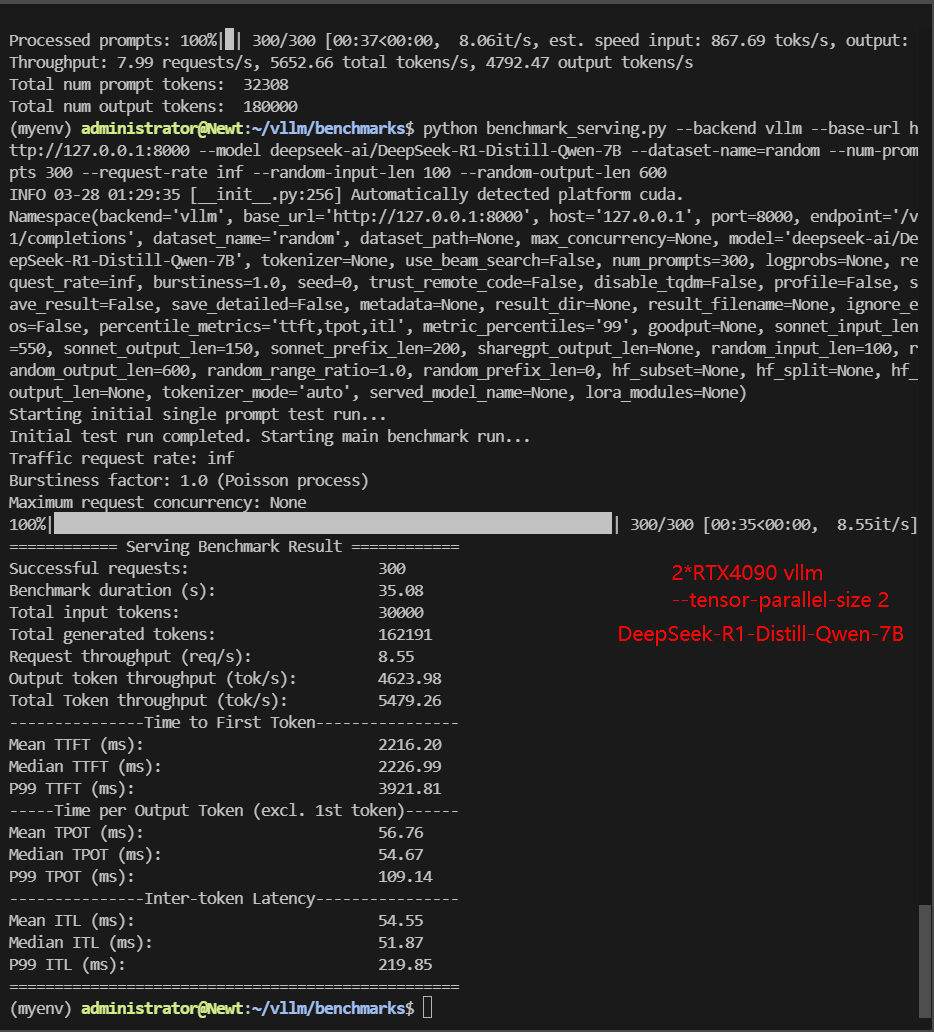
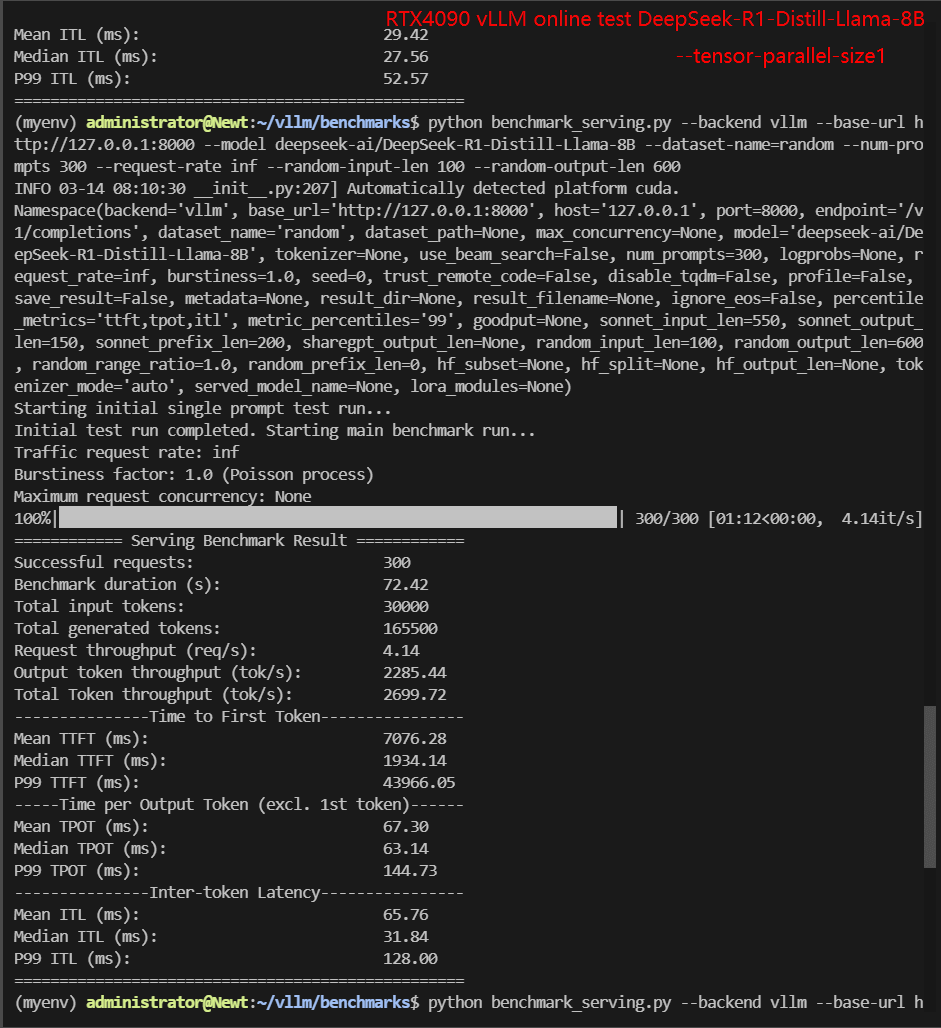
| Models | DeepSeek-R1-Distill-Qwen-7B | DeepSeek-R1-Distill-Qwen-7B | DeepSeek-R1-Distill-Qwen-7B | DeepSeek-R1-Distill-Llama-8B | DeepSeek-R1-Distill-Llama-8B | DeepSeek-R1-Distill-Llama-8B |
|---|---|---|---|---|---|---|
| Quantization | 16 | 16 | 16 | 16 | 16 | 16 |
| Size(GB) | 15 | 15 | 15 | 15 | 15 | 15 |
| Backend/Platform | vLLM | vLLM | vLLM | vLLM | vLLM | vLLM |
| GPU Server | RTX4090*1 | RTX4090*2 | RTX4090*2 | RTX4090*1 | RTX4090*2 | RTX4090*2 |
| Tensor Parallel Size | 1 | 1 | 2 | 1 | 1 | 2 |
| Request Numbers | 300 | 300 | 300 | 300 | 300 | 300 |
| Benchmark Duration(s) | 48.35 | 106.97 | 35.08 | 72.42 | 190.69 | 49.22 |
| Total Input Tokens | 30000 | 30000 | 30000 | 30000 | 30000 | 30000 |
| Total Generated Tokens | 161719 | 162207 | 162191 | 165500 | 166019 | 164855 |
| Request (req/s) | 6.21 | 2.80 | 8.55 | 4.14 | 1.57 | 6.10 |
| Input (tokens/s) | 620.5 | 280.46 | 855.28 | 414.28 | 157.32 | 609.55 |
| Output (tokens/s) | 3344.91 | 1516.37 | 4623.98 | 2285.44 | 870.61 | 3349.59 |
| Total Throughput (tokens/s) | 3965.41 | 1796.83 | 5479.26 | 2699.72 | 1027.93 | 3959.14 |
| Median TTFT (ms) | 1818.40 | 34768.42 | 2226.99 | 1934.14 | 80444.02 | 2450.92 |
| P99 TTFT (ms) | 34395.81 | 88093.83 | 3921.81 | 43966.05 | 178349.91 | 4586.66 |
| Median TPOT (ms) | 48.38 | 32.72 | 54.67 | 63.14 | 33.33 | 64.61 |
| P99 TPOT (ms) | 91.12 | 86.83 | 109.14 | 144.73 | 96.93 | 121.51 |
| Median Eval Rate (tokens/s) | 20.70 | 30.56 | 18.29 | 15.83 | 30.00 | 15.48 |
| P99 Eval Rate (tokens/s) | 10.97 | 11.5 | 9.16 | 6.91 | 10.31 | 8.23 |
✅ Key Takeaways:
- Best Performance: TP=2 (5479 tokens/s) – The multi-GPU setup finally beats the single-GPU baseline.
- Worst Performance: TP=1 on dual GPUs (1796 tokens/s) – slower than a single 4090!
- This confirms that 2 GPUs parallel inferencing can be accelerated, and Multi-GPU configurations but using just one of the GPUs severely degrades performance.
Why Does TP=1 Fail on Multi-GPU Servers?
Performance inconsistencies:
- DeepSeek-R1-Distill-Quen-7B: The throughput of 1×4090 (TP=1) (3965 tokens/s) is significantly higher than that of 2×4090 (TP=1) (1796 tokens/s), but the latency (TTF) is also higher.
- DeepSeek-R1-Distill-Llama-8B: Similarly, the throughput of 1×4090 (TP=1) (2699 tokens/s) is higher than that of 2×4090 (TP=1) (1027 tokens/s).
Possible Cause Analysis
Implicit multi-card allocation of vLLM:
- Even if TP=1, vLLM may still use multiple cards for pipeline parallelism or memory sharing (for example, sharding model weights into multiple card memory, but the calculation is still limited to a single card).
- Consequence: In a multi-card environment, memory bandwidth or communication overhead may cause additional delays, especially when not fully optimized.
Hardware resource competition:
- PCIe bandwidth limitation: In a dual-card environment, if the number of PCIe channels is insufficient (such as non-full-speed x16/x16), data transmission may become a bottleneck.
- Memory management: Multi-card memory allocation may introduce additional synchronization overhead (such as CUDA context switching).
vLLM Distributed Architecture
1️⃣ NUMA & PCIe Bottlenecks:
administrator@Newt:~$ nvidia-smi topo -m
GPU0 GPU1 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X SYS 0-17,36-53 0 N/A
GPU1 SYS X 18-35,54-71 1 N/AThe problem?
- SYS means GPUs are connected via slow PCIe lanes instead of NVLink.
- Cross-NUMA communication introduces major latency, as GPU0 & GPU1 access different CPU memory banks.
- PCIe bandwidth is halved when running dual-GPU setups, leading to contention.
Result:
- When TP=1, vLLM still initializes both GPUs, leading to unnecessary data transfers across NUMA nodes, worsening performance.
2️⃣ vLLM’s Silent Multi-GPU Overhead:
To achieve this, vLLM leverages Tensor Parallelism (TP) and Pipeline Parallelism (PP) to split and distribute computation across multiple GPUs.
- CUDA contexts are initialized on all available GPUs.
- CPU threads may be scheduled across NUMA nodes, increasing memory access latency.
- PCIe contention occurs, slowing tensor processing.
3️⃣ Why CUDA_VISIBLE_DEVICES=0 Doesn’t Fix It?
CUDA_VISIBLE_DEVICES=0 python benchmark_serving.py --backend vllm --base-url http://127.0.0.1:8000 --model deepseek-ai/DeepSeek-R1-Distill-Llama-8B --dataset-name=random --num-prompts 300 --request-rate inf --random-input-len 100 --random-output-len 600
Key Takeaways: Optimizing vLLM for Multi-GPU Inference
By properly configuring vLLM’s distributed architecture, you can maximize throughput, minimize latency, and fully utilize your multi-GPU hardware. 🚀
Get Started with GPU Server for Inference
Interested in optimizing your vLLM deployment? Check out our cheap GPU server hosting services or explore alternative GPUs for high-end AI inference.
Enterprise GPU Dedicated Server - RTX 4090
- 256GB RAM
- GPU: GeForce RTX 4090
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ada Lovelace
- CUDA Cores: 16,384
- Tensor Cores: 512
- GPU Memory: 24 GB GDDR6X
- FP32 Performance: 82.6 TFLOPS
Multi-GPU Dedicated Server- 2xRTX 4090
- 256GB RAM
- GPU: 2 x GeForce RTX 4090
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ada Lovelace
- CUDA Cores: 16,384
- Tensor Cores: 512
- GPU Memory: 24 GB GDDR6X
- FP32 Performance: 82.6 TFLOPS
Enterprise GPU Dedicated Server - A100
- 256GB RAM
- GPU: Nvidia A100
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 40GB HBM2
- FP32 Performance: 19.5 TFLOPS
- 50% Off First Month, 30% Off Renewals
Enterprise GPU Dedicated Server - A100(80GB)
- 256GB RAM
- GPU: Nvidia A100
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 80GB HBM2e
- FP32 Performance: 19.5 TFLOPS
vLLM optimization, vLLM distributed inference, multi-GPU inference, tensor-parallel-size, vLLM performance tuning, vLLM architecture, deep learning inference, LLM serving, NUMA optimization, vLLM benchmark