

Benchmarking Nvidia Quadro RTX A6000: Running LLMs on a GPU Server with Ollama
The Nvidia Quadro RTX A6000 is a powerhouse GPU known for its exceptional performance in AI and machine learning tasks. In this article, we delve into its performance when running Large Language Models (LLMs) on a GPU dedicated server. The benchmarks utilize the Ollama environment, testing models such as Llama2, Qwen, and others.
Server Specifications
Server Configuration:
- Price: $549.00/month
- CPU: Dual 18-Core E5-2697v4 (36 cores, 72 threads)
- RAM: 256GB
- Storage: 240GB SSD + 2TB NVMe + 8TB SATA
- Network: 100Mbps-1Gbps connection
- OS: Windows
GPU Details:
- GPU: Nvidia Quadro RTX A6000
- Compute Capability: 8.6
- Microarchitecture: Ampere
- CUDA Cores: 10,752
- Tensor Cores: 336
- GPU Memory: 48GB GDDR6
- FP32 Performance: 38.71 TFLOPS
These specifications provide an excellent foundation for LLM testing using Ollama.
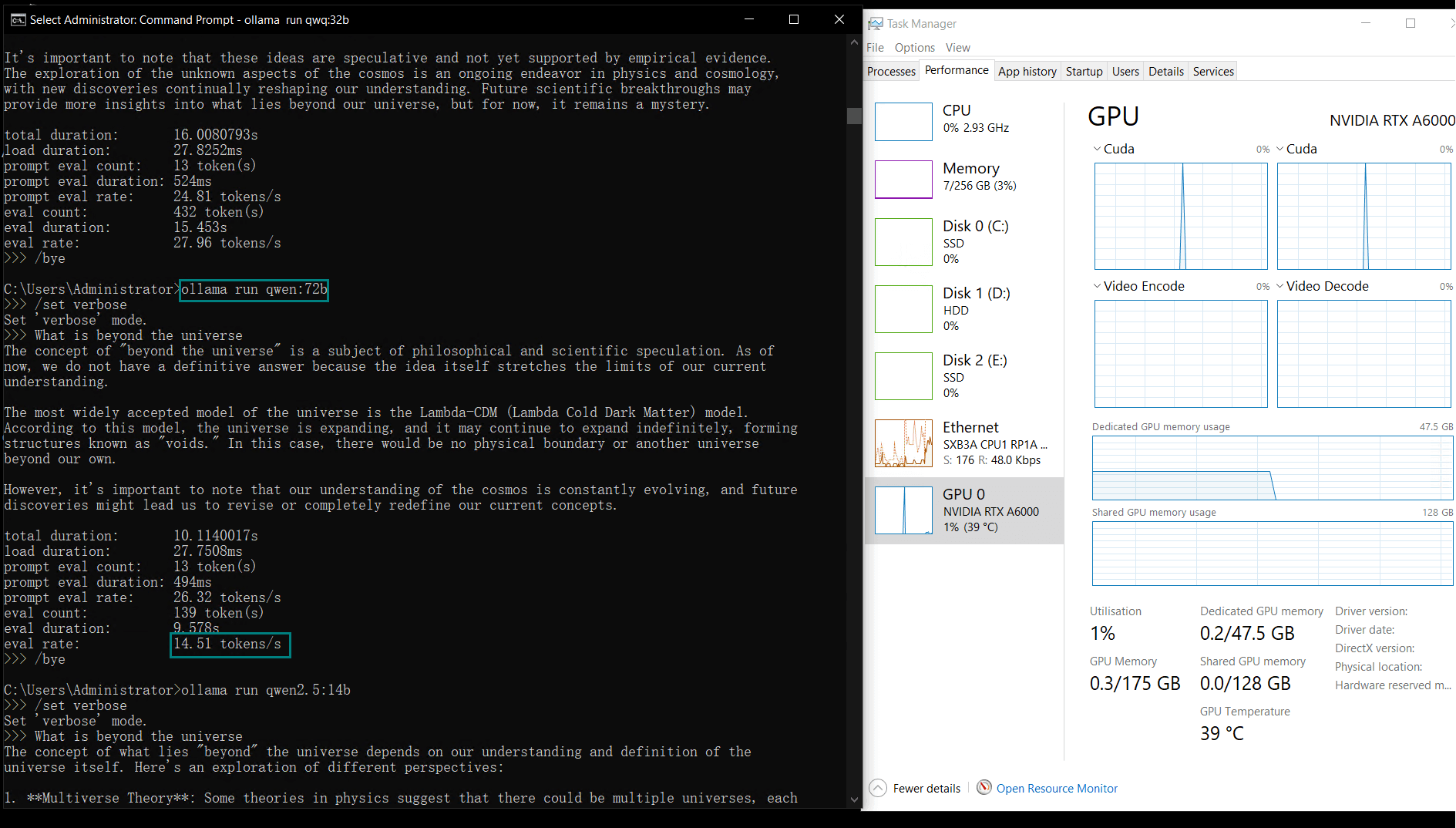
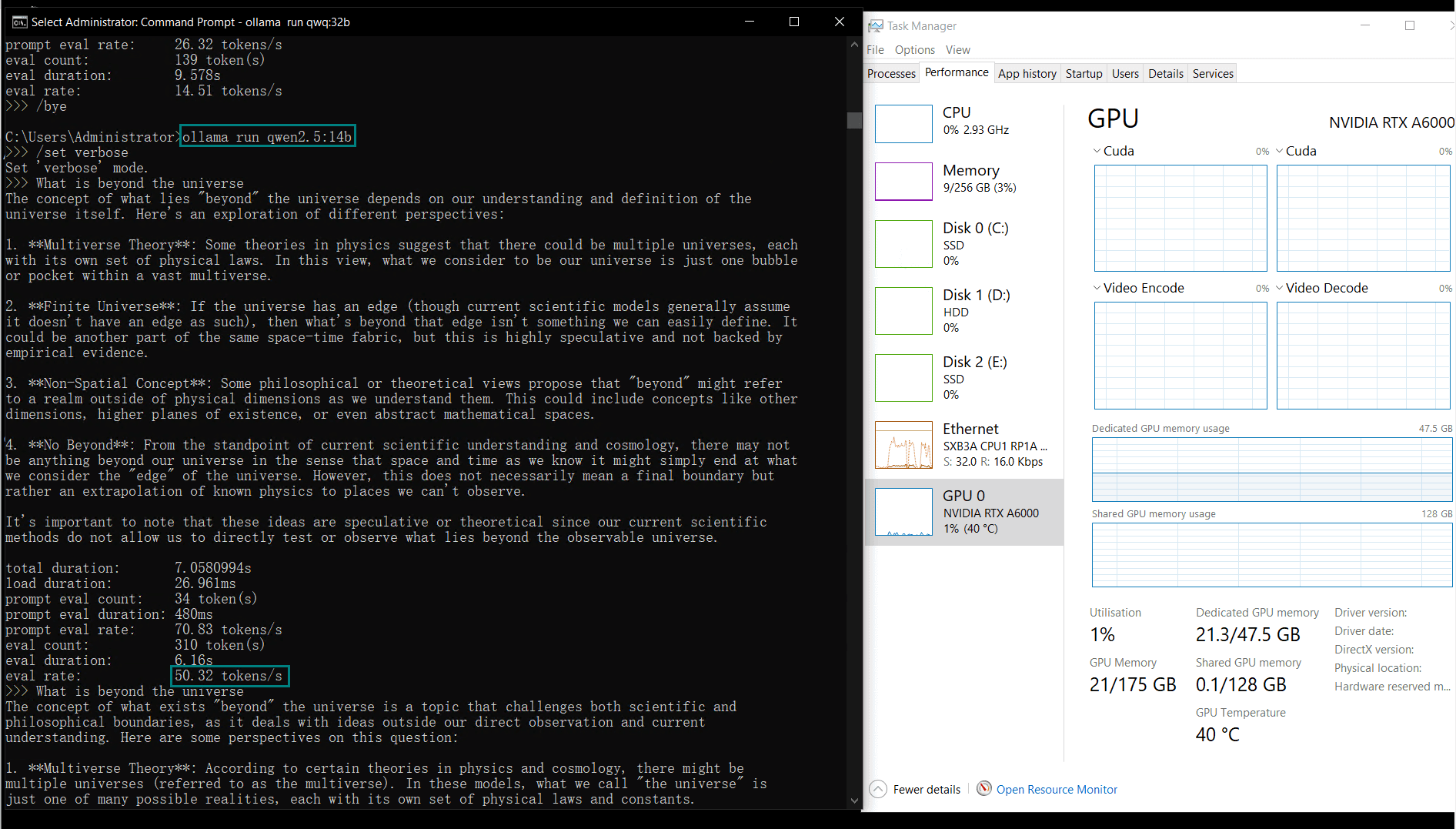
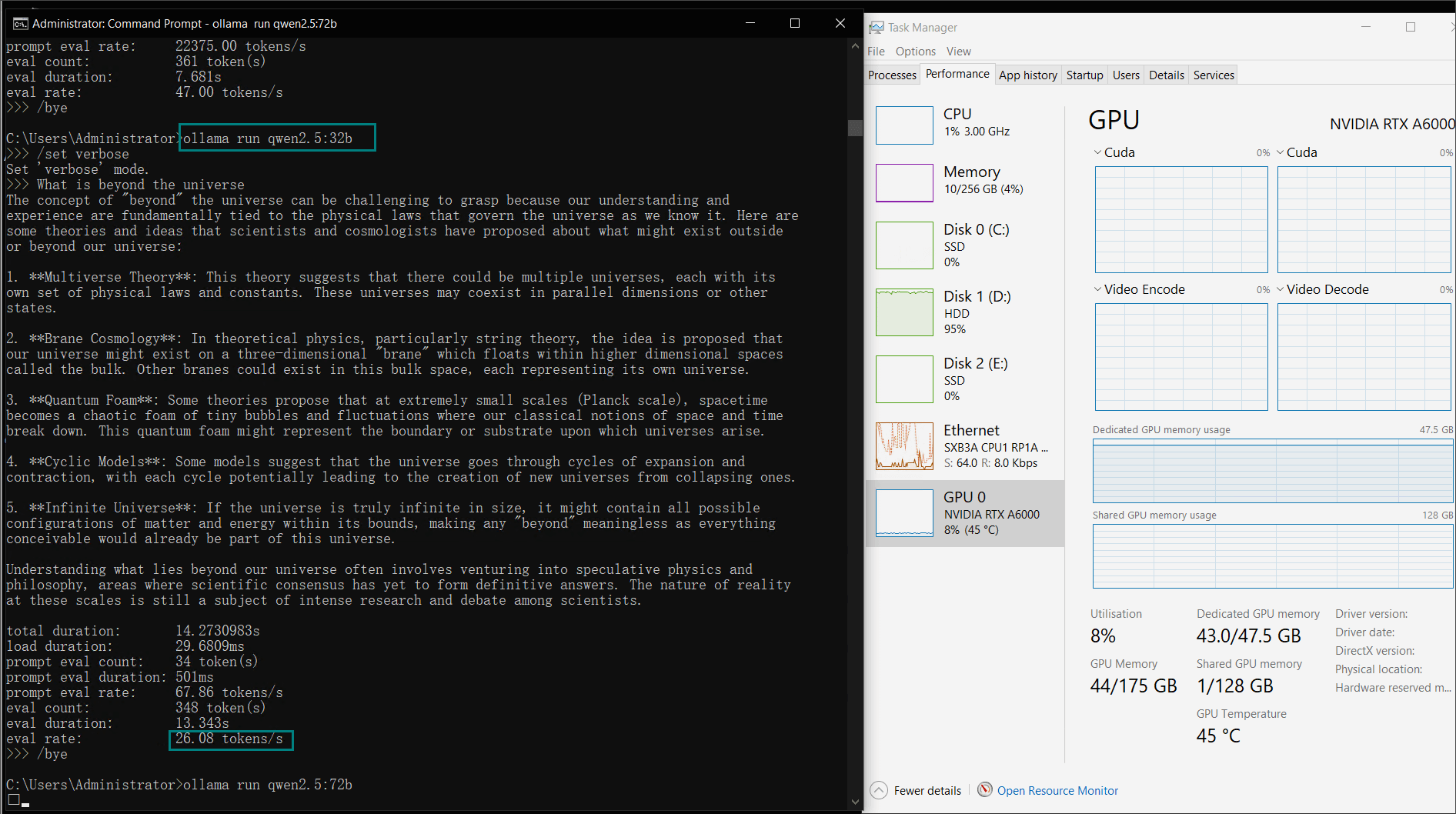
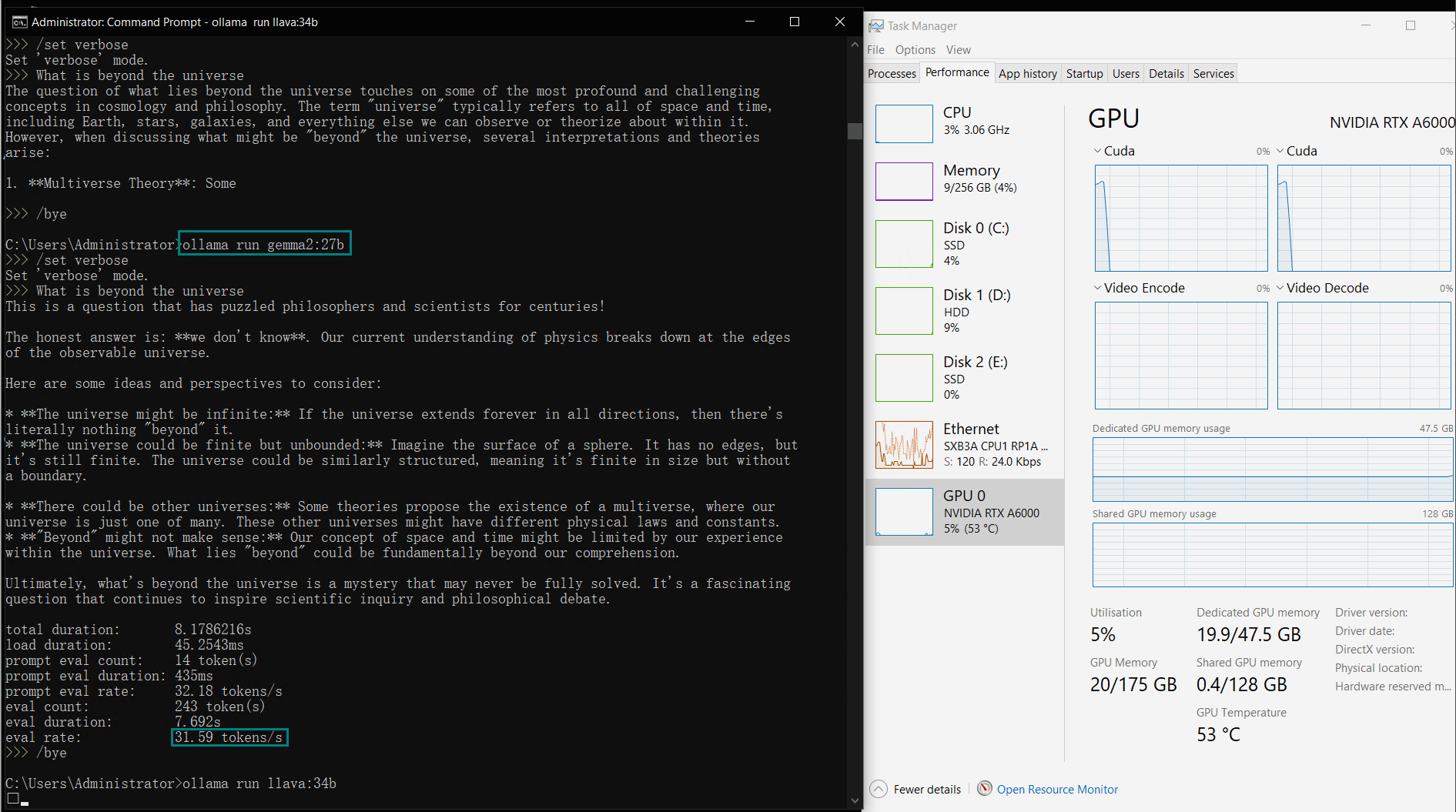
Benchmark Results: Ollama GPU A6000 Performance Metrics
| Models | deepseek-r1 | deepseek-r1 | deepseek-r1 | llama2 | llama2 | llama3 | llama3.3 | qwen | qwen | qwen2.5 | qwen2.5 | gemma2 | llava | qwq | phi4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Parameters | 14b | 32b | 70b | 13b | 70b | 70b | 70b | 32b | 72b | 14b | 32b | 27b | 34b | 32b | 14b |
| Size(GB) | 9GB | 20GB | 43GB | 7.4GB | 39GB | 40GB | 43GB | 18GB | 41GB | 9GB | 20GB | 16GB | 19GB | 20GB | 9.1GB |
| Quantization | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| Running on | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.11 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 | Ollama0.5.4 |
| Downloading Speed(mb/s) | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 11 |
| CPU Rate | 3% | 3% | 3% | 3% | 5% | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 3% | 3% | |
| RAM Rate | 4% | 4% | 4% | 3% | 3% | 3% | 3% | 4% | 3% | 3% | 4% | 3% | 4% | 4% | 4% |
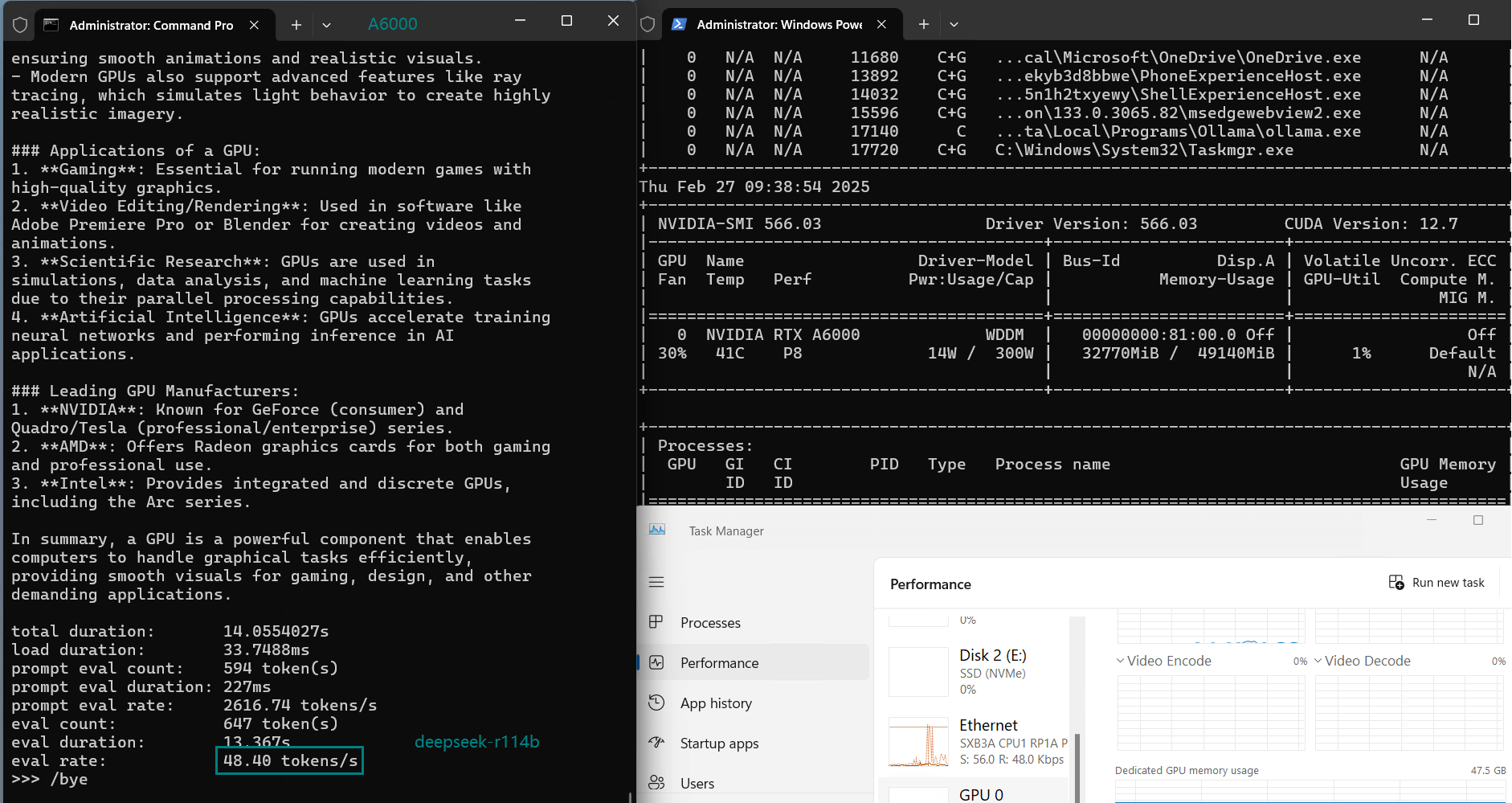
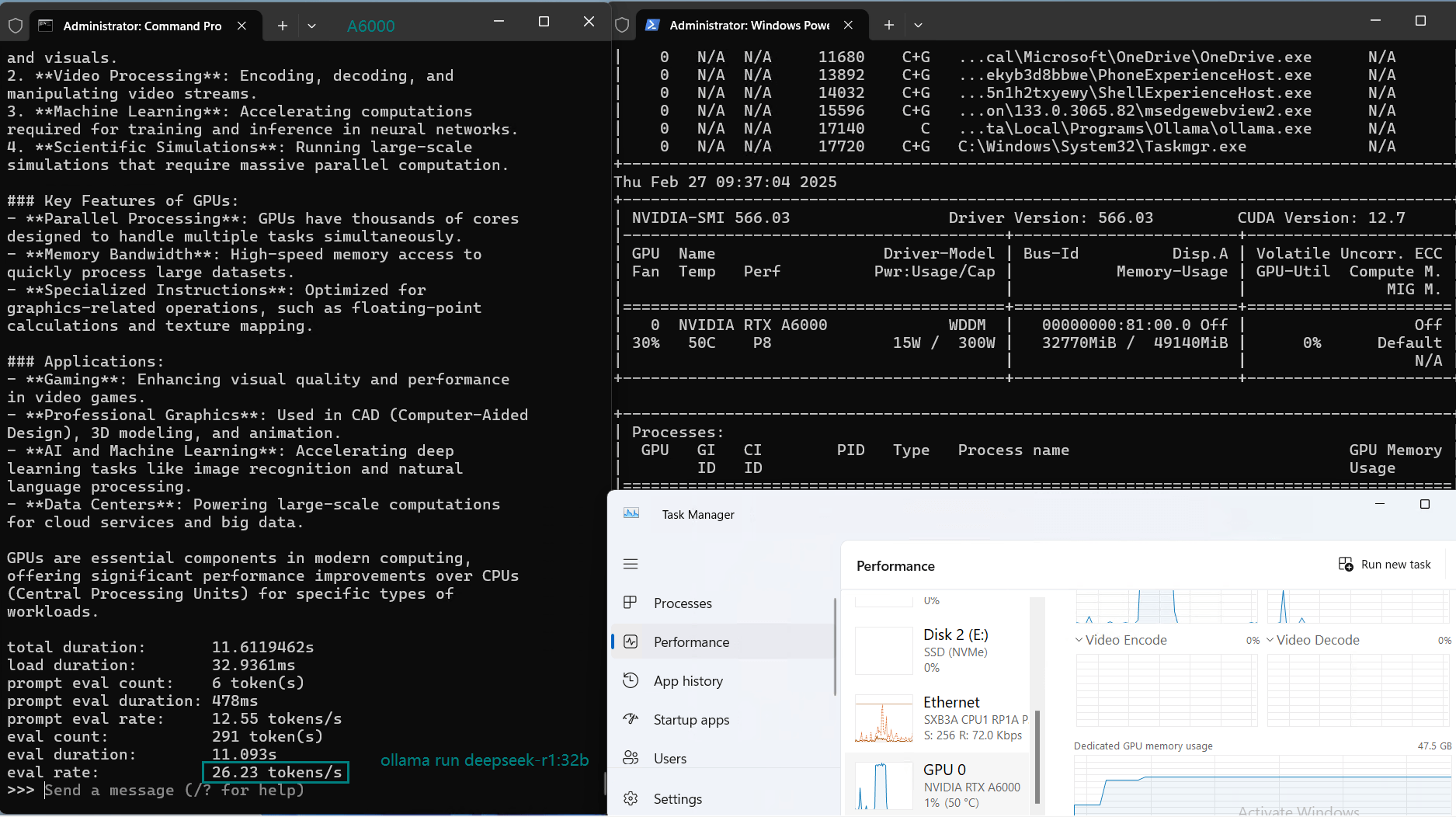
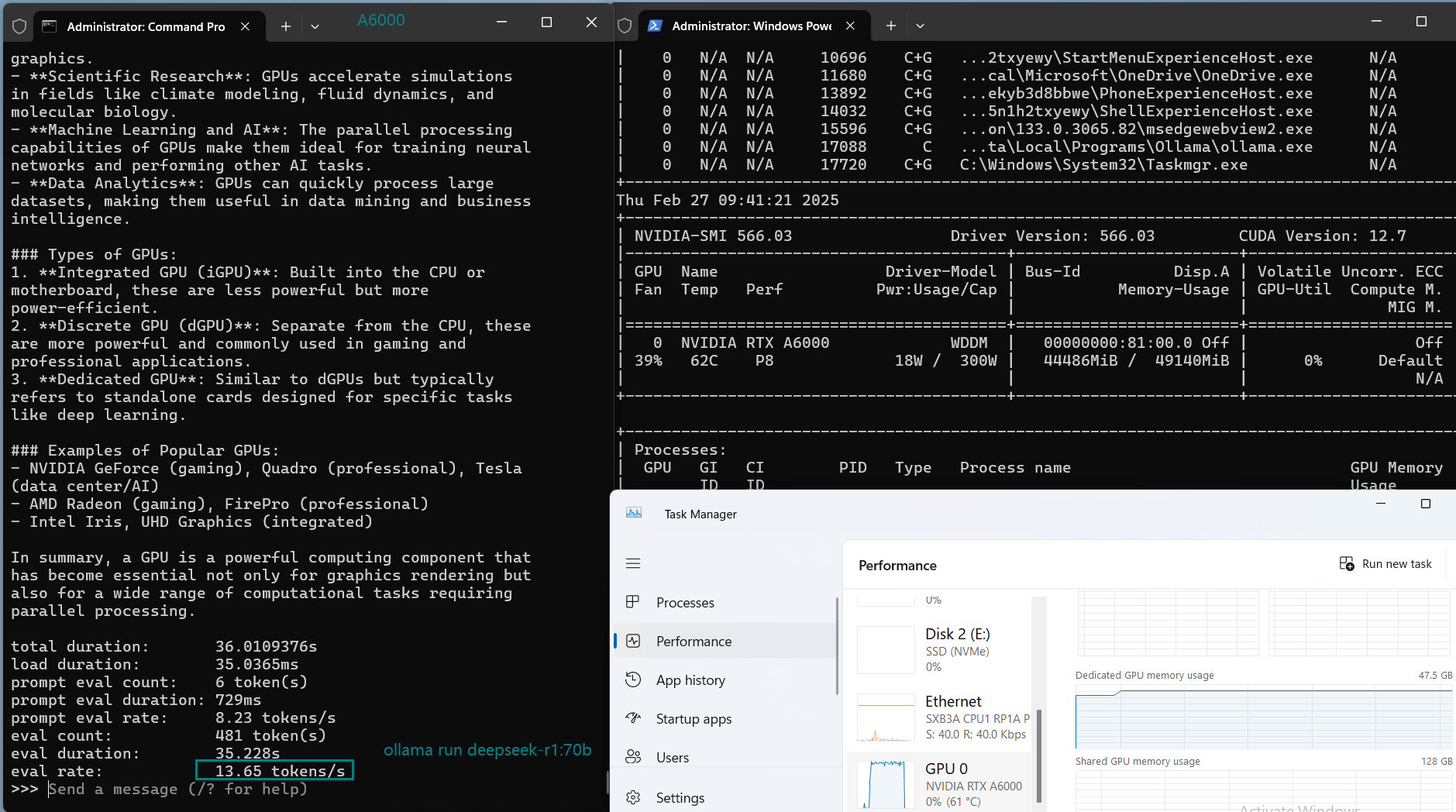
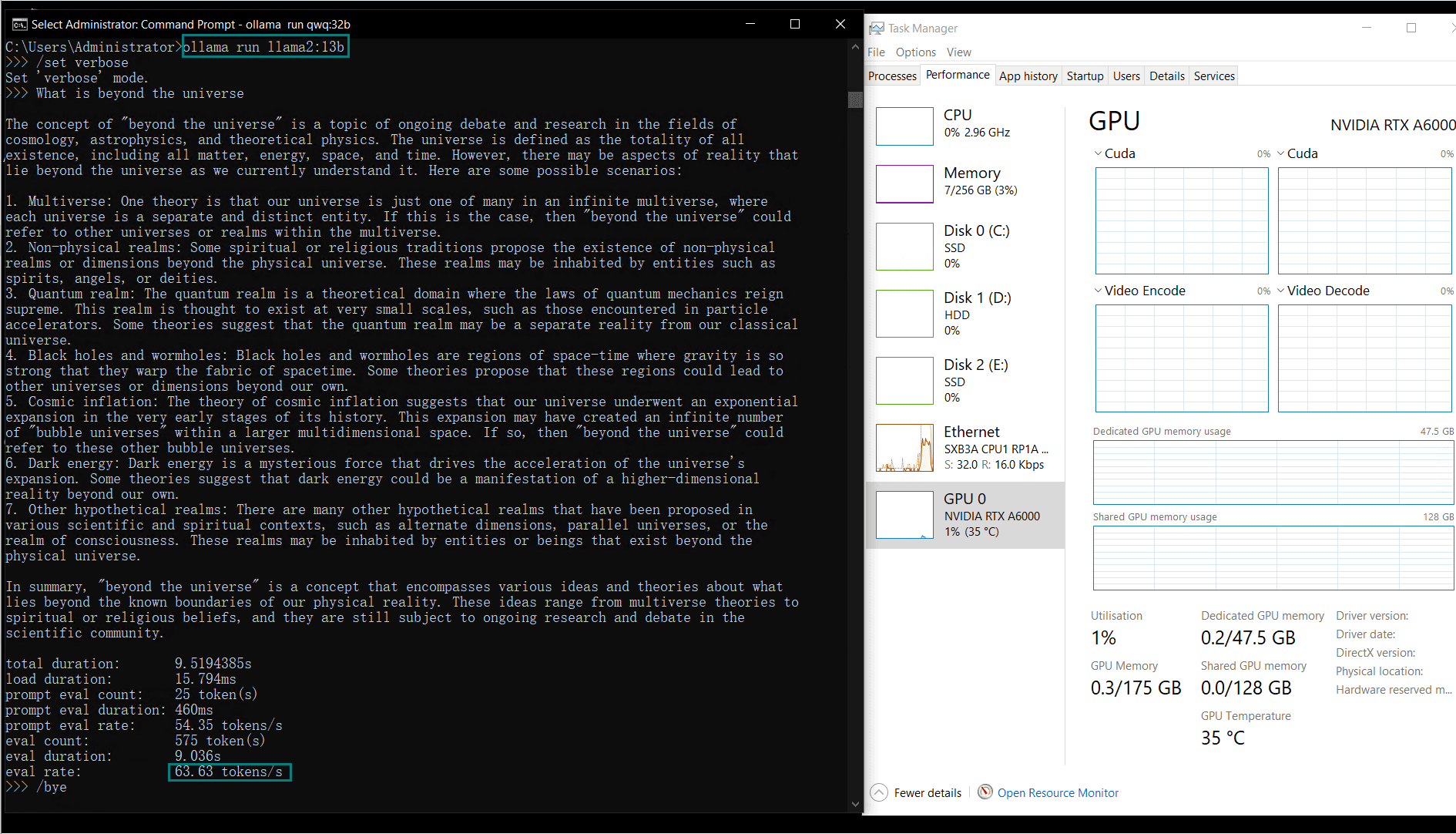
| GPU vRAM | 78% | 68% | 90% | 30% | 85% | 88% | 91% | 42% | 91% | 22% | 67% | 40% | 85% | 91% | 70% |
| GPU UTL | 86% | 92% | 96% | 87% | 96% | 94% | 94% | 89% | 94% | 83% | 89% | 84% | 68% | 89% | 83% |
| Eval Rate(tokens/s) | 48.40 | 26.23 | 13.65 | 63.63 | 15.28 | 14.67 | 13.56 | 27.96 | 14.51 | 50.32 | 26.08 | 31.59 | 28.67 | 25.57 | 52.62 |
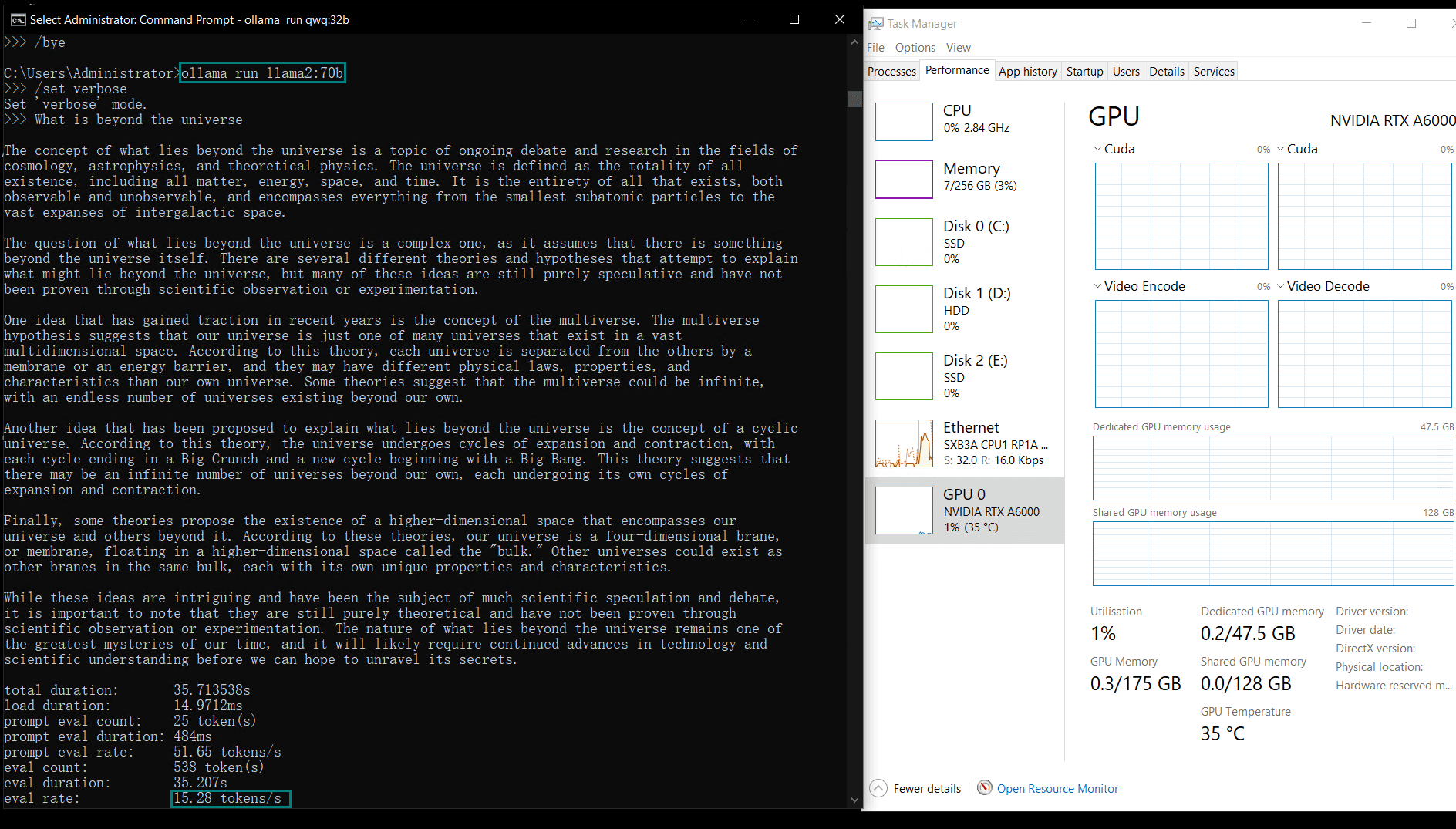
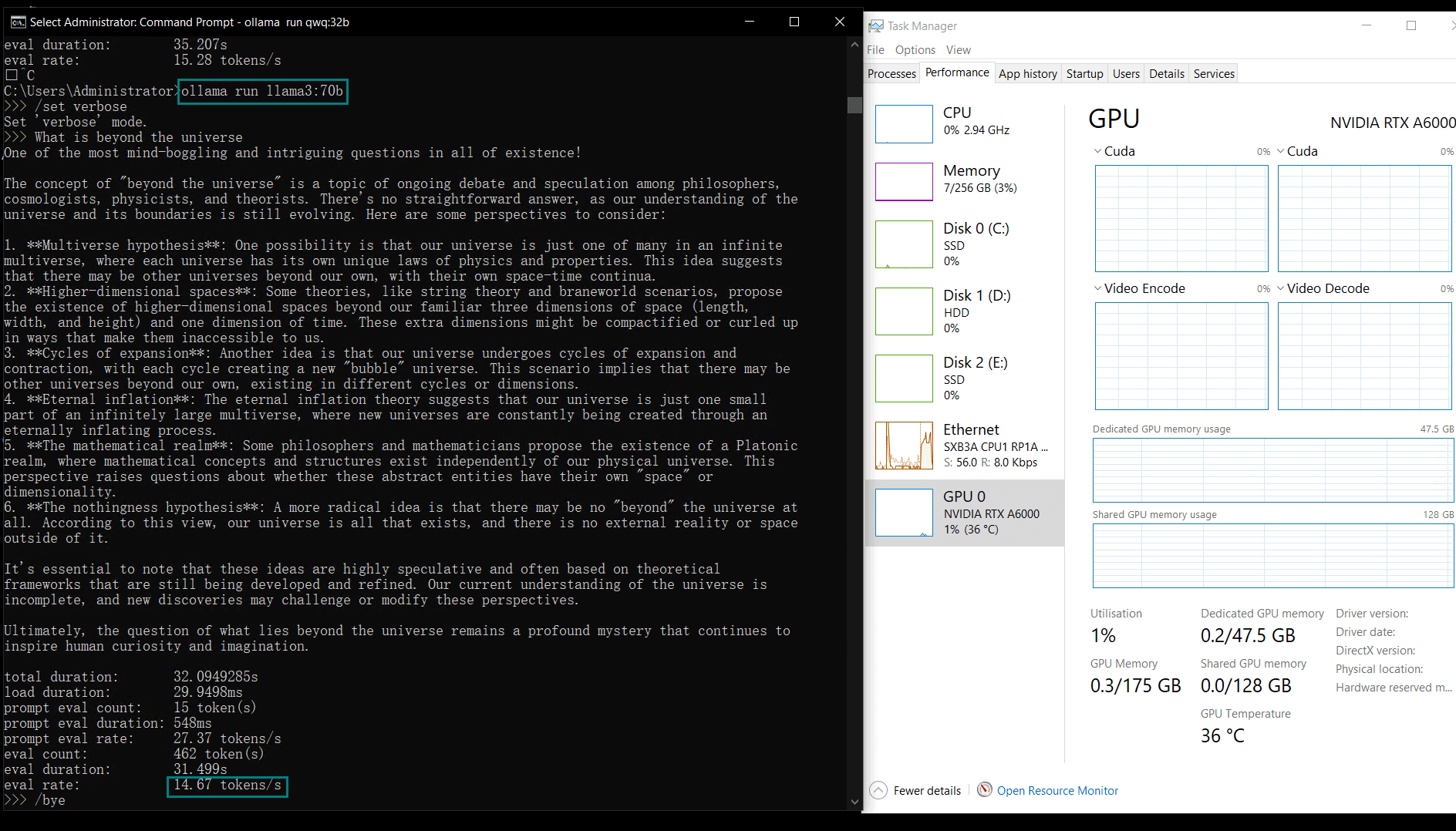
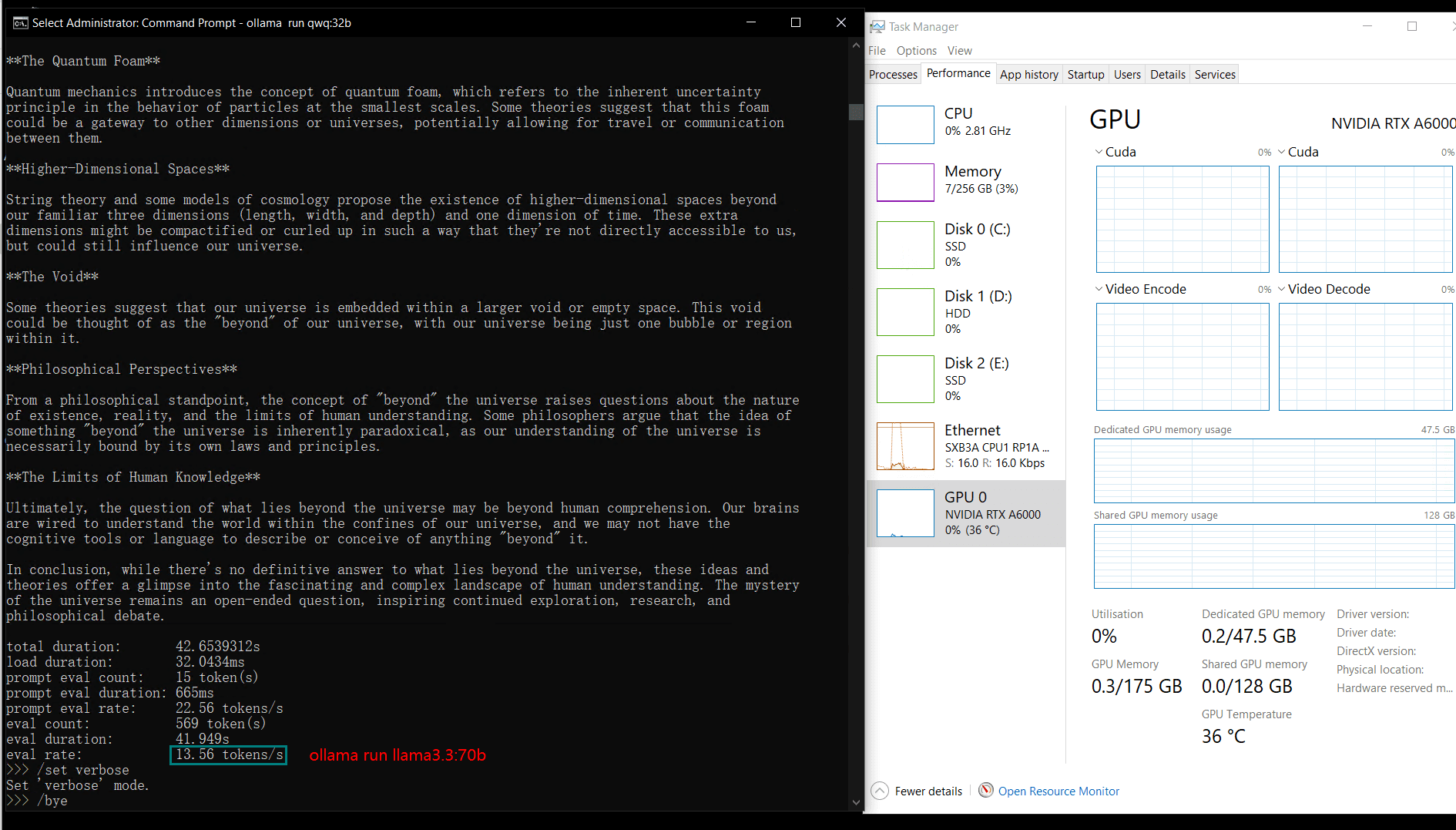
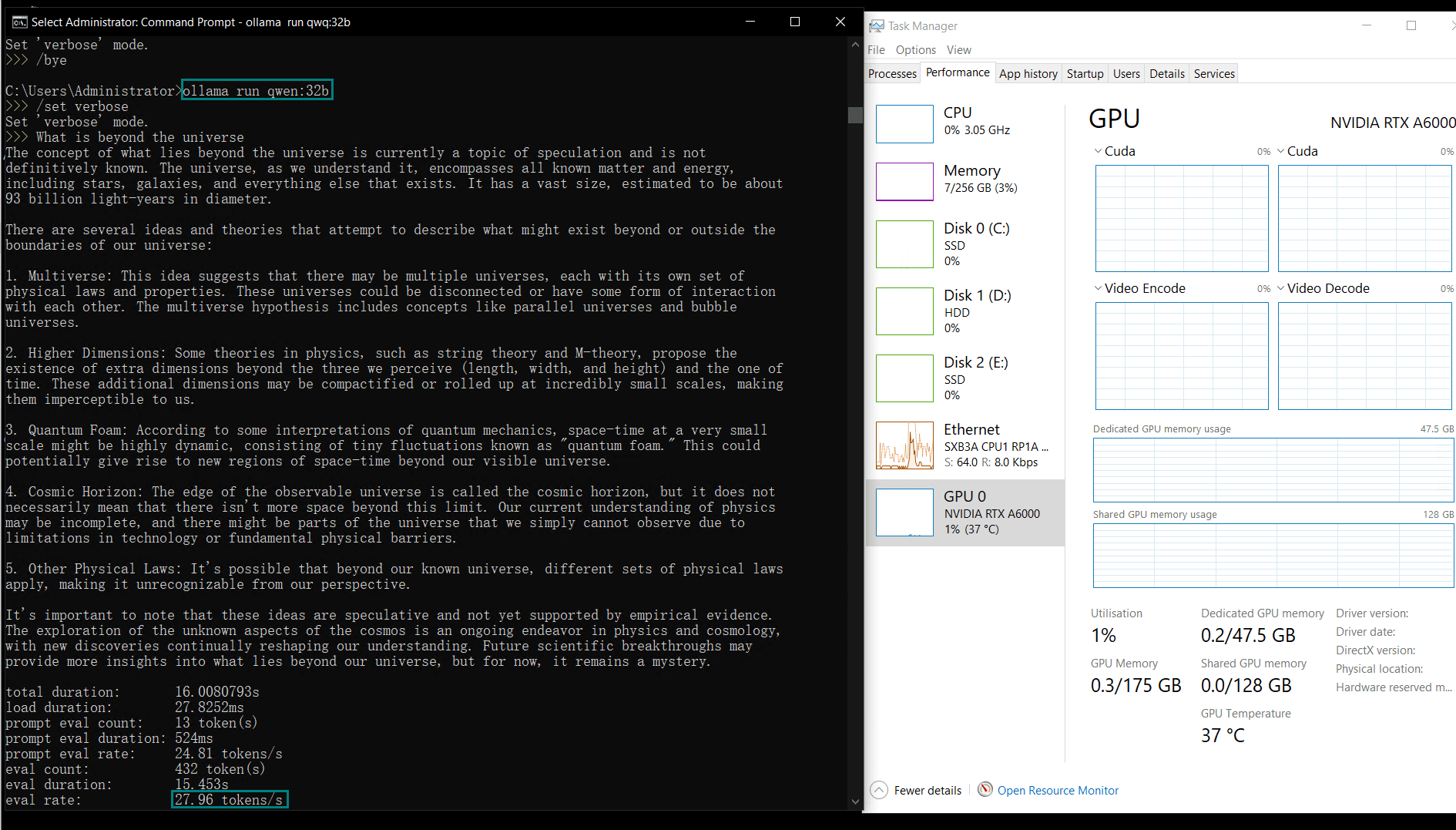
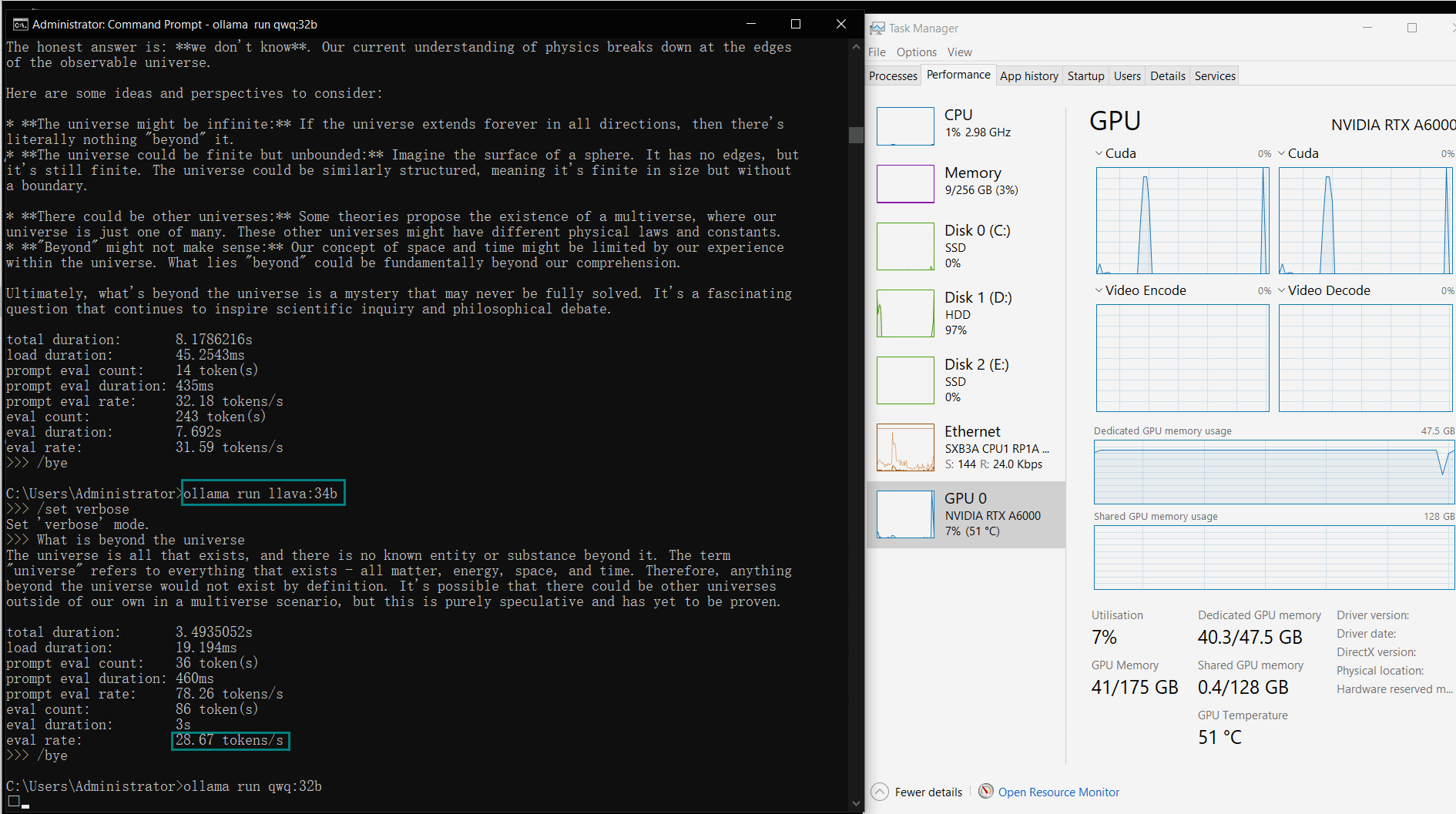
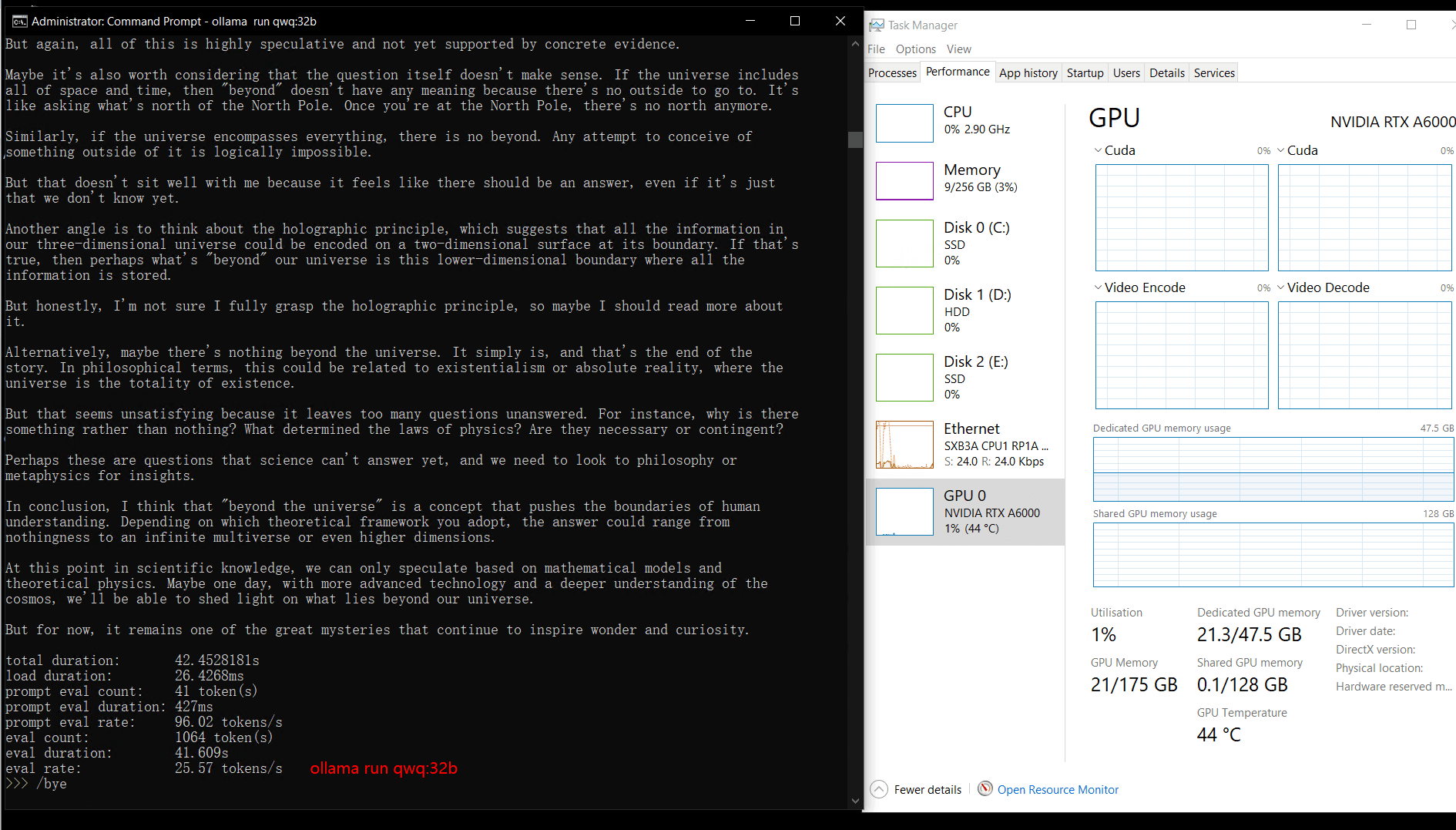
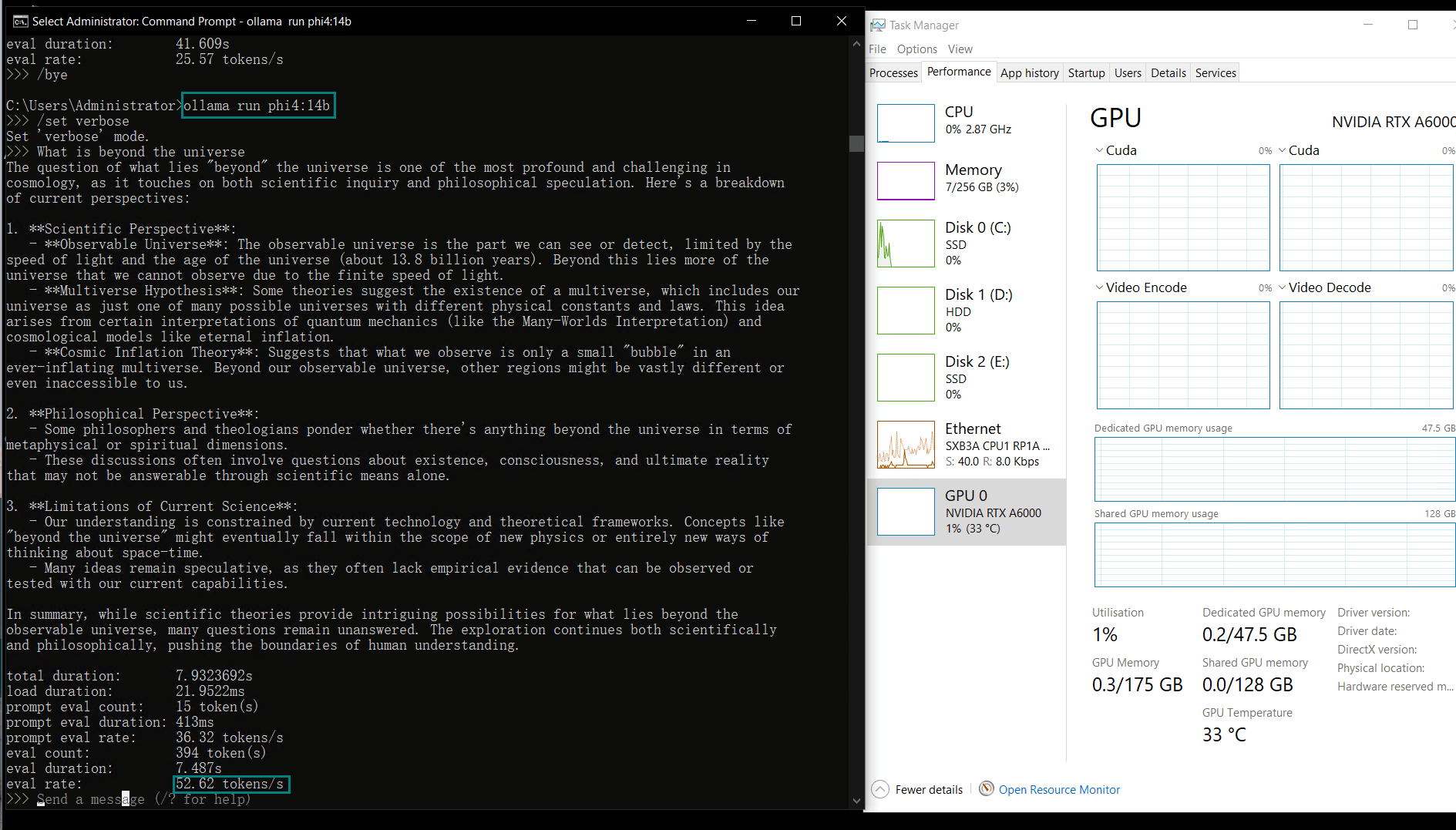
Key Insights
1. LLM Compatibility
2. Evaluation Rate
3. GPU Utilization
4. vRAM Usage
| Metric | Value for Various Models |
|---|---|
| Downloading Speed | 11 MB/s for all models, 118 MB/s When a 1gbps bandwidth add-on ordered. |
| CPU Utilization Rate | Maintain 3% |
| RAM Utilization Rate | Maintain 3% |
| GPU vRAM Utilization | 22%-91%. The larger the model, the higher the utilization rate. |
| GPU Utilization | 80%+. Maintain high utilization rate. |
| Evaluation Speed | 13.56 - 63.63 tokens/s. The larger the model, the slower the Reasoning speed. |
Get Started with A6000 GPU Dedicated Server
Enterprise GPU Dedicated Server - RTX 4090
- 256GB RAM
- GPU: GeForce RTX 4090
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ada Lovelace
- CUDA Cores: 16,384
- Tensor Cores: 512
- GPU Memory: 24 GB GDDR6X
- FP32 Performance: 82.6 TFLOPS
Enterprise GPU Dedicated Server - RTX A6000
- 256GB RAM
- GPU: Nvidia Quadro RTX A6000
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 10,752
- Tensor Cores: 336
- GPU Memory: 48GB GDDR6
- FP32 Performance: 38.71 TFLOPS
Enterprise GPU Dedicated Server - A100
- 256GB RAM
- GPU: Nvidia A100
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 100Mbps-1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 6912
- Tensor Cores: 432
- GPU Memory: 40GB HBM2
- FP32 Performance: 19.5 TFLOPS
- 50% Off First Month, 30% Off Renewals
Multi-GPU Dedicated Server - 3xRTX A6000
- 256GB RAM
- GPU: 3 x Quadro RTX A6000
- Dual 18-Core E5-2697v4
- 240GB SSD + 2TB NVMe + 8TB SATA
- 1Gbps
- OS: Windows / Linux
- Single GPU Specifications:
- Microarchitecture: Ampere
- CUDA Cores: 10,752
- Tensor Cores: 336
- GPU Memory: 48GB GDDR6
- FP32 Performance: 38.71 TFLOPS
Summary and Recommendations
The Nvidia Quadro RTX A6000, hosted on a dedicated GPU server, excels in running LLMs via Ollama. Its robust performance metrics, efficient utilization of computational resources, and compatibility with diverse models make it a top-tier option for AI developers.
If you’re looking for high-performance A6000 hosting or testing environments for LLM benchmarks, this setup offers exceptional value for both research and production use cases.
Nvidia Quadro RTX A6000, A6000 benchmark, LLM benchmark, Ollama benchmark, A6000 GPU performance, running LLMs on A6000, Nvidia A6000 hosting, Ollama GPU test, AI GPU benchmarking, GPU for large language models, A6000 vs RTX 4090, AI GPU hosting